【BI】⑦引入RabbitMQ
【BI】⑦引入RabbitMQ
交换机
1.direct交换机
绑定:允许我们将交换机和队列关联起来,并指定交换机将哪种类型的消息发送给哪个队列(类似计算机网络中两个路由器或网络设备相互连接的情况,也可以理解为网线)。
routingKey:路由键,控制消息要转发给哪个队列的(IP 地址)。
特点:消息会根据路由键转发到指定的队列。
场景:特定的消息只交给特定的系统(程序)来处理绑定关系:完全匹配字符串。
示例场景:发日志的场景,希望用独立的程序来处理不同级别的日志,比如 C1 系统处理 error 日志,C2 系统处理其他级别的日志。
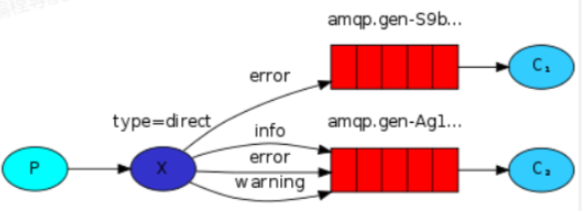
进一步说明:
(1)绑定 可以被理解为在网络中建立连接,就像你想要接入互联网并接收他人发送的消息时,你需要将你的网络1.与路由器建立连接,这就相当于插上一根网线。这种绑定可以被视为网络中的一根网线它将你的网络与互联网或服务器进行了连接。在计算机网络中,我们如何确定服务器发送的消息要发送给谁,或者由谁来接收这个消息呢?这涉及一定的路由规则。在计算机网络中,我们通过什么规则来确定消息的接收者或发送者呢?实际上,将绑定视为计算机网络中的路由是很好理解的。绑定类似于计算机网络中两个路由器或网络设备相互连接,也可以将其理解为一根网线的连接。这种绑定和连接的关系可以帮助我们在网络中实现消息的传递和路由。
(2)路由键可以类比于数据库中的 WHERE 条件吗?路由器很像 IP 地址,也可以称为路由表。称之为路由表是合适的,因为路由表存储了路由关系。可以简单地将其理解为IP 地址,我们如何知道一条消息要发送给哪台机器呢?假设我们要将消息从我们的计算机发送到位于北京的服务器,那么我们肯定需要知道对方的 IP 地址或者域名,而域名最终会被解析成IP 地址。因此,你可以将路由键理解为IP 地址。简单的理解并不能完全等同,但将其视为路由表也是可以的。因为路由表实际上存储了一些规则。对于路由键的概念,我们不必过于纠结,它更像是一种规则。
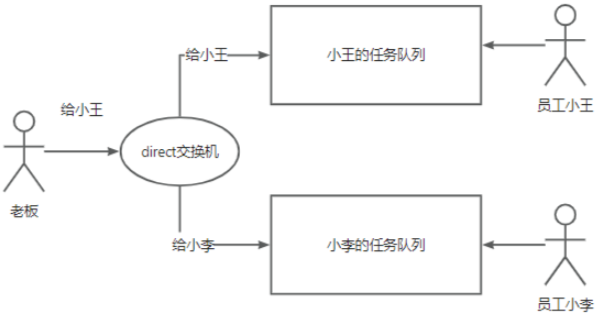
(3)场景举例:让我们以老板分配工作的情景为例。以前,老板发布一个任务,所有员工都能收到。但现在,我们有小王的任务队列和小李的任务队列。然而,老板只想给小王发送任务,应该怎么做呢?我们只需将任务发送到小王的队列,fanout 交换机无法满足需求,这时,我们可以使用 direct 交换机。通过建立一个绑定关系,如果老板的任务是给小王的,它会被发送到小王的队列;如果任务是给小李的,它会被发送到小李的队列。在这种情况下,老板发送任务相当于给任务一个名称或标识。例如,如果任务是给小王的,它会被发送到小王的队列,这样小李就不需要处理这个任务。从系统的角度来看,相当于这个消息是给A系统处理任务的,而不是给其他的系统。
(4)同一个路由键是不是只能绑定给一个队列,就是不能重名呢?其实不是,你可以用同样的路由键。例如,如果你想让小王和小李都收到发给小王的任务,你可以将交换机和小李的任务队列都绑定到相同的路由键。可以使用相同的规则,一个路由键可以绑定多个队列。官方文档中也提供了一个类似的例子:如果发送一条带有路由键为 black 的消息,那么这条消息会被发送到这两个队列吗?答案是肯定的。只要消息的路由键与交换机绑定的路由键一致,它就会被转发。
(5)交换机是否存储了所有的路由键,可以这样理解吗?可以。交换机知道它具有哪些路由键,以及每个路由键应该将消息路由到哪个队列。它类似于一个物流分发员,负责将货物传递到快递站。换句话说,交换机了解所有这些规则。
(6)可以将要发送的消息绑定到两个不同的路由键,而不改给小王或小李的标识?可以。这种场景实际上有其他规白.则可以适用。我们稍后还会学习到另一种适用于这种场景的交换机类型。此外,你也可以发送两条消息,一条发送给小王,另一条发送给小李,这也是可行的,可以发送两次消息。
继续看第四个官方示例Routing,首先他给我们讲了一下路由的概念,如果我们想让部分队列只接收交换机的消息,或者让交换机的消息只发送给特定的队列,以前我们无法实现这样的需求。但现在,我们可以学习一个新的概念,即绑定。
channel.queueBind(queueName, EXCHANGE_NAME, "");
// 参数:队列名称、交换机名称、路由建(routingKey)
当指定一个交换机后,必须确保我们的队列与该交换机进行了绑定,这样交换机才能将消息转发到该队列。这个绑定可以通过 queueBind 来实现,需要传递消息队列的名称和交换机的名称作为参数进行绑定。除此之外,queueBind 还有第三个参数:路由键(routingKey)
参考下图图示1,将交换机和队列Q1绑定,绑定的路由键是orange,其表示当发送一条带有路由键为orange的的消息,它会被转发到Q1队列(通过路由键决定将消息发送给哪个队列,从而控制消息的转发规则)
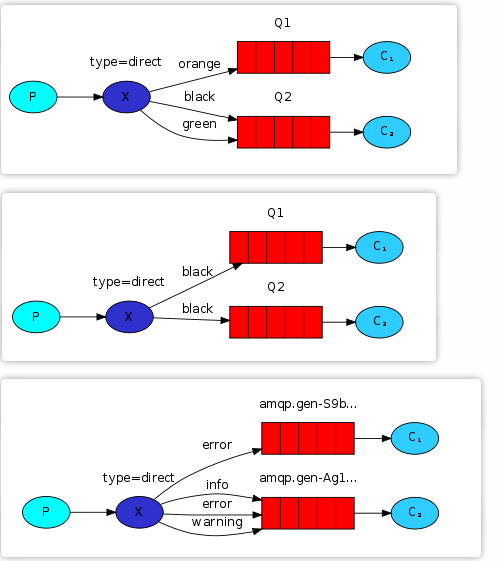
案例分析:假设需要发送日志,而上游系统或生产者会产生大量的日志消息。例如,QQ的注册消息,包括用户A的注册和用户B的注册,以及注册失败的消息,如用户A注册失败和用户B注册失败。如果有两个系统处理消息,一个负责处理所有失败的消息,另一个系统负责处理非失败的消息,那么使用 direct 交换机模型非常适合这种情况(参考上图图示3)
场景分析:老板指派任务,分别指定到对应的人,如果指定的人不存在则这个任务会被丢弃
生产者:
public class DirectProducer {
// 定义交换机名称
private static final String EXCHANGE_NAME = "direct-exchange";
public static void main(String[] argv) throws Exception {
// 创建工厂、设置属性
ConnectionFactory factory = new ConnectionFactory();
factory.setHost("localhost");
// 创建连接、通道
try (Connection connection = factory.newConnection();
Channel channel = connection.createChannel()) {
channel.exchangeDeclare(EXCHANGE_NAME, "direct");
// 获取严重程度(路由键)和消息内容(模拟从控制台输入)
// String severity = getSeverity(argv);
// String message = getMessage(argv);
Scanner scanner = new Scanner(System.in);
while (scanner.hasNext()) {
// 读取用户输入信息(约定格式:routingKey,message)
String userInput = scanner.nextLine();
String[] userInputs = userInput.split(",");
// 校验输入格式,如果满足则继续读取下一行
if(userInputs.length<1){
continue;
}
// 获取路由键和消息内容进行封装
String routingKey = userInputs[0];
String message = userInputs[1];
// 发布消息到交换机
channel.basicPublish(EXCHANGE_NAME, routingKey, null, message.getBytes("UTF-8"));
System.out.println(" [x] Sent '" + "':'" + message + "' with routingKey: " + routingKey);
}
}
}
}
消费者:
public class DirectConsumer {
// 定义交换机名称
private static final String EXCHANGE_NAME = "direct-exchange";
public static void main(String[] argv) throws Exception {
// 创建工厂设置属性
ConnectionFactory factory = new ConnectionFactory();
factory.setHost("localhost");
Connection connection = factory.newConnection();
Channel channel = connection.createChannel();
channel.exchangeDeclare(EXCHANGE_NAME, "direct");
// 创建队列,随机分配一个队列名称,并绑定到xiaowang路由键
String queueWang = "queue_xiaowang";
// 声明队列:设置队列为持久化的、非独占的、非自动删除的
channel.queueDeclare(queueWang, true, false, false, null);
// 将队列绑定到指定的交换机上,指定绑定的路由键为xiaowang
channel.queueBind(queueWang, EXCHANGE_NAME, "xiaowang");
// 创建队列,随机分配一个队列名称,并绑定到xiaoli路由键
String queueLi = "queue_xiaoli";
// 声明队列:设置队列为持久化的、非独占的、非自动删除的
channel.queueDeclare(queueLi, true, false, false, null);
// 将队列绑定到指定的交换机上,指定绑定的路由键为xiaoli
channel.queueBind(queueLi, EXCHANGE_NAME, "xiaoli");
// 打印等待消息
System.out.println(" [*] Waiting for messages. To exit press CTRL+C");
// 分别创建两个交付回调函数(模拟小王和小李回调交付)
