【BI】⑥分布式消息队列
【BI】⑥分布式消息队列
需求分析
首先,来探讨一下目前系统存在的不足。目前系统已经完成从同步到异步的转变。为什么需要改变呢?因为Al模型分析速度较慢,生成图表可能需要几秒或更长的时间。虽然OpenAl最近已经优化了欺工智能服务的效率,但当系统用户量大时,可能出现系统资源不足或AI服务生成速度跟不上的情况,这会导致系统瓶颈。
因此,我们采用异步处理,以提高户体验、及时反馈。目前,我们的异步实现依赖于本地线程池。这里的"本地” 值得深思:本地线程池会存在哪些问题?比如,假设Al服务限制只能有两个用户同时使用,那么单个线程池最大核心线程数为2即可。但如果系统需求量增大,后端从单服务器部署扩展到多服务器,每个服务器都需要一个线程池。 这样,在三个服务器的情况下,可能就有六个线程同时使用AI务,超过了服务的限制。这就是我们目前的问题:无法集中限制,只能进行单机限制。
另一个问题:目前的任务数据是存在哪里的?即使任务在数据库存储,但如果执行到一半,服务器宕机,任务可能就会丢失。虽然可以从数据库中重新读取,但这需要额外的编码工作,而且在系统复杂度增加时,实现任务重试或秩恢复的编码工作成本较高。因此,由于任务是在内存中执行,就有可能会丢失,尽管可以从数据库手动恢复并重试,但这需要额外开发。
此外,随着系统功能的增多,例如Al对话和Al绘画,如果我们还要增加更多的长时间耗时任务,那么我们可能需要开辟更多的线程池,这将使系统变得越来越复杂。在这种情况下,我们可以考虑将-些耗时的任务或功能单独抽取出来,这就是微服务的思想。将这些耗时任务单独提取出来,既不影响主业务,又可以使我们的核心系统更加安全、稳定和清晰。因此,这里我们可以优化的一个方面就是服务拆分或应用解耦。
了解决这些问题,我们可以思考如何运用其它技术手段。首先, 针对无法集中限制的问题,我们是否可以统-管理各个服务器的线程数量?我们可以在一个集中的地方生成线程, 执行任务,或者下发任务。例如,Redis就可以作为分布式存储,来存储多个服务器中的共享状态,比如用户登录信息。同样的,Redis也可以帮助我们实现任务的集中管理。欺,针对内存中的任务可能丢失的问题,我们可以考虑将任务存放在可持久化的硬盘中。硬盘中的数据不会因为系统重启而丢失。后,我们来看应用解耦的问题。我们可以引入一个"中间人“来解决应用间的耦合问题。什么是"中间人"呢?假设你现在想要购买一个国外的商品, 但是你自己无法去国外,这时候,你就需要找一个中间人。 这个中间人可以帮你与国外的商家对接,帮你购买你想要的商品,而无需你本人亲自去国外。在我们的场景中,这个"中间人"可以帮助我们实现核心系统和智能生成业务逻辑的解耦,从而使整个系统更加稳定和高效。
系统现状不足分析总结
现状:我们的异步处理是通过本地线程池实现的。
但是存在以下问题:
(1)无法集中限制,仅能单机限制:如果AI服务的使用限制为同时只能有两个用户,我们可以通过限制单个线程池的最大核心线程数为2实现这个限制。但是,当系统需要扩展到分布式,即多台服务器时,台服务器都需要有2个线程,这样就可能会产生2N个线程,超过Al服务的限制。因此,我们需要一个集中的管理方式来分发任务,例如统一存储当前正在执行的任务数。
