Redis-应用篇-③分布式锁
Redis-应用篇-③分布式锁
学习核心
分布式锁核心概念(分布式锁场景应用、分布式锁特性、基于分布式锁特性的分布式锁设计方案扩展和优化)
如何用redis实现分布式锁?
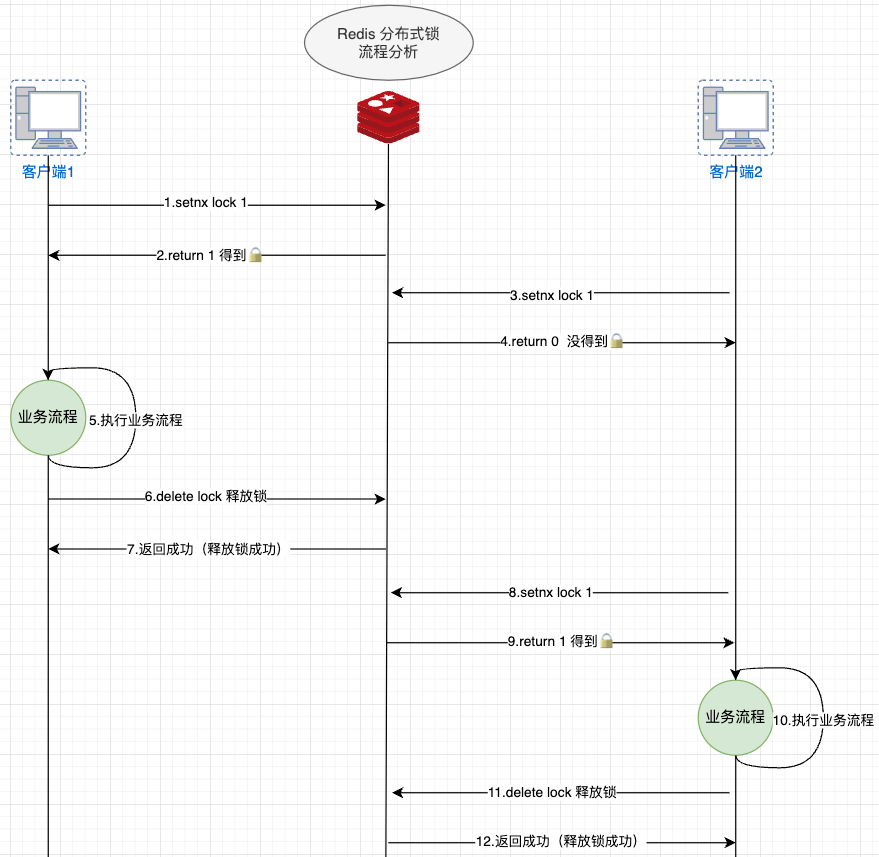
setnx =》确保互斥性(最简单的版本,但存在安全性问题:如果持有锁的客户端在执行过程中出现异常导致锁无法正确释放,就会造成死锁问题)
引入过期机制 =》确保安全性
方案1:setnx + expire
- 存在问题:无法确保两个指令操作的原子性,仍可能出现死锁问题
方案2:
SET lock_key lock_value NX PX 10000- 存在问题:由于业务执行时间过长,可能导致锁的误释放操作,进而破坏了锁的互斥性(A先获取锁执行业务流程,但执行过程中锁过期,此时B恰好获取到锁并执行业务流程,如果A执行完成后释放锁就会不小心把B的锁给释放掉,进而导致并发问题,导致分布式锁失效)
设置owner =》 确保对称性(谁申请谁释放原则)
- 实现方案:
SET lock_key lock_unique_value NX PX 10000在释放锁之前校验锁的归属者,如果归属于其他客户端则不做释放操作 - 存在问题:get lock 校验 和 del lock 操作是非原子操作,存在时间差攻击,可能出现校验的时候锁还是自己的,删除的时候却是其他客户端的。需通过Redis + Lua脚本确保操作的原子性
- 实现方案:
可靠性实现 =》确保可靠性,基于对单机部署可能出现的单点故障问题的解决方案
方案1:主从容灾(主从架构、哨兵模式)
- 存在问题:可能存在“从节点出现部分数据损失”、“分布式锁失效”、“出现短暂多机获取执行权限的情况”
- “从节点出现部分数据损失”:由于数据同步操作过程是一个异步过程,当主节点更新完成还未同步到从节点的过程中主节点宕机,则导致从节点出现部分数据损失的情况
- “分布式锁失效”:由于数据同步延时+主备切换导致,当A从主节点获取到锁但数据还未同步到从节点时主节点宕机,由于主备切换,未更新锁信息的从节点一旦上位成功称为新的主节点,当B从新主节点获取锁的时候就会获取成功,进而破坏了分布式锁的互斥性,导致分布式锁失效
- “出现短暂多机获取执行权限的情况”:由于上述问题,导致分布式锁失效,就会出现多个机器都获取到执行权限的问题
- 存在问题:可能存在“从节点出现部分数据损失”、“分布式锁失效”、“出现短暂多机获取执行权限的情况”
方案2:多机部署
redis分布式锁单点故障、可重入
除了redis还有哪些分布式锁方案(mysql、zk)