DeliverCallback deliverCallbackWang = (consumerTag, delivery) -> {
String message = new String(delivery.getBody(), "UTF-8");
System.out.println(" [小王冲冲冲] Received '" + message + "' with routing key '" + delivery.getEnvelope().getRoutingKey() + "'");
};
DeliverCallback deliverCallbackLi = (consumerTag, delivery) -> {
String message = new String(delivery.getBody(), "UTF-8");
System.out.println(" [小李] Received '" + message + "' with routing key '" + delivery.getEnvelope().getRoutingKey() + "'");
};
// 消费指定队列消息,设置自动确认消息已被消费
channel.basicConsume(queueWang, true, deliverCallbackWang, consumerTag -> { });
channel.basicConsume(queueLi, true, deliverCallbackLi, consumerTag -> { });
}
}
测试
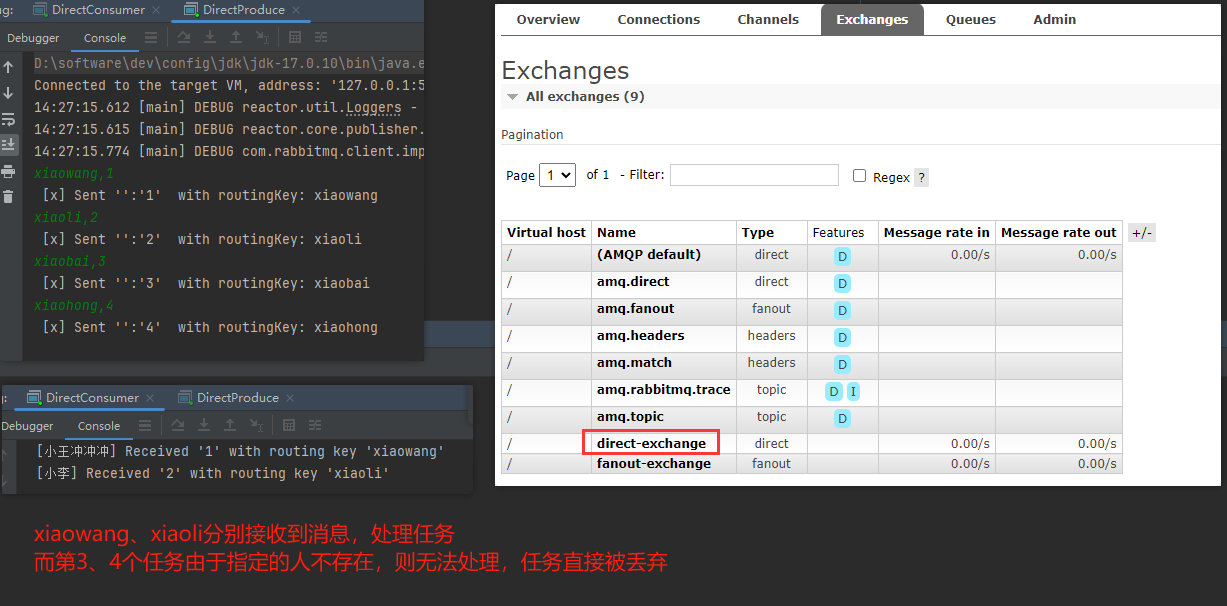
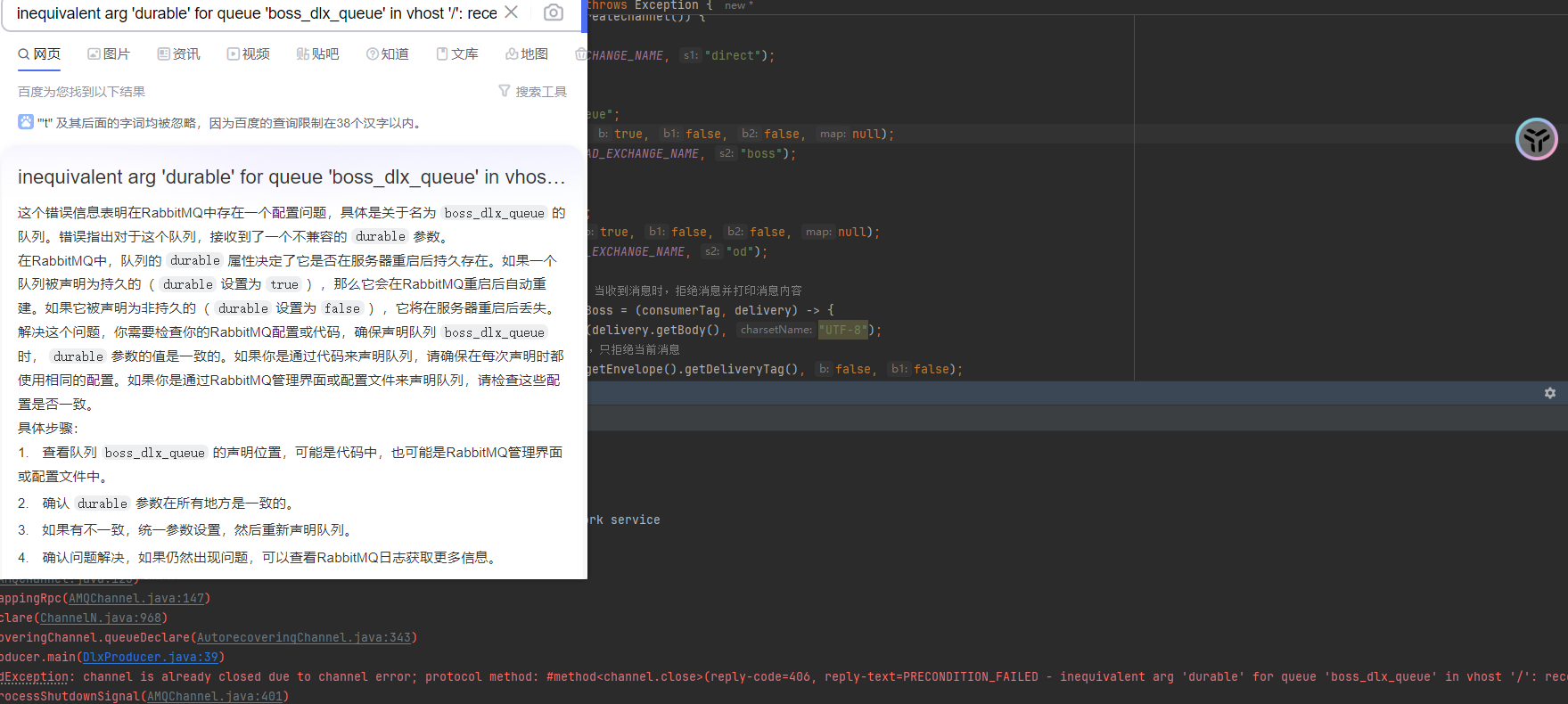
direct交换机规则:根据对应的交换机,查看任务指派情况,发现如果没有这个消费者或者routingKey,则交换机不知道将消息放到哪里,所以会直接丢掉
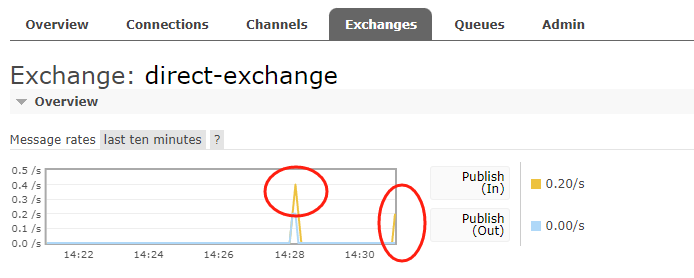
因为没有这个消费者或者说路由键,这个交换机不知道该把消息放到哪里,所以它就会把这个消息丢掉,这个就是 direct 交换机的规则。
2.Topics交换机
是否可以让老板发送一条消息,使所有员工都能收到,并且能够区分只有部分人能接收的情况。Topic交换机类型正是非常适用于这种场景:
特点:消息会根据一个 模糊的 路由键转发到指定的队列
场景:特定的一类消息可以交给特定的一类系统(程序)来处理
绑定关系:可以模糊匹配多个绑定匹配一个单词,
*.orange:a.orange、b.orange 都能匹配#:匹配0个或多个单词,比如 a.#,那么 a.a、a.b、a.a.a 都能匹配注意:这里的匹配和 MSQL的 like 的 % 不一样,只能按照单词来匹配,每个
'.'分隔单词,如果是'#.',其实可以忽略,匹配 0个词也 ok。
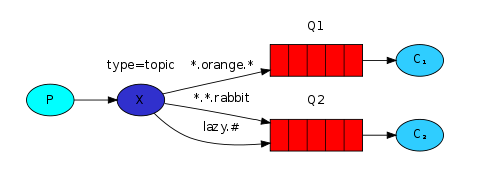
topic交换机的关键:根据模糊的路由键将消息转发到指定的队列(可以是一个或者多个队列)
这种场景适用于什么情况呢?适用于将特定类型的消息交给特定类型的系统来处理。通过这种方式,我们可以对消息队列和消息进行分类。你可以将其理解为分类的概念。 举个例子,我们仍然使用之前的模型来说明。现在我们的团队变得越来越庞大,不再只有两个员工。我们现在有一个前端组任务队列,一个后端组任务队列,还有一个产品组任务队列。每个组下面可以有多个员工,多个系统,具体如何划分我们不管。
应用场景:老板下发一个任务,让多个组处理

现在,我们的老板要发布任务了。以前使用 direct 交换机只能将任务分发给前端或后端。如果我们要给产品组任务,就需要绑定一个路由键,比如“给产品"。如果我们使用 direct 交换机,老板只能这样下发任务。但是,假设现在有一个任务,需要前端和后端协作完成,那么如何指定两个路由键呢?难道只能先给前端发送消息,再给后端发送消息?这实际上很麻烦,因为你要发送两个消息,性能肯定不如发送一条消息高。因此,在这种情况下,我们可以使用 topic 交换机。 将任务发送给 topic 交换机,topic 交换机会检查你的任务的路由键是否与它的绑定关系匹配。以前,精确匹配是指消息与一个路由键完全匹配,我们之前的 direct 交换机就是精确匹配。但是,现在的 topic 交换机的绑定关系可以模糊匹配多个绑定。
我们前端使用井号进行匹配,例如“#.前端.#”,只要任务中包含了"前端”这个字符串,就会将任务发送给前端。后端和产品同理。这样的话,当老板发布一个前后端都需要的任务时,这个任务会经过交换机进行匹配。交换机会发现前端匹配成功,就将任务发送给前端;同时发现后端也匹配成功,就将任务发送给后端。这样,一条消息就可以被发送到多个队列中。微信朋友圈的分组逻辑也可以用这个来实现。对于匹配的需求,使用星号可能存在一些限制。星号在匹配时占据一个单词的位置,并且中间的两个点之间的单词是固定的,这导致了无法匹配的情况。
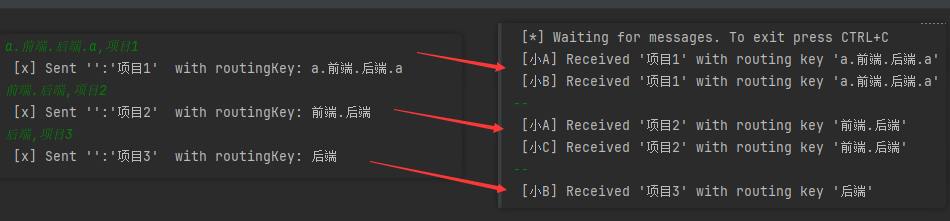
启动生产者、消费者模拟操作,分别发派如下任务(测试不同组合,校验统配符匹配规则)
a.前端.后端.a,项目1
前端.后端,项目2
后端,项目3
3.RPC交换机
RPC(远程过程调用)是一种技术,它允许不同的程序在网络上进行通信和交互,就像调用本地函数一样。使用 RPC,我们可以通过远程调用方式实现程序之间的内部通信。然而,在实际应用中,RPC的使用场景相对较少。一般情况下,如果只是实现两个程序之间的内部通信,并没有必要借助消息队列来模拟 RPC。你可以使用专门的 RPC框架,如 GRPC 或其他双工通信框架来完成。并不需要将消息队列用于模拟 RPC。
注意:消息队列并不是为了模拟 RPC而存在的,它有其独特的使用场景。当选择使用 Redis 时,有些人可能会使用 Redis 来模拟消息队列,就像黑马点评课程中所提到的那样。然而,一般情况下,并没有必要这样做。因为 Redis 主要用于缓存和分布式数据存储,而消息队列则用于消息传输和发布订阅。我们应该根据特定的技术和业务场景选择合适的技术方案,而不是强行使用某个技术来实现不适合的功能。虽然某些技术提供了这样的功能,但并不意味着我们非要使用它来实现。
4.Headers交换机
类似于主题和直接交换机,可以根据消息的 headers(头部信息)来确定消息应发送到哪个队列。这种方式不是像之前那样指定一个路由键,而是根据消息的头部信息进行匹配,以确定消息要发送到哪个队列。然而,由于性能较差目相对复杂,一般情况下并不推荐使用这种方式。
RabbitMQ核心特性
1.消息过期机制
可以给每条消息指定一个有效期,一段时间内未被消费者处理,就过期了,
示例场景:消费者(库存系统)挂了,一个订单 15 分钟还没被库存系统处理,这个订单其实已经失效了,怕库存系统再恢复,其实也不用扣减库存。
适用场景:清理过期数据、模拟延迟队列的实现(不开会员就慢速)、专门让某个程序处理过期请求。
进一步说明: 消息过期机制是干嘛的?消息过期机制是用来处理那些在一段时间内未被处理的消息。顾名思义,当一条消息1.在一定时间内未被消费者处理时,它就会过期,即失效。这种机制允许系统自动清理和丢弃那些长时间未被消费的消息,以避免消息队列中积累过多的过期消息,从而保持系统的效率和可靠性。
消息过期机制有什么应用场景?举个例子,假设一个用户向一个新系统发送了一个请求,比如支付订单。订单2通常有一个有效期限,比如 15 分钟。如果在这 15 分钟内,下游系统没有及时处理该订单,这可能意味着下游系统出现了故障,或者在这个时间段内不再需要处理该订单了,在这种情况下,如果将该消息放入队列中并设置了 15 分钟的过期时间,那么如果 15 分钟后还没有消费者来获取该消息,该支付订单消息就会过期。订单在 15 分钟内没有支付,那么该订单就已经失效了。下游系统就不再需要处理这个订单,也不需要更新库存或处理物流等相关操作。因此,消息过期机制非常适用于这种过期场景的处理。通过设置合适的过期时间,可以确保及时清理无效的消息,提高系统的效率和准确性。
3.什么叫延迟队列呢?它允许将消息延迟一段时间后再进行处理。举个例子,假设我们有一个程序,要求在用户进行某项操作之后不是立即处理,而是延迟几分钟后再执行。这种情况下,延迟队列可以派上用场。让我们以区分普通用户和会员用户的场景为例,对于会员用户,我们希望立即处理其请求;而对于普通用户,我们希望让其排队等待一段时间(比如5分钟)后再进行处理,以鼓励其购买会员。这时,可以利用延迟队列实现。消费者可以监听延迟队列,普通用户的请求由一个程序处理监听该延迟队列,而会员用户的请求则由另一个程序监听一个高优先级的队列。一旦你掌握了消息队列的知识,就可以实现这样的程序逻辑。延迟队列的实现可以借助消息过期机制。具体的实现思路是创建两个队列,第一个队列中的消息设置了过期时间,比如5分钟,然后将过期的消息转移到第二个队列中。接着,让相应的用户程序监听第二个队列,这样第二个队列就成为了延迟队列。实际上,这个思路与我们将要讨论的死信队列有一些相似之处,因为它们都涉及到特定的场景和处理
官方文档下的Doc中的Queue and Message TTL,3-12 版本
如何设置消息过期机制:针对每条消息设置过期时间(给消息增加属性)或者给队列指定过期时间
相当于是两种消息过期机制: 第一种方式是给队列中的所有消息指定一个统一的过期时间。也就是说,无论何时进入这个队列的消息,在特定的时间点都会过期失效。这种方式是针对整个队列而言。 第二种方式是给某条具体的消息指定过期时间。这意味着,针对特定的消息,我们可以指定一个独立的过期时间。这样,在达到指定的时间后,这条消息将会过期并自动失效。这两种方式在应用中具有不同的应用场景:第一种方式适用于需要在一定时间后对整个队列中的消息进行处理或清理的场景。例如,我们可以设置一个定期的清理任务,删除队列中过期的消息,以确保队列的有效性和性能。而第二种方式则适用于对于某些特定消息需要具备独立过期时间的场景。比如,在电商平台中,如果有一个购物车消息,我们可以为每个购物车消息单独设置过期时间,以便在一段时间内保留购物车状态,如果超过过期时间,系统可以自动清理过期的购物车消息。
给队列指定过期时间
消费者:给队列指定过期时间
(由于此处生产者中没有指定创建的队列,因此先启动消费者创建队列并设定过期时间:测试顺序,先启动消费者后启动生产者)
