MySQL-原理篇-③事务
MySQL-原理篇-③事务
学习核心
- 事务核心
- 事务 ACID 特性
- 理解ACID核心概念,分别是如何实现的
- 事务的隔离级别
- 理解事务并发场景:事务并发会产生什么问题?
- 事务的隔离级别:有哪些隔离级别?如何实现?
- 什么是MVCC?其实现原理?解决了什么问题?
- MySQL中的隔离级别实现原理:读未提交、读已提交、可重复读、串行化
- 事务 ACID 特性
学习资料
事务特性:ACID
1.ACID 概念核心
数据库事务有四大特性: ACID --> 原子性 一致性 隔离性 持久性
- 原子性(Atomicity):指事务在逻辑上是不可分割的操作单元,所有的语句要么都执行成功,要么都执行失败并进行撤销
- 一致性(Consistency):事务应确保数据库的状态从一个一致状态转变为另一个一致状态。一致状态的含义是数据库中的数据应满足完整性约束
- 隔离性(Isolation):隔离性是针对并发而言,用于隔离并发运行的多个事务,以避免产生相互影响。所谓的并发是指数据库服务器同时执行多个事务,如果在执行的过程中不采取有效的专门控制机制,并发事务之间会发生相互干扰
- 持久性(Durability):事务一旦提交对数据的修改就是持久性的,数据已经从内存转移到了外部服务器上,并执行了固化的步骤
InnoDB引擎通过什么技术来保证事务的这四个特性?
- 原子性是通过 undo log(回滚日志) 来保证的;
- 持久性是通过 redo log (重做日志)来保证的;
- 隔离性是通过 MVCC(多版本并发控制) 或锁机制来保证的;
- 一致性则是通过持久性+原子性+隔离性来保证;
2.ACID 案例拆解
案例准备:以t_account表操作为例(用于存储账户信息)
CREATE TABLE t_account (
id INT NOT NULL AUTO_INCREMENT COMMENT '自增id',
name VARCHAR(100) COMMENT '客户名称',
balance INT COMMENT '余额',
PRIMARY KEY (id)
) Engine=InnoDB CHARSET=utf8;
# 初始化数据
INSERT INTO `t_account` (`id`, `name`, `balance`) VALUES ('1', '小明', '15');
INSERT INTO `t_account` (`id`, `name`, `balance`) VALUES ('2', '小红', '10');
当向账户中执行存钱、取钱、转账等操作时,账户中的余额会发生变动,每一个操作都相当于现实世界中账户的一次状态转换。假设有这么一种场景:小明给小红转账10元,那么正常来说会执行两条语句:而这两条语句操作可以视为同一个事务,要确保两条语句都执行成功才能确保事务的正确性(即确保小明转出10元,小红收到10元),基于这个场景设计展开对事务ACID特性的理解
UPDATE account SET balance = balance - 10 WHERE id = 1; # 小明账户金额-10
UPDATE account SET balance = balance + 10 WHERE id = 2; # 小红账户金额+10
原子性
原子性:事务在逻辑上是不可分割的操作单元,所有的语句要么都执行成功,要么都执行失败并进行撤销。
场景中"小明给小红转账10元"就是一个事务,这个事务可能会拆解成若干个步骤,而这些步骤要么都成功,要么都不成功,不能存在中间的状态。如果中间的任意一个节点发生错误(例如数据库本身错误、操作系统错误、断电等异常)就会导致意想不到的结果,因此数据库的设计者为了确保这一特性,一旦中间节点出现异常,就会将已经触发了的操作恢复成未执行前的状态。
