MySQL-基础篇-数据类型
MySQL-基础篇-数据类型
学习核心
- 掌握MySQL数据类型
- 拆解常见数据类型在实际场景中的应用
学习资料
MySQL数据类型
数据类型分类
- 字符串类型
- 数字类型
- 日期和时间类型
- 二进制类型
- 地理位置数据类型
- JSON 数据类型
1.字符串类型
| 字符串类型 | 描述 |
|---|---|
VARCHAR | 纯文本字符串,字符串长度是可变的 |
CHAR | 纯文本字符串,字符串长度是固定的。当实际字段内容小于定义的长度时, MySQL SQL 会用空白空白符好补足 |
VARBINARY | 二进制字符串,字符串长度是可变的 |
BINARY | 二进制字符串,字符串长度是固定的 |
TINYTEXT | 二进制字符串,最大为 255 个字节 |
TEXT | 二进制字符串,最大为 65K |
MEDIUMTEXT | 二进制字符串,最大为 16M |
LONGTEXT | 二进制字符串,最大为 4G |
ENUM | 枚举;每个列值可以分配一个 ENUM 成员 |
SET | 集合;每个列值可以分配零个或多个 SET 成员 |
2.数字类型
数字是一个常用的数据类型。如果要存储年龄、金额等,需要用到数字数据类型。 MySQL SQL 支持 SQL 标准中所有的数字类型,包括整数和小数。下表显示了 MySQL 中数字相关的数据类型:
| 数字类型 | 描述 |
|---|---|
TINYINT | 一个非常小的整数,最大为 1 个字节 |
SMALLINT | 一个小整数,最大为 2 个字节 |
MEDIUMINT | 一个中等大小的整数,最大为 3 个字节 |
INT | 标准整数,最大为 4 个字节 |
BIGINT | 一个大整数,最大为 8 个字节 |
DECIMAL | 一个定点数 |
FLOAT | 单精度浮点数,最大为 4 个字节 |
DOUBLE | 双精度浮点数,最大为 8 个字节 |
BIT | 按位存储 |
MySQL的布尔数据类型
MySQL没有内置布尔数据类型,但是MySQL支持BOOLEAN或BOOL关键字,会将该类型转换为TINYINT(1)。当插入true或者false时,MySQL会将其对应存储为1或者0
3.日期和时间类型
MySQL 提供了丰富的日期和时间类型,可用于跟踪表中一行的变化
| 日期和时间类型 | 描述 |
|---|---|
DATE | CCYY-MM-DD 格式的日期值 |
TIME | hh:mm:ss 格式的时间值 |
DATETIME | CCYY-MM-DD hh:mm:ss 格式的日期和时间值 |
TIMESTAMP | CCYY-MM-DD hh:mm:ss 格式的时间戳值 |
YEAR | CCYY 或 YY 格式的年份值 |
4.二进制类型
MySQL 支持存储二进制数据(例如图片文件等),如果要存储文件则需要使用到BLOB类型(binary large object,二进制大对象)
| 二进制类型 | 描述 |
|---|---|
TINYBLOB | 最大为 255 个字节 |
BLOB | 最大为 65K |
MEDIUMBLOB | 最大为 16M |
LONGBLOB | 最大为 4G |
5.地理位置数据类型(空间数据类型)
| 空间数据类型 | 描述 |
|---|---|
GEOMETRY | 任何类型的空间值 |
POINT | 使用横坐标和纵坐标表示的一个点 |
LINESTRING | 一条曲线(一个或多个 POINT 值) |
POLYGON | 一个多边形 |
GEOMETRYCOLLECTION | GEOMETRY 值的集合 |
MULTILINESTRING | LINESTRING 值的集合 |
MULTIPOINT | POINT 值的集合 |
MULTIPOLYGON | POLYGON 值的集合 |
6.JSON 数据类型
MySQL从5.7.8版本开始支持JSON数据类型,允许更有效地存储和管理JSON文档。与 JSON 格式的字符串相比,MySQL提供的原生 JSON 数据类型提供有如下的优点:
- 自动验证:MySQL会对存储在JSON列中的JSON文档进行自动验证,无效的文档会产生错误
- 最佳存储格式:MySQL会将存储在JSON列中的JSON文档转换为允许快速读取文档元素的内部格式
常用数据类型
1.VARCHAR
VARCHAR 是可变长度的字符串类型。当一个列的类型定义为 VARCHAR 类型后,列中的内容的长度就是内容本身的长度(字符数)。
# 定义时指定最大长度,如果不指定默认是255
VARCHAR(max_length)
MySQL 存储 VARCHAR 数值时,会将最前的 1 或者 2 个字节存储为实际字符串内容的长度。如果列的值少于 255 个字节,则长度前缀为 1 个字节,否则为 2 个字节。
VARCHAR 允许的最大长度为 65535 个字节,这也是 MySQL 中的行大小的限制。在 MySQL 中,除了 TEXT 和 BLOB 列, 行大小限制为 65535 个字节。
一个 VARCHAR 列中能够存储多少个字符还和数据库使用的字符集有关
建表实例说明
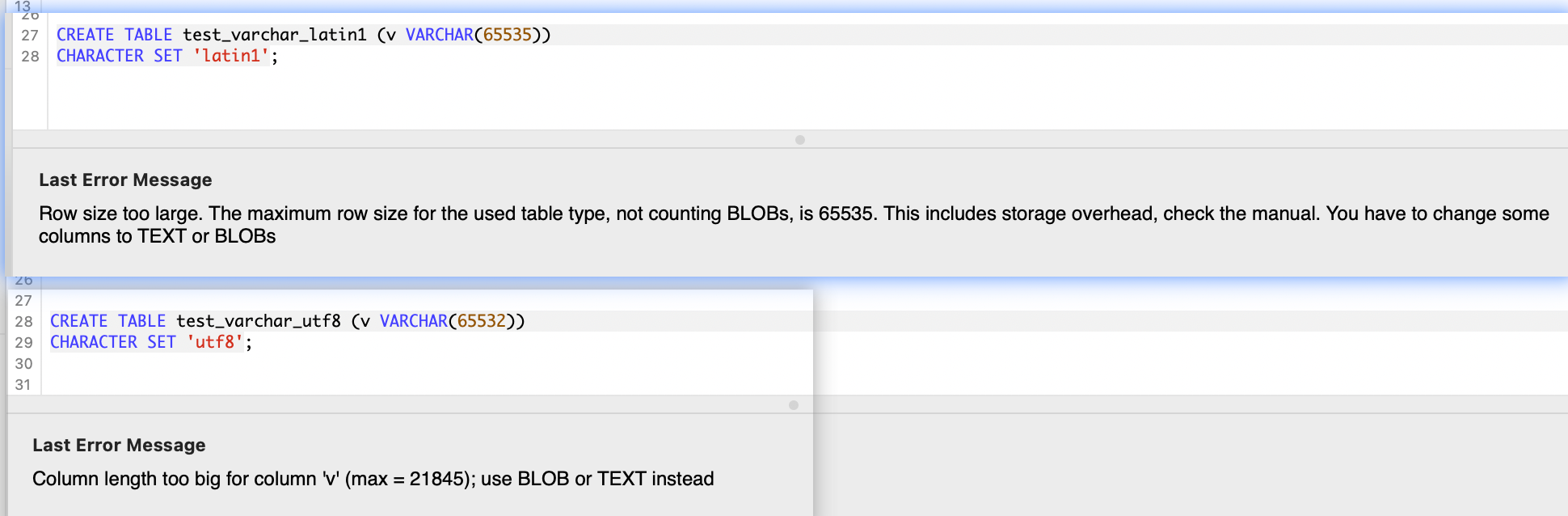
# 错误示例1:指定的错误的最大长度
CREATE TABLE test_varchar_latin1 (v VARCHAR(65535))
CHARACTER SET 'latin1';
-- 分析:因为长度指定大于255个字节,因此需要用2个字节用作长度前缀,此处最大设定为65532
# 错误示例2:指定字符集
CREATE TABLE test_varchar_utf8 (v VARCHAR(65532))
CHARACTER SET 'utf8';
-- 分析:因为每个utf8字符最多占用3个字节,因此长度设定最长为65535/3=21845 =>24844
VARCHAR 截断内容
当插入的内容超过 VARCHAR 列定义的长度时,MySQL 会采用如下策略:
- 如果超过的部分只包含空格,则多余的空格会被截断
- 如果超过的部分不只是空格,则给出错误提示
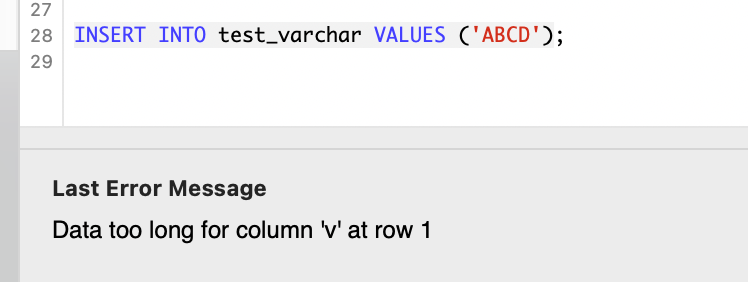
# 创建表进行测试
CREATE TABLE test_varchar (v VARCHAR(2))
CHARACTER SET 'latin1';
# 插入字符’A ‘(包含两个空格,总长度为3) => 数据正常插入,超出长度的空格被截断
INSERT INTO test_varchar VALUES ('A ');
# 插入字符’ABCD‘(总长度为4) => 数据无法插入,提示错误
INSERT INTO test_varchar VALUES ('ABCD');
2.CHAR
CHAR存储的是固定长度的字符类型,当一个列的类型定义为 CHAR 类型后,列中的内容的长度就是字段定义的长度(字符数)。
# 语法
CHAR(length)
length是一个数值,它指示了此列的字符数length可以是0到255之间的任何值- 如果不指定此值,则默认值是
1。也就是说CHAR等同于CHAR(1)。
如果写入 CHAR 列中的字符串的长度小于指定的字符长度,MySQL 会在源字符串后填充空格一直到指定的长度。当读取 CHAR 列中的值时,MySQL 会删除后面的空格。由于 CHAR 数据类型采用固定的长度进行存储,因此 CHAR 的性能要比 VARCHAR 更好
CREATE TABLE test_char (name char(5) NOT NULL);
INSERT INTO test_char VALUES ('Harve'), ('Tim');
SELECT name, LENGTH(name) FROM test_char;
# 当插入一个超过指定长度的CHAR值,MySQL不会自动截断字符串,会直接提示错误
INSERT INTO test_char VALUES('Steven');
需注意MySQL在读取数据的时候会删除值后面的空格内容,不论这个空格是否为原来的,即MySQL会自动忽略字符串尾部的空格。因此当设定CHAR为唯一列的时候,需注意忽略空格所带来的影响
3.INT
INT 和 INTEGER 是整数数据类型。为了更高效的存储不同长度的数字,MySQL 支持几种不同的整数数据类型: INT, SMALLINT, TINYINT, MEDIUMINT 和 BIGINT。下表展示了不同的整数类型的字节数和数值范围:
| 类型 | 字节数 | 最小值 | 最大值 | 最小值(无符号) | 最大值(无符号) |
|---|---|---|---|---|---|
TINYINT | 1 | -128 | 127 | 0 | 255 |
SMALLINT | 2 | -32768 | 32767 | 0 | 65535 |
MEDIUMINT | 3 | -8388608 | 8388607 | 0 | 16777215 |
INT | 4 | -2147483648 | 2147483647 | 0 | 4294967295 |
BIGINT | 8 | -263 | 263-1 | 0 | 264-1 |
# 语法
# UNSIGNED 标识此数据类型为无符号整数
INT [UNSIGNED]
INT(display_width) ZEROFILL
MySQL INT数据类型
INT数据类型列用于存储整数(例如年龄、数量等),可以结合AUTO_INCREMENT作为主键列
# 基本语法
CREATE TABLE test_int(
name char(30) NOT NULL,
age INT NOT NULL
);
# INT 和 INTEGER 是同义词,上述语句可以用INTEGER代替
# INT 与 AUTO_INCREMENT 结合使用(使用INT列作为自增列),ID列会自动生成
CREATE TABLE test_int_pk(
id INT AUTO_INCREMENT PRIMARY KEY,
name char(30) NOT NULL,
age INT NOT NULL
);
格式化需求:MySQL 为 INT 数据类型提供了显示宽度和 ZEROFILL 属性,主要用于格式化显示数字。从 MySQL 8.0.17 开始,显示宽度和 ZEROFILL 属性都不再建议使用,并且会在将来的版本中删除。如果有类似的格式化需求,可以使用LPAD()函数实现
# ZEROFILL(插入数据如果未达到定长则会在不影响原值的情况下用0去自动填充)
CREATE TABLE test_int_zerofill(
v2 INT(2) ZEROFILL,
v3 INT(3) ZEROFILL,
v4 INT(4) ZEROFILL
);
MySQL无符号整数数据类型
如果不希望输入负数,可以使用无符号整数类型。无符号类型的列只接受 0 和 正整数。当向一个无符号整数列插入负数时, MySQL 会返回错误提示
CREATE TABLE test_int_unsigned(
v INT UNSIGNED
);
# 插入负数错误
INSERT INTO test_int_unsigned VALUES (-1);
4.DECIMAL
DECIMAL 数据类型是定点数数据类型,用来存储精确的数值,比如账务金额等。底层实现上,MySQL 使用二进制形式存储该类型的值
DECIMAL[(M[,D])] [UNSIGNED] [ZEROFILL]
# 参考示例
amount DECIMAL(9, 4); =》 amount列的值范围是-99999.9999到99999.9999
amount DECIMAL(9); =》 amount列的值范围是-999999999到999999999
M是总的位数,不包含小数点和正负号D是小数部分的位数。如果D为0则表示没有小数部分。当D省略时,默认值为0UNSIGNED属性表示数值是无符号的。无符号的数字不能是负数ZEROFILL属性表示当整数部分位数不足时,用整数的左侧用0填充。带有ZEROFILL的列将自动具有UNSIGNED属性
DEC, NUMERIC, FIXED 是 DECIMAL 的同义词
DECIMAL实例
# 创建数据表
CREATE TABLE customer_balance (
id INT AUTO_INCREMENT PRIMARY KEY,
name VARCHAR(255),
balance DECIMAL(14, 4) NOT NULL
);
# 插入数据
INSERT INTO customer_balance(name, balance)
VALUES ('Tim', 1500.04),
('Jim', 10000),
('Tom', 333333.4);
# 检索数据
SELECT * FROM customer_balance;
# 更改数据表使其具有ZEROFILL属性,然后再次查询金额,可以看到不足位数自动用0填充
ALTER TABLE customer_balance MODIFY balance DECIMAL(14, 4) ZEROFILL NOT NULL;
SELECT * FROM customer_balance;
5.BIT
MySQL 中 BIT 数据类型被用来存储二进制的位值。通常使用 BIT 数据类型的列存储状态值,比如布尔值等。 BIT 数据类型也是易于扩展的
# 语法
BIT(M)
# BIT字面值:当需要向 BIT 列中插入 BIT 值时,需要使用 BIT 字面量。 BIT 字面量可以使用如下格式:此处val是二进制值,进包括0、1
b'val'
B'val'
0bval
BIT(M)允许存储M位值。M的取值范围是1到64- 如果不指定
M,那么它的默认值为1。BIT等效于BIT(1)
BIT 实例场景
BIT 列非常适合用来存储状态值。在下例子中,创建一个订单状态表 order_state,表中包含了一个用来存储订单状态的 state 列。此处预设订单有如下状态
| 状态 | 状态十进制值 | 状态二进制值 |
|---|---|---|
| 待支付 | 0 | 000 |
| 已支付 | 1 | 001 |
| 待发货 | 2 | 010 |
| 已发货 | 3 | 011 |
| 已完成 | 4 | 100 |
此处二进制的最大位数为3位,则state列的数据类型定义可为state BIT(3)
CREATE TABLE order_state (
order_id INT NOT NULL PRIMARY KEY,
state BIT(3) NOT NULL
);
INSERT INTO order_state (order_id, state)
VALUES (1, 3),
(2, b'011'),
(3, B'011'),
(4, 0b011);
SELECT * FROM order_state;
# 进制转化(如果希望让输出结果可读性强一点,可以使用函数或者表达式转化为进制显示)
BIN() 转为二进制
OCT() 转为八进制
HEX() 转为十六进制
state+0 转为十进制
# 进制转化示例
SELECT order_id,
state + 0,
BIN(state),
OCT(state),
HEX(state)
FROM order_state;
# 将BIT列作为where子句中的过滤条件,可以使用其对应的十进制或者BIT面值
SELECT * FROM order_state WHERE state = 3;
SELECT * FROM order_state WHERE state = (3);
SELECT * FROM order_state WHERE state = b'011';
SELECT * FROM order_state WHERE state = B'011';
SELECT * FROM order_state WHERE state = 0b011;
6.DATE
MySQL DATE 使用 yyyy-mm-dd 格式来存储日期值。如果想以其他的日期格式显示,比如 mm-dd-yyyy,可以使用 DATE_FORMAT 函数将日期格式化为您需要的格式。MySQL DATE 类型值的范围从 1000-01-01 到 9999-12-31。当向 DATE 列中插入值时,可以使用 yyyy-mm-dd 或者 yy-mm-dd 格式。
在严格模式下,您不能插入无效日期,比如:2018-08-32。否则 MySQL 会给出错误。在非严格模式下,MySQL 会将无效日期转为 0000-00-00。
# 语法
column_name DATE;
MySQL日期实例
如果使用两位数的年份值,MySQL 仍然按照以下规则将它转为四位数的年份值:虽然规则时明确的,但是,具有两位数的日期值可读性较差,因此应该避免使用两位数的年份
00-69范围内的年份值将转换为2000-206970-99范围内的年份值将转换为1970-1999