学习资料
分布式锁概念核心
分布式锁
在计算机领域,锁可以理解为针对某项资源使用权限的管理,它通常用来控制共享资源,比如一个进程内有多个线程竞争一个数据的使用权限,解决方式之一就是加锁。
分布式锁:分布式场景下的锁,比如多台不同机器上的进程,去竞争同一项资源,就是分布式锁。
分布式锁特性
互斥性:锁的目的是获取资源的使用权,要尽可能保证只让一个竞争者持有锁;
安全性:避免锁因为异常永远不被释放。当一个竞争者在持有锁期间内,由于意外崩溃而导致未能主动解锁,其持有的锁也能够被兜底释放,并保证后续其它竞争者也能加锁;
对称性:同一个锁,加锁和解锁必须是同一个竞争者。不能把其他竞争者持有的锁给释放了
可靠性:需要有一定程度的异常处理能力、容灾能力
而分布式锁的设计则是基于这4个特性进行扩展和优化,在剖析分布式锁实现原理的过程,可以结合这4个特性进行场景分析和扩展优化思考。所谓的场景分析,即分析分布式锁在分布式场景中经常会出现什么问题,如何解决:
- 可用问题:无论何时都要保证锁服务的可用性(这是系统正常执行锁操作的基础)
- 死锁问题:客户端一定可以获得锁,即使锁住某个资源的客户端在释放锁之前崩溃或者网络不可达(这是避免死锁的设计原则)
- 脑裂问题:集群同步时产生的数据不一致,导致新的进程有可能拿到锁,但之前的进程以为自己还有锁,那么就出现两个进程拿到了同一个锁的问题
分布式锁的常用实现方式
一般场景下,会依托第三方组件完成分布式锁设计。在MySQL-高可用篇-分布式锁中对分布式锁的实现方案有相应的介绍,此处针对的是Redis方案的详细剖析
Redis 实现分布式锁(setnx 方案)
1.setnx 方案核心
简化版本:借助 setnx 函数=>确保互斥性
Redis通常可以使用setnx(key, value)函数来实现分布式锁。key和value就是基于缓存的分布式锁的两个属性,其中key表示锁id,value = currentTime + timeOut,表示当前时间+超时时间。即某个进程获得key这把锁后,如果在value的时间内未释放锁,系统就会主动释放锁。
- setnx函数的返回值有0和1:
- 返回1:说明该服务器获得锁,setnx将key对应的value设置为当前时间 + 锁的有效时间
- 返回0:说明其他服务器已经获得了锁,进程不能进入临界区。该服务器可以不断尝试setnx操作,以获得锁
实现说明
加锁:SET lock_key unique_value NX PX 10000
- lock_key : key 键;
- unique_value :客户端生成的唯一的标识;