一致性
一致性(Consistency):事务应确保数据库的状态从一个一致状态转变为另一个一致状态。一致状态的含义是数据库中的数据应满足完整性约束,对照现实世界来说,如果数据库中的数据全部符合现实世界中的约束(all defined rules),则这些数据就是一致的(符合一致性)
所谓约束:回归到数据库核心概念,主键约束、唯一约束、外键约束、check约束、非空约束等等,而完整性约束则包括数据类型基本约束、实体完整性、参照完整性、用户自定义完整性的概念(实际上就是对标数据库约束,确保数据完整性)
如何确保数据库中数据的一致性?(可以从两个方面切入:数据库本身的约束、程序设计编写业务代码确保数据一致性)
- 数据库本身约束:指的是利用数据库约束限定字段的定义规则(例如主键约束确保主键ID唯一且非空,非空约束确保插入的某个值不能为null等)
- 并不是所有的数据库都支持所有的约束定义(有些数据库可能并没有实现这块的校验功能,例如MySQL仅仅是支持check语法,但实际上插入数据时并不会真正校验字段,可借助触发器来自定义一些约束条件)
- 程序设计编写代码:通过自定义规则限定,在代码层进行控制,确保数据一致性(可以理解通过程序设计满足业务规则,进而确保数据一致性)
- 如果将一致性检查的工作全部丢到数据库层面去控制,这无疑是一个比较耗费性能的选择。例如基于上述场景创建一个触发器,每当插入或者更新记录时都会校验一下
balance列的值是不是大于0,这就会影响到插入或更新的速度(这只是一个小小的一致性检查,现实生活中复杂的一致性需求比比皆是,不可能全部丢到数据库层面去校验) - 通过程序设计来对业务规则进行校验,以此确保数据的一致性
- 如果将一致性检查的工作全部丢到数据库层面去控制,这无疑是一个比较耗费性能的选择。例如基于上述场景创建一个触发器,每当插入或者更新记录时都会校验一下
==如何理解原子性和一致性的区别?==结合业务场景分析其特性概念:
- 原子性更倾向于过程(在执行的过程中这组操作要么都完成要么都不完成,不会存在中间态,如果中间存在异常则会恢复至原来的状态)
- 一致性看重的是结果(一致性关注的是数据经过一系列操作之后,最终是否满足完整性约束,是否符合现实世界规则定义)
隔离性
隔离性(Isolation):隔离性是针对并发而言,用于隔离并发运行的多个事务,以避免产生相互影响。所谓的并发是指数据库服务器同时执行多个事务,如果在执行的过程中不采取有效的专门控制机制,并发事务之间会发生相互干扰
假设一种场景:在"小明给小红转账10元"这个事务发生的同时,"小明发工资了收到10元"。很明显这是两个不同的事务,正常逻辑来说小明转出10元,收到10元,其总余额应该是不变的。但是基于并发事务的场景,就有可能出现下列的情况
# 事务1
UPDATE account SET balance = balance - 10 WHERE id = 1; # 语句1 小明转出10
UPDATE account SET balance = balance + 10 WHERE id = 2; # 语句2 小红收到10
# 事务2
UPDATE account SET balance = balance + 10 WHERE id = 1; # 语句3 小明收到10