CREATE TABLE test_date (
id INT AUTO_INCREMENT PRIMARY KEY,
created_date DATE NOT NULL
);
# 如果插入错误日期的语句,MySQL会提示错误
INSERT INTO test_date(created_date) VALUES ('2008-02-30');
MySQL DATE函数
MySQL 提供了许多有用的日期函数,允许有效地操作日期。以下列出了常用的日期函数:
NOW(): 获取当前日期和时间CURDATE(): 获取当前日期DATE(): 获取日期部分DATE_FORMAT(): 格式化输出日期DATEDIFF(): 计算两个日期之间的天数DATE_ADD(): 在给定日期上增加给定的时间间隔DATE_SUB(): 在给定日期上减少给定的时间间隔DAY(): 返回日期中天MONTH(): 返回月份QUARTER(): 返回季节YEAR(): 返回年份WEEK(): 函数返回给定日期是一年周的第几周WEEKDAY(): 函数返回工作日索引WEEKOFYEAR(): 函数返回日历周
# NOW()获取当前日期和时间
SELECT NOW();
# CURDATE() 获取获取当前系统日期
SELECT CURDATE();
# DATE() 函数用来返回一个日期或者日期时间值的日期部分
SELECT DATE(NOW());
# DATE_FORMAT() 格式化日期
SELECT DATE_FORMAT(CURDATE(), '%m/%d/%Y') today;
# DATEDIFF()要计算两个日期值之间的天数
SELECT DATEDIFF('2021-01-01','2022-01-01') days;
# DATE_ADD() 函数用于将天数、周数、月数、年数等添加到给定的日期值
SELECT CURDATE() `今天`,
DATE_ADD(CURDATE(), INTERVAL 1 DAY) '一天后',
DATE_ADD(CURDATE(), INTERVAL 1 WEEK) '一周后',
DATE_ADD(CURDATE(), INTERVAL 1 MONTH) '一月后',
DATE_ADD(CURDATE(), INTERVAL 1 YEAR) '一年后';
# DATE_SUB() 被用于从日期中减去一个时间间隔
SELECT CURDATE() `今天`,
DATE_SUB(CURDATE(), INTERVAL 1 DAY) '一天前',
DATE_SUB(CURDATE(), INTERVAL 1 WEEK) '一周前',
DATE_SUB(CURDATE(), INTERVAL 1 MONTH) '一月前',
DATE_SUB(CURDATE(), INTERVAL 1 YEAR) '一年前';
# DAY, MONTH, QUARTER, YEAR:获取日期的日、月、季度、年份等信息
SELECT DAY(CURDATE()) `day`,
MONTH(CURDATE()) `month`,
QUARTER(CURDATE()) `quarter`,
YEAR(CURDATE()) `year`;
# WEEK, WEEKDAY, WEEKOFYEAR:分别返回日期的周数、工作日索引、日历周
SELECT WEEKDAY(CURDATE()) `weekday`,
WEEK(CURDATE()) `week`,
WEEKOFYEAR(CURDATE()) `weekofyear`;
7.DATETIME
MySQL中使用DATETIME存储包含日期和时间的值,其查询显示默认格式为YYYY-MM-DD HH:MM:SS(默认情况下该值范围为 1000-01-01 00:00:00 到 9999-12-31 23:59:59)
一个 DATETIME 值使用 5 个字节进行存储。此外,一个 DATETIME 值可以包括一个尾随小数秒,格式为: YYYY-MM-DD HH:MM:SS[.fraction]。 例如, 2015-12-20 10:01:00.999999 。当包括小数秒精度时, DATETIME 值需要更多的存储空间,如下表所示:
| 小数秒精度 | 存储(字节) |
|---|---|
| 0 | 0 |
| 1、2 | 1 |
| 3、4 | 2 |
| 5、6 | 3 |
例如, 2015-12-20 10:01:00.999999 需要 8 个字节,5 个字节用于 2015-12-20 10:01:00 和 3 个字节用于 .999999。 而 2015-12-20 10:01:00.9 只需要 6 个字节,1 个字节用于小数秒精度。需注意在 MySQL 5.6.4 之前, DATETIME 值需要 8 个字节的存储空间,而不是 5 个字节
MySQL 日期时间 VS 时间戳
MySQL 提供了另一种类似于 DATETIME 的 时间数据类型 TIMESTAMP
占用空间:
TIMESTAMP需要 4 个字节,而DATETIME需要 5 个字节。TIMESTAMP和DATETIME二者都需要额外字节存储小数秒值范围:
TIMESTAMP值范围从1970-01-01 00:00:01 UTC到2038-01-19 03:14:07 UTC。如果要存储超过 2038 年的时间值,则应使用DATETIME代替TIMESTAMP时区存储:MySQL
TIMESTAMP以 UTC 值存储。但是,MySQL 将DATETIME值按原样存储,没有时区
在实际业务场景应用中,如果服务器的时区不同,则数据类型为TIMESTAMP的列读取的时候会根据时区进行调整(DATETIME存储的是时间数据,而TIMESTAMP会根据时区调整),也就意味着需要考虑数据库移动到不同时区的服务器的场景
# 案例1:时区切换问题
CREATE TABLE timestamp_n_datetime (
id INT AUTO_INCREMENT PRIMARY KEY,
ts TIMESTAMP,
dt DATETIME
);
INSERT INTO timestamp_n_datetime(ts,dt) VALUES(NOW(),NOW());
# 切换时区测试
SET time_zone = '+03:00';
SELECT ts, dt FROM timestamp_n_datetime;
# --------------------------------------------------------------------------------
# 案例2:日期、时间函数应用
CREATE TABLE test_datetime (
id INT AUTO_INCREMENT PRIMARY KEY,
created_at DATETIME
);
INSERT INTO test_datetime(created_at) VALUES('2015-11-05 14:29:36');
# DATE函数 返回指定的日期
SELECT * FROM test_datetime WHERE DATE(created_at) = '2015-11-05';
# TIME 从DATETIME值中提取时间部分
SELECT TIME(created_at) from test_datetime;
# MySQL YEAR、QUARTER、MONTH、WEEK、DAY、HOUR、MINUTE 和 SECOND 函数:分别对应获取DATETIME值的年、季度、月、周、日、小时、分钟、秒
SET @dt = NOW();
SELECT
YEAR(@dt),
QUARTER(@dt),
MONTH(@dt),
WEEK(@dt),
DAY(@dt),
HOUR(@dt),
MINUTE(@dt),
SECOND(@dt);
8.YEAR
在 MySQL 中, YEAR 数据类型用来存储年份值。
YEAR 数据类型占用1个字节,YEAR值的范围为从 1901到 2155,还有 0000.
定义为 YEAR 数据类型的列可以接受多种输入格式,包括:
- 4 位数字的年份值,从 1901 to 2155
- 4 位数字的年份值的字符串形式,从'1901'到'2155'
- 2 位数字的年份值,从0到99,并按如下规则转换为 4位数年份:
- 1到 69 转换为 2001到2069
- 70 到 99 转换为 1970到 1999
- 0 转换为 0000.