public class TtlProducer {
// 定义队列名称:ttl_queue
private final static String QUEUE_NAME = "ttl_queue";
public static void main(String[] argv) throws Exception {
// 创建ConnectionFactory对象,用于创建到RabbitMQ服务器的连接(设置factory的相关属性)
ConnectionFactory factory = new ConnectionFactory();
// 设置连接主机(如果修改了端口号、设定了用户名密码,则此处相应要设置,如果没有额外变动则默认即可)
factory.setHost("localhost");
// 创建连接:实现与RabbitMQ服务进行交互
try (Connection connection = factory.newConnection();
// 创建通道
Channel channel = connection.createChannel()) {
// 消息虽然可以重复声明,必须要指定相同参数,在消费者的创建队列要指定过期时间(此处先注释)
// channel.queueDeclare(QUEUE_NAME, false, false, false, null);
// 构建要发送的消息内容
String message = "Hello World!";
// 使用channel.basicPublish方法发布消息到指定队列
channel.basicPublish("", QUEUE_NAME, null, message.getBytes(StandardCharsets.UTF_8));
System.out.println(" [x] Sent '" + message + "'");
}
}
}
public class TtlConsumer {
// 定义静态常量(hello):表示正在监听的队列名称
private final static String QUEUE_NAME = "ttl_queue";
public static void main(String[] argv) throws Exception {
// 创建连接工厂,设置连接属性
ConnectionFactory factory = new ConnectionFactory();
factory.setHost("localhost");
// 从工厂获取一个姓的连接
Connection connection = factory.newConnection();
// 创建连接通道
Channel channel = connection.createChannel();
// 创建队列,指定消息过期参数
Map<String,Object> args = new HashMap<>();
// 设置消息过期时间为5s
args.put("x-message-ttl", 5000);
channel.queueDeclare(QUEUE_NAME, false, false, false, args);
System.out.println(" [*] Waiting for messages. To exit press CTRL+C");
// 处理消息:使用deliverCallback处理接收到的消息
DeliverCallback deliverCallback = (consumerTag, delivery) -> {
String message = new String(delivery.getBody(), StandardCharsets.UTF_8);
System.out.println(" [x] Received '" + message + "'");
};
// 测试1:在指定频道上消费队列中的消息,接收到的消息会传递给deliverCallback处理,持续阻塞
channel.basicConsume(QUEUE_NAME, true, deliverCallback, consumerTag -> { });
// 测试2:测试不自动确认的情况下消息是否会丢失
// channel.basicConsume(QUEUE_NAME, false, deliverCallback, consumerTag -> { });
}
}
先启动消费者,查看新创建的队列
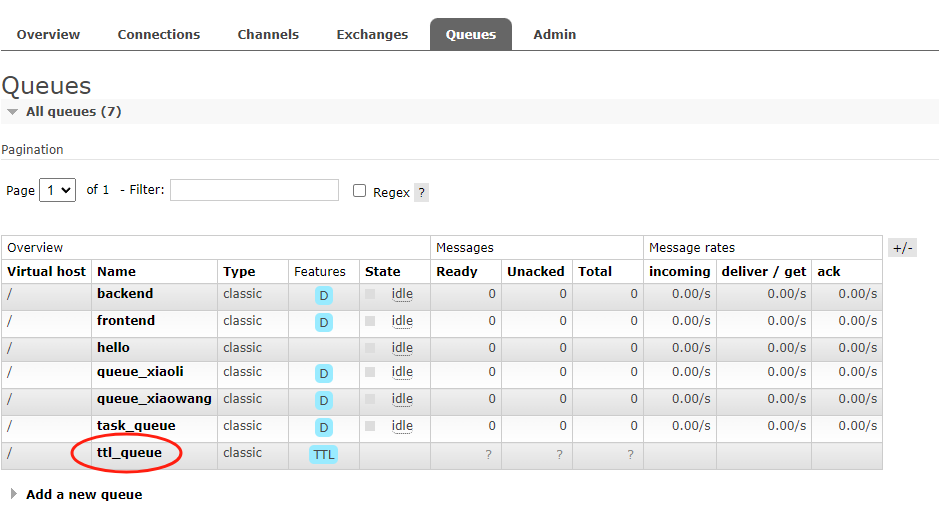
然后启动生产者,这个时候生产者发布一条消息,然后消费者监听消费。说明在过期时间限定内消费者消费了消息,并且自动确认
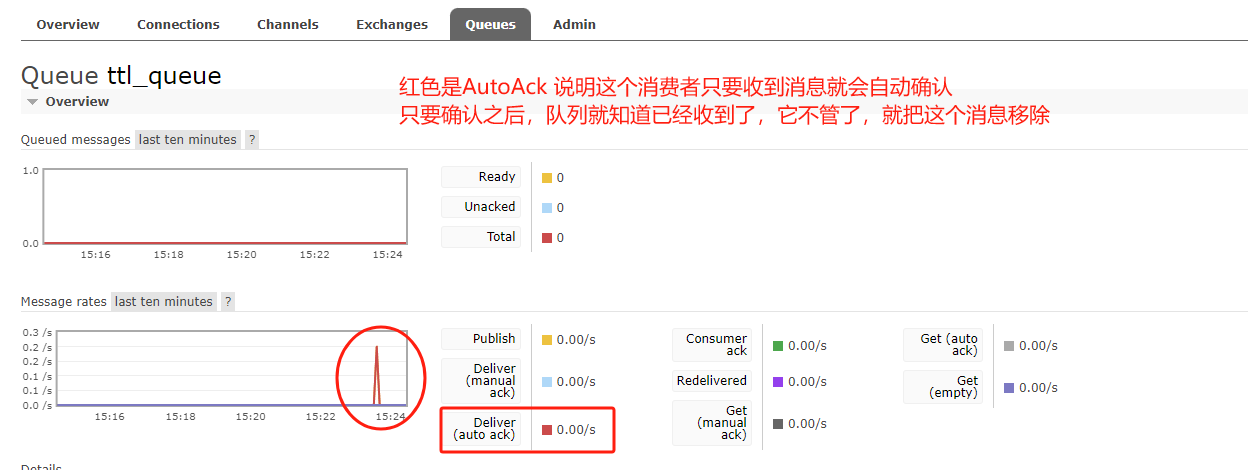
(2)测试流程2:修改autoAck,测试不自动确认的情况下消息是否会丢失
重启消费者=》重启生产者,此时消费者虽然接收到消息,但是还没确认。
RabbitMQ管理页查看,消息处于未确认状态(没有人接收),但是5s后消息没有过期
channel.basicConsume(QUEUE_NAME, false, deliverCallback, consumerTag -> { });
随后将消费者停掉,再查看管理页面,消息被丢掉了(变成-)
(3)测试流程:
重启生产者=》迅速查看管理页面,看到一条消息(黄色),但是此时消费者没启动,没有任何接收操作,因此5s后消息会自动过期(5s后变为0)
综合测试流程(2)、(3)可以得出结论:
- 过期时间内,当生产者发布消息被消费者接收但是还没有确认的话,这个消息不会过期(可以理解为消息在过期时间内已经到达消费端,只不过在处理中,在这个处理过程中就算过期时间到达,消息还是可以被正常处理的)。关闭消费者,则未被确认的任务会被丢掉
- 过期时间内,当生产者发布消息(5s过期),如果5s内还没有消费者接收处理,则消息会自动过期
给消息指定过期时间
生产者:给某条消息指定过期时间
public class TtlProducer1 {
public static void main(String[] argv) throws Exception {
// 创建ConnectionFactory对象,用于创建到RabbitMQ服务器的连接(设置factory的相关属性)
ConnectionFactory factory = new ConnectionFactory();
// 设置连接主机(如果修改了端口号、设定了用户名密码,则此处相应要设置,如果没有额外变动则默认即可)
factory.setHost("localhost");
// 创建连接:实现与RabbitMQ服务进行交互
try (Connection connection = factory.newConnection();
// 创建通道
Channel channel = connection.createChannel()) {
// 构建要发送的消息内容
String message = "test ttl message";
// 给消息指定过期时间
AMQP.BasicProperties properties = new AMQP.BasicProperties.Builder()
// 设置消息过期时间(1000ms)
.expiration("10000")
.build();
// 使用channel.basicPublish方法发布消息到指定队列(发布到my-exchange交换机、routing-key路由键)
channel.basicPublish("my-exchange", "routing-key", null, message.getBytes(StandardCharsets.UTF_8));
System.out.println(" [x] Sent '" + message + "'");
}
}
}
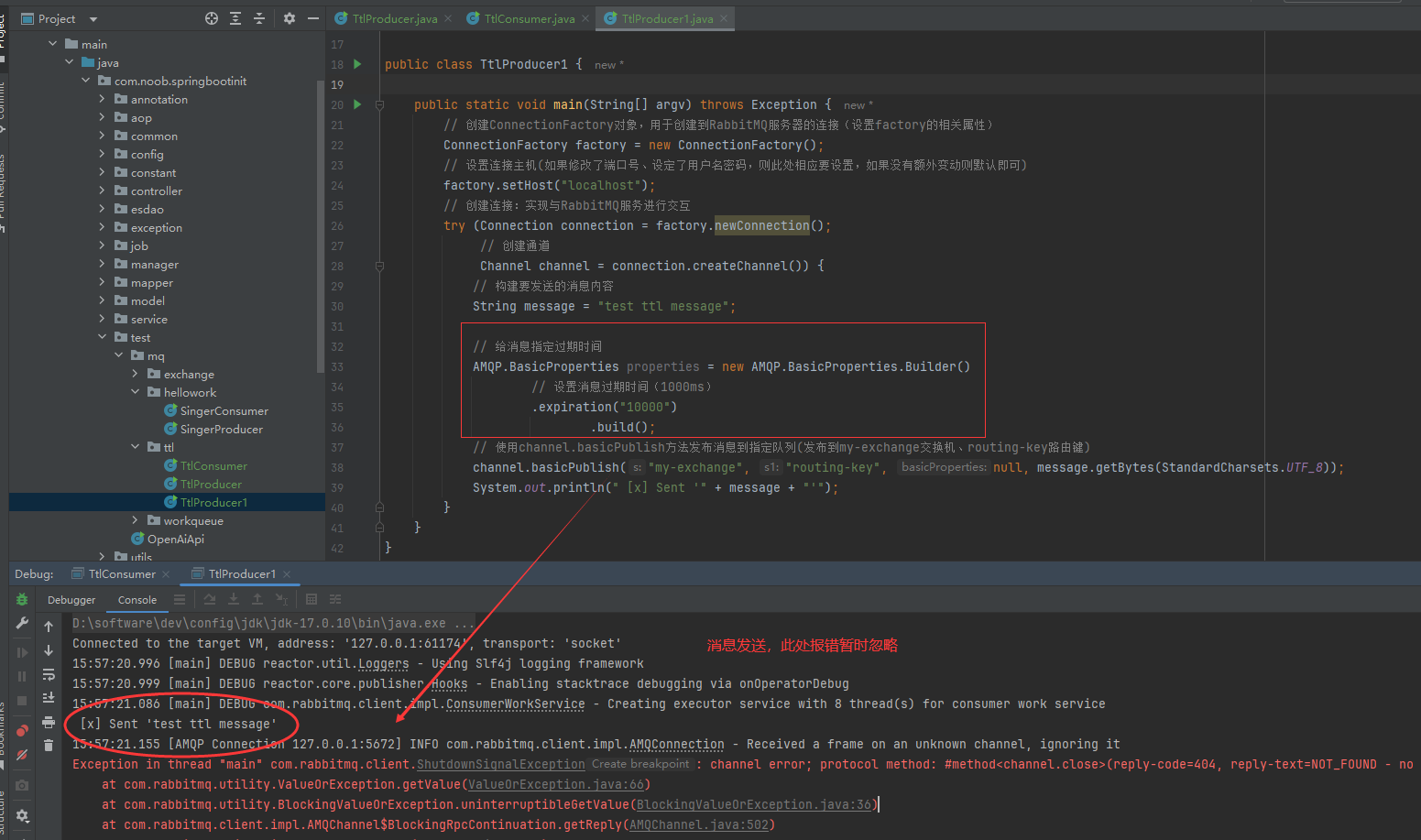
2.消息确认机制
参考前面消息确认机制的梳理
autoack,默认为 false -- 消息确认机制。消息队列如何确保消费者已经成功取出消息呢?它依赖一个称为消息确认的机制。当消费者从队列中取走消息后必须对此进行确认。这就像在收到快递后确认收货一样,这样消息队列才能知道消费者已经成功取走了消息,并能安心地停止传输。因此,整个过程就像这样。 思考一个问题:如何保证消息不会丢失,例如当业务流程失败时该怎么办,可以回答:“可以选择拒绝接收失败的消息,并重新启动。重新启动或进行其他处理可以指定拒绝某条消息。
为了保证消息成功被消费(快递成功被取走),rabbitmq 提供了消息确认机制,当消费者接收到消息后,比如要给一个反馈:
- ack:消费成功
- nack:消费失败
- reject:拒绝
如果告诉 rabbitmg 服务器消费成功,服务器才会放心地移除消息
channel.basicConsume(TASK_QUEUE_NAME, false, deliverCallback, consumerTag -> {});
但是,如果在接收到消息后,工作尚未完成,是否就不需要确认成功呢?这种情况,建议将 autoack 设置为false 根据实际情况手动进行确认了
// 指定确认某条消息
channel.basicAck(delivery.getEnvelope().getDeliveryTag(), false);
- 参数1:要确认消息
- 参数2:multiple 批量确认,是否需要一次性确认所有的历史消息,直到当前这条消息为止
- 参数3: requeue 是否重新入列,可用于重试
// 指定拒绝某条消息
channel.basicNack(delivery.getEnvelope().getDeliveryTag(), false);
在消息消费的流程中,如果你拒绝处理某条消息,那么该消息将被标记为失败。这意味着它将返回到队列中,等待重新处理。如果你选择不重新入队该消息,那么这条消息将被丢弃,不会再被消费者处理。因此,拒绝消息相当于将其废弃掉,不再进行后续处理。这是保证消息不丢失的一部分流程。
3.死信队列
3.1 死信队列的讲解
为了保证消息的可靠性,比如每条消息都成功消费,需要提供一个容错机制,即:失败的消息怎么处理?