- NX :代表只在 lock_key 不存在时,才对 lock_key 进行设置操作;(用于保证当分布式锁不存在时,只有一个client能写入此key成功,获取到此锁)
- PX 10000 :表示设置 lock_key 的过期时间为 10s,用于避免客户端发生异常而无法释放锁
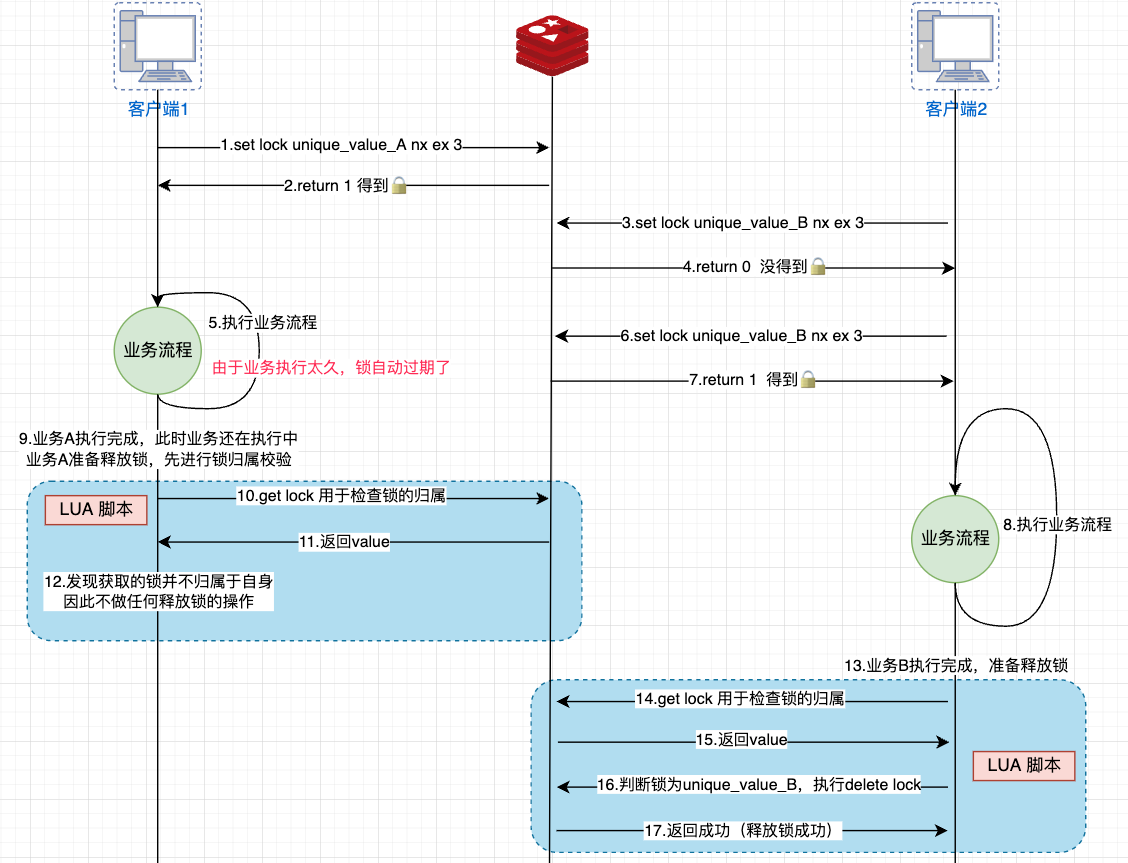
解锁:解锁的过程是将lock_key键删除,但不能乱删,必须保证执行加锁和解锁操作的客户端是同一个。此处则通过unique_value进行校验,借助LUA脚本判断unique_value是否为加锁客户端(选用 Lua 脚本是为了保证解锁操作的原子性)
// 释放锁时,先比较 unique_value 是否相等,避免锁的误释放
if redis.call("get",KEYS[1]) == ARGV[1] then
return redis.call("del",KEYS[1])
else
return 0
end
setnx 方案简化版本(
setnx lock 1)
2.setnx 方案简化版本优化
基于Redis方案的核心实现的简化版本,结合业务场景可能衍生的异常问题一步步进行优化。
🗄️支持过期时间=>确保安全性(避免死锁)
(1)超时机制的引入
最简化版本存在一个问题:如果获取锁的服务挂掉了,则锁一直得不到释放,就会导致其他客户端无法正常获取到锁,进而导致进程阻塞。因此需要通过引入超时机制进行兜底,即在加锁的同时设置锁的过期时间。
- 方案1:
setnx(加锁) + expire(设置过期时间),但这两条指令操作不具备原子性,仍然可能存在并发安全问题(例如setnx成功、expire失败,还是会回退到简化版本的问题) - 方案2:
SET lock_key lock_value NX PX 10000(过期时间单位设置:EX-单位秒、PX-单位毫秒)
(2)超时机制衍生问题
💊设置了超时时间为什么死锁问题还会存在?
解决方案:确保加锁命令和设置锁时间的操作是原子性
此处需要注意一个问题,在 Redis2.6.12 的之前的版本中,由于加锁命令和设置锁过期时间命令是两个操作(不是原子性的),当出现某个线程操作完成 setnx 之后,还没有来得及设置过期时间,线程就挂掉了,就会导致当前线程设置 key 一直存在,后续的线程无法获取锁,最终造成死锁的问题,所以要选型 Redis 2.6.12 后的版本或通过 Lua 脚本执行加锁和设置超时时间(Redis 允许将 Lua 脚本传到 Redis 服务器中执行, 脚本中可以调用多条 Redis 命令,并且 Redis 保证脚本的原子性)。
💊如何合理设置超时时间?