(2)由于任务存储在内存中执行,可能会丢失:我们可以通过从数据库中人工提取并重试,但这需要额外的开发(如定时任务)。然而,重试的场景是非常典型的,我们不需要过于关注或自行实现。-个可能的解决方案是将任务存储在可以持久化的硬盘中。
(3)优化:随着系统功能的增加,长耗时任务也越来越多,系统会变得越来越复杂(比如需要开启多个线程池,可能出现资源抢占的问题)。一种可能的解决方案是服务拆分,即应用解耦。我们可以将长耗时、资源消耗大的任务单独抽成一个程序, 以避免影响主业务。此外,我们也可以引入一个“中间人",让它帮助我们连接两个系统,比如核心系统和智能生成业务。
分布式消息队列
1.中间件
连接多个系统,帮助多个系统紧密协作的技术(或者组件)。
比如: Redis、 消息队列、分布式存储Etcd
谈到中间人,我们必须引入一个概念,那就是中间件。
什么是中间件?可以将其视为在开发系统或多个应用时,于连接多个系统或使多个系统紧密协作的工具。常用的中间件包括Redis,消息队列,以及分布式存储如ETCD等。
实上,如果非要定义,数据库也可以被视为一种中间件。例如,假设我们有两个系统,系统A和系统B,他们需要共享同一份数据。这时,我们可以将数据存储在数据库中,这样,数据库就像是连接这两个系统的"中间人”,即满足中间件的定义。
在NodeJS中,中间件的含义稍有不同,它指的是在不影响业务逻辑的前提下,增强系统功能的工具,连接通用功能和系统。
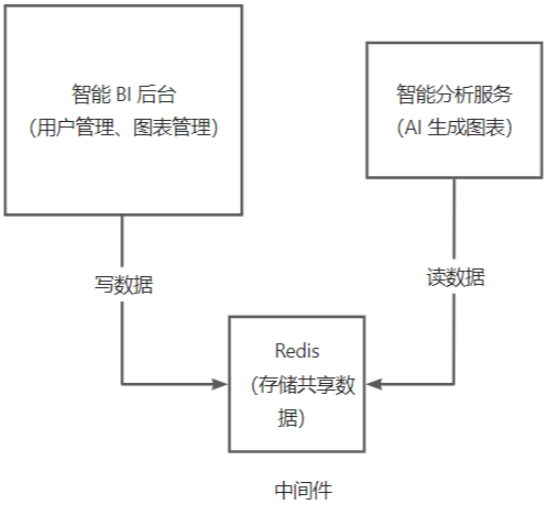
以智能BI后台为例,原有的系统包括用户管理和图表管理等。随着系统应用量的增加,智能分析业务可能会消耗大量资源。此时,我们可能会考虑将智能分析业务抽出,创建一个单独的智能分析服务, 专负责生成图表。
问:如何让这两个系统紧密协作呢? 答:这时,我们就可以使用中间件。 例如,我们可以使用Redis来存储共享数据。孫统和智能分析服务都可以读取Redis中的数据。这样,Redis就充当了一个"中间人"的色,连接了这两个系统,这就是中间件的概念。
2.消息队列
基础概念
下面,我们来介绍一个非常常用的中间件,即分布式消息队列。在了解分布式消息队列之前,我们先来解释一下什么是消息队列。从字面上理解,消息队列就是存储消息的队列。队列有-个显著特点,那就是"先进先出"。就像我们在食堂排队打饭一样,排在前面的人先打饭,这正是队列最常见的特点。假设这是一个消息队列,它可以存储消息。那么这就引出了我们的核心概念,即消息的存储。其中涉及到三个关键词:存储、队列和消息。
- 存储:可以保存数据、消息
- 消息:可能是某种数据结构(字符串、对象、二进制数据、Json数据)
- 队列:先进先出的数据结构
可以将消息队列此作特殊的数据库,这种理解其实也没有错,但是消息队列的主要作用是数据的存储。此外,消息队列与分享接口的主要区别在于,消息队列可以存储数据,分享接口,像HTTP请求- -样,发送完之后就没有了,它不会帮你保存数据。
消息队列和数据库的最大区别在于其应用场景和作用。消息队列不仅可以实现消息的传输,且可以在多个不同的系统应用之间实现消息的传输,无需关心应用的编程语言或系统框架。例如,你可以让Java发的应用发送消息,让PHP开发的应用来接收消息。这样,我们就不需要把所有的代码都写在一个 系统或项目里,实现了所谓的 应用解耦。