- 2 位数字的年份值的字符串形式,从0"到'99',并按如下规则转换为 4位数年份
- '0'到'69'转换为 2000到 2069
- '70'到'99'转换为 1970 到 1999
若未启用严格 SOL 模式,MVSOL会将无效的 YEAR 值转为 0000。在严格 SOL 模式下,插入无效的 YEAR 值时会产生错误
9.ENUM
在 MySQL 中,一个 ENUM 是一个字符串的列表,它定义了一个列中允许的值,列的值只能是创建列时定义的允许值列表中的的一个
MySQL ENUM 数据类型列适合存储状态和标识等有限数量的固定值的数据
MySQL ENUM 数据类型具有以下优点:
- 列值的可读性更强
- 紧凑的数据存储。MySQL 存储
ENUM时只存储枚举值对应的数字索引 (1,2,3, …)
# 语法
ENUM ('v1', 'v2', ..., 'vn')
- ENUM 用于声明一个枚举类型,V1-VN是此枚举类型的可选项列表(只能使用该枚举类型中定义的值),枚举值只能是字符串
- 一般情况将枚举的数量保持在20以下
MySQL ENUM实例
假设有一个订单表用来存放电子商务订单。其中,订单状态 state 只有四种状态,如下表:此处可为 state 列使用 ENUM 类型
| 状态名 | 状态值 |
|---|---|
| 未支付 | Unpaid |
| 已支付 | Paid |
| 已发货 | Shipped |
| 已完成 | Completed |
CREATE TABLE orders (
id INT PRIMARY KEY AUTO_INCREMENT,
title VARCHAR(255) NOT NULL,
state ENUM('Unpaid', 'Paid', 'Shipped', 'Completed') NOT NULL
);
# 要插入数据到ENUM列中,必须使用预定义列表中的值,否则插入错误
INSERT INTO orders(title, state) VALUES ('Apples', 'Paid');
# 还可使用枚举成员的数字索引将数据插入到ENUM列中
INSERT INTO orders(title, state) VALUES ('Bananas', 2);
# 如果state设置为not null,当插入的时候如果没有指定合法的state枚举值,则默认使用第一个枚举成员作为枚举值
INSERT INTO orders(title) VALUES('Oranges');
# 验证枚举插入
SELECT * FROM orders;
# 在非严格 SQL 模式下,如果在 ENUM 列中插入无效值,MySQL 将使用带有数字索引 0 的空字符串 '' 进行插入。如果启用了严格 SQL 模式,尝试插入无效 ENUM 值将导致错误
# 枚举值的过滤(可以使用具体的枚举值,也可使用索引)
SELECT * FROM orders WHERE state = 'Paid';
SELECT * FROM orders WHERE state = 2;
# 枚举值的排序(MySQL中根据索引号对ENUM值进行排序,即其顺序取决于其在枚举列表中的定义顺序)
SELECT * FROM orders ORDER BY state;
ENUM 的优缺点
MySQL中ENUM的引入具备可读性、提升存储效率,但是它也有一定的缺点
更改枚举成员时需通过
ALTER TABLE语句重建整个表,浪费一定的时间和资源获取完整的枚举列表比较复杂,需要通过访问
information_schema数据库SELECT column_type FROM information_schema.COLUMNS WHERE TABLE_NAME = 'orders' AND COLUMN_NAME = 'state';ENUM不是SQL标准,因此移植到其他的RDBMS可能会存在问题
ENUM的限制性:枚举列表不可重用,且枚举值是字符串无法包含更多的信息
业务场景应用
1.数字类型:避免自增踩坑
表结构设计过程中,数字类型在业务场景中的应用是非常常见的,需要在设计上思考全面,才能有效避免后续系统运行时出现表结构修改的巨大成本。
【1】INT 类型取值范围的考虑
首先需要结合实际业务场景预设字段取值范围,然后择选一个适合的数据类型。
| 类型 | 字节数 | 最小值~最大值【signed】 | 最小值~最大值【unsigned】 |
|---|---|---|---|
TINYINT | 1 | -128~127 | 0~255 |
SMALLINT | 2 | -32768~32767 | 0~65535 |
MEDIUMINT | 3 | -8388608~8388607 | 0~16777215 |
INT | 4 | -2147483648~2147483647 | 0~4294967295 |
BIGINT | 8 | -9223372036854775808~9223372036854775807 | 0-18446744073709551615 |
【2】signed VS unsigned
整形类型中有signed、unsigned类型,默认是signed类型。
在实际业务场景中,不建议刻意去用unsigned属性,因为在一些数据分析场景中,SQL返回的结果可能并不如预期。
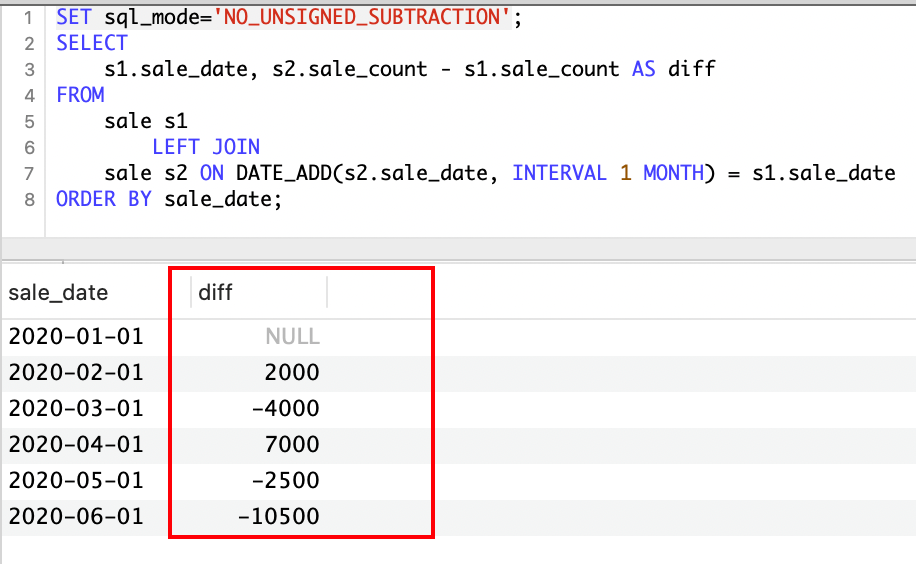
例如销售表sale,在设计sale_count属性的时候用到unsigned属性(即设计时希望存储的列值大于等于0),这个从设计的角度上来看是没有问题的。但是如果说在后续对销售表的统计分析场景中,例如需要统计每月销售数量的变化,那么就不免出现“负增长”的情况(即当月对比上月销售数量减少),那么在SQL执行的过程中就可能会出现异常(MySQL 提示用户计算的结果超出了范围,MySQL要求unsigned 数值相减之后依然为 unsigned,否则就会报错)
Create Table: CREATE TABLE `sale` (
`sale_date` date NOT NULL,
`sale_count` int unsigned DEFAULT NULL,
PRIMARY KEY (`sale_date`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_general_ci
INSERT INTO `sale` (`sale_date`, `sale_count`)
VALUES
('2020-01-01', 10000),
('2020-02-01', 8000),
('2020-03-01', 12000),
('2020-04-01', 5000),
('2020-05-01', 7500),
('2020-06-01', 18000);
# 统计每月销售数量变化
SELECT
s1.sale_date, s2.sale_count - s1.sale_count AS diff
FROM
sale s1
LEFT JOIN
sale s2 ON DATE_ADD(s2.sale_date, INTERVAL 1 MONTH) = s1.sale_date
ORDER BY sale_date;
-- 执行异常提示:BIGINT UNSIGNED value is out of range in '(`db_mysql_base`.`s2`.`sale_count` -`db_mysql_base`.`s1`.`sale_count`)'
解决方案:
- 方案1:对数据库参数
sql_mode设置为NO_UNSIGNED_SUBTRACTION,设定允许相减的结果为signed,才能得到正确的结果 - 方案2:在数据库设置的时候要考虑完善,建议使用signed类型
【3】浮点类型 VS 高精度类型
MySQL 之前的版本中存在浮点类型 Float 和 Double,但这些类型因为不是高精度,也不是 SQL 标准的类型,所以在真实的生产环境中不推荐使用,否则在计算时,由于精度类型问题,会导致最终的计算结果出错。
更重要的是,从 MySQL 8.0.17 版本开始,当创建表用到类型 Float 或 Double 时,会抛出下面的警告:MySQL 提醒用户不该用上述浮点类型,甚至提醒将在之后版本中废弃浮点类型
当声明数字类型中的高精度 DECIMAL 类型要指定精度和标度,例如:salary DECIMAL(8,2)
其中 8 是精度(精度表示保存值的主要位数),2 是标度(标度表示小数点后面保存的位数)。通常在表结构设计中,类型 DECIMAL 可以用来表示用户的工资、账户的余额等精确到小数点后 2 位的业务
在海量并发的互联网业务中使用,金额字段的设计并不推荐使用 DECIMAL 类型,而更推荐使用 INT 整型类型(参考下述案例讲解)
业务表结构设计实战
(1)整形类型与自增设计
在真实业务场景中,整型类型最常见的就是在业务中用来表示某件物品的数量。例如上述案例sale表的销售数量,或电商中的库存数量、购买次数等。在业务中,整型类型的另一个常见且重要的使用用法是作为表的主键,即用来唯一标识一行数据。整型结合属性 auto_increment,可以实现自增功能,但在表结构设计时用自增做主键,必须要注意以下两点内容,若不注意,可能会对业务造成灾难性的打击:
- 要用 BIGINT 做主键,而不是 INT;
- 注意回溯现象:自增值并不持久化,可能会有回溯现象(MySQL 8.0 版本前)
【1】为什么选择BIGINT而不是INT? =》从取值范围考虑
INT 的范围最大在 42 亿的级别,在真实的互联网业务场景的应用中,很容易达到最大值。例如一些流水表、日志表,每天 1000W 数据量,420 天后,INT 类型的上限即可达到。即在使用自增整型做主键的场景中,建议一律使用 BIGINT,而不是 INT,进而避免后续表结构变更的巨大维护成本。不要为了节省 4 个字节使用 INT,当达到上限时,再进行表结构的变更,将是巨大的负担与痛苦
此处引申思考一个问题,当自增数值达到INT的上限时,MySQL会有怎样的表现?会不会重置为1(并不会,会抛出重复插入错误)
# 创建表,测试插入INT上限的ID数据
CREATE TABLE t (a INT AUTO_INCREMENT PRIMARY KEY);
INSERT INTO t VALUES (2147483647);
# 当继续插入下一条数据此时MySQL会提示错误(即主键自增达到INT上限之后,再次执行自增插入,会报重复错误,MySQL并不会将其重置为1)
INSERT INTO t VALUES (2147483647);
Duplicate entry '2147483647' for key 'PRIMARY'
【2】回溯现象:MySQL 8.0 版本前,自增不持久化,自增值可能会存在回溯问题
# 1.创建表,测试插入多条数据(此处插入4条数据)
select * from t;
INSERT INTO `t` (`a`) VALUES (1),(2),(3),(4);
# 2.查看创建表语句
show create table t;
-- 展示结果
CREATE TABLE `t` (
`a` int(11) NOT NULL AUTO_INCREMENT,
PRIMARY KEY (`a`)
) ENGINE=InnoDB AUTO_INCREMENT=5 DEFAULT CHARSET=utf8
-- 从上述结果可以看到目前表的AUTO_INCREMENT被定位到5
# 3.删除2条数据,然后再次查看,确认自增指标
# a.删除自增为4的记录(此处要删除最大的ID那条记录才能校验是否发生回溯),再次查看确认,发现下一个自增值还是5(AUTO_INCREMENT=5),目前来看是正常的,自增并没有回溯
# b.重启mysql服务,再次查看确认,自增值会发生回溯(AUTO_INCREMENT=4)
结合上述案例分析,如果数据表中指定了自增INT类型,当数据表出现删除操作的时候,就有可能会存在自增回溯现象,而要解决这一问题,则需要通过升级MySQL版本(MySQL8.0版本修复了这个bug,每张表的自增值会持久化),如果无法通过升级数据库版本,则不建议在核心业务表中使用自增数据类型做主键。
除此之外,在海量互联网架构设计过程中,为了之后更好的分布式架构扩展性,不建议使用整型类型做主键,更为推荐的是字符串类型。自增主键ID问题剖析如下:
- 可靠性不高:MySQL低版本存在主键ID回溯问题(低版本中每张表的自增值不会持久化,如果删除的数据较多,一些ID会被重复利用)
- 安全性不高:对外接口容易暴露业务信息(例如
user/1这种接口),可以通过剖析接口信息,使用爬虫工具进行数据获取 - 性能差:自增ID由服务器生成,在高并发场景中,会存在AUTO_INCREMENT锁竞争问题
- 交互多:业务还需要一次last_insert_id才能知道刚才插入数据的ID,这需要多一次的网络交互。这在高并发性能吃紧的场景下是及其浪费的
- 局部唯一性:只能在当前数据库中唯一,而非全局唯一,对于核心业务表,这在分布式环境下是绝对不允许的
(2)资金字段设计
在海量互联网业务的设计标准中,并不推荐用 DECIMAL 类型,而是更推荐将 DECIMAL 转化为 整型类型
在用户余额、基金账户余额、数字钱包、零钱等的业务设计中,由于字段都是资金字段,一般习惯使用 DECIMAL 类型作为字段的选型,因为这样可以精确到分,如:DECIMAL(8,2)(基于此设定最大存储值为999999.99,百万级的资金存储)
CREATE TABLE User (
userId BIGINT AUTO_INCREMENT,
money DECIMAL(8,2) NOT NULL,
......
)
为什么不选用DECIMAL?(推荐使用BIG INT分段存储)
**取值范围选择:**用户的金额至少要存储百亿的字段,而统计局的 GDP 金额字段则可能达到数十万亿级别,如果用类型 DECIMAL 定义,不好统一。
计算效率:类型 DECIMAL 是通过二进制实现的一种编码方式,计算效率远不如整型来的高效
推荐使用BIG INT 来存储金额相关的字段,字段存储时采用分存储的方式,以此存储千兆级别的金额。
在数据库设计中,非常强调定长存储,因为定长存储的性能更好,采用分段存储的方式,所有金额相关字段都是定长字段,占用 8 个字节,存储高效。另一点,直接通过整型计算,效率更高。当使用BIG INT分段存储金额字段的时候,针对小数点的数据可以交由前端进行拼接处理展示即可
2.字符串类型:不能忽略的COLLATION(排序规则)
CHAR(N) 用来保存固定长度的字符,N 的范围是 0 ~ 255,请牢记,N 表示的是字符,而不是字节。
VARCHAR(N) 用来保存变长字符,N 的范围为 0 ~ 65536, N 表示字符。
在超出 65536 个字符的情况下,可以考虑使用更大的字符类型 TEXT 或 BLOB,两者最大存储长度为 4G,其区别是 BLOB 没有字符集属性,纯属二进制存储。
和 Oracle、Microsoft SQL Server 等传统关系型数据库不同的是,MySQL 数据库的 VARCHAR 字符类型,最大能够存储 65536 个字符,所以在 MySQL 数据库下,绝大部分场景使用类型 VARCHAR 就足够了
字符集:考虑字符集支持的字符、存储占用、排序规则等
在表结构设计中,除了将列定义为 CHAR 和 VARCHAR 用以存储字符以外,还需要额外定义字符对应的字符集,因为每种字符在不同字符集编码下,对应着不同的二进制值。常见的字符集有 GBK、UTF8,通常推荐把默认字符集设置为 UTF8。
而且随着移动互联网的飞速发展,推荐把 MySQL 的默认字符集设置为 UTF8MB4,否则,某些 emoji 表情字符无法在 UTF8 字符集下存储,比如 emoji 笑脸表情,对应的字符编码为 0xF09F988E:
select CAST(0xF09F988E as char charset utf8) as emoji;
select CAST(0xF09F988E as char charset utf8mb4) as emoji;
# 创建字符集为utf8的列,尝试插入emoji
CREATE TABLE `emoji_test` (
`a` varchar(100) CHARACTER SET utf8,
PRIMARY KEY (`a`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
INSERT INTO emoji_test VALUES (0xF09F988E);
-- 插入操作提示错误:[ERROR in query 2] Incorrect string value: '\xF0\x9F\x98\x8E' for column 'a' at row 1
包括 MySQL 8.0 版本在内,字符集默认设置成 UTF8MB4,8.0 版本之前默认的字符集为 Latin1。因为不同版本默认字符集的不同,可显式地在配置文件中进行相关参数的配置[mysqld] character-set-server = utf8mb4,或者在创建表、列的时候显式指定字符集编码
不同的字符集,CHAR(N)、VARCHAR(N) 对应最长的字节也不相同。比如 GBK 字符集,1 个字符最大存储 2 个字节,UTF8MB4 字符集 1 个字符最大存储 4 个字节。所以从底层存储内核看,在多字节字符集下,CHAR 和 VARCHAR 底层的实现完全相同,都是变长存储
排序规则(Collation)是比较和排序字符串的一种规则,每个字符集都会有默认的排序规则,你可以用命令 SHOW CHARSET
SHOW CHARSET LIKE 'utf8%';
SHOW COLLATION LIKE 'utf8mb4%';
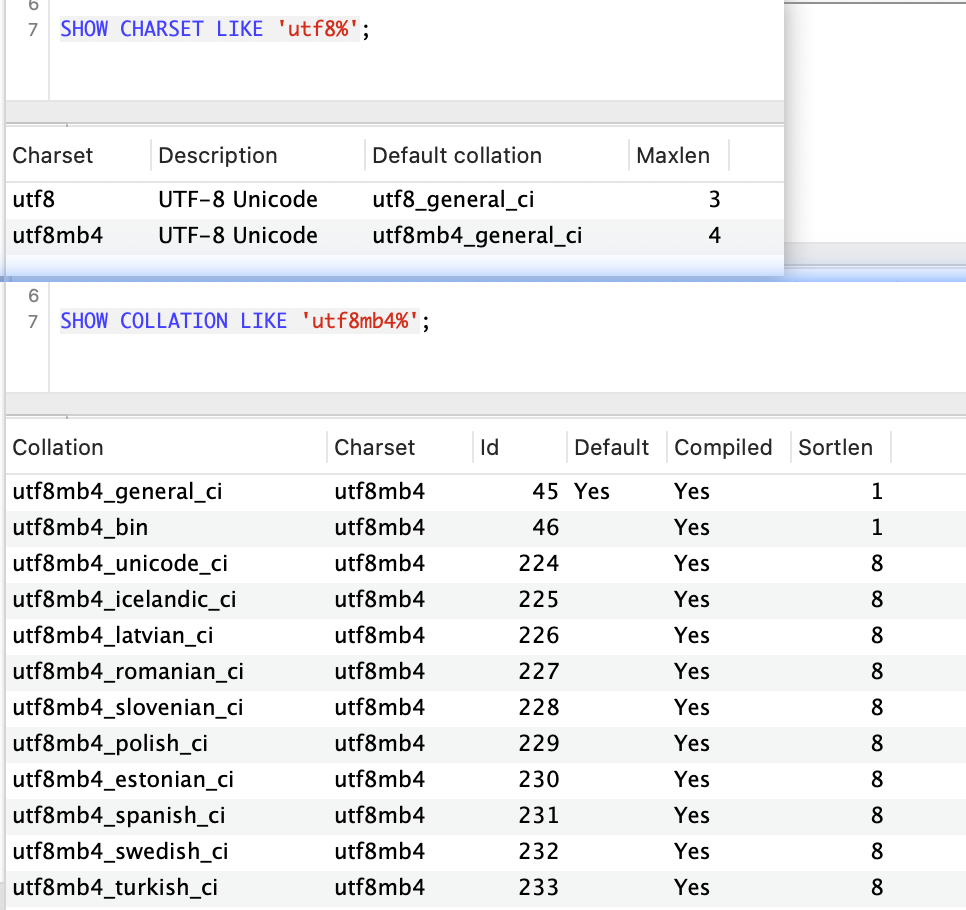
排序规则以 _ci 结尾,表示不区分大小写(Case Insentive),_cs 表示大小写敏感,_bin 表示通过存储字符的二进制进行比较。需要注意的是,比较 MySQL 字符串,默认采用不区分大小的排序规则。绝大部分业务的表结构设计无须设置排序规则为大小写敏感!除非特定业务真正需要
正确修改字符集
不少业务在设计时没有考虑到字符集对于业务数据存储的影响,所以后期需要进行字符集转换,但有时候会发现执行如下操作后,依然无法插入 emoji 这类 UTF8MB4 字符