死信:指过期的消息、被拒收的消息、消息队列已满以及处理失败的消息的统称。
死信队列:专门用来处理死信的队列(实际上是一个普通的队列,但被专门用来接收并处理死信消息。可以将它理解为名为"死信队列"的队列)。
死信交换机:用于将死信消息转发到死信队列的交换机,也可以设置路由绑定来确定消息的路由规则(是一个普通的交换机,只是被专门用来将消息发送到死信队列。可以将其理解为名为"死信交换机”的交换机)。
死信可以通过将死信交换机绑定到死信队列来实现。这样,当消息被标记为死信时,它将被转发到死信交换机,并最终路由到死信队列进行处理。
示例场景:
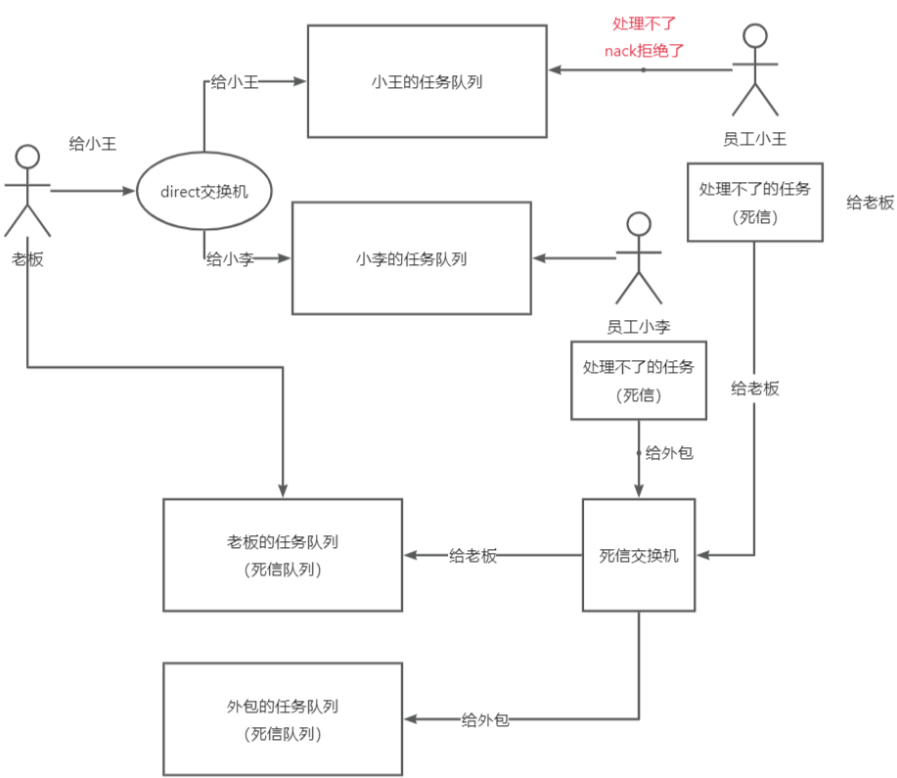
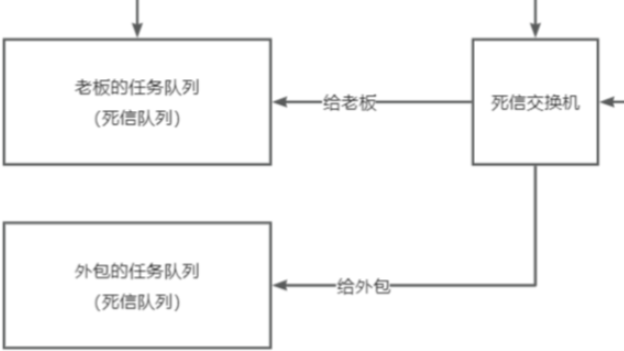
进一步说明: 死信队列 是用于处理无法被消费的消息的特殊队列。在消息队列中,为了确保消息的可靠性,即每条消息都能被成功消费,我们需要提供一种容错机制来处理可能发生的失败情况。因此,引入了死信的概念。 死信 是指那些无法被正常处理的消息,包括过期的消息、被消费者拒绝的消息、消息队列已满无法存储的消息以及处理失败的消息等。这些消息没有得到正确的响应,就好像是挂起的信件,没有被妥善处理。为了处理这些失败的消息,我们引入了死信队列的概念。死信队列是一个专门用于处理死信的队列。可以将其理解为一种任务队列,用来存放那些无法被正常处理的任务。 举个例子来说,假设我们有两个员工小李和小王,如果他们无法完成某个任务并拒绝了,我们不能简单地忽略这个任务
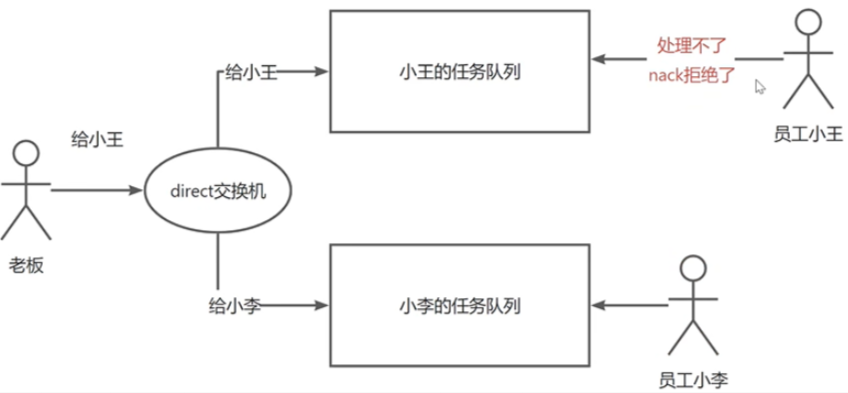
在这种情况下,我们可以将这个任务放入一个叫做"老板任务队列"的死信队列中,然后让老板从这个任务队列中处理消息。
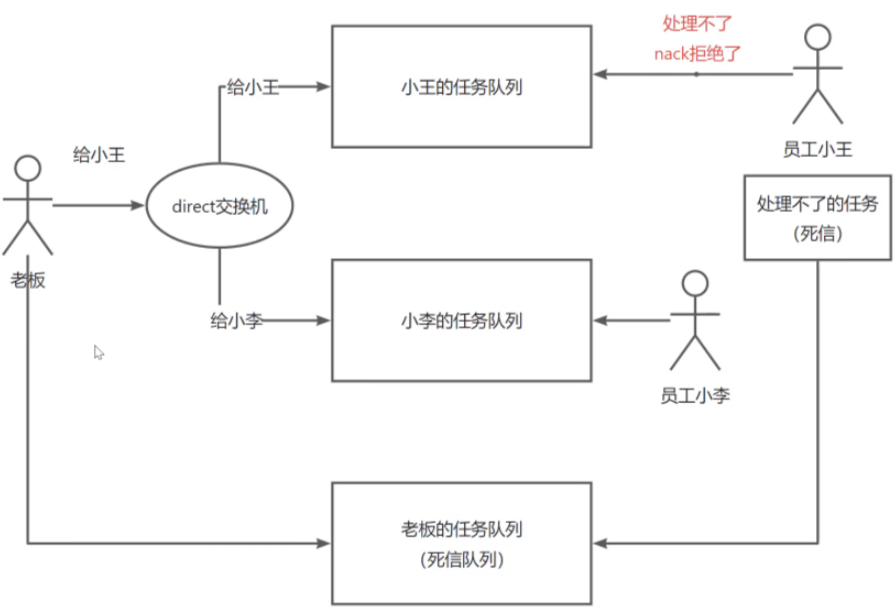
所以,死信队列实际上就是一个普通的任务队列,只是它被专门用来处理死信消息。这个队列的名称被称为"死信队列",但它并不是一个新的特性,只是给这个队列取了一个特殊的名称而已。因此,死信队列的定义就是一个专门用于处理死信消息的普通队列。
为了完善示例场景图,我们需要引入死信交换机和路由绑定的概念现在员工小王和员工小李,他们都处理不了某些任务。在这种情况下,他们可以将处理不了的任务发送到死信交换机,并通过路由键指定消息应该被路由到哪个队列。对于员工小王,他和老板关系好。因此,当他处理不了的任务时,他可以将消息发送给死信交换机,并使用指定的路由键将消息路由给老板。 对于员工小李,他和老板关系一般,无法直接将处理不了的任务发送给老板。但他可以选择找一个外包人员来处理这些任务。他可以将消息发送给死信交换机,并根据需要使用不同的路由键,将一部分任务路由给外包人员,将另一部分任务路由给老板。
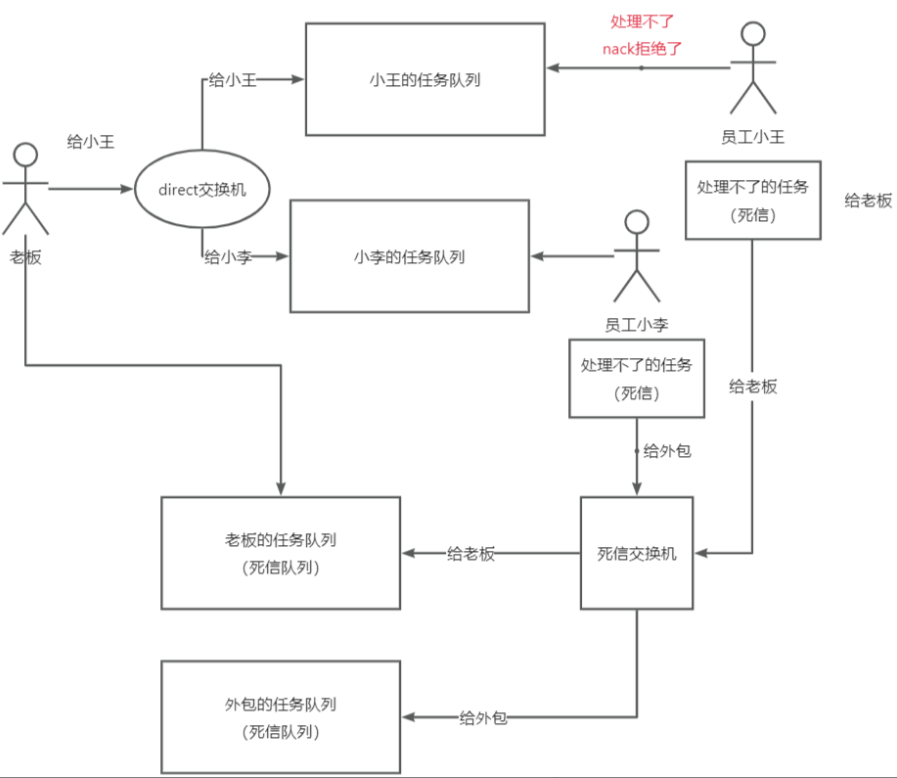
这个流程的关键是,无论是员工小王还是员工小李,当他们遇到处理不了的任务时,将这些失败的消息作为新的消息发送给死信队列,然后由死信交换机根据路由键将消息分发给相应的处理方。通过引入死信交换机和路由绑定的机制,我们可以灵活地处理失败的消息,并将其分发给不同的处理者,确保任务得到适当的处理。
死信队列主要用于处理以下情况下的死信消息。根据官方文档的说明,有以下三种情况:
1.消息被拒绝:当消费者使用basic.reject或basic.nack拒绝消息,并将requeue 参数设置为 false,意味着不将消息重新放回队列,这时消息就成为了死信
2.消息过期:当消息的过期时间设置,并且消息在队列中等待时间超过了设定的过期时间,该消息就会变成死信。
3.队列长度限制:当队列达到了设置的最大长度限制,新进入的消息将无法被存储,而被直接丢弃。这些无法进入队列的消息被视为死信。因此,当消息被拒绝、过期或者队列长度超过限制时,这些消息就会成为死信,并被发送到死信队列进行后续处理
死信队列可以通过客户端配置,一般情况下不建议客户端配置,而是直接在代码中定义
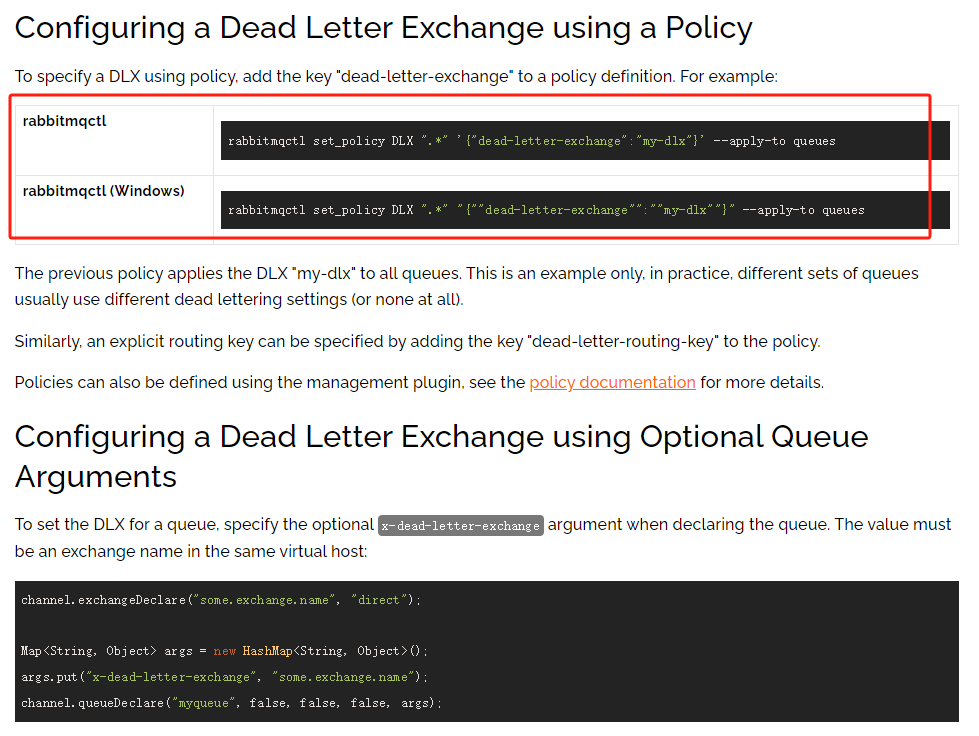
在处理无法处理的消息时,你可以为消息队列绑定一个路由键,以指定将这些无法处理的消息转发到哪个死信队列
首先,需要创建一个死信队列并创建一个死信交换机。这是第一步操作。
然后,可以给无法处理消息的队列绑定这个死信交换机。这是第二步操作。这样做的目的是为了让无法处理的消息能够被转发到死信交换机。
接下来,可以为需要容错处理的队列指定一个路由键。例如,可以将这些失败的任务指定转发给外包处理。这样当队列无法处理消息时,它会将这些失败的任务发送给外包,就好像是将任务转发出去一样。这是第三步操作。
容错处理步骤
【1】创建死信交换机和死信队列,并且绑定关系
【2】将无法处理消息的队列绑定到死信交换机(消费者)
// 创建用于指定死信队列的参数的Map对象
Map<String,Object> args= new HashMap<String, Object>();
// 将队列绑定到指定的交换机,设置死信队列参数
args.put("x-dead-letter-exchange", DEAD_EXCHANGE_NAME);
// 指定死信要转发到指定队列
args.put("x-dead-letter-routing-key", "boss");
// 创建新的小狗队列,将其绑定到业务交换机
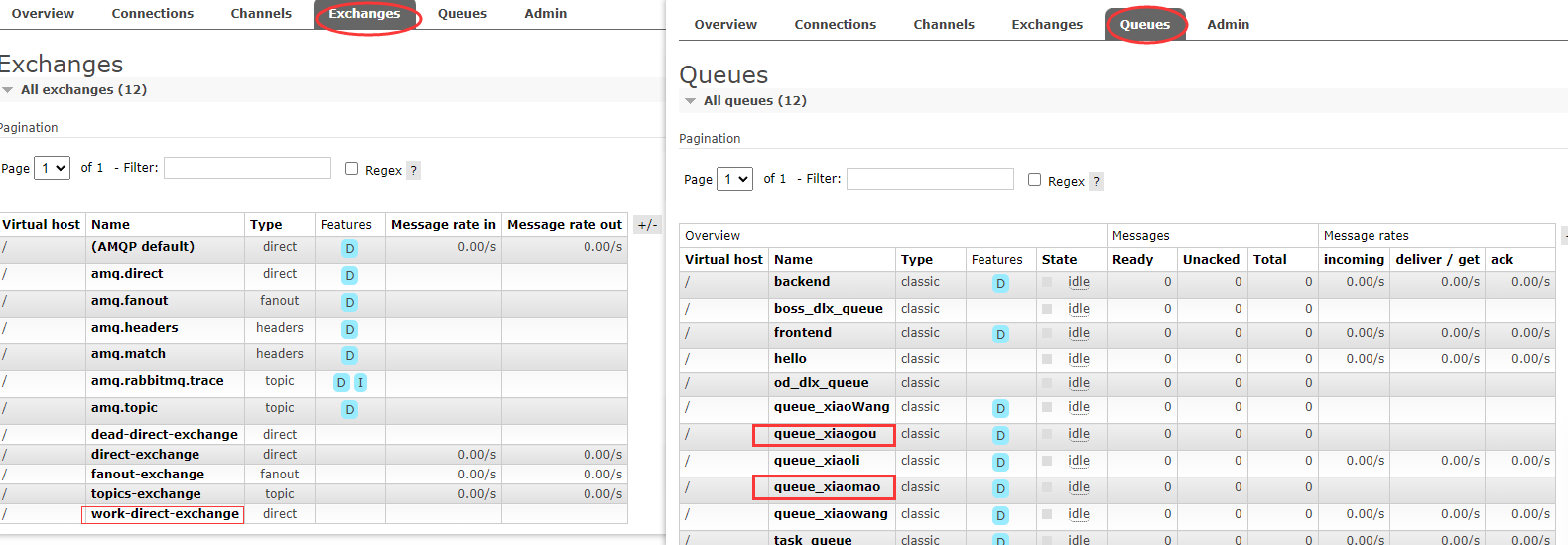