那么,消息队列是如何实现解耦的呢?首先,我们需要理解,消息队列的主要功能是在多个不同的系统应用之间实现消息的传输,而存储只其中一个环节。存储的目的是为了防止传输失败。如果发送消息的人发送成功了,但接收消息的人获取失败了,那这个消息就不能丢掉,我们需要将它保存起来, 以便于接收消息的人能够重新获取。
消息队列总结
消息队列:用于存储信息的队列。 此处的关键词有三个:存储、消息队列。 ●存储:对数据的储存能力。 ●消息:指任何形式的数据结构,例如字符串、对象、=进制数据、JSON等。 ●队列:有先进先出特性的数据结构。 问:消息队列是特殊的数据库么? 答:也可以这么理解,但是消息队列的核心作用不止于存储数据。 消息队列的应用场景(作用):在多个不同的系统、应用之间实现消息的传输(也可以存储)。需要考虑传输应用的 编程语言、系统框架等等。例如,可以让java开发的应用发消息,让php开发的应用收消息,这样就不用把所有代码写到同一个项目里(应用解耦)。
消息队列模型
消息队列主要由四部分组成:消息生产者(Producer) 、消息消费者(Consumer) 、消息(Message) 和消息队列(Queue) 。这里,我们可以通过一个类比来理解消息队列的运作方式。
想象- -下这个场景:小是-个快递员(消息生产者),他在早上八点拿到了一个包裹(消息)。然而,收件人小受(消息消费者)说早上八点他有事,无法收快递,让小王晚上八点再来送。此时,如果有一个快递柜(消息队列) ,小王就可以将包裹存放在快递柜里,然后告诉小受密码,小受什么时候有时间就可以取包裹。在这个过程中,归并不需要等受在家。
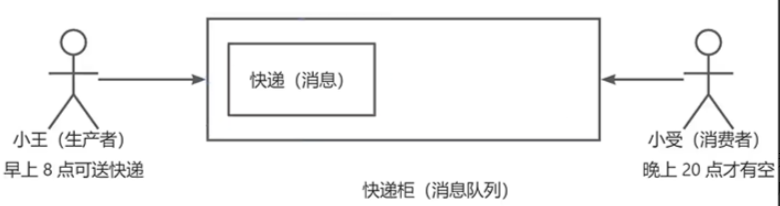
通过这个例子,我们可以看到,消息队列的一个主要优点就是可以集中存储消息,使得消息的发送者和接收者无需同时在线,实现了发送者和接收者的解耦。这就是消息队列的核心作用,以及为什么我们需要使用消息队列的原因。
我们已经阐述了消息队列模型的基本结构。现在,让我们进一步探讨其优点。假设我们的快递员王寄送的是一本Java书籍。此时,又出现了一个新的生产者小李,他并非快递员,而是一个寄件人, 他需要寄送的是Python书籍。
小悸完全可以把他的Python书籍放进同一个快递柜里,而收件从小受能够从这个快递柜中去取。这就意味着,无论是小李还是小王,或者其他任何想要使用这个快递柜的人,他们都可以是不同的个体,,且睛件物品也可以格不相同。
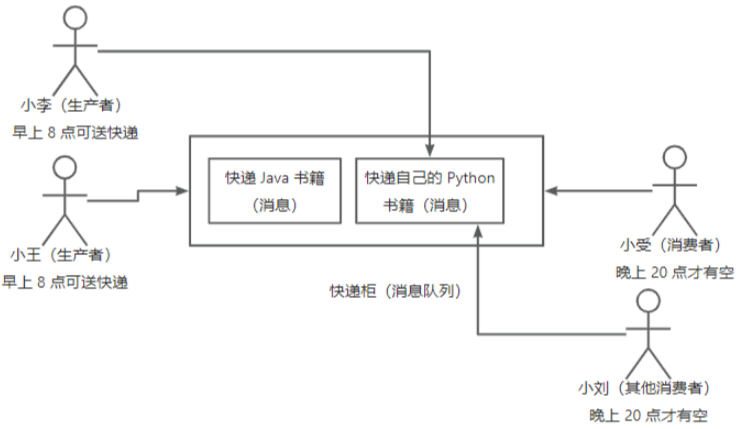
这实际上正好反映出了刚刚提到的一点消息队列可以实现无需考虑传输应用的编程语言、系统和框架。 也就是说,无论是Iava还是Python,都可以向消息队列中发送消息。消费者可以是Python系统,也可以是JavaSpringboot开发的系统等。此外,还可以有其他消费者,如小刘。换句话说, 消费者和生产 者是完全独立的,互不影响。只要他们能够从消息队列中取出或放入消息,那就可以实现所需的功能。
消息队列的模型总结
生产者: Producer, 类比为快递员,发送消息的人客户端
消费者: Consumer,类比为取快递的人,接受读取消息的人(客户端
消息: Message,类比为快递,就是生产者要传输给消费者的数据
消息队列: Queue
问:为什么不直接传输,要用消息队列?