正常逻辑下,事务1、事务2先后执行都是符合场景的。但是如果事务1和事务2是并发的场景下,则可能出现语句1和语句3同时执行的情况,那么此时语句执行时获取到的balance都为10,假设事务1中的语句1先执行完balance变为15-10=5,事务2中的语句3紧随其后执行完balance会变为10+10=20,事务1中的语句2正常执行完结整个事务。那么此时小明更新后的balance就会固化到数据库中(balance为20),此时就会发现执行结果与预期并不一致(账户无缘无故多了10),这便是由于并发事务未隔离导致相互影响,从而衍生异常情况。
这种设想只是泛化的场景,还可细化到将语句在数据库中的执行拆解为多个补充,并发事务下每个步骤都可能存在交替执行的情况(可以理解为CPU资源优先,线程通过调度抢占资源,谁抢到谁优先执行)

持久性
持久性(Durability):事务一旦提交对数据的修改就是持久性的,数据已经从内存转移到了外部服务器上,并执行了固化的步骤(之后无论数据库出什么幺蛾子都与本次转换无关,数据被永久固化到磁盘空间)
3.事务的控制
支持事务的存储引擎
MySQL中通过show engines命令查看存储引擎属性,确认其是否支持事务
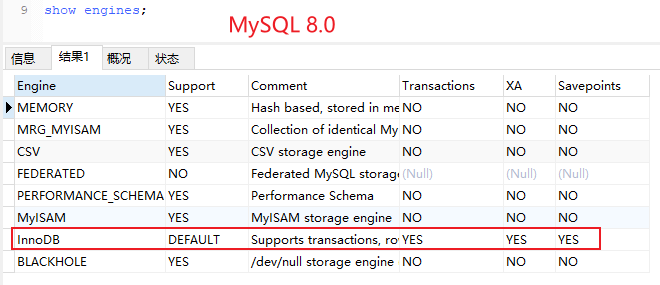
事务的控制
开启事务:
BEGIN [WORK]:开启事务,紧跟其后可以写若干条语句(都归与该事务)START TRANSACTION:开启事务(对比BEGIN其可限定条件(通过修饰符限定)),其格式为START TRANSACTION [修饰符],可限定多个修饰符以逗号隔开READ ONLY:标识为只读事务READ WRITE:标识为读写事务WITH CONSISTENT SNAPSHOT:启动一致性读
提交事务:
COMMIT [WORK]回滚:当发现事务中某些步骤出错了,可通过事务回滚来将数据库恢复到事务执行之前的样子
ROLLBACK [WORK]:手动回滚时使用(当事务在执行过程中遇到了某些错误而无法继续执行的话,事务自身会自动的回滚)
保存点:
- 定义保存点:
SAVEPOINT 保存点名称; - 指定保存点回滚:
OLLBACK [WORK] TO [SAVEPOINT] 保存点名称;
- 定义保存点:
自动提交:MySQL提供了一个自动提交的系统变量(默认ON),即在默认情况下如果不显式的使用
START TRANSACTION或者BEGIN语句开启一个事务,每一条语句都算是一个独立的事务,这种特性称之为事务的自动提交- 查看自动提交系统变量:
SHOW VARIABLES LIKE 'autocommit'; - 关闭自动提交:
- 方式1:显式的的使用
START TRANSACTION或者BEGIN语句开启一个事务,在本次事务提交或者回滚前会暂时关闭掉自动提交的功能。 - 方式2:把系统变量
autocommit的值设置为OFF(SET autocommit = OFF;)
- 方式1:显式的的使用
- 查看自动提交系统变量:
隐式提交:当取消掉自动提交后,发现输入某些语句之后被悄悄提交了,这些因为某些特殊的语句而导致事务提交的情况称为
隐式提交- 例如DDL语句(定义或修改数据库对象的数据定义语言):例如对数据库、表、视图、存储过程使用create、alter、drop语句
- 在一个事务还没提交或回滚的时候又使用
START TRANSACTION或者BEGIN语句开启了另一个事务时,会隐式的提交上一个事务
事务的隔离级别
1.并发事务导致的问题
隔离性是针对并发事务而言的,通过隔离多个并发事务避免其相互影响。MySQL 服务端是允许多个客户端连接的,这意味着 MySQL 会出现同时处理多个事务的情况,那么在同时处理多个事务的时候,就可能出现脏读(dirty read)、不可重复读(non-repeatable read)、虚读/幻读(phantom read)、丢失更新 的问题
