消息队列-②实践篇
消息队列-②实践篇
学习核心
- 消息队列-实践篇
- Kafka 实践经验 (消息丢失、消息重复、消息有序、消息积压等问题处理)
- 话题1 - 消费语义:at most once、at least once、exactly once
- 消息不丢失:消息什么情况下会丢失?kafka如何解决消息丢失问题
- 消息不重复消费:消息什么情况下会重复?kafka如何解决消息不重复消费
- 话题2 - 消息有序
- 什么情况下需要消息有序?
- 如何实现消息有序?
- 话题3 - 消息积压
- 消息积压问题是什么?
- 如何处理消息积压问题?
学习资料
Kafka 实践经验
1.消费语义
消费语义概念核心
对于消息,一般有如下几种消费模式:
at most once(最多一次语义):消息可能会丢失,但绝不会被重复发送,其适用于对消息传递可靠性要求不高的场景(如日志记录)at least once(至少一次语义):消息不会丢失,但有可能被重复发送处理,其适用于对消息传递可靠性有要求,但可以容忍消息重复的场景(如事件通知)exactly once(精确一次语义):消息不会丢失,也不会被重复发送,其适用于关键业务场景,需要严格保证消息处理一次且仅一次(如金融交易处理)
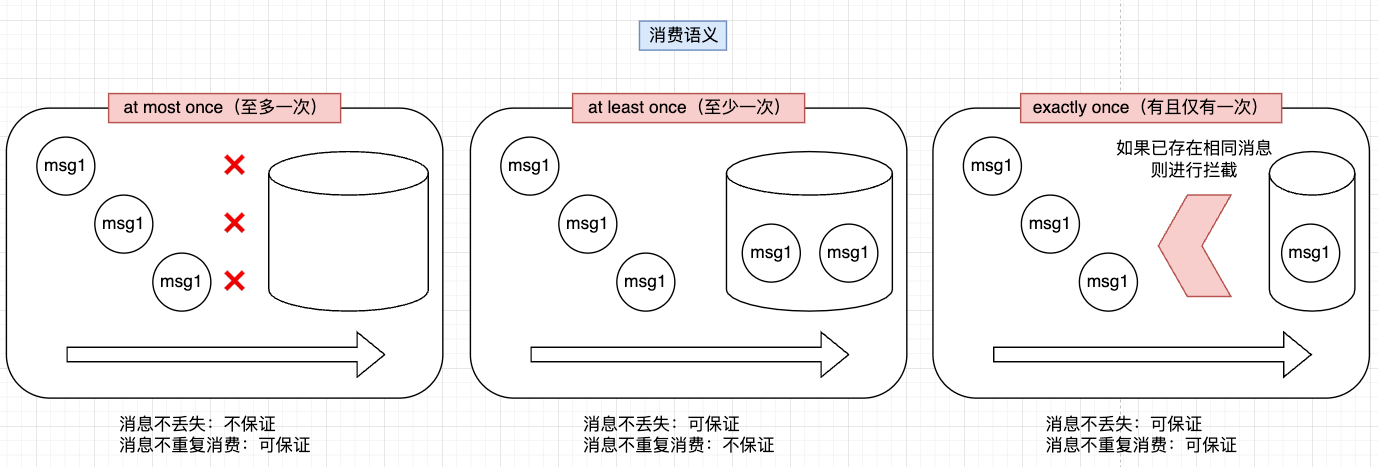
如果基于”消息不丢失“和”消息不重复消费“这两方面进行考虑,选择相应的语义分析:
| 分析目标 | 至多一次 | 至少一次 | 精确一次 |
|---|---|---|---|
| 消息不丢失 | 不保证 | 可保证 | 可保证 |
| 消息不重复消费 | 可保证 | 不保证 | 可保证 |
消息队列一般实现的都是at least once语意(即至少能消费一次),比如Kafka就是如此,即只要消息进入了Kafka,是很容易去实现at least once的能力的,但是要考虑被重复发送的可能性
但实际上在后端业务中,很多时候业务对消费的态度其实是exactly once(精确一次语义),也就是既保证消息不丢失,又保证消息不重复。Kafka要进一步实现“精准一次消费”是非常困难的。这主要是因为后端任何一个环节,都要考虑各种故障情况:
- (1)系统故障和网络问题:分布式系统中,Broker、生产者和消费者之间的通信可能会受到网络延迟、中断或系统故障等等异常情况的影响。这些问题可能导致消息重复发送、接收或处理
- (2)并发处理:Kafka支持高并发处理,多个消费者可以同时消费同一个主题的消息。在并发环境中,确保每条消息只被处理一次需要复杂的协调和同步机制
- (3)消费者处理逻辑:消费者在处理消息时可能会出现异常或错误,导致消息处理失败。如果消费者没有正确处理这些情况(例如,没有提交偏移量或没有重试机制),那么消息可能会被重复处理
虽然Kafka可以通过一系列机制保证了消息的至少一次消费,但由于分布式系统的复杂性和不确定性,它无法承诺每条消息都被精确处理一次,那怎么办呢?