答:产不用关心你的消费者要不要消费什么时候消费,我只需要把东西给消息队列,我的工作就算完成了。
生产者和消费者实现了解耦,互不影响。
优势
接下来,让我们更深入地探讨一下消息队列的优势。为何需要使用消息队列呢?这主要归结为消息队列的几个核心
特性:
首先是异步处理,所谓的异步处理,意味着生产者(如小李)在发送完消息后可以立即转而进行其他任务,无等待消费者处理消息。这样生产者就无需等待消费者接收消息才能进行下-步操作,避免了阻塞。这与我们之前讨论的异步化处理非常类似,消息队列使我们的系统具备了这种能力。
其次,消息队列还有削峰填谷的能力。削峰填谷是指当消费者的处理能力有限时(例如,Al应用可能每隔几秒才能处理一次智能生成服务),而用户的请求量又很大(例如,新上线的系统有大量用户同时使用),我们可以先将用户的请求存储在消息队列中,然后消费者或实际执行应用可以按照自身的处理能力逐步从队列中取出请求。
比如说,在12点10分有10万个请求涌入。若直接在系统内部立刻处理这10万个请求,系统很可能会因处理不过来而过载甚至宕机。而如果将这10万个请求放入消息队列中,消费者或下游处理系统就可以以自可处理的恒定速率,比如每秒处理一个请求, 慢慢消费并执行。这样的话,就很好地保护了系统,将原本的流量高峰平滑地分散开,就像水管中的恒定流速一样, 以稳定的方式进行处理。
这是消息队列所具有的削峰填谷功能。虽然线程池也能实现削峰填谷的效果,但它并没有消息队列这样的存储灵活性,或者说,消息队列能实现的持久化存储。
消息队列优势总结
(1)异步处理: -生产者发送完消息,便可以立即转向其他任务,而消费者则可以在任何时候开始处理消息。这样一来,生产者和消费者之间就不会发生阻塞。
(2)削峰填谷:消息队列允许我们先将用户请求存储起来,然后消费者(或说实际执行任务的应用)可以根据自身的处理能力和需求,逐步从队列中取出并处理请求。
a.原本: 12点时来10万个请求,原本情况下,10万个请求都在系统内部立刻处理,很快系统压力过大就宕机了。
b.现在:把这10万个请求放到消息队列中,处理系统以自己的恒定速率(此如每秒1个)慢慢执行,从而保护系统、稳定处理
分布式消息队列优势
我们来谈谈分布式消息队列的优势。尽管线程池有些许消息队列的影子,例如本地开启一个数组队列也能实现类似功能,但分布式消息队列有其独特的优势。
首先,分布式消息队列支持消息持久化,也就是数据持久化。它能将我们的消息集中存储到硬盘里,因此服务器重启后,数据不会丢失。就如同快递一样,即使丢失,也有一定的机制能帮你找回, 这是分布式消息队列的首要优势。