脏读 :一个事务「读到」了另一个「已修改但未提交的数据」
对于两个事务T1,T2 。 T1读取了已经被T2更新但是还没有提交的字段之后,如果T2发生了回滚,T1读取的内容就是无效的
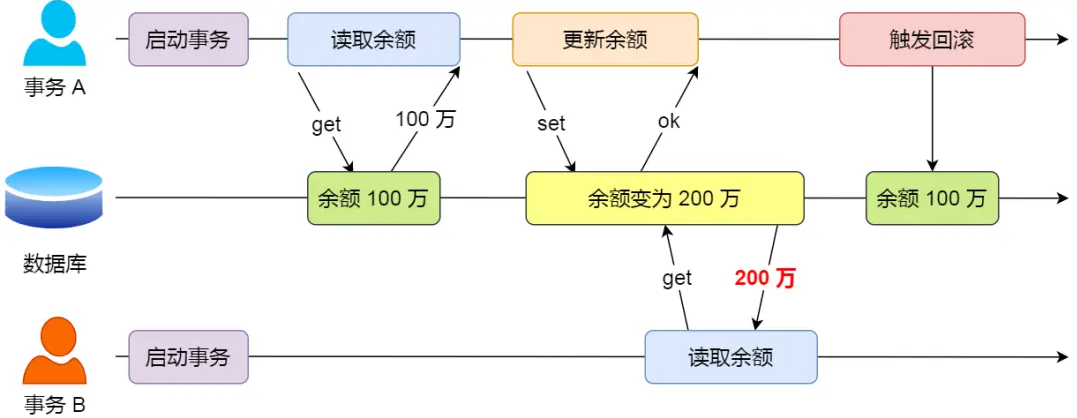
不可重复读:在一个事务内多次读取同一个数据,前后读取到的数据不一样
对于两个事务T1,T2。T1读了一个字段,在过程中T2更新了该字段之后,T1再次读取同一个字段,两次读取的值就是不同的
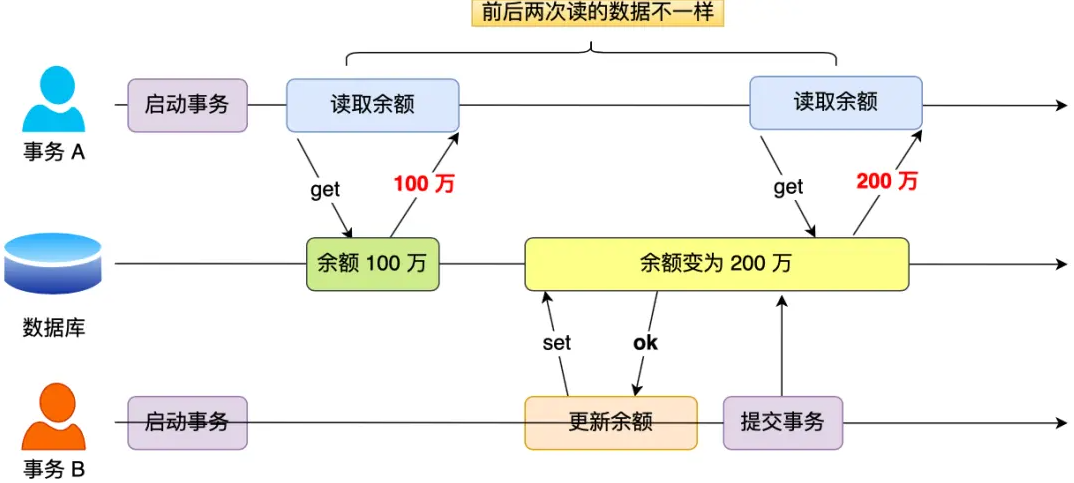
幻读(虚读):同一事务中,当同一个查询执行多次的时候,由于其他事务进行了插入操作并提交事务,导致每次返回不同的结果集
对于两个事务T1,T2 T1从一个表中读取一个字段,然后T2在该表中插入一个新的行之后,如果T1再次读取这个表发现数据行数变多
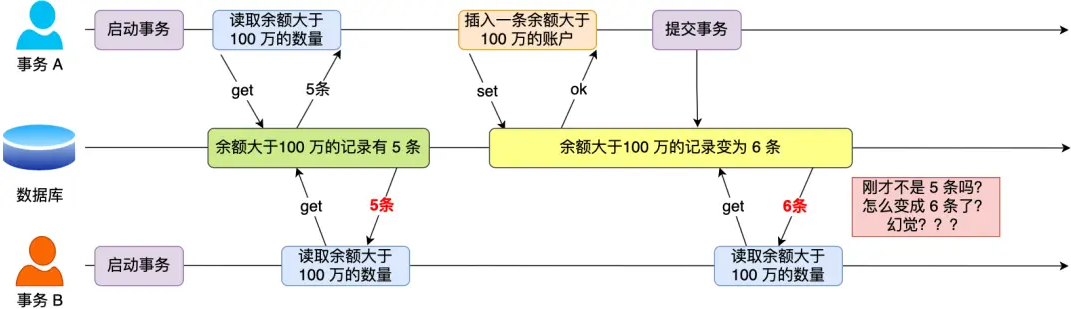
丢失更新:两个事务同时更新一行数据,一个事务对数据的更新把另一个事务对数据的更新覆盖了
2.针对并发问题设定的隔离级别
4种隔离级别
并发问题严重性:脏读 > 不可重复读 > 虚读/幻读
- 脏读:读到其他事务未提交的数据
- 不可重复读:前后读取同一数据,出现不一致
- 虚读/幻读:前后读取的记录数量不一致
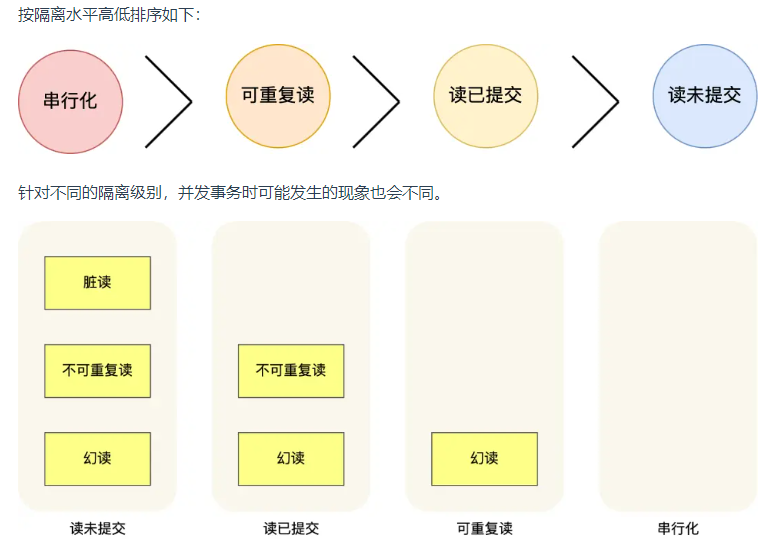
针对并发问题,SQL标准提出了四种隔离级别来规避这些现象,隔离级别越高,性能效率就越低,这四个隔离级别如下:
- 读未提交(read uncommitted),指一个事务还没提交时,它做的变更就能被其他事务看到;
- 读提交(read committed),指一个事务提交之后,它做的变更才能被其他事务看到;
- 可重复读(repeatable read),指一个事务执行过程中看到的数据,一直跟这个事务启动时看到的数据是一致的,MySQL InnoDB 引擎的默认隔离级别;
- 串行化(serializable);会对记录加上读写锁,在多个事务对这条记录进行读写操作时,如果发生了读写冲突的时候,后访问的事务必须等前一个事务执行完成,才能继续执行;
隔离级别如何实现
这四种隔离级别是如何实现?
- 读未提交:允许读到未提交事务修改的数据,因此直接读取最新数据即可
- 读已提交、可重复读:通过Read View实现(数据快照)
- 「读提交」隔离级别是在「每个语句执行前」都会重新生成一个 Read View
- 「可重复读」隔离级别是「启动事务时」生成一个 Read View,然后整个事务期间都在用这个 Read View
- 串行化:通过加读写锁的方式来避免并行访问(能解决所有并发问题,但效率最低)
MySQL 的开启事务命令:两种命令的主要区别在于启动时机不同
begin/start transaction命令:执行该命令后不代表事务启动,只有执行完该命令后执行了第一条select语句才是事务真正启动的时机start transaction with consistent snapshot命令:执行该命令就会马上启动事务
(1)何为MVCC?
Read View 在MVCC中如何工作?
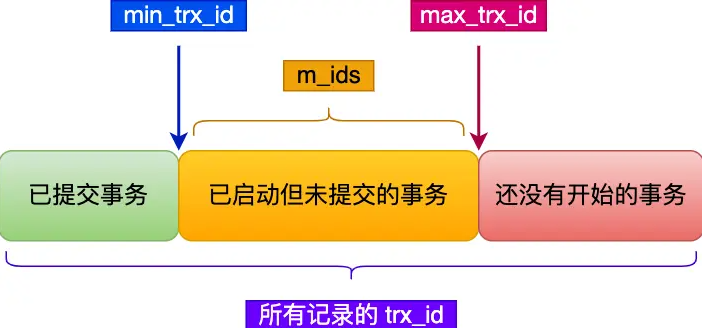
掌握Read View中 4 个字段的作用:creator_trx_id、m_ids、min_trx_id、max_trx_id