# 原创建table语句
CREATE TABLE `emoji_test` (
`a` varchar(100) CHARACTER SET utf8,
PRIMARY KEY (`a`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
# 修改字符集错误示例
ALTER TABLE emoji_test CHARSET utf8mb4;
# 上述修改只是将表的字符集修改为 UTF8MB4,下次新增列时,若不显式地指定字符集,新列的字符集会变更为 UTF8MB4,但对于已经存在的列,其默认字符集并不做修改,可以通过命令 SHOW CREATE TABLE 进一步确认
-- 展示create table结果如下(表设定为utf8mb4,但是对应列还是utf8)
CREATE TABLE `emoji_test` (
`a` varchar(100) CHARACTER SET utf8 NOT NULL,
PRIMARY KEY (`a`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4
# 修改字符集正确示例(指令:ALTER TABLE … CONVERT TO…)
ALTER TABLE emoji_test CONVERT TO CHARSET utf8mb4;
# 再次查看建表信息
show create table emoji_test;
-- 展示create table结果如下(正常设定为utf8mb4)
CREATE TABLE `emoji_test` (
`a` varchar(100) NOT NULL,
PRIMARY KEY (`a`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4
业务表结构设计实战
(1)用户性别设计
设计表结构时,会遇到一些固定选项值的字段。例如,性别字段(Sex),只有男或女;又或者状态字段(State),有效的值为运行、停止、重启等有限状态。一般场景中,可能会使用INT类型存储性别或者其他字段,但是这样就可能存在两点问题:
- 表达不清:例如性别指定0、1这类,无法通过字段直接判断其含义(需要进行类似枚举转化成实际的业务含义)
- 脏数据:设定了tinyint,用户可以插入一些非法的值(例如插入一些无效的字段值),最终导致表中存在无效数据,后期清理代价较大
在 MySQL 8.0 版本之前,可以使用 ENUM 字符串枚举类型,只允许有限的定义值插入。如果将参数 SQL_MODE 设置为严格模式。但由于类型 ENUM 并非 SQL 标准的数据类型,而是 MySQL 所独有的一种字符串类型。抛出的错误提示也并不直观,这样的实现总有一些遗憾,主要是因为MySQL 8.0 之前的版本并没有提供约束功能。自 MySQL 8.0.16 版本开始,数据库原生提供 CHECK 约束功能,可以方便地进行有限状态列类型的设计
CREATE TABLE `User` (
`id` bigint NOT NULL AUTO_INCREMENT,
`sex` char(1) COLLATE utf8mb4_general_ci DEFAULT NULL,
PRIMARY KEY (`id`),
CONSTRAINT `user_chk_1` CHECK (((`sex` = _utf8mb4'M') or (`sex` = _utf8mb4'F')))
) ENGINE=InnoDB
INSERT INTO User VALUES (NULL,'M');
NSERT INTO User VALUES (NULL,'Z'); // 违法插入
(2)账号密码存储设计(敏感信息存储)
在数据库表结构设计时,千万不要直接在数据库表中直接存储密码,一旦有恶意用户进入到系统,则面临用户数据泄露的极大风险。比如金融行业,从合规性角度看,所有用户隐私字段都需要加密,甚至业务自己都无法知道用户存储的信息(隐私数据如登录密码、手机、信用卡信息等)。
改进1:MD5加密
一般场景可能会通过函数 MD5 加密存储隐私数据,这没有错,因为 MD5 算法并不可逆。然而,MD5 加密后的值是固定的,如密码 12345678,它对应的 MD5 固定值即为 25d55ad283aa400af464c76d713c07ad。基于这种思路,可以对MD5 进行暴力破解,计算出所有可能的字符串对应的 MD5 值。若无法枚举所有的字符串组合,那可以计算一些常见的密码,如111111、12345678 等(在线解密 MD5 加密后的字符串)
改进2:加盐(salt)固定盐值的加密算法
因此在设计密码的时候,还需要加盐(salt),每个公司的盐值都是不同的,因此计算出的值也是不同的。若盐值为 psalt,则密码 12345678 在数据库中的值为:password = MD5(‘psalt12345678’)。但基于这种固定盐值的加密算法,还是会存在一定的问题:
- 若 salt 值被(离职)员工泄漏,则外部黑客依然存在暴利破解的可能性;
- 对于相同密码,其密码存储值相同,一旦一个用户密码泄漏,其他相同密码的用户的密码也将被泄漏;
- 固定使用 MD5 加密算法,一旦 MD5 算法被破解,则影响很大。
改进3:动态盐 + 非固定加密算法
列 password 存储的格式:$salt$cryption_algorithm$value
- $salt:表示动态盐,每次用户注册时业务产生不同的盐值,并存储在数据库中。若做得再精细一点,可以动态盐值 + 用户注册日期合并为一个更为动态的盐值。
- $cryption_algorithm:表示加密的算法,如 v1 表示 MD5 加密算法,v2 表示 AES256 加密算法,v3 表示 AES512 加密算法等。
- $value:表示加密后的字符串
# User表设计
CREATE TABLE User (
id BIGINT NOT NULL AUTO_INCREMENT,
name VARCHAR(255) NOT NULL,
sex CHAR(1) NOT NULL,
password VARCHAR(1024) NOT NULL,
regDate DATETIME NOT NULL,
CHECK (sex = 'M' OR sex = 'F'),
PRIMARY KEY(id)
);
# 参考示例
SELECT * FROM User\G
*************************** 1. row ***************************
id: 1
name: David
sex: M
password: $fgfaef$v1$2198687f6db06c9d1b31a030ba1ef074
regDate: 2020-09-07 15:30:00
*************************** 2. row ***************************
id: 2
name: Amy
sex: F
password: $zpelf$v2$0x860E4E3B2AA4005D8EE9B7653409C4B133AF77AEF53B815D31426EC6EF78D882
regDate: 2020-09-07 17:28:00
在上述示例中用户 David 和 Amy 密码都是 12345678,然而由于使用了动态盐和动态加密算法,两者存储的内容完全不同。
即便别有用心的用户拿到当前密码加密算法,则通过加密算法 $cryption_algorithm 版本,可以对用户存储的密码进行升级,进一步做好对于恶意数据攻击的防范。因此,针对业务隐私信息,如密码、手机、信用卡等信息,需要进行采用安全有效的加密算法(推荐使用动态盐+动态加密算法进行隐私数据的存储)
3.日期类型:TIMESTAMP可能是巨坑
几乎每张业务表都带有一个日期列,用于记录每条记录产生和变更的时间。例如用户表会有一个日期列记录用户注册的时间、用户最后登录的时间;电商行业中的订单表(核心业务表)会有一个订单产生的时间列,当支付时间超过订单产生的时间,这个订单可能会被系统自动取消。
MySQL 数据库中常见的日期类型有 YEAR、DATE、TIME、DATETIME、TIMESTAMEP。因为业务绝大部分场景都需要将日期精确到秒,所以在表结构设计中,常见使用的日期类型为DATETIME 和 TIMESTAMP,也会有开发人员使用整型来存储日期信息
对于日期类型的选择,一般是:DATETIME、TIMESTAMP、INT
DATETIME
从 MySQL 5.6 版本开始,DATETIME 类型支持毫秒,DATETIME(N) 中的 N 表示毫秒的精度。例如,DATETIME(6) 表示可以存储 6 位的毫秒值。同时,一些日期函数也支持精确到毫秒,例如常见的函数 NOW、SYSDATE
# 查询当前系统实现(精确到6为毫秒数)
select NOW(6);
2024-06-21 13:11:36.254416
# 可以将 DATETIME 初始化值设置为当前时间,并设置自动更新当前时间的属性。例如用户表 User 设计
CREATE TABLE User (
id BIGINT NOT NULL AUTO_INCREMENT,
name VARCHAR(255) NOT NULL,