String queue1 = "queue_xiaogou";
// 声明队列:设置队列为持久化的、非独占的、非自动删除的
channel.queueDeclare(queue1, true, false, false, args);
// 将队列绑定到指定的交换机上,指定绑定的路由键为xiaomao
channel.queueBind(queue1, WORK_EXCHANGE_NAME, "xiaogou");
【3】为需要容错处理的队列指定转发规则,即将失败的消息转发到哪个死信队列(消费者)
// 指定死信要转发到外包队列
args.put("x-dead-letter-routing-key", "od");
【4】通过程序读取死信队列中的消息,并进行处理(生产者)
// 创建给老板的死信队列并绑定
String queueBoss = "boss_dlx_queue";
channel.queueDeclare(queueBoss, true, false, false, null);
channel.queueBind(queueBoss, DEAD_EXCHANGE_NAME, "boss");
// 创建给外包的死信队列
String queueOd = "od_dlx_queue";
channel.queueDeclare(queueOd, true, false, false, null);
channel.queueBind(queueOd, DEAD_EXCHANGE_NAME, "od");
// 创建用于处理老板死信队列的回调函数,当收到消息时,拒绝消息并打印消息内容
DeliverCallback deliverCallbackBoss = (consumerTag, delivery) -> {
String message = new String(delivery.getBody(), "UTF-8");
// 拒绝消息,不重新将消息放回队列,只拒绝当前消息
channel.basicNack(delivery.getEnvelope().getDeliveryTag(), false, false);
System.out.println(" [boss-死信] Received '" + message + "' with routing key '" + delivery.getEnvelope().getRoutingKey() + "'");
};
// 创建用于处理外包死信队列的回调函数,当收到消息时,拒绝消息并打印消息内容
DeliverCallback deliverCallbackOd = (consumerTag, delivery) -> {
String message = new String(delivery.getBody(), "UTF-8");
// 拒绝消息,不重新将消息放回队列,只拒绝当前消息
channel.basicNack(delivery.getEnvelope().getDeliveryTag(), false, false);
System.out.println(" [od-死信] Received '" + message + "' with routing key '" + delivery.getEnvelope().getRoutingKey() + "'");
};
// 消费指定队列消息
channel.basicConsume(queueBoss, false, deliverCallbackBoss, consumerTag -> { });
channel.basicConsume(queueOd, false, deliverCallbackOd, consumerTag -> { });
启动生产者,创建死信交换机(查看RabbitMQ的交换机),它绑定了两个死信队列
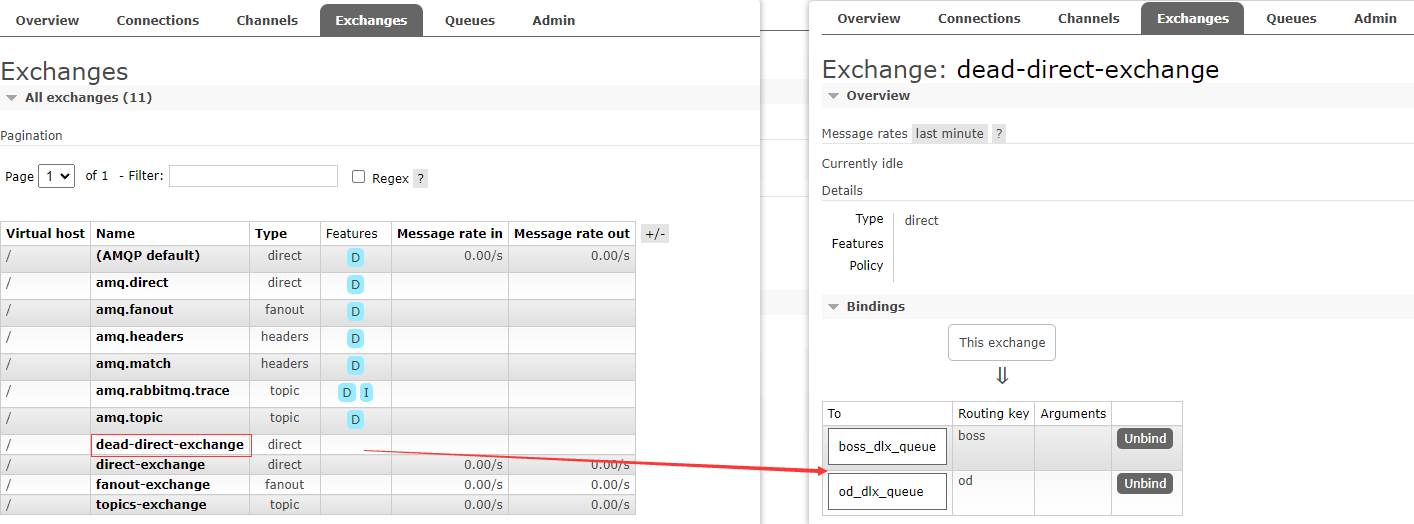
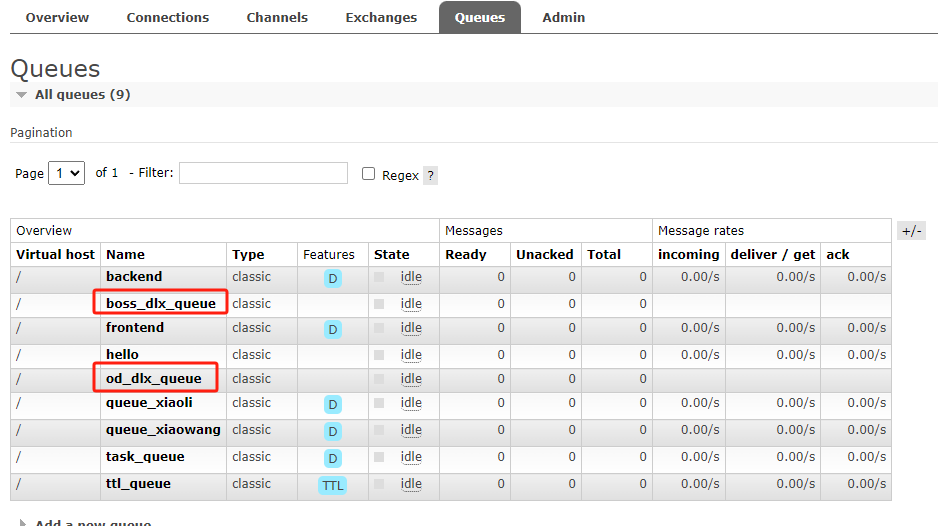
启动消费者,查看管理页面,可以看到新建的队列和交换机
在生产者发送两条消息:
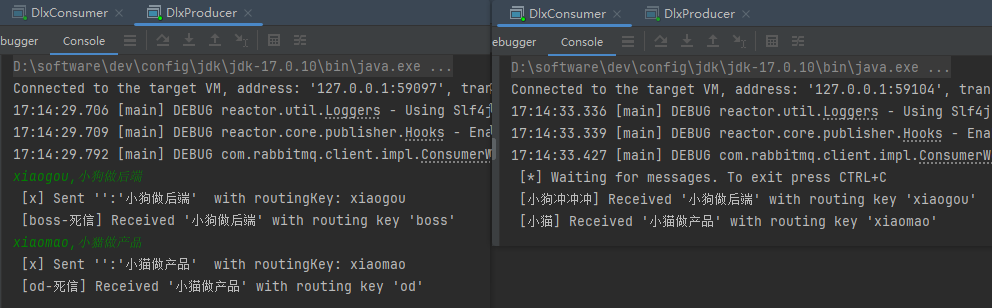
老板会在小猫完不成任务时收到消息,只要小猫拒绝这条消息
外包会在小狗完不成任务时收到消息,只要小狗拒绝这条消息
小猫收到了消息,它拒绝了,老板收到了小猫转发的任务
小狗收到了消息,它拒绝了,外包收到了小狗转发的任务
xiaogou,小狗做后端
xiaomao,小猫做产品
配置修改错误:在声明交换机的时候,测试修改了代码导致前后的队列声明不一致,此处通过代码声明需确保每次的参数配置一致,否则启动会报错。为纠正这个错误,通过RabbitMQ控制台将相关的交换机、队列删除,然后再启动项目重新生成(注意现有的一些参数复用代码的时候的影响)
RabbitMQ重点知识
RabbitMQ核心
1.消息队列的概念、模型、应用场景
2.交换机的类别、路由绑定的关系
3.消息可靠性
a.消息确认机制(ack、 nack、 reject) b.消息持久化(durable) c.消息过期机制 d.死信队列
4.延迟队列(类似死信队列)
5.顺序消费、消费幂等性(待定)
6.可扩展性(仅作了解)
a.集群
b.故障的恢复机制
c.镜像
7.运维监控告警(仅作了解)
RabbitMQ项目实战
1.客户端选择
先考虑怎么在项目中使用 RabbitMQ?