creator_trx_id:创建该Read View的事务的事务IDm_ids:创建Read View时,当前数据库中【活跃且未提交】的事务ID列表(此处【活跃事务】指的是活跃且未提交的事务)min_trx_id:创建Read View时,当前数据库中【活跃且未提交】的事务中最小事务的事务ID(即m_ids的最小值)max_trx_id:创建Read View时,当前数据库中应该给下一个事务的ID值(指全局事务中最大的事务ID值+1,并不是m_ids的最大值)
事务ID是递增分配的(比如现在有id为1,2,3这三个事务,之后id为3的事务提交,那么一个新的读事务在生成ReadView时,m_ids就包括1和2,min_trx_id的值就是1,max_trx_id的值就是4)
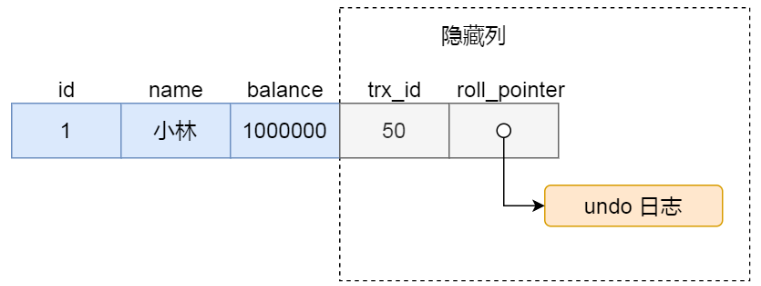
聚簇索引记录中的两个隐藏列:
trx_id:当一个事务对某条聚簇索引记录进行改动时,就会把该事务的事务 id 记录在 trx_id 隐藏列里roll_pointer:每次对某条聚簇索引记录进行改动时,都会把旧版本的记录写入到 undo 日志中,这个隐藏列是个指针,指向每一个旧版本记录,可以通过它找到修改前的记录
假设在账户余额表插入一条余额为 100 万的记录,然后把这两个隐藏列也画出来,该记录的整个示意图如下
在创建Read View后,可以将记录中的 trx_id 划分这三种情况:
一个事务去访问记录的时候,除了自己的更新记录总是可见之外,还有几种情况:
- 如果记录的 trx_id 值小于 Read View 中的
min_trx_id值,表示这个版本的记录是在创建 Read View 前已经提交的事务生成的,所以该版本的记录对当前事务可见 - 如果记录的 trx_id 值大于等于 Read View 中的
max_trx_id值,表示这个版本的记录是在创建 Read View 后才启动的事务生成的,所以该版本的记录对当前事务不可见 - 如果记录的 trx_id 值在 Read View 的
min_trx_id和max_trx_id之间,需要判断 trx_id 是否在 m_ids 列表中:- 如果记录的 trx_id 在
m_ids列表中,表示生成该版本记录的活跃事务依然活跃着(还没提交事务),所以该版本的记录对当前事务不可见 - 如果记录的 trx_id 不在
m_ids列表中,表示生成该版本记录的活跃事务已经被提交,所以该版本的记录对当前事务可见
- 如果记录的 trx_id 在
这种通过「版本链」来控制并发事务访问同一个记录时的行为就叫 MVCC(多版本并发控制),**所谓版本链控制是通过对比「事务的 Read View 里的字段」和「记录中的两个隐藏列」**来实现的
场景案例:设定一种场景来拆解不同隔离级别的工作原理,以及对应隔离级别可以或者不可以解决什么并发问题
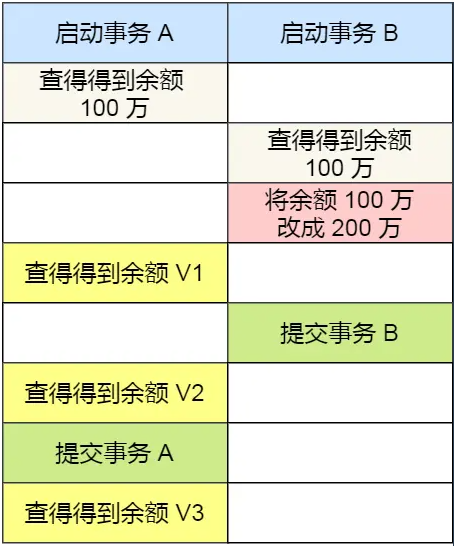
有一张账户余额表,里面有一条账户余额为 100 万的记录。然后有两个并发的事务,事务 A 只负责查询余额,事务 B 则会将余额改成 200 万,下面是按照时间顺序执行两个事务的行为
(2)可重复读是如何工作的(Read View + redo logo)
可重复读的实现原理是通过Read View实现的,在启动事务时生成一个 Read View,然后整个事务期间都在用这个 Read View
假设事务 A (事务 id 为51)启动后,紧接着事务 B (事务 id 为52)也启动了,那这两个事务创建的 Read View 如下:
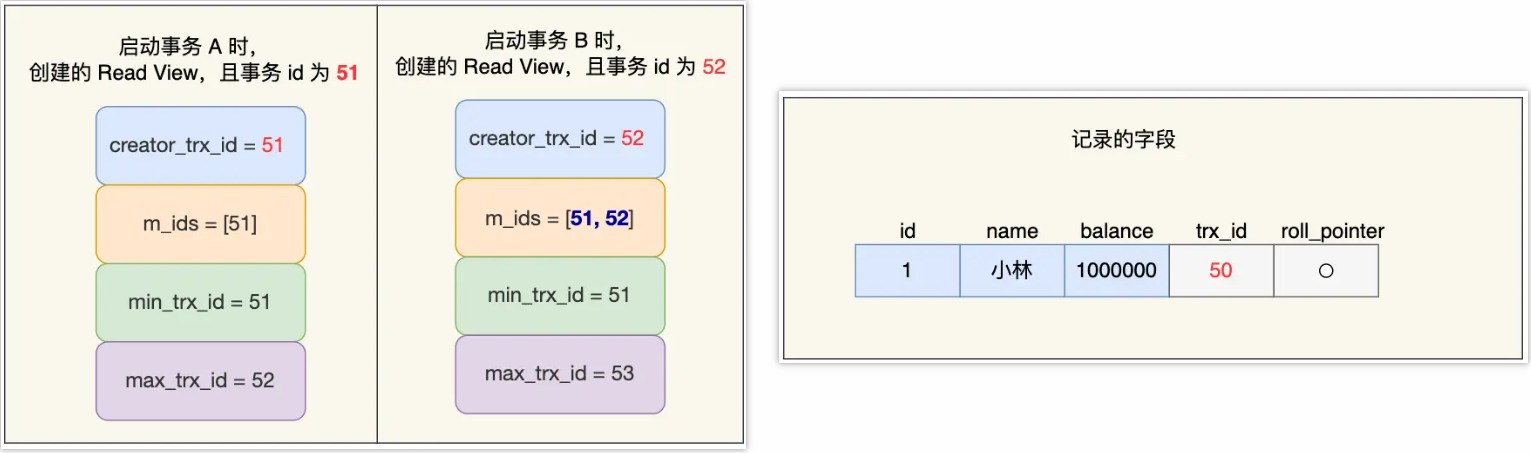
结合Read View的4个字段属性,分析Read View的具体内容:
- 在事务 A 的 Read View 中,它的事务 id 是 51,由于它是第一个启动的事务,所以此时
m_ids就只有 51,min_trx_id是事务 A 本身,下一个事务 id 则是 52 - 在事务 B 的 Read View 中,它的事务 id 是 52,由于事务 A 是活跃的,所以此时
m_ids有51、52,min_trx_id是事务A(51),下一个事务 id 应该是 53
在可重复读隔离级别下,事务A、事务B按顺序执行了以下操作:
- ①事务 B 读取账户余额记录,读到余额是 100 万;
- ②事务 A 将账户余额记录修改成 200 万,并没有提交事务;
- ③事务 B 读取账户余额记录,读到余额还是 100 万;
- ④事务 A 提交事务;
- ⑤事务 B 读取账户余额记录,读到余额依然还是 100 万;
拆解这一过程,分析如下:
- ①事务B第一次读取账户余额记录,对比事务B的Read View的参数:发现min_trx_id(51)>50,则说明修改该记录的事务在事务B启动前就提交过了,因此该记录对事务B是可见的(即事务B可以读取到这条记录)
- ②事务 A 通过update语句修改记录(但未提交),将对应用户余额修改为200W,此时MySQL会记录相应的
undo log,并以链表的方式串联起来形成版本链:由于事务A修改了该记录,以前的记录变为旧版本记录,最新的记录和旧版本记录通过链表方式串接起来,最新记录的trx_id就是事务A的事务ID(trx_id=51)
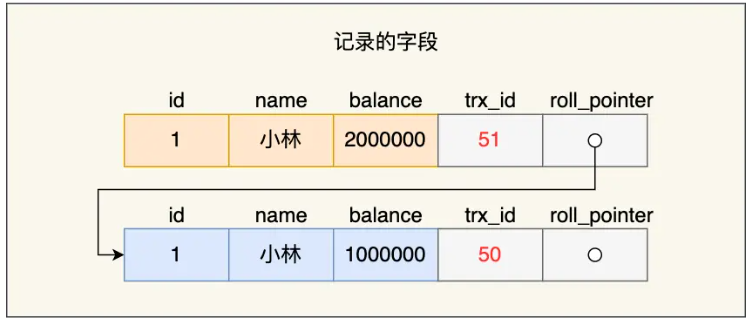
- ③事务B读取账户余额记录,由于隔离级别的可重复读,读取的Read View还是基于事务启动时创建的:发现trx_id(51)在min_trx_id~max_trx_id之间,则需判断trx_id值是否在m_ids范围内,判断结果是在的(则说明这条记录是被还没提交的事务修改的),因此当前的记录版本对事务B来说是不可见的(即事务B不会读取这个版本的记录),而是继续沿着
undo log链条确认旧版本的值,直到找到符合【trx_id小于事务B的Read View中的min_trx_id】这一条件的第一条记录(即此处对照为trx_id=50的版本记录),因此此时事务B读取的余额为100W - ④事务A提交事务
- ⑤事务B再次读取账户余额记录,由于隔离级别的可重复读,由于隔离级别的可重复读,读取的Read View还是基于事务启动时创建的,因此此处就算事务A将余额修改为200W并提交了事务,按照参数分析,事务B此时读取的还是100W这条记录
结合上述步骤分析,可重复读隔离级别通过启动事务时生成一个 Read View,然后整个事务期间都在用这个 Read View,搭配undo log构建MVCC,进而确保「可重复读」隔离级别下在事务期间读到的记录都是事务启动前的记录
【可重复读】隔离级别解决了脏读、不可重复读问题
(3)读已提交是如何工作的
读已提交的实现原理是通过Read View实现的,在每次读取数据时,都会生成一个新的 Read View
也意味着,事务期间的多次读取同一条数据,前后两次读的数据可能会出现不一致,因为可能这期间另外一个事务修改了该记录,并提交了事务
假设假设事务 A (事务 id 为51)启动后,紧接着事务 B (事务 id 为52)也启动了,接着按顺序执行了以下操作:
- ①事务 B 读取数据(创建 Read View),小林的账户余额为 100 万;
- ②事务 A 修改数据(还没提交事务),将小林的账户余额从 100 万修改成了 200 万;