锁超时失效导致的误操作:通过超时时间来控制锁的失效时间并不太靠谱。比如在有些场景中,一个线程 A 获取到了锁之后,由于业务代码执行时间可能比较长(或者网络延迟、GC卡顿等问题),导致超过了锁的超时时间触发自动失效,后续线程 B 又意外的持有了锁,当线程 A 再次恢复后,通过 del 命令释放锁,就错误的将线程 B 中同样 key 的锁误删除了,就会导致其他并发线程有可乘之机,则失去了分布式锁独占资源的意义。
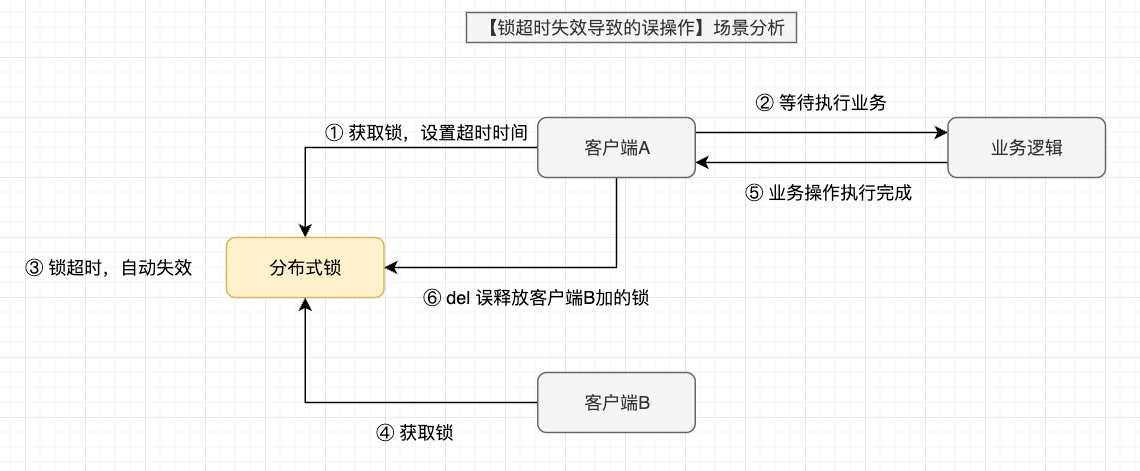
如果锁的超时时间设置过长,会影响性能,如果设置的超时时间过短,有可能业务阻塞没有处理完成,能否合理设置超时时间,是基于缓存实现分布式锁很难解决的一个问题。
如何合理设置超时时间呢? =》可以基于续约的方式设置超时时间:先给锁设置一个超时时间,然后启动一个守护线程,让守护线程在一段时间后,重新设置这个锁的超时时间。实现方式就是:写一个守护线程,然后去判断锁的情况,当锁快失效的时候,再次进行续约加锁,当主线程执行完成后,销毁续约锁即可。不过这种方式实现起来相对复杂,所以针对超时时间的设置,要站在实际的业务场景中进行衡量。
🗄️设置owner=>确保对称性
(1)设置owner
结合上述超时机制衍生场景问题分析,如果设置的超时时间不合理,就可能出现服务A误释放掉服务B的锁,进而导致一系列的并发问题。为了避免这种场景,除却上述基于续约的方式设置超时时间来确保服务完成才释放锁,还可通过设置owner的方式来明确规定分布式锁的归属,即分布式锁需满足谁申请谁释放的原则,不允许释放别人的锁。
演进方案:SET lock_key lock_value NX PX 10000 =》SET lock_key unique_value NX PX 10000,即确保此处的unique_value是唯一的,且在释放锁的时候需要相应校验该锁是否归属于自身。
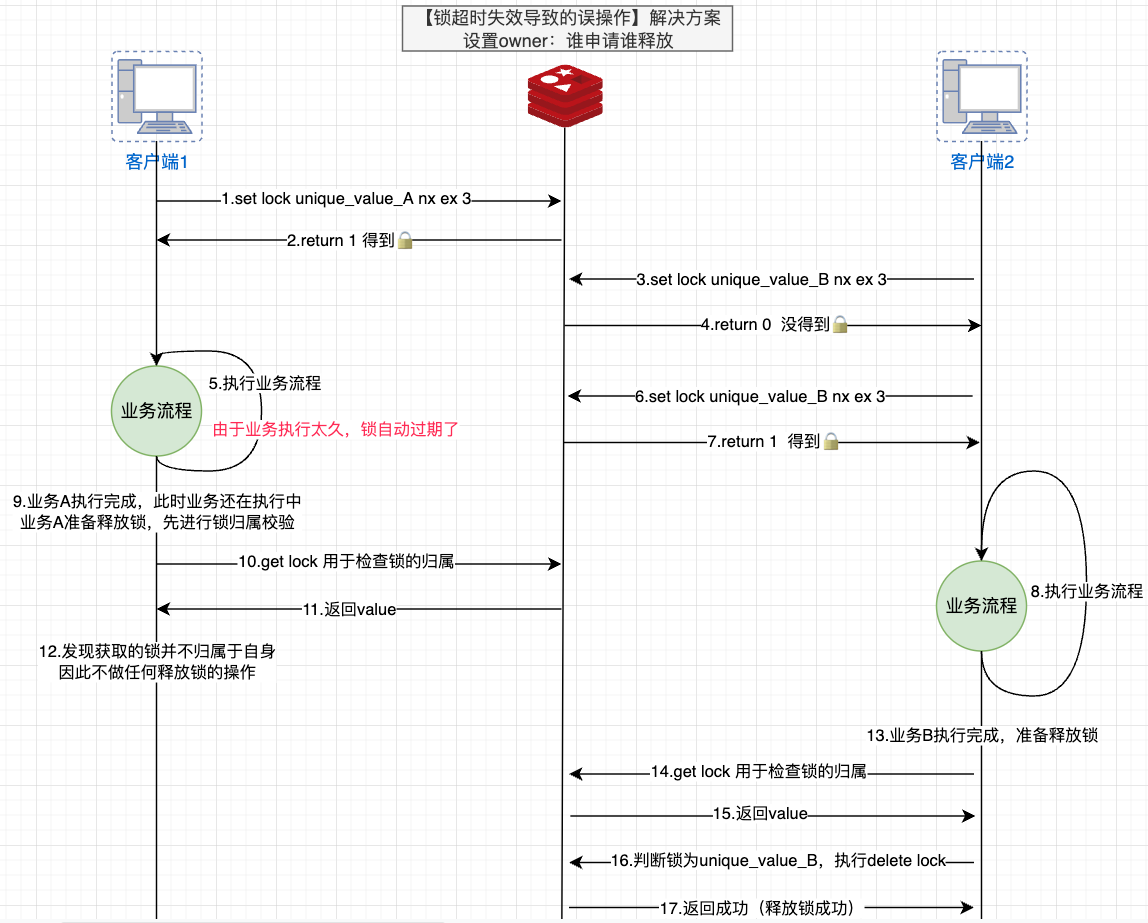
(2)衍生问题
获取/校验锁、释放锁操作的非原子性导致的并发问题:结合上述步骤分析,可以看到虽然通过设置owner可以规避误释放别人的锁的情况,但是由于这些操作并不是原子性的,因此还是会衍生出一系列并发问题。例如上述释放锁的操作过程是:先获取锁、检查锁、删除锁,但是这些操作并不是原子性的,则可能出现检查锁的时候是自己的,但是删除的时候却是别人的了(结合图示理解:步骤14检查锁归属于业务B,但是在其发送delete lock之前如果锁过期了,其他业务还是有机会拿到锁,这个时候业务B删除的就是其他业务的锁,进而导致并发异常),但目前Redis并没有设计一个提供这种场景原子化的操作,因此需要借助外界的辅助——Lua 脚本
Redis + Lua =》解决原子操作问题场景,有了Lua的特性,Redis才真正在分布式锁、秒杀等场景,有了用武之地,改造之后的流程分析如下:
🗄️可靠性的保证
基于上述优化,可以看到分布式锁构建的核心特性中互斥性、安全性、对称性都已满足,目前剩下可靠性需进一步优化解决。针对一些异常场景,例如Redis挂掉了、业务执行时间过程、网络波动等情况,分析其解决方案。
(1)容灾考虑
基于上述的案例场景,都是基于单机场景来考虑的,而单机场景最典型的就是单机故障问题。如果单机Redis挂掉了,则无法正常获取锁。一般针对单机故障的容灾方案有两种:主从容灾、多机部署
主从容灾(Redis 架构方案)
主从容灾是较为简单的一种方式,即为Redis配置从节点,当主节点挂了则用从节点顶上。
最基础的部署架构是主从复制,可为master配置多个从节点(可进一步通过划分等级的形式分散master的管理压力),但该模式下如果主节点出现故障需人工介入进行切换。为了减少人工操作的成本,Redis引入了哨兵模式来实现监听和自动转移故障,可以灵活自动切换而不需人工介入
主备切换导致的安全性问题