1.使用官方的客户端(推荐)
·优点:兼容性好,换语言成本低,比较灵活
缺点:太灵活,要自己去处理一些事情。比如要自己维护管理链接,很麻烦。
2.使用封装好的客户端,比如 Spring Boot RabbitMQ Starter(本次使用)·优点:简单易用,直接配置直接用,更方便地去管理连接缺点:封装的太好了,你没学过的话反而不知道怎么用。不够灵活,被框架限制。
根据场景来选择,没有绝对的优劣:类似jdbc和 MyBatis。
本次使用 Spring Boot RabbitMQ Starter(结合目前项目架构;Spring Boot 项目)
进一步说明: 如何在项目中使用 RabbitMQ 呢?有两种常见的方式可以使用 RabbitMQ.
第一种方式是使用官方提供的客户端,官方提供了多种语言的客户端,如 Go、C++ 等。官方客户端的优点是兼容性好,如果你以后学习了 Go 语言、C++或者 PHP,都可以使用类似的语法进行操作。它的特点是灵活性高而且官方提供的示例代码可以直接应用到项目中,帮助你创建生产者和消费者。然而,它的缺点在于过于灵活,需要自己处理一些细节。
举个例子来说明,就像使用JDBC和 MvBatis 一样。在创建消费者和生产者时,你需要创建一个通道(channel)。这个通道就相当于一个客户端。那么每个线程都需要创建一个客户端吗?如果有1000个线程,难道要创建1000个客户端,建立1000个连接吗?这样会非常麻烦,需要自己维护和管理连接。所以,官方提供的原生方式虽然灵活,但缺点是需要自己管理连接,比较繁琐。
第二种方式是使用封装好的框架,例如 Spring Boot RabbitMQ Starter。Spring Boot 天然支持集成RabbitMQ,并提供了封装好的框架。类似于JDBC和 MyBatis 的关系。使用这种方式的优点是简单易用,只需要进行相应的配置即可直接使用。缺点是封装得非常好,如果你没有学习过相关文档,可能不知道该如何使用。刚刚我们讲的官方客户端,大家很快就能创建出生产者和消费者。但是,如果你使用 Spring Boot,如果没有看过官方文档,你知道该如何使用吗?你知道如何配置,如何使用特定的语法来发送消息吗?另外一个点是,封装的框架可能不够灵活。这里的不够灵活并不是指它不能实现某些功能,而是指只有 Spring Boot 官方给你封装了的功能,你才能使用。使用别人框架的一个缺点就是,如果框架没有封装某个功能,你可能无法使用,受到了框架的限制。这是一个双刃剑。所以,选择哪种方式取决于具体场景。
2.基础构建
maven:spring-boot-starter-amqp,和springboot版本保持一致
<!-- https://mvnrepository.com/artifact/org.springframework.boot/spring-boot-starter-amqp -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-amqp</artifactId>
<version>2.7.2</version>
</dependency>
修改application.yml配置
spring:
# rabbitMQ配置
rabbitmq:
host: localhost
port: 5672
password: guest
username: guest
创建bizmq包(存放业务相关的mq代码):生产者MyMessageProducer、消费者MyMessageConsumer(此处用于测试:放在test/mq/demo下,后BI改造可参考)
MyMessageProducer:发送消息到RabbitMQ
MyMessageConsumer:接收消息并处理
// 标记该类为一个组件,让Spring能够扫描并将其纳入管理
@Component
public class MyMessageProducer {
// 注入RabbitTemplate
@Resource
private RabbitTemplate rabbitTemplate;
/**
* 发送消息
* @param exchange 交换机名称:指定消息要发送到哪个交换机
* @param routingKey 路由键:指定消息根据什么路由规则转发到对应的队列
* @param message 消息内容:要发送的消息
*/
public void sendMessage(String exchange, String routingKey, String message) {
rabbitTemplate.convertAndSend(exchange, routingKey, message);
}
}
// 标记该类为一个组件,让Spring能够扫描并将其纳入管理
@Component
// 生成日志记录器
@Slf4j
public class MyMessageConsumer {
/**
* 接收消息的方法:指定程序监听的消息队列和确认机制
* @param message
* @param channel
* @param deliveryTag
*/
// SneakyThrows注解简化异常处理
@SneakyThrows
// RabbitListener注解设定要监听的队列名称、设置消息的确认机制
@RabbitListener(queues = {"code_queue"}, ackMode = "MANUAL")
// @Header(AmqpHeaders.DELIVERY_TAG) 方法注解,从消息头中获取投递标签deliveryTag(RabbitMQ中每条消息都会被分配一个唯一的投递标签,用于标识该消息在通道中的投递状态和顺序)
public void receiveMessage(String message, Channel channel, @Header(AmqpHeaders.DELIVERY_TAG) long deliveryTag) {
// 使用日志记录器打印接收到的消息内容
log.info("receiveMessage message = {}", message);
// 手动确认消息接收,向RabbitMQ发送确认消息
channel.basicAck(deliveryTag, false);
}
// 此处代码设定效果等同于:channel.basicConsume(QUEUE_NAME, true, deliverCallback, consumerTag -> { });
}
MqInitMain:启动测试,查看创建的交换机和队列情况
// 用于创建测试程序用到的交换机和队列(只用在程序启动前执行一次)
public class MqInitMain {
public static void main(String[] args) {
try {
// 创建连接工厂
ConnectionFactory factory = new ConnectionFactory();
factory.setHost("localhost");
// 创建连接
Connection connection = factory.newConnection();
// 创建通道
Channel channel = connection.createChannel();
// 定义交换机
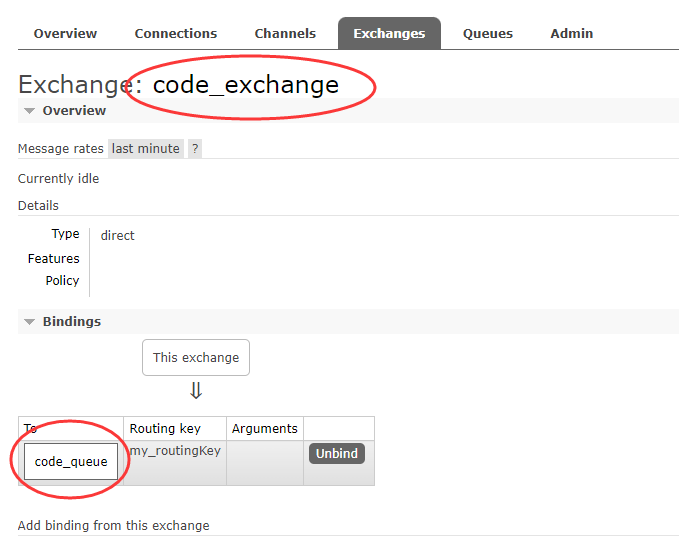
String EXCHANGE_NAME = "code_exchange";
// 声明交换机,指定交换机类型为direct
channel.exchangeDeclare(EXCHANGE_NAME,"direct");
// 创建队列,并随机分配队列名称
String QUEUE_NAME = "code_queue";
// 声明队列,设置队列持久化、非独占、非自动删除、传入额外的参数为null
channel.queueDeclare(QUEUE_NAME,true,false,false,null);
// 将队列绑定到交换机,指定路由键为"my_routingKey"
channel.queueBind(QUEUE_NAME,EXCHANGE_NAME,"my_routingKey");
} catch (IOException e) {
throw new RuntimeException(e);
} catch (TimeoutException e) {
throw new RuntimeException(e);
}
}
}
随后编写单元测试,测试生产者发送消息的功能
@SpringBootTest
class MyMessageTest {
@Resource
private MyMessageProducer myMessageProducer;
@Resource
private MyMessageConsumer myMessageConsumer;
@Test
void sendMessage() {
myMessageProducer.sendMessage("code_exchange","my_routingKey","hello world");
}
}
3.项目改造
改造基础构建
开始进行项目回归,之前的做法是将任务提交到线程池中,然后在线程池中编写处理程序的代码,任务在线程池中排队等待执行。然而,这种方式存在一个问题,如果程序中断了,那么任务就会丢失,无法得到处理。
现在我们需要对流程进行改进,具体步骤如下:
(1)将任务的提交方式改为向消息队列发送消息。
(2)编写一个专门用于接收消息并处理任务的程序。
(3)如果程序中断,消息未被确认,消息队列将会重新发送这些消息,确保任务不会丢失
(4)现在,所有的消息都集中发送到消息队列中,你可以部署多个后端程序,它们都从同一个消息队列中获取任务,从而实现了分布式负载均衡的效果。
通过这样的改进,我们实现了一种更可靠的任务处理方式。任务不再依赖于线程池,而是通过消息队列来进行分发和处理,即使程序中断或出现故障,任务也能得到保证并得到正确处理。同时,我们还可以通过部署多个后端程序来实现负载均衡,提高系统的处理能力和可靠性。
实现步骤:
(1)创建交换机和队列
(2)将线程池中的执行代码移到消费者类中
(3)根据消费者的需求来确认消息的格式(chartld)
(4)将提交线程池改造为发送消息到队列
验证:
验证发现,如果程序中断了,没有 ack、也没有 nack(服务中断,没有任何响应),那么这条消息会被重新放到消息队列中,从而实现了每个任务都会执行。
将步骤2中涉及到的MqInitMain(BiInitMain)、MyMessageConsumer(BiMessageConsumer)、MyMessageProducer(BiMessageProducer)分别copy为BI构建所需(放到bizmq包下)
其实,对于这个BI生产者来说,并没有必要存在,因为我们的生产者代码中并没有任何与特定业务逻辑相关的代码,全部都是现成的代码。可以做一些优化,将交换机的名称写死,即固定为一个特定的值。这样做的好处是我们不需要在每次使用时都传递交换机名称的参数,而是直接在代码中指定一个固定的交换机名称。
public interface BiMqConstant {
String BI_EXCHANGE_NAME = "bi_exchange";
String BI_QUEUE_NAME = "bi_queue";
String BI_ROUTING_KEY = "bi_routingKey";
}
然后分别调整BiInitMain、BiMessageConsumer、BiMessageProducer(将其调整为常量引入)
// 用于创建测试程序用到的交换机和队列(只用在程序启动前执行一次)
public class BiInitMain {
public static void main(String[] args) {
try {
// 创建连接工厂
ConnectionFactory factory = new ConnectionFactory();
factory.setHost("localhost");
// 创建连接
Connection connection = factory.newConnection();
// 创建通道
Channel channel = connection.createChannel();
// 定义交换机
String EXCHANGE_NAME = BiMqConstant.BI_EXCHANGE_NAME;
// 声明交换机,指定交换机类型为direct
channel.exchangeDeclare(EXCHANGE_NAME,"direct");
// 创建队列,并随机分配队列名称
String QUEUE_NAME = BiMqConstant.BI_QUEUE_NAME;
// 声明队列,设置队列持久化、非独占、非自动删除、传入额外的参数为null
channel.queueDeclare(QUEUE_NAME,true,false,false,null);
// 将队列绑定到交换机,指定路由键为"my_routingKey"
channel.queueBind(QUEUE_NAME,EXCHANGE_NAME,BiMqConstant.BI_ROUTING_KEY);
} catch (IOException e) {
throw new RuntimeException(e);
} catch (TimeoutException e) {
throw new RuntimeException(e);
}
}
}
// 标记该类为一个组件,让Spring能够扫描并将其纳入管理
@Component
// 生成日志记录器
@Slf4j
public class BiMessageConsumer {
/**
* 接收消息的方法:指定程序监听的消息队列和确认机制
* @param message
* @param channel
* @param deliveryTag
*/
// SneakyThrows注解简化异常处理
@SneakyThrows
// RabbitListener注解设定要监听的队列名称、设置消息的确认机制
@RabbitListener(queues = {BiMqConstant.BI_QUEUE_NAME}, ackMode = "MANUAL")
// @Header(AmqpHeaders.DELIVERY_TAG) 方法注解,从消息头中获取投递标签deliveryTag(RabbitMQ中每条消息都会被分配一个唯一的投递标签,用于标识该消息在通道中的投递状态和顺序)
public void receiveMessage(String message, Channel channel, @Header(AmqpHeaders.DELIVERY_TAG) long deliveryTag) {
// 使用日志记录器打印接收到的消息内容
log.info("receiveMessage message = {}", message);
// 手动确认消息接收,向RabbitMQ发送确认消息
channel.basicAck(deliveryTag, false);
}
// 此处代码设定效果等同于:channel.basicConsume(QUEUE_NAME, true, deliverCallback, consumerTag -> { });
}
// 标记该类为一个组件,让Spring能够扫描并将其纳入管理
@Component
public class BiMessageProducer {
// 注入RabbitTemplate
@Resource
private RabbitTemplate rabbitTemplate;
/**
* 发送消息
* @param exchange 交换机名称:指定消息要发送到哪个交换机
* @param routingKey 路由键:指定消息根据什么路由规则转发到对应的队列
* @param message 消息内容:要发送的消息
*/
public void sendMessage(String message) {
rabbitTemplate.convertAndSend(BiMqConstant.BI_EXCHANGE_NAME, BiMqConstant.BI_ROUTING_KEY, message);
}
}
❓线程池是不是更适用于需要多个线程处理任务,而 MQ 更适用于服务间通信与应用解耦?