- ③事务 B 读取数据(创建 Read View),小林的账户余额为 100 万;
- ④事务 A 提交事务;
- ⑤事务 B 读取数据(创建 Read View),小林的账户余额为 200 万;

- ①事务B读取数据:使用的是启动事务B后第一次创建的Read View,此时min_trx_id为50,因此事务B读取到的版本是100W(是被其他事务已提交的)
- ②事务A修改数据但未提交,构建版本链
- ③事务B读取数据:使用的是新创建的Read View,此时min_trx_id为50,会沿着版本链寻找满足条件的第一条记录,因此读取到的版本是100W
- ④事务A提交事务
- ⑤事务B读取数据:使用的是新创建的Read View(参考下图所示:因为事务A已经提交,因此从活跃事务中剔除),此时min_trx_id为52,且发现trx_id为51,因此读取的版本是200W
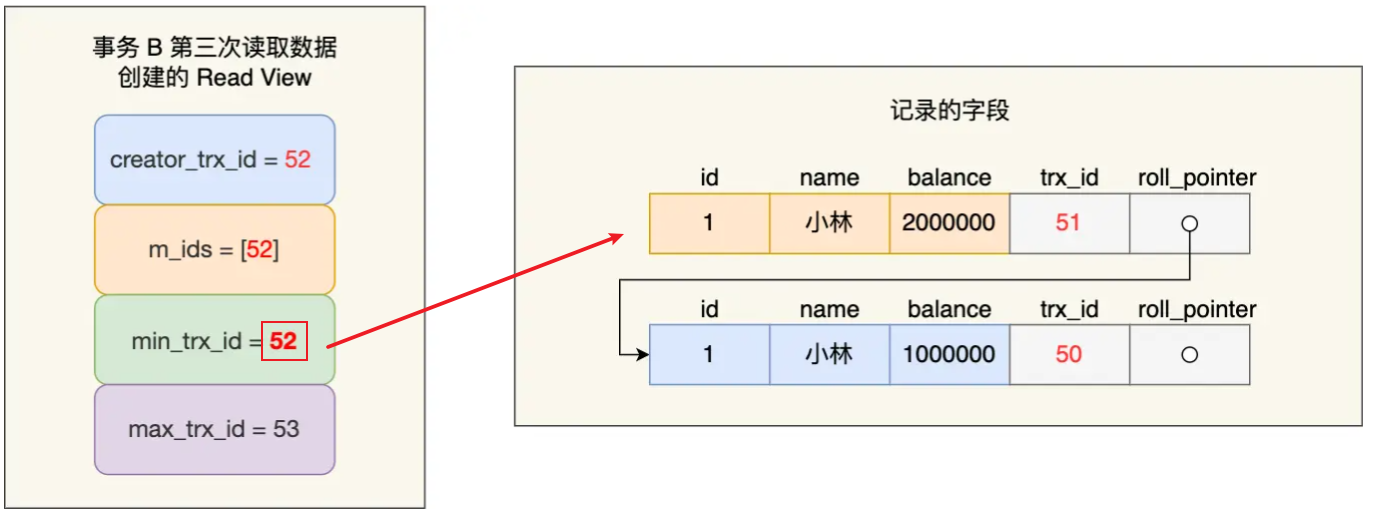
结合上述步骤分析,在读提交隔离级别下,事务每次读数据时都重新创建 Read View,那么在事务期间的多次读取同一条数据,前后两次读的数据可能会出现不一致,因为可能这期间另外一个事务修改了该记录,并提交了事务
【读已提交】隔离级别解决了脏读问题
(4)MySQL的可重复读隔离级别是否完全解决幻读问题?
要解决脏读现象,就要将隔离级别升级到读已提交以上的隔离级别;要解决不可重复读现象,就要将隔离级别升级到可重复读以上的隔离级别。而对于幻读现象,不建议将隔离级别升级为串行化,因为这会导致数据库并发时性能很差。MySQL InnoDB 引擎的默认隔离级别虽然是「可重复读」,但是它很大程度上避免幻读现象,其解决方案有两种:
- 针对快照读(普通 select 语句),是 通过 MVCC 方式解决了幻读,因为可重复读隔离级别下,事务执行过程中看到的数据,一直跟这个事务启动时看到的数据是一致的,即使中途有其他事务插入了一条数据,是查询不出来这条数据的,所以就很好了避免幻读问题
- 针对当前读(select ... for update 等语句),是通过 next-key lock(记录锁+间隙锁)方式解决了幻读,因为当执行 select ... for update 语句的时候,会加上 next-key lock,如果有其他事务在 next-key lock 锁范围
所谓幻读:当同一个查询在不同的时间产生不同的结果集时,事务中就会出现所谓的幻象问题。例如,如果 SELECT 执行了两次,但第二次返回了第一次没有返回的行,则该行是“幻像”行
举个例子,假设一个事务在 T1 时刻和 T2 时刻分别执行了下面查询语句,途中没有执行其他任何语句:只要 T1 和 T2 时刻执行产生的结果集是不相同的,那就发生了幻读的问题
SELECT * FROM t_test WHERE id > 100;
- T1 时间执行的结果是有 5 条行记录,而 T2 时间执行的结果是有 6 条行记录,那就发生了幻读的问题
- T1 时间执行的结果是有 5 条行记录,而 T2 时间执行的结果是有 4 条行记录,也是发生了幻读的问题
快照读如何避免幻读?
可重复读隔离级是由 MVCC(多版本并发控制)实现的,实现的方式是开始事务后(执行 begin 语句后),在执行第一个查询语句后,会创建一个 Read View,后续的查询语句利用这个 Read View,通过这个 Read View 就可以在 undo log 版本链找到事务开始时的数据,所以事务过程中每次查询的数据都是一样的,即使中途有其他事务插入了新纪录,是查询不出来这条数据的,所以就很好了避免幻读问题
当前读如何避免幻读?