sex CHAR(1) NOT NULL,
password VARCHAR(1024) NOT NULL,
money INT NOT NULL DEFAULT 0,
register_date DATETIME(6) NOT NULL DEFAULT CURRENT_TIMESTAMP(6),
last_modify_date DATETIME(6) NOT NULL DEFAULT CURRENT_TIMESTAMP(6) ON UPDATE CURRENT_TIMESTAMP(6),
CHECK (sex = 'M' OR sex = 'F'),
PRIMARY KEY(id)
);
-- 列 register_date 表示注册时间,DEFAULT CURRENT_TIMESTAMP 表示记录插入时,若没有指定时间,默认就是当前时间
-- 列 last_modify_date 表示当前记录最后的修改时间,DEFAULT CURRENT_TIMESTAMP(6) ON UPDATE CURRENT_TIMESTAMP(6) 表示每次修改都会修改为当前时间(基于此设计,当记录修改的时候会联动触发时间更新操作)
TIMESTAMP
TIMESTAMP 时间戳类型,其实际存储的内容为‘1970-01-01 00:00:00’到现在的毫秒数。在 MySQL 中,由于类型 TIMESTAMP 占用 4 个字节,因此其存储的时间上限只能到‘2038-01-19 03:14:07’。
MySQL 5.6 版本开始,类型 TIMESTAMP 也能支持毫秒。与 DATETIME 不同的是,若带有毫秒时,类型 TIMESTAMP 占用 7 个字节,而 DATETIME 无论是否存储毫秒信息,都占用 8 个字节。
类型 TIMESTAMP 最大的优点是可以带有时区属性,因为它本质上是从毫秒转化而来。如果业务需要对应不同的国家时区,可考虑 TIMESTAMP
- 例如新闻类的业务,通常用户想知道这篇新闻发布时对应的自己国家时间
- 例如有些国家会执行夏令时。根据不同的季节,人为地调快或调慢 1 个小时,带有时区属性的 TIMESTAMP 类型本身就能解决这个问题。
参数 time_zone 指定了当前使用的时区,默认为 SYSTEM 使用操作系统时区,用户可以通过该参数指定所需要的时区。如果想使用 TIMESTAMP 的时区功能,可以通过下面的语句将之前的用户表 User 的注册时间字段类型从 DATETIME(6) 修改为 TIMESTAMP(6):
ALTER TABLE User
CHANGE register_date register_date TIMESTAMP(6) NOT NULL DEFAULT CURRENT_TIMESTAMP(6);
# 可通过设定不同的时区来观察注册时间(中国的时区是 +08:00,美国的时区是 -08:00)
SET time_zone = '-08:00';
SELECT name,register_date FROM User WHERE name = 'David';
# 一般情况下直接加减时区并不直观,可通过设置时区名字来切换时区
SET time_zone = 'America/Los_Angeles';
SET time_zone = 'Asia/Shanghai';
业务表结构设计实战
在做表结构设计时,对日期字段的存储,通常会有 3 种选择:DATETIME、TIMESTAMP、INT。
INT 类型就是直接存储 ‘1970-01-01 00:00:00’ 到现在的毫秒数,本质和 TIMESTAMP 一样,因此用 INT 不如直接使用 TIMESTAMP。
或许会认为 INT 比 TIMESTAMP 性能更好。但是,由于当前每个 CPU 每秒可执行上亿次的计算,所以无须为这种转换的性能担心。更重要的是,在后期运维和数据分析时,使用 INT 存储日期,是会让 DBA 和数据分析人员发疯的,INT的可运维性太差。
如果是TIMESTEMP 存储日期,因为类型 TIMESTAMP 占用 4 个字节,比 DATETIME 小一半的存储空间。但若要将时间精确到毫秒,TIMESTAMP 要 7 个字节,和 DATETIME 8 字节差不太多。但目前来看,现在距离 TIMESTAMP 的最大值‘2038-01-19 03:14:07’已经很近,要结合实际场景择选。
总的来说,建议你使用类型 DATETIME。 对于时区问题,可以由前端或者服务这里做一次转化,不一定非要在数据库层面解决。
TIMESTAMP的性能问题
TIMESTAMP 的上限值 2038 年很快就会到来,那时业务又将面临一次类似千年虫的问题。另外,TIMESTAMP 还存在潜在的性能问题。
虽然从毫秒数转换到类型 TIMESTAMP 本身需要的 CPU 指令并不多,这并不会带来直接的性能问题。但是如果使用默认的操作系统时区,则每次通过时区计算时间时,要调用操作系统底层系统函数 __tz_convert(),而这个函数需要额外的加锁操作,以确保这时操作系统时区没有修改。所以,当大规模并发访问时,由于热点资源竞争,会产生两个问题。
- 性能不如 DATETIME: DATETIME 不存在时区转化问题
- 性能抖动: 海量并发时,存在性能抖动问题
为了优化 TIMESTAMP 的使用,强烈建议使用显式的时区,而不是操作系统时区。比如在配置文件中显示地设置时区,而不要使用系统时区:
[mysqld]
time_zone = "+08:00"
可通过命令 mysqlslap 来测试 TIMESTAMP、DATETIME 的性能,命令如下:
# 比较time_zone为System和Asia/Shanghai的性能对比
mysqlslap -uroot --number-of-queries=1000000 --concurrency=100 --query='SELECT NOW()'
显式指定时区的性能要远远好于直接使用操作系统时区。所以,日期字段推荐使用 DATETIME,没有时区转化。即便使用 TIMESTAMP,也需要在数据库中显式地配置时区,而不是用系统时区
表结构设计规范:每条记录都要有一个时间字段
在做表结构设计规范时,强烈建议每张业务核心表都增加一个 DATETIME 类型的 last_modify_date 字段,并设置修改自动更新机制, 标识每条记录最后修改的时间。这样设计的好处是: 用户可以知道每个用户最近一次记录更新的时间,以便做后续的处理。比如在电商的订单表中,可以方便对支付超时的订单做处理;在金融业务中,可以根据用户资金最后的修改时间做相应的资金核对等。
4.非结构存储
关系型的结构化存储存在一定的弊端,因为它需要预先定义好所有的列以及列对应的类型。但是业务在发展过程中,或许需要扩展单个列的描述功能,这时,如果能用好 JSON 数据类型,那就能打通关系型和非关系型数据的存储之间的界限,为业务提供更好的架构选择
在使用 JSON 数据类型时可能会遇到各种各样的问题,其中最容易犯的误区就是将类型 JSON 简单理解成字符串类型。 需要结合实际业务场景分析,以更好地存储非结构化的数据
JSON数据类型
JSON(JavaScript Object Notation)主要用于互联网应用服务之间的数据交换。MySQL 支持RFC 7159定义的 JSON 规范,主要有JSON 对象和JSON 数组两种类型。以JSON存储图片的相关信息为例:JSON 类型可以很好地描述数据的相关内容,比如这张图片的宽度、高度、标题等(这里使用到的类型有整型、字符串类型),且JSON对象除了支持字符串、整型、日期类型,JSON 内嵌的字段也支持数组类型,如上代码中的 IDs 字段
{
"Image": {
"Width": 800,
"Height": 600,
"Title": "View from 15th Floor",
"Thumbnail": {
"Url": "http://www.example.com/image/481989943",
"Height": 125,
"Width": 100
},
"IDs": [116, 943, 234, 38793]
}
}
数组类型的JSON:
[
{
"precision": "zip",
"Latitude": 37.7668,
"Longitude": -122.3959,
"Address": "",
"City": "SAN FRANCISCO",
"State": "CA",
"Zip": "94107",
"Country": "US"
},
{
"precision": "zip",
"Latitude": 37.371991,
"Longitude": -122.026020,
"Address": "",
"City": "SUNNYVALE",
"State": "CA",
"Zip": "94085",
"Country": "US"
}
]
此处可能会将JSON当做一个大文本的非结构化存储的字符串类型,但实际上MySQL对其的设计是一种新的类型,它有自己的存储格式,还能在每个对应的字段上创建索引,做特定的优化。JSON 类型的另一个好处是无须预定义字段,字段可以无限扩展。而传统关系型数据库的列都需预先定义,想要扩展需要执行 ALTER TABLE … ADD COLUMN … 这样比较重的操作