通过增加从节点的方式,虽然一定程度解决了单点的容灾问题,但并不是尽善尽美的,例如可能出现下述一些异常的情况的原因分析
- 从节点数据损失的原因:主从数据的同步操作是异步进行的,如果在主节点数据的更新操作还没有完全同步到从节点的过程中主节点崩溃了,则会导致部分从节点数据损失
- 分布式锁可能失效的原因:分布式锁可能失效的原因也是由于同步延迟+主备切换导致的。例如客户端A在主节点获取到锁,但如果此时锁的信息还没有同步到从节点,而主节点却挂掉了,由于主备切换机制,未同步到锁信息的从节点一旦上位成功变成主节点,此时客户端B请求获取锁也会成功,则此时就会导致不同的客户端获取到同一个资源的锁,进而导致分布式锁功能失效
- 短暂出现多机获取执行权限的情况的原因:基于上述同步延迟+主备切换导致分布式锁的互斥性被破坏,因此不同客户端会认为自己成功获取到锁,然后去执行自己的业务操作,就会短暂出现多机获取执行权限的情况
多机部署(Red Lock 算法)
Redis 如何解决集群情况下分布式锁的可靠性? => 引入RedLock算法
如果对一致性的要求更高,可以尝试多级部署。例如Redis的RedLock,大概的思路就是多个机器(通常是奇数个)达到一半以上同意加锁才算加锁成功。结合简单案例进行分析:假设有5个独立的Redis节点,基本保证它们不会同时宕掉,获取锁和释放锁的过程中,客户端会执行以下操作:
- 依次向5个Redis申请加锁;
- 只要超过一半,也就是3个Redis返回成功,那么就是获取到了锁。如果超过一半失败,需要向每个Redis发送解锁命令;
- 由于向5个Redis发送请求,会有一定时耗,所以锁剩余持有时间,需要减去请求时间(且如果剩余时间已经为0,也是获取锁失败);
- 使用完成之后,向5个Redis发送解锁请求;
返回失败概念:返回失败是一个泛概念,可能是Redis没有获取到锁,也可能是Redis获取到锁但是因为网络或者其他问题导致响应失败
为什么最后没成功的都要解锁?:因此此处的返回失败并不局限于加锁失败,有可能加锁成功但因为网络抖动导致响应失败,而最终针对所有Redis统一发送解锁请求可以理解为一种统一的补偿
此处引入多节点部署仅仅是为了增强可靠性,该模式并没有leader概念,会对每个节点都操作,其好处在于如果挂了2台Redis,整个集群还是可用的,可以给运维更多时间进行修复。
需注意此处的多机部署概念仅仅针对于加锁操作,不要陷入物尽其用的误区: 将多机部署理解为多个独立的单节点部署,它就是一种基于此场景的架构模式(不要将其和其他架构混淆对比),它的作用仅仅是为了增强分布式锁的可靠性,主要用于分布式锁,不要过于复杂化它的概念
客户端获取锁的流程:同时向多个机器申请加锁,超过半数响应成功后则认为成功获取到锁,此时则执行相应的业务流程操作(假设业务流程操作还涉及到Redis缓存相关的操作,此处执行业务操作应该回归到业务系统架构本身,而不是说又向多个Redis发起请求,执行多个重复的操作)。即需区分部署架构针对的业务场景,而不要陷入物尽其用的误区,不要认为采用了多机部署的方式,就将分布式锁场景和业务缓存操作都归于同一个部署架构(架构思维在不同场景可能具有适用性,但不是说所有场景复用同一套架构都能满足,需要区分业务场景进行设计),这是一种错误的惯性思维。最主要的是,不要去复杂化一个架构的场景应用,不同场景有相应的架构适应性适配,不要局限在物尽其用的误区,既要又要,就会复杂化架构设计,而陷入纠结
(2)可靠性深究
实际上不管是哪种方案,由于分布式系统中的三大困境问题(NPC),都无法实现完全可靠的分布式的分布式锁
- N:Network Delay(网络延迟)
- P:ProcessPause(进程暂停)
- C:Clock Drift (时钟漂移)
RedLock在NPC下的表现
N:Network Delay(网络延迟)
当分布式锁获得返回包的时间过长(响应时长),此时可能虽然加锁成功,但此时锁可能很快过期