解决方案:要实现精准一次消费,实际光靠消息队列是做不到的,需要消息队列与业务逻辑配合完成,实际做法就是消息队列至少一次消费+业务提供篡等性,这种这种消息队列与业务配合的做法,就能实现业务逻辑上的准确一次消费
如何保证消息不丢失
消息队列作为消息传递的中枢,承担着不同业务的消息数据,这些消息如果在链路中丢失了,可能会带来严重的影响,所以消息队列需要保证消息不丢失。
结合消费语义分析,如果要保证消息不丢失,则at least once和at exactly可以达标,因此要选择相应的消费语义去实现
如何实现
at least once?
反向思考,什么情况下消息会丢失?然后结合这些可能丢失消息的环节进行处理,进而实现at least once:生产环节、存储环节、消费环节

(1)生产环节
消息生产环节(生产端把消息发到Broker这个环节),在环境正常部署的情况下,这个环节其实跟Kafka这个应用关系不大,毕竟发消息是在Kafka客户端,所以Kafka很难保证完全可靠,唯一能做的一点就是发送消息之后必须得到响应,不然就反复重试
Kafka本身是没有什么机制可以保证消息一定生产成功的(需要有额外的确认机制才可以),生产这个环节是在数据进入消息队列之前,消息队列没有办法控制”消息生产“的异常情况,这点也无法由消息队列保证,这个结论也不影响消息队列的可靠性
要解决生产环节的消息不丢失问题,可以通过”重试机制“来保证(当然重试机制也有相应的限制,需结合业务场景调整适配)
例如数据是从数据库或者磁盘中取出进行发送的话,则需记录下已发送的记录或者记录下发送到第几行,当服务挂掉重新恢复之后再次重试发送直到至少成功一次
(2)存储环节
存储环节:针对的是进入消息队列之后的数据,它是持久的(依托于kafka消息队列的确认机制和持久化存储能力,是非常可靠的)
一旦消息被写入并确认(根据所选择的确认级别),消息就会被持久化存储到磁盘中,及时系统发生故障或从其,已经确认的消息也不会丢失,以确保可以被消费者至少消费一次
生产者侧的写入策略配置(扩展参考)
如果不主动设置,acks默认是1,丢失数据的情况比较少(几乎可以忽略),性能也是很高的。如果希望完全可靠的话,则需要设置为all
| acks | 行为 | 可靠性 | 性能 |
|---|---|---|---|
| 0 | 生产者在发送消息后不会等待来自服务器的确认,所以生产者实际是不知道消息是否成功,也就无从重试,生产可靠性是最低的 | 不可靠 | 最高 |
| 1 | 生产者会在消息发送后等待主节点(主节点可理解为Leader节点所在的Broker机器)的确认,但不会等待所有副本的确认 | 相对可靠 | 较高 |
| all或-1 | 只有在所有副本(准确说是所有ISR副本)都成功写入消息后,生产者才会收到确认。这确保了消息的可靠性,但延迟是最高的 | 可靠 | 较低 |
结合图示理解(实线箭头表示操作需要完成,虚线箭头表示不用等待操作完成)

除此之外,Kafka实际上还通过副本机制,让持久化数据更可靠,即将每个主题划分为多个分区,并为每个分区创建多个副本。这确保了即使部分Broker发生故障,消息仍然可以从其他副本中恢复,并被消费者消费。
每个主题在Kafka中被划分为多个分区,每个分区可以有多个副本。其中一个是Leader副本,用于接收读写请求而其他的是Follower副本,用于备份数据。当生产者发送消息到某个分区时,消息首先被写入Leader副本,并等待确认。根据所选的确认级别,生产者可能会等待Leader确认或所有ISR确认。