其次,分布式消息队列具有可扩展性,这分布式与单机最大的区别。如果一个服务 器只能处理1000个户的请求,超出这个数量的请求,服务器可能就无法承受,甚至会宕机。然而,可扩展性意味着无论你的用户数量再多,通过增加机器,我们都能自动地承受新增的用户。分布式的特点就是可以根据需求随时增加或减少节点,以保持服务稳定。
再者,分布式消息队列能够实现应用解耦。这是在分布式场景下才能实现的功能,允许各个使用不同语言框架开发的系统之间进行灵活的数据传输与读取。
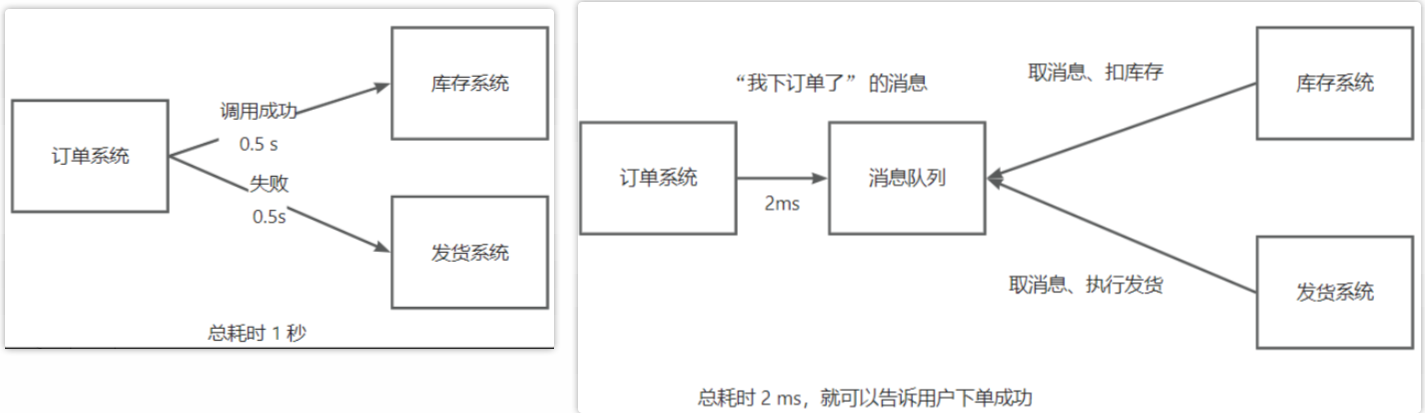
此外,让我们来讨论一下应用解耦和分布式消息队列的另一个优势,这也是面试中常被问到的问题。假设我们有一个订单系统,库存系统和发货系统。以往,我们将所有这些系统全都放到同一个大项目中,那会带来哪些问题呢?
以订单系统为例,它需要调用库存系统进行减库存,然又要调用发货系统进行发货。如果库存系统调用成功,但发货系统突然调用失败,整个系统就会出现问题。如果发货系统崩溃,库存系统可能也会受到影响。但如果我们实施应用解耦,订单系统下订单时只需向消息队列发送一个消息, 然后立即返回。库存系统和发货系统可以从消息队列中取出消息进行处理。如果发货系统突然宕机,不会影响库存系统。当发货系统恢复后,可以从消息队列中找到订单消息,然后继续执行业务逻辑。
后一个优点是,通过消息队列,订单系统不需要同步调用所有系统,只需发送消息到队列就可以立即返回,这样性能更高,响应时间更短。这就是为什么我们在构建秒杀系统时,必须要用消息队列,你可以将所有耗时的操作全部推给消息队列,让库存和发货系统自己去处理订单,它们可以自己去保证订单不被重复执行等。当然,实际情况比我说的要复杂-些。
在大公司中,消息队列还有一个可能被忽视的应用场景,这就是发布订阅模式, 可以说这是消息队列的第四个优势。我们常在公司中遇到这样的场景:假设你在一家大公司, 以腾讯为例,我们都知道,腾讯有许多产品,许多产品都需要用QQ登录。如果QQ对其账号体系进行了改革,那么所有使用QQ登录的下游系统都必须知道这个变化。
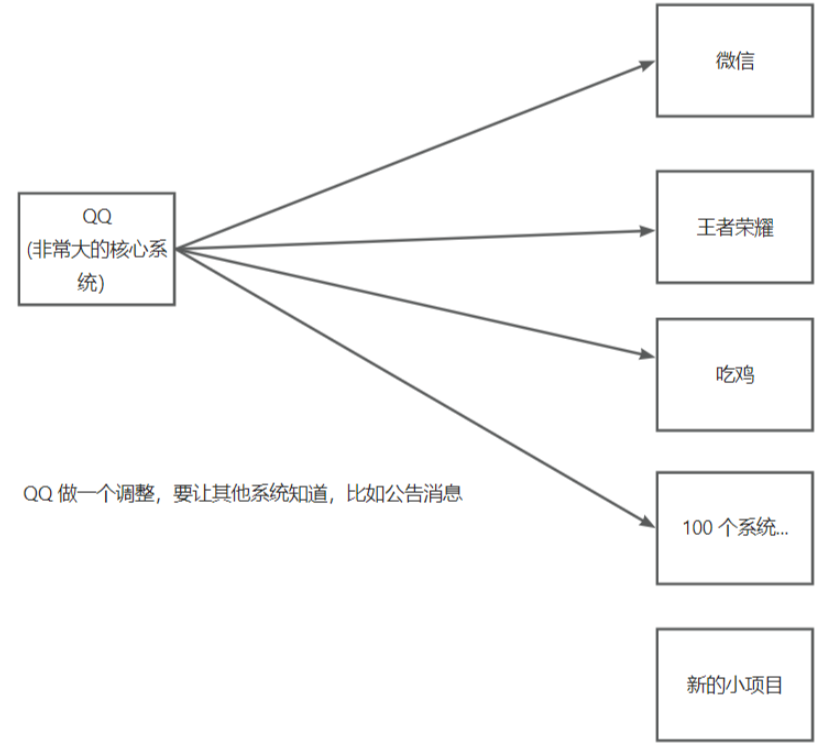