对,线程池和消息队列(MQ)在不同的场景下有不同的适用性,线程池更适合处理需要多个线程并发执行的任务,而 MQ 更适合用于分布式场景下的信息传输、应用解耦、负载均衡以及消息可靠性保证。
❓也就是说,分布式中使用线程池就不适合了呗,保证不了任务的先后?
确实,在分布式环境中使用线程池可能无法保证任务的先后顺序。如果你需要考虑消息的顺序性,就需要设计额外的机制来实现。单独使用一个消息队列可以确保消息的顺序传递,但是如果引入了其他复杂的机制,就无法保证顺席了。例如,如果你按顺序接收消息 1、2、3、4、5,但是将它们作为任务提交给线程池执行,就无法保证它们按照顺序执行。
然而,只要你保证按顺序将任务提交给线程池,它们实际上也会按顺序执行。这意味着,如果你以顺序方式将消息 1、2、3、4、5 进入线程池作为任务,线程池会按照任务的顺序依次执行。因此,需要根据具体情况来权衡使用线程池和消息队列,并设计适当的机制来确保任务的顺序性。如果消息的顺序对业务很重要,可以考虑使用有序消息队列或其他保证顺序性的解决方案。
后端接口改造:业务流程复写
定位ChartController中的异步调用方法,将其进行改写(新增一个接口(引入MQ处理的接口))
public class ChartController {
// 引入消息生产者
@Resource
private BiMessageProducer biMessageProducer;
@PostMapping("/genChartByAiAsyncMq")
public BaseResponse<BiResponse> genChartByAiAsyncMq(@RequestPart("file") MultipartFile multipartFile, GenChartByAiRequest genChartByAiRequest, HttpServletRequest request) {
// 业务逻辑实现:改造异步调用逻辑
}
}
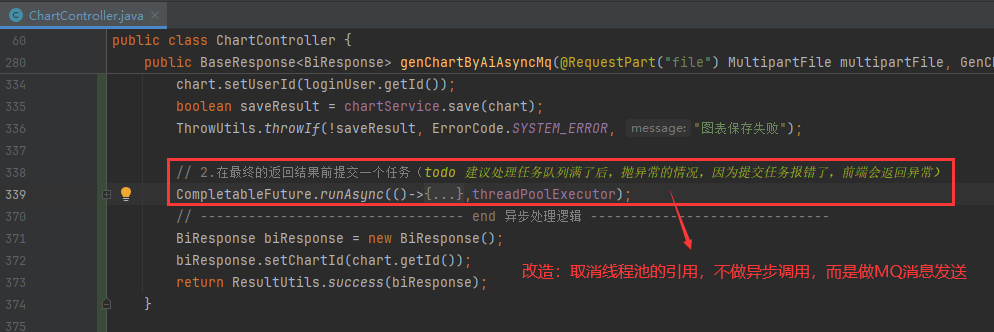
也就是说上面异步调用处理图表的逻辑,调整为发送MQ消息。因此此处需要考虑要发送的MQ消息内容是什么,消费者如何根据MQ消息去复现业务逻辑
那这个消息发送什么呢?是不是要把这个参数传递给消费者。换句话说,将消费者需要的参数作为消息的内容传递过去,将其发送到消息队列中。这样,消费者就可以从消息队列中获取消息,并恢复当时的场景,以便执行相应的任务。这种方式使得消费者能够独立处理任务,而不是在线程池中处理。通过在消息队列中发送消息并携带所需参数,消费者可以获取到这些消息并进行相应的处理 所以在这里,首先需要查看消费者的代码,以了解消费者需要什么样的参数或数据。根据消费者需要的内容来确定生产者发送的消息内容。因此,生产者的代码应该与消费者的代码保持一致,根据消费者的要求来发送相应的消息
因此将上面的CompletableFuture相关代码,先放到BiMessageConsumer中进行梳理:敲定要实现的业务逻辑,然后再填充发送消息的内容
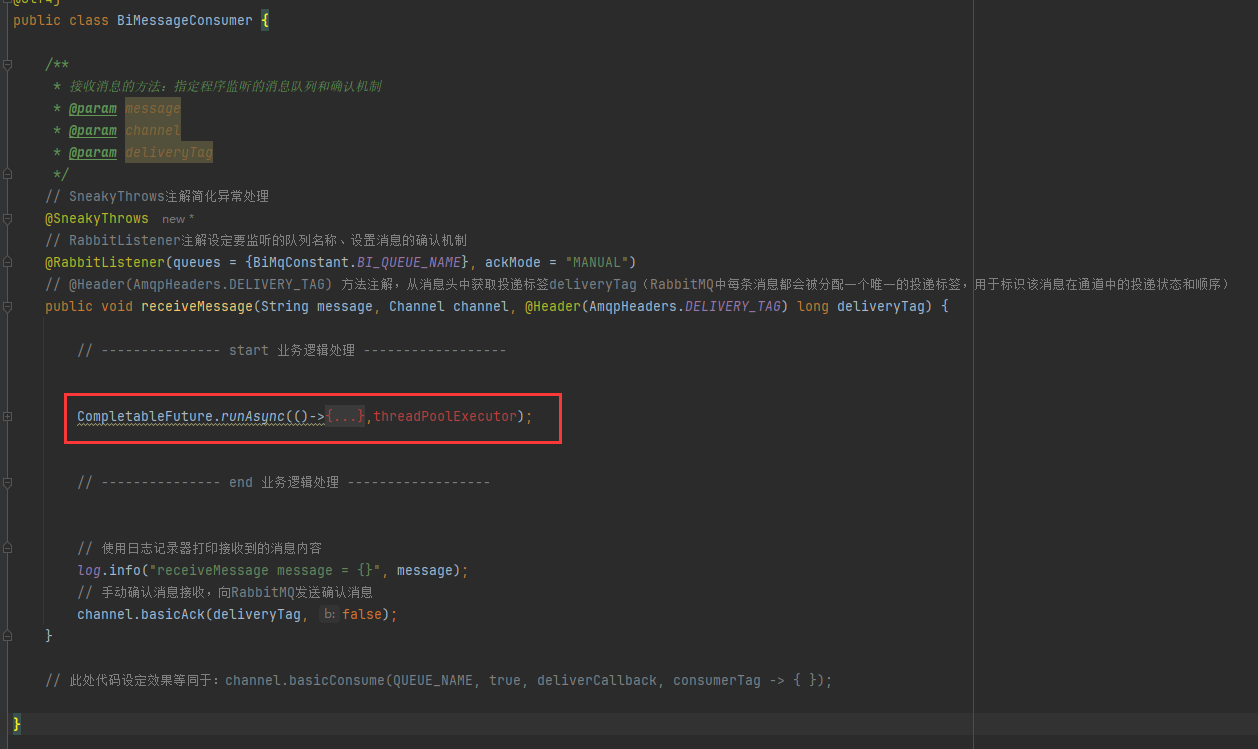
其实就是想办法依次处理飘红信息,然后看缺少什么必要参数补充进来即可
其中userInput相关参数其实在初始化图表数据中已经保存下来,因此可以直接根据chartId查询数据库chart实体,然后再根据chart实体构建一遍即可(而不需要通过消息传递的方式把所有的数据再传入一遍)
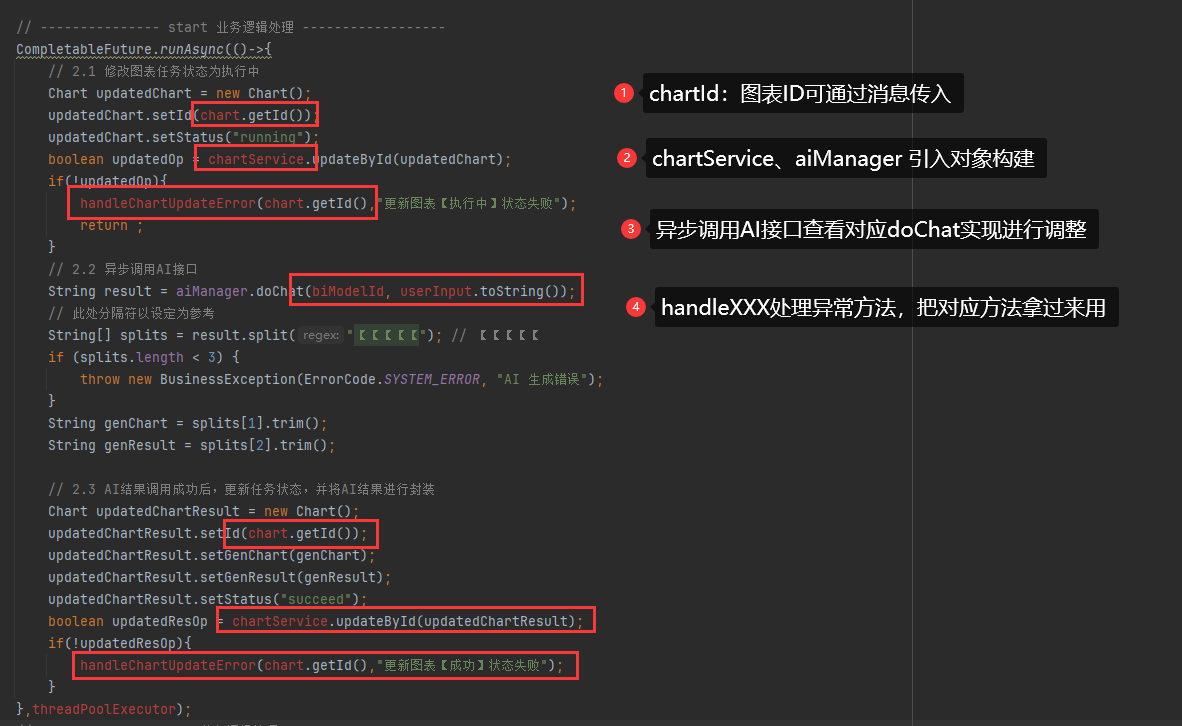
查看改造后的内容:可以明确的是目前就仅仅只需要一个chartId(因此可以考虑,将chartId作为消息传入,而暂时不需要其他参数,如果后续需要其他参数辅助,则考虑扩展message格式为json格式设定)
// 接收消息参数
long chartId = Long.parseLong(message);
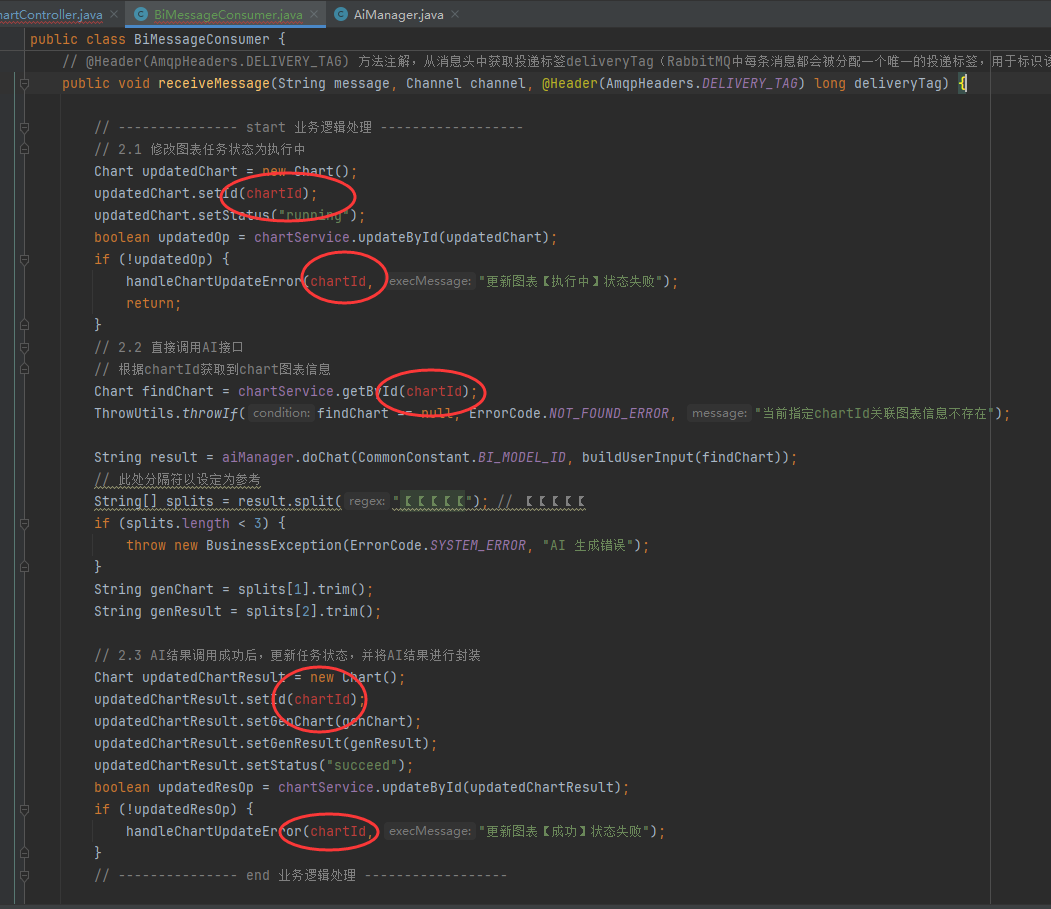
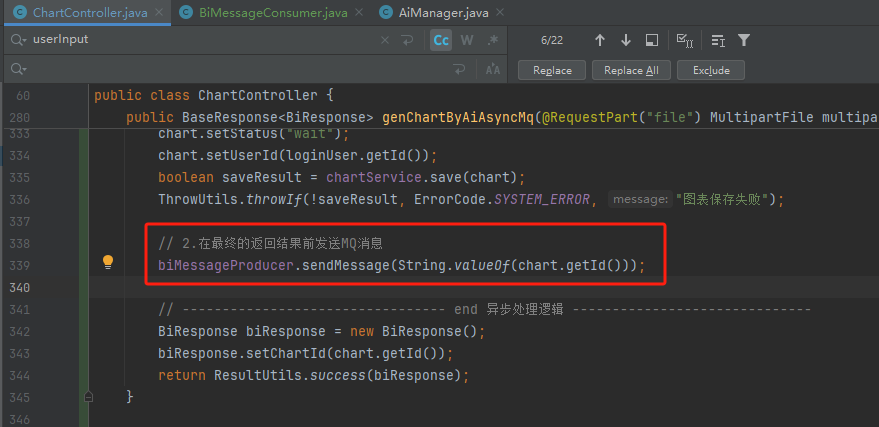
然后回到ChartController发送消息,则可明确发送的message即为chartId
biMessageProducer.sendMessage(String.valueOf(chart.getId()));
集群情况是不是得保证消息不重复?