(3)消费环节
Kafka提供了偏移量管理功能:Kafka消费者通过提交每个分区的偏移量来跟踪已经消费的消息,即使消费者在处理消息时发生故障,重新启动后它仍然可以从最后一个提交的偏移量处继续消费,确保消息至少被处理一次。
相比于自动提交,另一种方式是手动提交,也就是由消费者业务代码自己控制提交时机,主动调用函数来提交(即为了保证消费最终被处理过,只有在消费端处理成功之后,才提交偏移到Broker,否则不进行偏移提交,这样下次拉取还能拉取到这条消息)
这种模式下,即使发生消费者宕机,重启恢复之后也不会发生消息丢失,其本质就类似于平常我们去餐厅吃饭,吃满意之后再付钱,要是饭菜有问题,就不付钱。
总结分析
针对at least once语义的实现,从消息的生产环节、存储环节、消费环节3方面考虑:
- 生产环节:针对的是进入MQ之前的数据,这点kafka没有机制保证,但可通过业务侧重试机制来保证
- 存储环节:针对的是进入MQ之后的数据,kafka的确认机制和持久化能力提供了可靠性保证,依托于写入时指定的ACK策略(需选择所有副本都写入的策略)
- 消费环节:选择”手动提交“(消费成功才提交确认)
- kafka提供了偏移量管理功能,有两种提交方式
- 自动提交:根据提交每个分区的偏移量来跟踪已经消费的消息,即使发生故障也可以跟踪到对应的偏移量处继续消费,确保消息至少被处理一次
- 手动提交:由消费者自行控制提交时机(自行触发函数提交偏移量),只有消费端处理成功之后才提交偏移到Broker,否则就不进行偏移提交
- kafka提供了偏移量管理功能,有两种提交方式
实际业务场景中,大多数业务并不追求消息绝对不丢失,主要也是考虑和性能的兼顾:
- 生产环节:设定重试策略
- 存储环节:ACK写入策略一般选择主节点确认(这种方案可靠性和性能都较高,不追求全部副本都确认,允许这个环节存在数据丢失的情况)
- 消费环节:手动提交,待消费成功后再提交偏移
如何让消息不重复消费
结合消费语义分析,如果要保证消息不重复消费,则at most once和at exactly可以达标,因此要选择相应的消费语义去实现
如何实现
at most once?
类似地,还是从三个环节(生产环节、存储环节、消费环节)进行分析:
- 生产环节:在发送消息的时候重复发送(例如网络抖动、生产者重试发送等情况)
- 存储环节:在kafka中存储的阶段是不会重复存储的
- 消费环节:”手动提交“场景下,业务消费消息之后因某些异常原因没有及时成功提交偏移,导致消息被重复拉取
由于存在网络波动,基本无法做到让消息不重复,只能从”消费“关键字入手,”不重复消费“(不重复产生影响)才是真正的目的。也就是说,光靠消费队列无法做到不重复消费,需要消息队列和业务逻辑配合完成
(1)幂等性消费
Kafka是没办法解决重复消费的问题,只能引入别的机制来解决,即引入可重入消费(幂等性消费)
在数学中,幂等函数为f(x)= f(f(x))。举个例子,求绝对值的函数就是幂等函数abs(x)= abs(abs(x))。可以看到这个函数无论执行多少次,结果都是一样的。在计算机领域,等性也是相似的含义:简单来说,即同样的操作无论执行多少次,结果都一样,也就是说只有第一次造成了数据的改变。
以转账为例,同一笔转账请求,即使因为网络波动或者失败重试重发了多次,但最终实际的金额流转只会有一次。
幂等性是后端设计一个重要原则,因为网络是不可靠的,前置操作(比如请求到MySOL,MySOL之前的流程就是前置操作,也不知道有哪些环节会重复)也是不可靠的,也就是说一个相同的请求,总有概率会重放到你的服务,这种情况是需要考虑的。