现在设想这样一个场景,腾讯有非常多的子系统,例如微信、王者荣耀等,假设有 100 个这样的系统。如果 QQ进行了一些改革,我们如何将这些改变通知给这些系统?最简单,但也最费时的方法,就是直接一个个通知。例如,QQ 发布了新的数据或进行了一些调整,需要让其他系统知道,或者 Q0 发布了新的公告,其他系统也需要同步这个公告。如果 QQ 直接调用其他系统,这会有什么问题呢? 首先,系统越多,这个操作的时间就会越长,而且可能会遇到失败的情况,这无疑是一项繁琐的工作。其次,假设现在有100 个系统,如果有新的项目或团队加入,他们可能不知道要接收 QQ 的这些变动,而且 QQ 也无法得知新加入的项目,因此可能会有信息漏洞,这是致命的。那我们应该怎么解决这个问题呢?解决方案就是,大的核心系统(如 QQ)向一个地方,也就是我们的消息队列发送消息,然后其他的系统都去订阅这个消息队列,读取这个消息队列中的消息就可以了。这样,QQ 就不需要关心背后有多少系统,只需要向消息队列发送消息,其他系统如果需要这些消息,就可以从消息队列中获取,这样就解决了上述的问题。
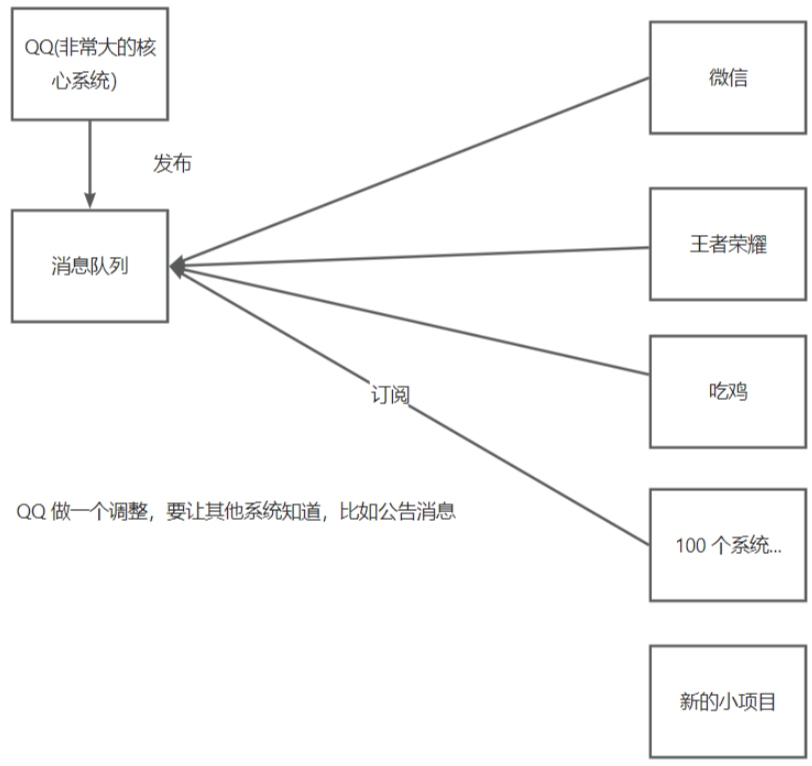
分布式消息队列总结
优点:
1)数据持久化:它可以把消息集中存储到硬盘里,服务器重启就不会丢失
2)可扩展性:可以根据需求,随时增加(或减少)节点,继续保持稳定的服务
3)应用解耦:可以连接各个不同语言、框架开发的系统,让这些系统能够灵活传输读取数据
以前,把所有功能放到同一个项目中,调用多个子功能时,一个环节错,系统就整体出错。
使用消息队列进行解耦: 一个系统挂了,不影响另一个系统 系统挂了并恢复后,仍然可以取出消息,继续执行业务逻辑 只要发送消息到队列,就可以立刻返回,不用同步调用所有系统,性能更高
4)发布订阅:如果一个非常大的系统要给其他子系统发送通知,最简单直接的方式是大系统直接依次调用小系 统。(参考QQ) 问题:
每次发通知都要调用很多系统,很麻烦、有可能失败
新出现的项目(或者说大项目感知不到的项目)无法得到通知
解决方案:大的核心系统始终往一个地方(消息队列)去发消息,其他的系统都去订阅这个消息队列(读取这个消息队列中的消息)
应用场景
1.耗时的场景(异步) 2.高并发场景(异步、削峰填谷) 3.分布式系统协作(尤其是跨团队、跨业务协作,应用解耦) 4.强稳定性的场景(比如金融业务,持久化、可靠性、削峰填谷)