RedLock 中会计算实际的锁剩余持有时间(需要减去请求时间),一定程度避免网络延迟问题的影响
P:ProcessPause(进程暂停)
比如发生GC,获取锁之后GC了,处于GC执行中,然后锁超时。即机器A竞争锁成功,此时却发生了GC(GC期间锁超时了),此时机器B申请锁会成功获取到锁,则会出现两个机器获取到同一个锁,破坏了分布式锁的互斥性:
- 机器A先获取到锁,但发生GC期间锁失效了,等待GC完成,机器A此时会认为自己还拥有锁,于是继续执行业务操作
- GC结束后,机器B尝试获取锁发现可以获取成功,执行业务操作
此处如果想要破局或许会想到,在GC完成之后让机器A再确认一遍是不是还拥有锁进而决定是否继续执行业务操作,这点理论上是可行的,但是却存在两个难点:
- 无法明确GC完成的时间点:如果要强制通过时间做粗略判断,这种思路很吃场景经验,实现上存在难度
- GC完了又GC:如果能拿捏上面一点,判断的时候是ok的,但是判断完之后又发生GC了,基于这点RedLock是无法解决的
C:Clock Drift (时钟漂移)
如果竞争者A,获得了RedLock,在5台分布式机器上都加上锁。为了方便分析,直接假设5台机器都发生了时钟漂移,锁瞬间过期了。此时竞争者B拿到了锁,此时A和B拿到了相同的执行权限。
根据上述的分析,可以看出RedLock也不能抗住NPC的挑战,因此,单单从分布式锁本身出发,要做到完全可靠是不可能的。且RedLock这种方案本身比较重,在实际生产场景中应用并不多。要实现一个相对可靠的分布式锁机制,还是需要和业务的配合,业务本身要幂等可重入,这样的设计可以省却很多麻烦。
3.Redis 分布式锁实现(基于JAVA版本)
todo:https://www.cnblogs.com/x-kq/p/14801102.html (其他文档实现)
Redis 实现可重入锁
基于上述Redis实现分布式锁的方案,会发现其存在一个问题,即它不可重入。
重入锁 VS 不可重入锁
所谓不可重入锁,即若当前线程执行某个方法已经获取了该锁,那么在方法中尝试再次获取锁时(例如调用了其他的方法),会因为获取不到锁而被阻塞。可以理解为对于同一个客户端成功获取了锁 ,对于同一个锁却只能拿1次而不能拿多次(对于同一把锁的访问需等到锁释放后再重新获取,对于同一个客户端而言就会略显鸡肋)
可重入锁(递归锁):指的是在同一线程内,外层函数获得锁之后,内层递归函数仍然可以获取到该锁。 即同一个线程再次进入同样代码时,可以再次拿到该锁。 它的作用是:防止在同一线程中多次获取锁而导致死锁发生
// 可重入理解:假设 X 线程在 a 方法获取锁之后,继续执行 b 方法,如果此时不可重入,线程就必须等待锁释放,再次争抢锁。锁明明是被 X 线程拥有,却还需要等待自己释放锁,然后再去抢锁,这看起来就很奇怪,我释放我自己?
public synchronized void a() {
b();
}
public synchronized void b() {
// pass
}
1.JAVA中的重入锁
在java的编程中synchronized 和 ReentrantLock都是可重入锁。可以参考ReentrantLock的代码
import lombok.extern.slf4j.Slf4j;
import java.util.concurrent.locks.ReentrantLock;
@Slf4j
public class ReentrantLockDemo {
// 锁
private static ReentrantLock lock = new ReentrantLock();
public void doSomething(int n){
try{
// 进入递归第一件事:加锁
lock.lock();
log.info("--------lock()执行后,getState()的值:{} lock.isLocked():{}",lock.getHoldCount(),lock.isLocked());