一般而言,从接口层面来保证幂等性,一个接口可重入的基础,就是它底层操作都是可重入的。
基于概念分析,此处的幂等性消费其实和Kafka其实没有太大关系,它是一种业务的通用手段,下述案例以MySQL、Redis中的幂等处理方法进行说明
使用Redis进行幂等处理,Redis 常见幂等性实现思路
- 唯一标识符:为每个消息分配一个全局唯一的标识符(如UUID)
- Redis Set:将已消费的消息ID存储在Redis的Set数据结构中。每次消费消息前,检査该消息ID是否已存在于Set中
- 原子操作:使用Redis的原子操作(如 SISMEMBER 和 SADD )来检査和添加消息ID,确保操作的原子性
使用MySQL进行幂等处理,MySQL 常见幂等性实现思路
- 唯一约束:在MySQL表中为消息ID创建一个唯一约束
- INSERT IGNORE:使用 INSERT IGNORE 或 ON DUPLICATE KEY UPDATE 语句来尝试插入消息记录。如果 消息ID已存在,则忽略或更新该记录
- 事务:在需要的情况下,使用事务来确保多个操作的原子性
(2)流量优化(Redis过滤+MySQL幂等)
如果业务是用MySQL做存储,则可以参考上面MySOL幂等性的处理思路,但此处有个小的优化点,如果重复请求过多,那么MySOL凭白无故会多承担这部分压力,而实际场景中MySOL数据库的性能是比较宝贵的,因此可以加一层Redis过滤来进行性能优化
即在Redis中缓存已经处理过的唯一Key(即缓存已经处理过的消息记录唯一Key),请求压力到MySQL之前先做一次检查过滤,如果发现存在于Redis(说明消息已经被消费过了,请求不需要再打到MySQL),如果发现Redis中不存在,则将请求继续打到MySQL,依赖MySQL的幂等做最后兜底
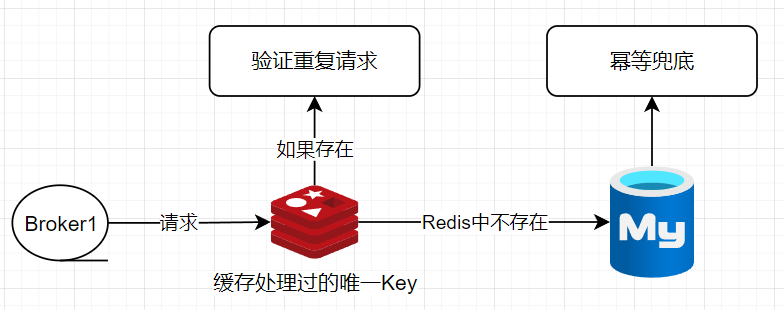
精准一次消费
上述案例分析中,主要从“消息不丢失”、“消息不重复消费” 两个方面分析相应的消费语义实现,从“生产环节”、“存储环节”、“消费环节”三个核心环节分析问题可能出现的原因和相应语义的实现方案。
例如“消息不丢失”是基于“at least once”(至少一次)消费语义说明、“消息不重复消费”是基于“at most once”(至多一次)消费语义说明,但还有一种“exactly once”(精准一次)消费语义,实际上它就是“at least once”+“at most once”语义的组合,构成精准一次消费
2.消息有序
为什么要“消息有序”?
理解“消息有序”,首先需要分析什么场景要消息有序,简单来说,只要有前后依赖的消息,就需要有序。
比如最简单的一个资金系统,假设一个用户的资金本来是1000,他先充值1000,再转账2000。
- 如果按正确的顺序,充值1000 =》账面变成2000,再转账2000 这个顺序操作是可执行的
- 假设执行顺序反了,就变成先转账2000,但账面上才1000是无法转出2000的,显然是会失败的
顺序对结果产生了影响,这就是为什么需要消息有序
要解决消息队列如何让消息有序的问题,可以先分析下下述图示:

Kafka一个主题(topic)的全局可以看作是无序的,因为有很多不同Partition(分区)用于存储,但是在同一个Partition的消息显然是 有序的。所以如果在业务上希望消息有序,则需在Partition的路由上动手脚
如何让消息有序?