让我们总结一下消息队列的应用场景。消息队列的优势包括数据持久化、可扩展性、应用解耦,以及发布订阅模式。现在,我们来探讨一下在何时我们需要使用消息队列。第一,当遇到耗时任务的场景,我们可以考虑使用消息队列。原因是消息队列能提供异步处理的能力。第二,在高并发场景下,消息队列也是非常有用的工具。它不仅提供异步处理的能力,还有助于实现流量的削峰填谷,这是消息队列的一个显著优点。 第三,在分布式系统协作的环境下,消息队列同样非常适用。例如,QQ 团队和微信团队各自拥有自己的系统,这两个系统可能使用不同的语言,基于不同的技术栈开发。你不能像处理传统的单体应用那样,把所有东西都写在个 Spring Boot 项目中,你需要通过某种方式,如消息队列,来实现系统之间的解耦。QQ 的消息能够通过消息队列传输给微信,实现跨团队、跨系统、跨业务的协作。这正是消息队列的应用解优势的体现。 最后,如果你需要保证系统的高稳定性或者强稳定性,消息队列也是非常重要的工具。例如,在金融支付转账的场景下,对系统稳定性的要求非常高,不允许有任何错误。在这种情况下,我们可以利用消息队列的持久化和可靠性保证特性,以及削峰填谷的能力,来满足高稳定性的需求,因此,当你在开发过程中遇到以上这些场景,就可以考虑使用消息队列了
消息队列缺点
下面,我们将探讨消息队列的应用场景,原因在于它并非适合所有情况,某些情况下我们应该避免使用消息队列,或者需要认清使用消息队列可能会遇到的问题。 首先,最直接的问题是使用消息队列意味着你需要学习和掌握一个新的工具,并在你的系统中引入一个额外的中间件。这将会使你的系统变得更复杂,并需要更多的维护工作。若你在公司实施此类解决方案,我们通常会选择由第三方大公司提供的稳定中间件,而这会产生额外的成本。即使你自己部署和维护,也需要额外的资源投入另外,一旦你开始使用消息队列,你就需要承担由此带来的各种可能问题,例如消息丢失。并非消息队列就可以保证消息不会丢失,比如在发送消息的过程中,可能就因为某些原因而失败再者,你需要保证消息的顺序性,即消息需要按照特定的顺序被消费。此外,你还需要防止消息的重复消费,避免同一个系统多次处理同一条消息。同时,你还需要保证数据的一致性,这并非是消息队列的特定问题,而是任何分布式系统都需要考虑的问题。例如,分布式锁就是为了解决分布式系统中多个服务器之间的一致性问题。因此,这些都是使用消息队列时需要考虑的问题,也是在分布式场景下需要考虑的问题。单机和分布式是两个不同的维度。如果你之前只是处理单机问题,首次处理分布式项目时可能会遇到一些问题。因此,我们需要提前学习和理解这些知识。可能有同学会说,“面试问得像构建火箭,但实际工作就像拧螺丝”。实际上,这并非是说你的工作中不会用到这些知识,而是指只有当你熟练掌握这些知识,才可能有机会应用它们。如果等到真正需要用到分布式的时候再去学习,可能就会出现严重的问题,例如丢失消息,而这可能意味着丢失金钱。所以我们需要提前做好学习和准备。