是的,集群环境下确实需要考虑消息的去重。RabbitMQ 本身提供了消息确认机制,可以确保消息只被消费次。当同一条消息被确认后,它就会被标记为已确认,这样就不会再被消费者接收到。如果你的集群是备份集群也就是多个机器都可能接收和存储同一条消息,你需要确保消费者不会重复读取多个机器的消息。一般情况下RabbitMQ 已经为你提供了相应的机制来解决这个问题。可以参考网上的教程来深入了解。
前端交互改造
引入了新的接口,最简单的改造方式就是将原来调用BI异步的接口调整为现在的MQ处理即可
为了更好地对比,此处可以copy一份异步调用组件的实现,再复刻一个页面出来
- 启动后端项目,执行指令
yarn run openapi:更新接口 - 配置路由、创建组件(基于原有的页面改造)
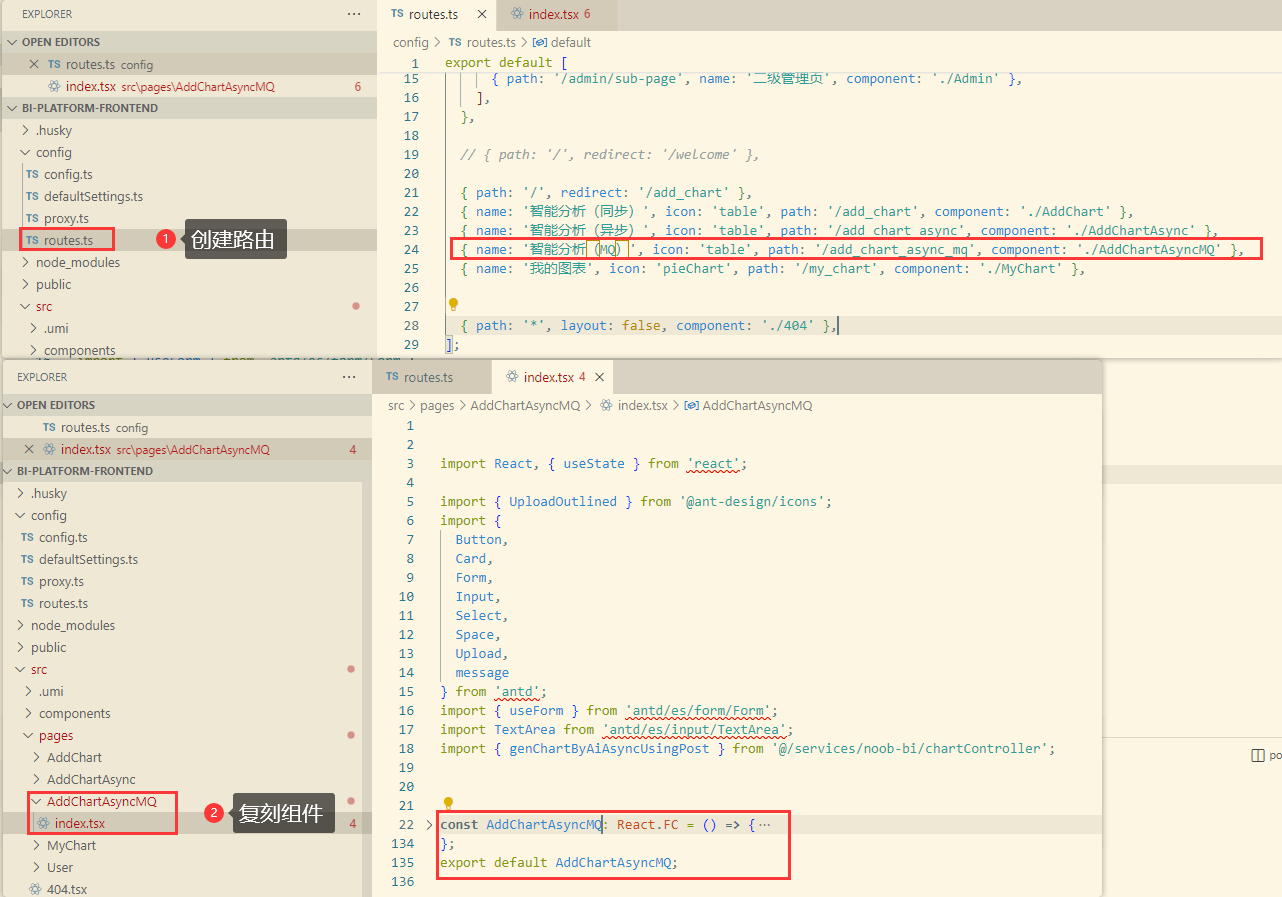
- 调整页面细节,接口交互(genChartByAiAsyncMqUsingPost),启动项目
测试
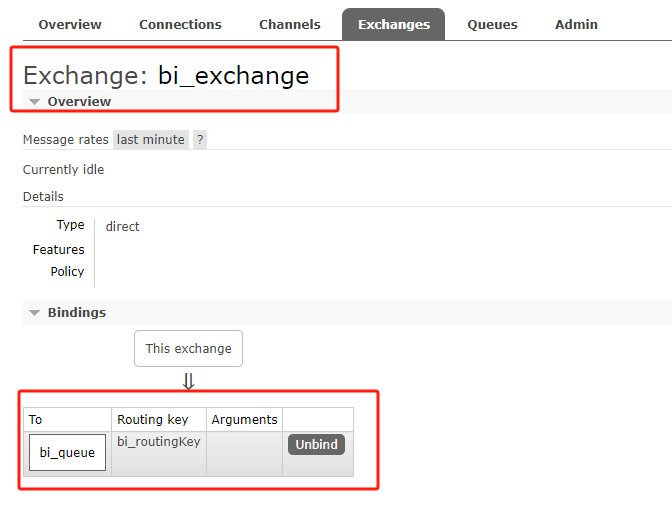
启动BiInitMain初始化交换机和队列,然后查看RabbitMQ管理器中的内容
关闭所有应用程序,启动测试
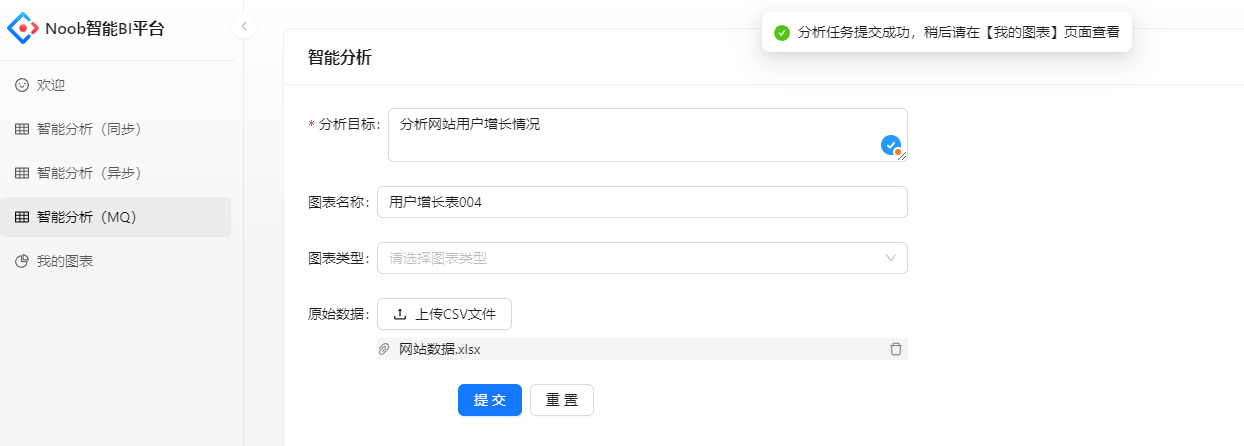
验证:发现,如果程序中断了,没有ack、也没有 nack(服务中断,没有任何响应),那么这条消息会被重新放到消息队列中,从而实现了每个任务都会执行。
新的问题:它会不会无限执行?这是一个需要考虑的问题。每次重启时,所有失败的任务都会重新执行,可能会导致无限循环执行的情况。为了解决这个问题,可以考虑在数据库中记录任务的执行状态。当程序重启后,可以检查任务的状态,如果任务已经成功执行过,则可以跳过该任务,避免重复执行。这样可以有效地防止任务的无限执行,确保任务的正确性和可靠性。
项目扩展
项目中还有很多的扩展点可以考虑。比如,当消息被拒绝后,我们可以将其放入死信队列中进行处理,被拒绝的消息放入死信队列后,我们可以对其进行进一处理。
对于被拒绝的消息或生成失败的图表,我们可以在数据库中将其状态更改为失败。这样,前端展示的图表状态就不再是一直处于响应中或生成中的状态。这些图表的生成中或待生成状态都是由于之前的程序中断或特殊的失败导致的。因此,我们必须有一个容错机制,通过死信队列就可以实现这一点。
另外,我们还要考虑程序是否会无限执行的问题,组还有许多优化点可以进行完善。例如,支持通过分组进行图表搜索,为图表打标签以增强系统的功能。此外,我们还可以利用缓存来提升已生成图表的加载速度,从而提升系统的性能和用户体验。
这个项目非常适合使用消息队列来实现。你也可以考虑将其改造为分布式架构,并使用多个消费者和多台服务器来监听消息队列。
其他优化点: .
(1)给任务的执行增加guava Retrying重试机制,保证系统可靠性
(2)提前考虑到AI生成错误的情况,在后端进行异常处理(比如AI说了多余的话,提取正确的字符串)
(3)如果说任务根本没提交到队列中(或者队列满了),不是可以用定时任务把失败状态的图表放到队列中 (补偿)
(4)建议给任务的执行增加一个超时时间,超时自动标记为失败(超时控制)
(5)反向压励: https://zhuanlan.zhihu.com/p/404993753, 通过调用的服务状态来选择当前系统的策略(比如根据AI服务的当前任务队列数来控制咱们系统的核心线程数),从而最大化利用系统资源。
(6)我的图页面增加一个刷新、定时自动刷新的按钮,保证获取到图表的最新状态(前端轮询)
(7)任务执行成功或失败,给用户发送实时消息通知(实时: websocket、 server side event)