简单粗暴:根据业务分区
基于上述分析,让消息有序即根据**“分区”**做手脚。一种最“简单粗暴”的方式就是根据业务确定分区,以此实现业务消息有序。
即将业务所有消息都指定同一个分区Key(所有消息添加至同一个Partition),比如秒杀业务像下面这样向tp-seckill这个Topic发送消息,都用分区Key:"aaabbbccc"来发送:kafkaTemplate.send("tp-seckill","aaabbbccc", msg); 潜在的不足之处在于这样做性能的扩展性就低了很多,当单个业务增长比较快,最后压力都给到了同一个Partition,无法发挥多Partition的优势,所以一般而言还会根据情况进一步地业务内再分区。
分区优化:业务内再次分区
基于上述简单粗暴的方式,可以根据业务分区,而如果单个业务压力过大,就要考虑业务内再次切分。这里可以类比一下MySQL的分表,其实会发现差不多,本质都是将集合进一步做切片,以寻求更大的并发能力和吞吐量。
分区思路
(1)子业务分区
子业务分区核心:探索将大颗粒拆得更小更细,以便进一步扩展
同一个团队下,可能有不同的服务(比如金融服务、消息服务等),假设都要传递消息给消息队列,可以按照不同的服务划分为相应的分区。按业务分了之后,其实还可以深挖是否可以按子业务拆分,比如金融服务分为风控子业务、支付子业务,消息服务分为短信通知、微信通知等
// 例如消息服务的短信服务分区key:msg-aaabbbccc
kafkaTemplate.send("tp-msg","msg-aaabbbccc", msg);
// 例如消息服务的微信服务分区key:wechat-aaabbbccc
kafkaTemplate.send("tp-msg","wechat-aaabbbccc", msg);

(2)客户分区
以客户之间没有依赖、但是客户内部需要有序来为前提,可以选择按客户分区
如果对于客户而言,数据是比较独立的,客户之间没什么交互,还可以按客户来分区。
比如消息是记录某个客户的减肥记录,里面包含了日期和减了多少斤,消费之后希望按投递的顺序记录进某个文件或数据库,这种场景就是客户自己有序即可,客户不用关心别的客户减肥情况,也就是说客户之间不需要依赖。符合这种场景的业务,就可以按客户来进行分区,比如最简单的,按用户id%100来分,这样就可以划出来100个分区,比如用户1001就用分区Key:user-mod-1,用户2002就用分区Key:user-mod-2
// 如果userId%100=1 则用分区Key:user-mod-1
kafkaTemplate.send("tp-body","user-mod-1", msg);
// 如果userId%100=2 则用分区Key:user-mod-2
kafkaTemplate.send("tp-body","user-mod-2", msg);
// .... 以此类推 .....
这种方式有一个缺点,增减节点会对原有的路由分布会造成冲击,比如原来9个分区,用户id是10,那算出来就是10%9=1号分区,假设增加一个分区,该用户就路由到10 % 10=0号分区,也就是说,当节点增加或减少,会打乱原有的路由规则
如果要解决这个问题,可以考虑参考Redis哈希槽的做法:引入槽的概念,比如约定16384个槽,用用户id进行Hash计算,然后 % 16384,这样就可以关联到算法关联到某个槽(实际业务场景中可能不一定会用到这么多槽,可以定小一点:例如1024)
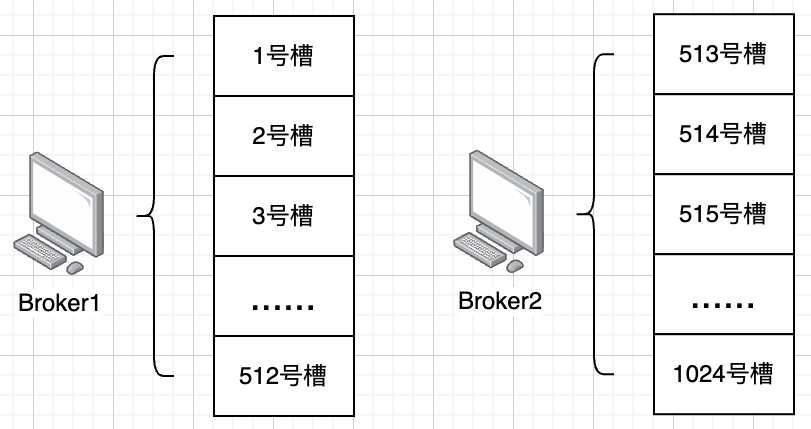
这种模式下,新增节点,就可以有选择性地分配一些槽给新节点,而不用全局都打乱。同时,因为槽比较好腾挪,如果在运营过程中发现流量不均匀,也可以选择性地直接调整热点槽到相对有余力的节点。
除了用Hash槽,还可以用一致性Hash来解决这个问题(实际场景中引入简单的hash槽已经是作为一种扩展了,没必要做太复杂,堆砌太多容易被挑战如果面试过程中一上来就说Hash槽和一致性Hash两种方案,可能会被挑战是否真正实践过。在真实的生产中,业务团队会实现得很简单,Hash槽这种方式都是比较少见)
(3)大小客户分区(客户分区进化版)
还是以客户之间没有依赖、但是客户内部需要有序来为前提。如果单纯按客户来分,能解决大多数的问题,但是设想这么一种场景,某个业务有100个客户,90个客户每天产生100条消息,剩下10个客户,每天产生1000 0000条消息,也就是发生了大客户扎堆现象,这样压力还是集中在同一个Partition(可以理解为数据倾斜概念)
这种情况就可以考虑给大客户提供单独的分区,比如知道ID为user-123的用户是一个大客户,就单独为它指定一个分区user-big,不和其它客户的user-common一起卷,相当于是开通VIP通道
// 如果是大客户
kafkaTemplate.send("tp-body","user-big", msg);
// 如果普通客户
kafkaTemplate.send("tp-body","user-common", msg);
那么此处会思考一个问题:如何感知某个客户就是大客户呢?
