消息队列-⑦扩展篇
消息队列-⑦扩展篇
学习核心
- 消息队列-扩展篇
- 消息队列消费模型
- Zookeeper扮演了什么角色(基本认知)
- Kafka版本演进(了解)
学习资料
todo:window 下基于docker搭建kafka
消息队列消费模型
1.消费模型
- 点对点模型:一对一消费(一条消息只能被消费者消费一次)
- 发布订阅模型:生产者发布主题,订阅者可以订阅一个或多个主题,接受相应主题的信息,每条消息可以被多个订阅者消费
🚀点对点模型
点对点模型:生产者将消息发送到队列,消费者从队列读取并处理消息,并且每条消息只能被消费者消费一次。这点和数据结构里的队列概念类似(消费即出队),所以在某些资料也会称之为队列模型

在点对点模型下,是没法多个消费者都消费同一条消息的,如果非要安排多个消费者,那其实这些消费者是竞争关系,某条消息被一个抢到了,那么另外的消费者就无法得到该消息。
说实话,一条消息被多个消费者访问,是现代互联网一个非常常见的消息处理场景,如果作为消息队列不支持这个能力的话,可以说是一个残缺不全的消息队列,为了适应需求,因此后期引入了发布-订阅模型
🚀发布订阅模型
发布者将消息发送到主题,订阅者订阅一个或多个主题,就可以接收相应主题的消息。每条消息可以被多个订阅者消费
发布订阅模型的核心目的就是让一条消息能传递到多个消费者

3.不同消息队列的消费模型
Kafka是什么模型?
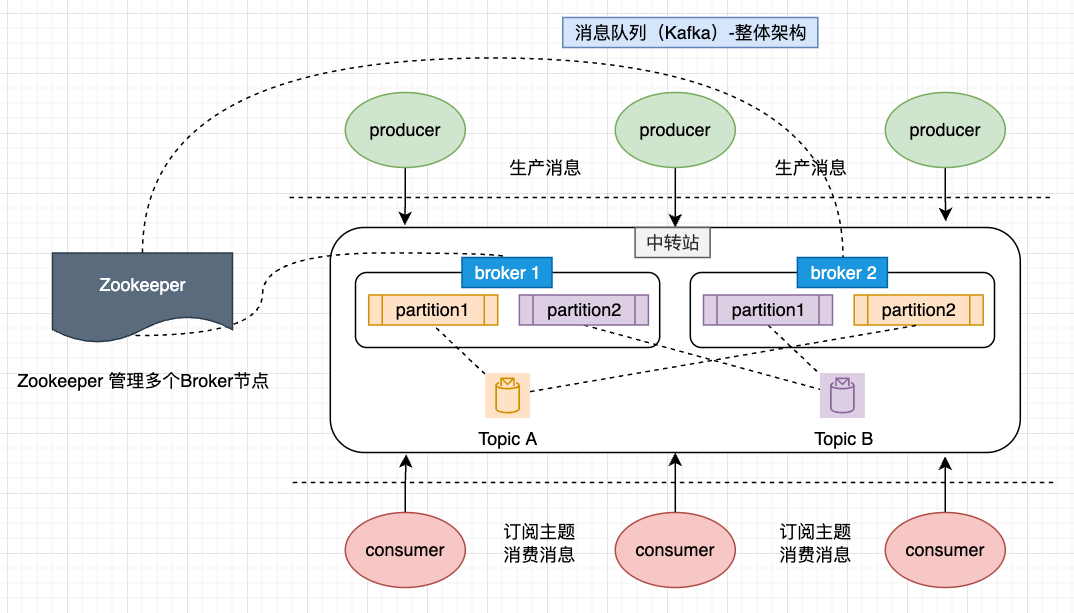
结合Kafka的架构图示分析,很明显Kafka是一个经典的“发布-订阅模型”:
- producer 将消息投递到topic,由consumer订阅topic进行消费
- 不同消费者可以消费相同主题,也就是一条消息能传递给多个消费者
- 消费者可以通过偏移量来指定从哪里开始拉取,也就是说数据不是消费就删除,而是可以重复拉取(显然不是点对点(队列)模型)
4.其他消息队列是什么模型?
其实发布订阅模型,可以说是为了解决点对点模型不足而诞生的。换句话说,点对点模型能做的,发布订阅模型都能做,但发布订阅模型能做的,点对点做不了
所以,基本上所有现代消息队列,都是发布订阅模型(比如RocketMQ,Kafka,Pulsar)。唯一一个坚持用点对点模型的是RabbitMQ,其虽然本身架构是点对点模型,但是实际是通过加了个中间层,来拟支持了发布订阅的功能。
简单理解,一般的消息队列就是生产者->队列->消费者,但是RabbitMQ是生产者->Exchange->队列->消费者,其中Exchange做了一次转发,一条消息如果需要多个消费者消费,就让 Exchange 将消息发送到多个队列,每个消费者再去各自队列消费这条相同消息,本质就是自身架构上没有支持发布-订阅模式,但是通过一层代理模拟了发布订阅的功能。