log.info("--------递归{}次--------",n);
if(n<=2){
this.doSomething(++n);
}else{
return;
}
}finally {
lock.unlock();
log.info("--------unlock()执行后,getState()的值:{} lock.isLocked():{}",lock.getHoldCount(),lock.isLocked());
}
}
public static void main(String[] args) {
ReentrantLockDemo reentrantLockDemo=new ReentrantLockDemo();
reentrantLockDemo.doSomething(1);
log.info("执行完doSomething方法 是否还持有锁:{}",lock.isLocked());
}
}
# output
结合原理理解ReentrantLock的实现
// ReentrantLock加锁流程分析:
1.先判断是否有线程持有锁,没有加锁进行加锁
2.如果加锁成功,则设置持有锁的线程是当前线程
3.如果有线程持有了锁,则再去判断,是否是当前线程持有了锁
4.如果是当前线程持有锁,则加锁数量(state)+1
final boolean nonfairTryAcquire(int acquires) {
final Thread current = Thread.currentThread();
int c = getState();
//先判断,c(state)是否等于0,如果等于0,说明没有线程持有锁
if (c == 0) {
//通过cas方法把state的值0替换成1,替换成功说明加锁成功
if (compareAndSetState(0, acquires)) {
//如果加锁成功,设置持有锁的线程是当前线程
setExclusiveOwnerThread(current);
return true;
}
}
else if (current == getExclusiveOwnerThread()) {//判断当前持有锁的线程是否是当前线程
//如果是当前线程,则state值加acquires,代表了当前线程加锁了多少次
int nextc = c + acquires;
if (nextc < 0) // overflow
throw new Error("Maximum lock count exceeded");
setState(nextc);
return true;
}
return false;
}
// ReentrantLock释放锁流程分析:
每次释放锁的时候都对state减1,
当c值等于0的时候,说明锁重入次数也为0了,
最终设置当前持有锁的线程为null,state也设置为0,锁就释放了。
// 释放锁
protected final boolean tryRelease(int releases) {
int c = getState() - releases;//state-1 减加锁次数
//如果持有锁的线程,不是当前线程,抛出异常
if (Thread.currentThread() != getExclusiveOwnerThread())
throw new IllegalMonitorStateException();
boolean free = false;
if (c == 0) {//如果c==0了说明当前线程,已经要释放锁了
free = true;
setExclusiveOwnerThread(null);//设置当前持有锁的线程为null
}
setState(c);//设置c的值
return free;
}
2.Redis如何实现可重入分布式锁?