=》一般是结合2个大方向:
- 提前知晓:比如很多To B业务,合作都是签订协议的,是不是大客户一目了然,所以可以提前为其独立一个分区
- 实际运作:实际运作发现它是大客户,这种情况下就是发现之后,再迁移新的消息的独立分区
消息有序总结
理解为什么要“消息有序”?
- 在部分场景中,业务依赖需要消息有序支撑,否则可能出现有异常问题
如何解决消息有序?(核心:分区,对标数据库分库分表概念)
- 分区
- 简单粗暴(按照业务分区)
- 分区优化:为了保持更大的并发度,可以根据业务进行分区,尽量只让需要排序的消息放在一个分区,而没有依赖的消息则分离开来,兼顾性能和业务去求需求。如果单个业务分区承载压力过大,则继续拆分子业务,按照子业务分区
- 分区思路
- 子业务分区
- 客户分区:针对客户之间无相互依赖,但是客户内部需要消息有序的前提
- 客户分区:最基础的Hash分区,但可能存在问题
- 问题1:“增删节点会打乱分区路由”的问题
- 通过“Hash槽”、“一致性Hash”这两种扩展方案解决
- 问题2:分区内数据可能存在数据倾斜问题(某个客户分区数据很多或很少)
- 问题1:“增删节点会打乱分区路由”的问题
- 大小客户分区:基于“客户分区”的一种优化方向
- 针对客户分区存在的“数据倾斜”问题,进一步优化调整为按照“客户大小”进行分区
- 将大客户放在一个分区(类似开通VIP渠道概念),不和其他普通客户混在一起
- 针对客户分区存在的“数据倾斜”问题,进一步优化调整为按照“客户大小”进行分区
- 客户分区:最基础的Hash分区,但可能存在问题
- 分区
3.消息积压
消息积压问题
消息积压即消息太多,短时间内处理不过来了。比如消费端处理速度是100/s,但是现在消息队列里已经累计了1000万条数据待消费,那么需要10万秒才能消费完,相当于要1天多,在很多业务场景里,这就算是积压了。
需注意一点,“积压与否”其实并不是一个严格的概念,根据业务不同,对积压的理解是不一样的,比如一个特定的场景中,消费端就是每天凌晨2点拉任务消费,1s能消费10000笔,那么每天积累1000万条数据也可以吃下来,基于此场景在这个团队看来,就不是积压问题
针对积压问题,其实乐观一点是在发生前避免,也就是尽可能不让积压发生:
- 做压测:摸清业务的承载能力,合理部署资源,留一定程度的BUFFER
- 做好相应优化性能:让吞吐能进一步提高,消费能力更高,则积压的可能性自然就更小
- 提前扩容:比如在一些大型活动来临之前,提前安排资源扩容,不打没有准备的仗
当然,在问题未发生前解决,都是比较理想化的。在生产环境中,总会有意想不到的突发情况导致积压,所以积压之后也得有对应的处理手段,首先就是能及时发现
消息积压是消息队列非常常见的问题,大致解决思路就是及时发现、解决异常、增加资源、弃车保帅,具体怎么做需要适配业务场景,最重要的是掌握解决问题的思路
如何处理消息积压问题
(1)发现积压:监控告警
通过监控自动发现积压(第一时间感知到),比如通过定时服务监测Kafka的队列信息,通过队列信息计算积压情况,具体步骤:
- 步骤1:在kafka脚本目录下执行下述脚本(todo)
// 需注意消费组要提前创建
sh kafka-consumer-groups.sh --bootstrap-server localhost:9092 --describe --group miaomiao
- 步骤2:查看结果并分析