Zookeeper扮演了什么角色(基本认知)
在消息队列的学习中,使用Docker搭建Kafka环境,其还依赖于一个特别重要的组件Zookeeper,Kafka 通过第三方存储工具Zookeeper来实现Broker的整体化。如果是使用docker安装方式,进入容器之后,cd到bin目录,找到zkCli.cmd脚本并执行,则可进入zookeeper控制台,通过这个控制台可以借助命令操作zookeeper
1.Zookeeper在MQ场景中扮演的角色
# 进入zookeeper容器
docker exec -it zookeeper-test /bin/bash
# 进入指定bin目录,执行zkCli.sh指令,进入zookeeper控制台
作用1:管理Broker、Topic数据
Zookeeper中存储了Broker和Topic相关的信息。比如可以查看Broker的id,例如单机版的Kafka,只有1个ID为1001的brokers。
使用get命令可以查看1001具体的数据,也可以查看topic列表以及其下的Partition分片信息
# 查看Brokers信息
ls /brokers/ids
# 查看指定broker的Topic信息
get /brokers/ids/1001
# 查看topic列表信息
ls /brokers/topics
# 查看Partition分片信息(lieu查看test这个Topic下的分片信息)
ls /brokers/topics/test
# 查看分片的Leader、ISR列表等
ls /brokers/topics/test/partitions/0/state
get /brokers/topics/test/partitions/0/state
Zookeeper的数据很像Linux目录结构,此处不用把Zookeeper当成什么很复杂的技术,对于用户(Kafka)而言,它就是一个透明的、拿来即用的工具。
作用2:记录分区和消费者的关系
kafka的每个partition只能被某个消费者组的同一个consumer消费,kafka必须知道所有的partition与consumer的关系,因此消费者与分区的关系被保存在zk当中
作用3:记录消费者偏移
这个用法在0.9版本之后早就取缔了,就大概介绍一下
Kafka此前的版本还会在Zookeeper上记录消费者的偏移,但这显然是存在问题的,Zookeeper高可靠性适合做分布式协调,但是不太适合高并发的访问和大量的IO交互,而消费提交在高并发场景就是大量的IO交互。所以,新一点版本的Kafka,是不会再把偏移提交到Zookeeper,而是搞了个内部主题(_consumer_offsets)来存储偏移信息
作用4:存储配置信息
Zookeeper本身就比较适合作为配置中心,所以在Kafka中也用来记录一些配置信息,这样将配置信息存储在Zookeeper这种第三方组件,所有的Broker都可以很方便地拿到对应配置以及感知到相应变化。
比如,通过指令ls /config/topics、get /config/topics/[topicName]可以查看Zookeeper记录了主题相关的一些配置
作用5:协助选举Controller
对于使用方而言,Zookeeper有几个特性
- (1)相同路径不允许重复写入
- (2)数据可以是临时的,也就是如果没续期过期后会自动删除
- (3)支持watch机制,可以感知到对应路径的创建、删除
基于此,Kafka比较早期就直接让分片副本抢写Zookeeper,谁先写入谁就是Leader,但是这样有个潜在问题:当分区和副本数量比较多的时候,所有的副本都直接参与选举,对ZooKeeper的压力会比较大。更新一些的版本,Kafka做了优化,与其让所有副本都来卷,不然就先选举一个Broker作为Controller,也就是控制者。
Controller职责:感知Broker、Topic、Partition的变化,维护Partiontion的Leader信息。
现在生产环境的版本基本都是优化之后的Controller方式,原来所有副本都参与的方式是很早的版本设计。有了Controller再结合ISR机制,就可以直接指定ISR集合中的第一个备选Broker作为新Leader。所有的Broker会尝试在Zookeeper中创建数据/controller,先创建成功的就是Controller。注意,这是个临时数据,如果当前的Controller挂掉或者网络掉线,这个数据就会消失。其它Broker通过Watch感知到这件事之后,就会再次抢写。
2.Zookeeper在MQ场景的功用总结
Zookeeper 拥有分布式协调能力,Kafka主要是用Zookeeper来管理Broker/Topic数据、记录分区和消费者关系、存储配置以及选择Controller。在很早的Kafka版本中,Kafka会利用Zookeeper存储消费偏移信息,但由于Zookeeper不适合用作频繁IO交互的场景,因此砍掉了这个设计,通过引入“内部主题”(_consumer_offsets)存储记录消费偏移(提交),减轻Zookeeper负担,让其专注协调相关事宜
Kafka版本演进(了解)
1.Kafka 版本规则说明
在 Kafka 1.0.0之前基本遵循4位版本号(例如Kafka 0.9.2.1等)。从Kafka 1.0.0开始Kafka就告别了4位版本号,遵循语义化版本控制(Semantic Versioning,SemVer)的规则,版本号格式为Major.Minor.Patch:
- MAJOR(主版本号):一般代表重大改变,当进行重大功能更新或不向后兼容的变更时,增加主版本号,比如从 2.x到 3.0
- MINOR(次版本号):当添加新功能或进行向后兼容的改进时,增加次版本号,比如2.4到2.5
- PATCH(补丁版本号):通常是为修复一些Bug发布的版本,比如2.4.1到2.42
版本兼容性
- 主版本号更新:通常会包含不向后兼容的更改。升级到一个新的主版本可能需要修改配置或代码
- 次版本号更新:通常是向后兼容的,添加了新功能或改进了现有功能。升级到一个新的次版本通常不会破坏现有的配置或代码
- 补丁版本号更新:通常是完全向后兼容的,只是修复了错误或漏洞。升级到一个新的补丁版本通常是安全的,不会影响现有系统
版本支持和维护
- 每个主版本和次版本在发布后都会有一段时间的支持期。在此期间,开发团队会发布补丁和小更新来修复问题和提高稳定性
- 当一个新的主版本发布时,旧的主版本可能会逐渐停止维护
2.版本选择建议
(1)遵循一个基本原则,Kafka客户端版本和服务端版本应该保持一致,否则可能会遇到一些问题
(2)根据是否用到了Kafka的一些新特性来选择,假如不想维护Zookeeper,可以选择3.0之后的版本
(3)不用去追求最新版本,大厂很多团队是选择2.x的版本,足够稳定,而且很多团队用了非常多年了,没有刚需是不会冒险升级的,特别是腾讯一些团队,尤其是遵循这个原则