Redis 如何实现可重入操作?
结合ReentrantLock的实现原理分析可知,如果是基于上述set实现分布式锁方案,Redis只要解决两个问题即可实现可重入锁:
- 怎么保存当前持有的线程
- 用value值存储当前线程ID(但需确保唯一性),如果是集群环境下线程ID重复,则可在项目启动时生成一个全局进程id,使用进程id+线程id 确保唯一性
- 加锁次数(重入了多少次),怎么记录维护
- 加锁记录的存储:value值存储格式设置为【进程id+线程id+加锁次数】
- 加锁记录的维护:无法通过java代码确保这两个步骤的原子性
- 步骤1:先获取到value值,加锁次数+1
- 步骤2:设置新值
在执行步骤2之前,如果这个key失效了(设置持有锁超时),如果还能再设置进去,就会有并发问题
SET是不支持重入锁的,目前对于redis的重入锁业界还是有很多解决方案的,当前比较流行的就是采用Redisson。
Redisson (Redis Hash可重入锁)
Redisson作为一个分布式锁,它不仅是一个可重入锁,还提供了重试机制和WatchDog机制(自动续期),即其具有如下特性:
- 可重入:利用 hash 结构记录线程 id 和重入次数
- 可重试:利用信号量和 PubSub 功能实现等待、唤醒,获取锁失败的重试机制
- 超时续约:利用 watchDog,每隔一段时间(releaseTime / 3),重置超时时间
此处介绍其可重入特性,Redisson 类库就是通过 Redis Hash 来实现可重入锁:
- 当线程拥有锁之后,往后再遇到加锁方法,直接将加锁次数加 1,然后再执行方法逻辑
- 退出加锁方法之后,加锁次数再减 1,当加锁次数为 0 时,锁才被真正的释放
可重入锁大特性就是计数,计算加锁的次数。所以当可重入锁需要在分布式环境实现时,需要统计加锁次数
加锁逻辑(Redis hash结构存储,借助lua脚本确保操作的原子性)
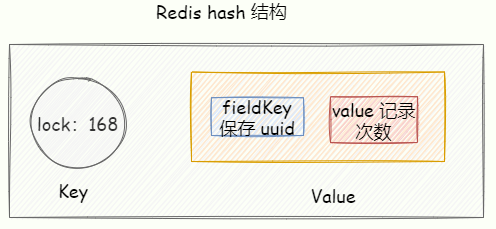
用 Redis hash 结构实现,key 表示被锁的共享资源, hash 结构的 fieldKey 的 value 则保存加锁的次数
if (redis.call('exists', KEYS[1]) == 0) then
redis.call('hincrby', KEYS[1], ARGV[2], 1);
redis.call('pexpire', KEYS[1], ARGV[1]);
return 1;
end ;
if (redis.call('hexists', KEYS[1], ARGV[2]) == 1) then
redis.call('hincrby', KEYS[1], ARGV[2], 1);
redis.call('pexpire', KEYS[1], ARGV[1]);
return 1;
end ;
return ;
加锁代码首先使用 Redis exists 命令判断当前 lock 这个锁是否存在
- 如果锁不存在的话,直接使用
hincrby创建一个键为lockhash 表,并且为 Hash 表中键为uuid初始化为 0,然后再次加 1,后再设置过期时间 - 如果当前锁存在,则使用
hexists判断当前lock对应的 hash 表中是否存在uuid这个键,如果存在,再次使用hincrby加 1,后再次设置过期时间 - 如果上述两个逻辑都不符合,直接返回
解锁逻辑
if (redis.call('hexists', KEYS[1], ARGV[1]) == ) then
return nil;
end ;
-- 计算当前可重入次数
local counter = redis.call('hincrby', KEYS[1], ARGV[1], -1);
-- 小于等于 代表可以解锁
if (counter > ) then
return ;
else
redis.call('del', KEYS[1]);
return 1;
end ;
return nil;
首先使用 hexists 判断 Redis Hash 表是否存给定的域
- 如果 lock 对应 Hash 表不存在,或者 Hash 表不存在 uuid 这个 key,直接返回
nil - 若存在的情况下,代表当前锁被其持有,首先使用
hincrby使可重入次数减 1 ,然后判断计算之后可重入次数,若小于等于 0,则使用del删除这把锁。
解锁代码执行方式与加锁类似,只不过解锁的执行结果返回类型使用 Long。这里之所以没有跟加锁一样使用 Boolean ,这是因为解锁 lua 脚本中,三个返回值含义如下:
- 1 代表解锁成功,锁被释放
- 0 代表可重入次数被减 1
null代表其他线程尝试解锁,解锁失败.
分布式锁的其他方案
可以参考此前MySQL篇章学习中对分布式锁的介绍,以及相关方案的实现