观案LOG-END-OFFSET和CURRENT-OFFSET这两个字段,LOG-END-OFFSET表示最新消息的偏移量CURRENT-OFFSET表示当前消费到了哪里,如果CURRENT-OFFSET远小于LOG-END-OFFSET,则可以看作积压。但具体小多少算积压则需结合具体场景分析,比如每小时只能消费1条消息,那么100完全可以看作积压,比如每秒能处理10000条消息,10w也不算积压,挤压与否是取决于业务场景的
(2)处理积压:分析常见积压问题并处理
常见积压问题类型
- 出现异常(异常消息导致的阻塞)=》尽快排查异常,将异常消息消费掉
- 非核心模块拖后腿 =》重要场景中通过系统降级(关掉一些可能影响消费的非核心模块)来提升消费效率
- 压力过载(压力超过可承载范围)=》扩容、设置中间消费者、保新
积压问题类型1:出现异常(异常消息导致的阻塞)
如果是顺序消费场景,是依赖每条消息处理成功的,如果某条消息有问题的话,那就会一直堵在这里,就像被放毒了一样。
至于具体是什么问题,这就千奇百怪了,可能是交易依赖某个资源不足,可能是代码存在什么特殊的bug,刚好这笔交易的某个数值触发了这个bug,需要消费服务升级才能解决。这种异常是直接卡死了整个消息队列,影响比较严重,此时就需要尽快介入,升级消费端代码,将这笔消息合理地处理掉。
参考阿里的一个“消息积压分析案例”(原因是消费者线程出bug卡住,无法正常消费,导致消息积压)
积压问题类型2:非核心模块拖后腿
如果消费链路上还依赖了许多不那么核心的业务,因为这些业务拉满了消费速度,在积压情况下,就可以先进行系统降级,也就是砍掉相关逻辑,加快数据消费。
例如:一个秒杀消费场景,秒杀消费链路中有个数据统计上报,这个功能并不是核心业务,在需要更高性能时候可以给这个功能停掉,这就要求代码里是具备了对应的开关功能的,可以快速降级。
积压问题类型3:压力过载(压力超过可承载范围)
这种情况单纯就是压力过大扛不住了,基于此情况可以采取下述思路解决:
【1】快速加资源扩容:一般而言消费能力跟不上,可以增加消费者对应的资源(这个前提是要消费者服务是支持水平扩容的,不然增加机器也没用)
这里还需要考虑一个主题的分片数量,一个分片只能被消费者组中的一个Consumer消费,如果消费者组中消费者的数量是和分片持平的,比如当前10个分片,对应了10个消费者,这种情况单独扩容消费者是没用的,还需要对应增加分片数量。当然,假设一开始分片数量就多于消费者,比如10个分片只有2个消费者,这时候扩容8个以内的消费者是不用再额外增加做了分片的。
【2】设置中间消费者(暂存消费任务):放置在kafka和真正的消费者之间,中间消费者不处理消费逻辑,仅仅只是提交offset,同时保证将消息保存到别的地方(比如内存、磁盘、数据库、Redis、其它kafka)这样可以一定程度缓解kafka存储的积压(注意只是缓解,争取到了一些解决问题的时间,还是得想办法提高消费速度)
【3】保新:即积压的就消息暂时不管,新的消息导入到新的消息队列并及时处理,待后续缓过来了再处理旧消息
考虑这种场景,因为某个业务做活动,大量消息在几分钟内打入消息队列,积压了几亿条数据,假设没有钱扩容,按现有能力要处理掉这些消息需要耗费1小时,然后此时每秒还有其它业务的消息(假设1000/s),此时这些消息一旦进入消息队列,相当于会被前面的积压堵住。如果业务允许的话,其实可以选择保新,即新消息导入到新的消息队列,这样新消息可以得到及时处理,而旧消息,就等1小时之后慢慢消耗掉即可