JSON 类型是从 MySQL 5.7 版本开始支持的功能,而 8.0 版本解决了更新 JSON 的日志性能瓶颈。如果要在生产环境中使用 JSON 数据类型,强烈推荐使用 MySQL 8.0 版本
业务表结构设计实战
(1)用户登录设计
在数据库中,JSON 类型比较适合存储一些修改较少、相对静态的数据,比如用户登录信息的存储如下
DROP TABLE IF EXISTS UserLogin;
CREATE TABLE UserLogin (
userId BIGINT NOT NULL,
loginInfo JSON,
PRIMARY KEY(userId)
);
由于当前业务的登录方式越来越多样化,如同一账户支持手机、微信、QQ 账号登录,所以这里可以用 JSON 类型存储登录的信息由于当前业务的登录方式越来越多样化,如同一账户支持手机、微信、QQ 账号登录,所以这里可以用 JSON 类型存储登录的信息
# 插入数据测试
SET @a = '
{
"cellphone" : "13918888888",
"wxchat" : "破产码农",
"QQ" : "82946772"
}';
INSERT INTO UserLogin VALUES (1,@a);
SET @b = '
{
"cellphone" : "15026888888"
}';
INSERT INTO UserLogin VALUES (2,@b);
# 检索结果
userId loginInfo
1 {"QQ": "82946772", "wxchat": "破产码农", "cellphone": "13918888888"}
2 {"cellphone": "15026888888"}
如果不采用JSON方式存储,则按照原有结构化方式存储,需要为不同的登录类型设定存储字段,参考如下所示。但传统方式定义存在两个问题:
- 存储无法充分利用:有些列可能是比较稀疏的,一些列可能大部分是NULL值
- 扩展性较差:如果要新增一种登录方式,则需要修改表结构
CREATE TABLE UserLogin (
userId BIGINT NOT NULL,
cellphone VARCHAR(255),
wechat VARCHAR(255)
QQ VARCHAR(255),
PRIMARY KEY(userId)
);
MySQL 配套提供了丰富的 JSON 字段处理函数,用于方便地操作 JSON 数据,具体可以见 MySQL 官方文档。其中,最常见的就是函数 JSON_EXTRACT,它用于从 JSON 数据中提取所需要的字段内容
# 查询用户的手机和微信信息
SELECT
userId,
JSON_UNQUOTE(JSON_EXTRACT(loginInfo,"$.cellphone")) cellphone,
JSON_UNQUOTE(JSON_EXTRACT(loginInfo,"$.wxchat")) wxchat
FROM UserLogin;
# 检索结果
1 13918888888 破产码农
2 15026888888 NULL
# MySQL为了简化语法规则,提供了->>表达式(其实现效果等价于上述语句)
SELECT
userId,
loginInfo->>"$.cellphone" cellphone,
loginInfo->>"$.wxchat" wxchat
FROM UserLogin;
当 JSON 数据量非常大,如果希望对 JSON 数据进行有效检索时,可以利用 MySQL 的函数索引功能对 JSON 中的某个字段进行索引。比如在上面的用户登录示例中,假设用户必须绑定唯一手机号,且希望未来能用手机号码进行用户检索时,可以创建下面的索引:
# 为JSON字段指定索引
ALTER TABLE UserLogin ADD COLUMN cellphone VARCHAR(255) AS (loginInfo->>"$.cellphone");
ALTER TABLE UserLogin ADD UNIQUE INDEX idx_cellphone(cellphone);
# 可以在创建表的时候就完成虚拟列以及函数索引的创建
CREATE TABLE UserLogin (
userId BIGINT,
loginInfo JSON,
cellphone VARCHAR(255) AS (loginInfo->>"$.cellphone"),
PRIMARY KEY(userId),
UNIQUE KEY uk_idx_cellphone(cellphone)
);
上述 SQL 首先创建了一个虚拟列 cellphone,这个列是由函数 loginInfo->>“$.cellphone” 计算得到的。然后在这个虚拟列上创建一个唯一索引 idx_cellphone。这时再通过虚拟列 cellphone 进行查询,就可以看到优化器会使用到新创建的 idx_cellphone 索引

(2)用户画像设计
部分业务需要做用户画像(即对用户打标签),然后根据用户的标签,通过数据挖掘技术,进行相应的产品推荐。比如:
- 在电商行业中,根据用户的穿搭喜好,推荐相应的商品;
- 在音乐行业中,根据用户喜欢的音乐风格和常听的歌手,推荐相应的歌曲;
- 在金融行业,根据用户的风险喜好和投资经验,推荐相应的理财产品。
此处可以用 JSON 类型在数据库中存储用户画像信息,并结合 JSON 数组类型和多值索引的特点进行高效查询。
原始用户画像实现方式
假设有张画像定义表:
CREATE TABLE Tags (
tagId bigint auto_increment,
tagName varchar(255) NOT NULL,
primary key(tagId)
);
SELECT * FROM Tags;
INSERT INTO `Tags` (`tagId`, `tagName`)
VALUES
(1, '70后'),
(2, '80后'),
(3, '90后'),
(4, '00后'),
(5, '爱运动'),
(6, '高学历'),
(7, '小资'),
(8, '有房'),
(9, '有车'),
(10, '常看电影'),
(11, '爱网购'),
(12, '爱外卖');
表 Tags 是一张画像定义表,用于描述当前定义有多少个标签,接着给每个用户打标签,比如用户 David的标签是 80 后、高学历、小资、有房、常看电影;用户 Tom,90 后、常看电影、爱外卖。若不用 JSON 数据类型进行标签存储,通常会将用户标签通过字符串,加上分割符的方式,在一个字段中存取用户所有的标签:
+-------+---------------------------------------+
|用户 |标签 |
+-------+---------------------------------------+
|David |80后 ; 高学历 ; 小资 ; 有房 ;常看电影 |
|Tom |90后 ;常看电影 ; 爱外卖 |
+-------+---------------------------------------+
这种方式的缺点在于:不好搜索特定画像的用户,另外分隔符也是一种自我约定,在数据库中其实可以任意存储其他数据,最终产生脏数据
JSON方式构建用户画像
DROP TABLE IF EXISTS UserTag;
CREATE TABLE UserTag (
userId bigint NOT NULL,
userTags JSON,
PRIMARY KEY (userId)
);
INSERT INTO UserTag VALUES (1,'[2,6,8,10]');
INSERT INTO UserTag VALUES (2,'[3,10,12]');
上述定义中userTags存储的就是Tags已定义的那些标签值,只是使用JSON数组类型进行存储
MySQL 8.0.17 版本开始支持 Multi-Valued Indexes,用于在 JSON 数组上创建索引,并通过函数 member of、json_contains、json_overlaps 来快速检索索引数据。所以你可以在表 UserTag 上创建 Multi-Valued Indexes:
# MySQL 8.0.17版本开始支持
ALTER TABLE UserTag ADD INDEX idx_user_tags ((cast((userTags->"$") as unsigned array)));
# 查询用户画像为常看电影的用户,可以使用函数 MEMBER OF
EXPLAIN SELECT * FROM UserTag WHERE 10 MEMBER OF(userTags->"$")
# 查询画像为 80 后,且常看电影的用户,可以使用函数 JSON_CONTAINS
EXPLAIN SELECT * FROM UserTag WHERE JSON_CONTAINS(userTags->"$", '[2,10]')
# 如果想要查询画像为 80 后、90 后,且常看电影的用户,则可以使用函数 JSON_OVERLAP
EXPLAIN SELECT * FROM UserTag WHERE JSON_OVERLAPS(userTags->"$", '[2,3,10]')