MySQL 里除了普通查询是快照读,其他都是当前读,比如 update、insert、delete,这些语句执行前都会查询最新版本的数据,然后再做进一步的操作
另外,select ... for update 这种查询语句是当前读,每次执行的时候都是读取最新的数据。针对加锁、不加锁的场景拆解当前读的执行流程
假设select ... for update不加锁,此时事务A在T2时刻是当前读,读取的是事务B插入的记录,就会出现T1、T2前后两次查询的结果集合不同,导致出现幻读
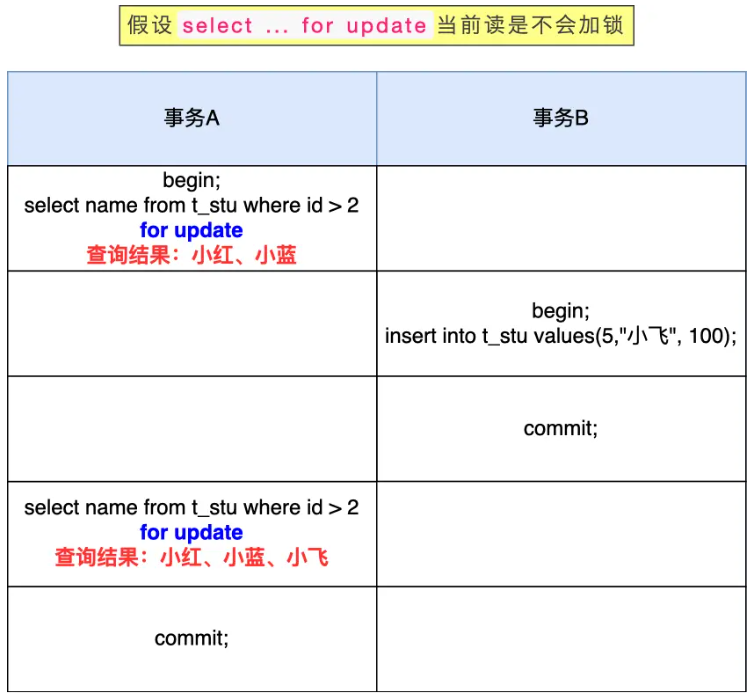
因此,Innodb 引擎为了解决「可重复读」隔离级别使用「当前读」而造成的幻读问题,就引出了间隙锁。假设,表中有一个范围 id 为(3,5)间隙锁,那么其他事务就无法插入 id = 4 这条记录了,这样就有效的防止幻读现象的发生

以上述案例进行拆解,事务 A 执行了这面这条锁定读语句后,就在对表中的记录加上 id 范围为 (2, +∞] 的 next-key lock(next-key lock 是间隙锁+记录锁的组合)。事务 B 在执行插入语句的时候,判断到插入的位置被事务 A 加了 next-key lock,于是事物 B 会生成一个插入意向锁,同时进入等待状态,直到事务 A 提交了事务。这就避免了由于事务 B 插入新记录而导致事务 A 发生幻读的现象
幻读现象并没有完全解决:可重复读隔离级别下虽然很大程度上避免了幻读,但是还是没有能完全解决幻读
【幻读场景1】:在可重复读隔离级别下,事务 A 第一次执行普通的 select 语句时生成了一个 ReadView,之后事务 B 向表中新插入了一条 id = 5 的记录并提交。接着,事务 A 对 id = 5 这条记录进行了更新操作,在这个时刻,这条新记录的 trx_id 隐藏列的值就变成了事务 A 的事务 id,之后事务 A 再使用普通 select 语句去查询这条记录时就可以看到这条记录了,于是就发生了幻读
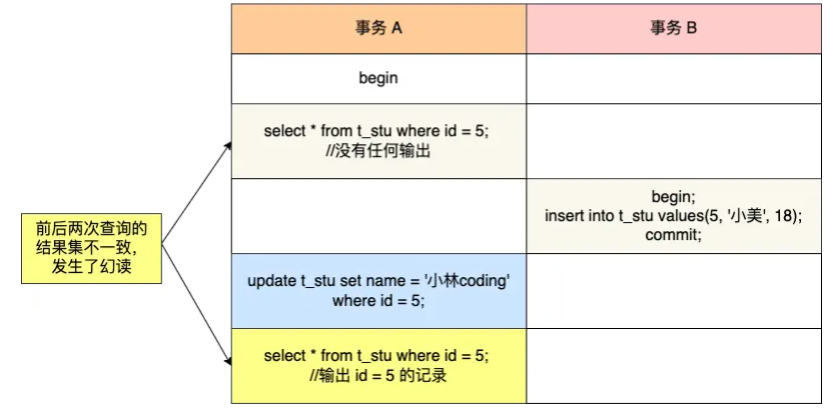
【幻读场景2】:快照读、当前读组合
- T1 时刻:事务 A 先执行「快照读语句」:select * from t_test where id > 100 得到了 3 条记录。
- T2 时刻:事务 B 往插入一个 id= 200 的记录并提交;
- T3 时刻:事务 A 再执行「当前读语句」 select * from t_test where id > 100 for update 就会得到 4 条记录,此时也发生了幻读现象
要避免这类特殊场景下发生幻读的现象的话,就是尽量在开启事务之后,马上执行 select ... for update 这类当前读的语句,因为它会对记录加 next-key lock,从而避免其他事务插入一条新记录