4.技术选型
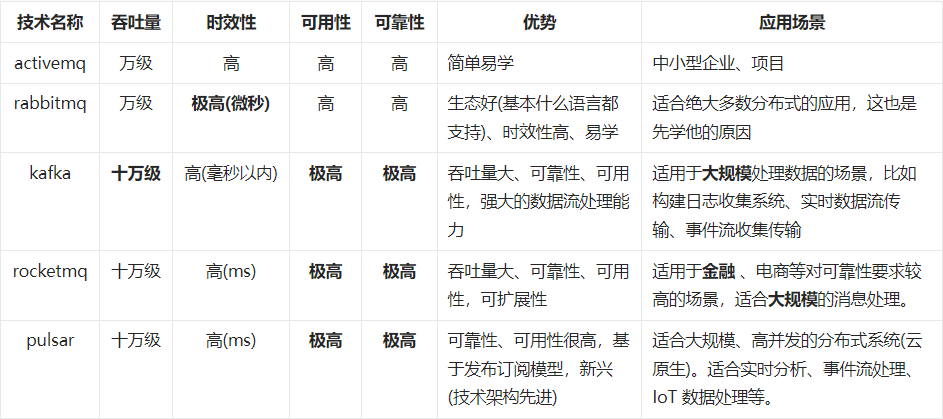
主流技术 1.activemg 2. rabbitmg 3. kafka 4.rocketmg 5.zeromg 6.pulsar(云原生) 7. Apache InLong (Tube) 技术对比 技术选型指标: 吞吐量:IO、并发 时效性:类似延迟,消息的发送、到达时间 可用性:系统可用的比率(比如1年365 天岩机 1s,可用率大概X个9)可靠性:消息不丢失(比如不丢失订单)、功能正常完成
RabbitMQ入门实战
1.基本概念
首先,我们要介绍一个基本概念,也就是 RabbitMQ 中的 AMQP 协议,那么,什么是 AMQP 呢?AMQP 的全称是 Advanced Message Queue Protocol,即高级消息队列协议,RabbitMQ 就是根据这个协议开发的。AMQP 是一个标准的协议,不仅 RabbitMQ,如果你想自己实现一个消息队列,也可以按照这个协议来设计。 AMQP 协议主要由几个部分组成,如下图所示,它非常适合我们来解释这个协议的各个组成部分。
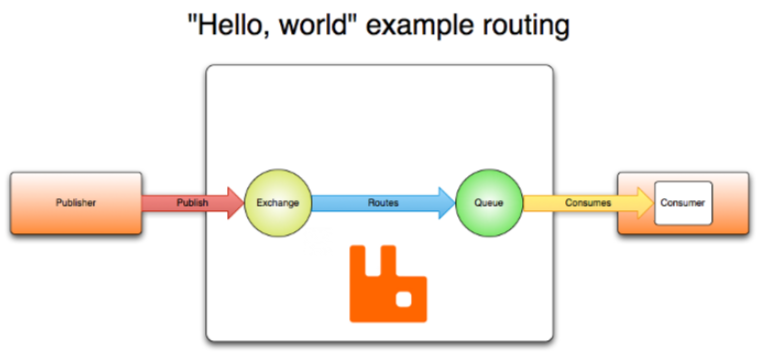
首先,看到图中的 Publisher,也就是消息的生产者,它负责发送消息。然后在最右边的是 Consumer,也就是消息的消费者,它负责接收消息。在中间的部分,用兔子头标识的就是 RabbitMQ,它承载着以下的功能: 1.生产者:发消息到某个交换机。 2.消费者:从某个队列中取消息。 3.交换机(Exchange):像路由器一样,负责将消息从生产者发送到对应的队列。 4.队列(Queue):存储消息的地方。 5.路由(Routes):转发,就是怎么把消息从一个地方转到另一个地方(比如从生产者转发到某个队列)。假设你现在要向北京的同学发送一条微信消息,这个消息会通过网络传输,通过许多设备和网络线路,这个过程就需要路由器的帮助。路由器的作用就是根据发送和接收的地址,找到一条可以把消息传递过去的路径。在这个模型中,交换机的作用就是路由器的角色,负责把消息转发到对应的队列。 消费者的角色就是从特定的队列中取出消息。在这个图中,我们只画出了一个队列,但实际上可能会有多个队列消息会从多个队列发送到交换机,这就构成了整个模型的流程。 你可以将这个消息发送模型理解为我们在发送一条微信消息的过程:我作为消息的发送者,首先会将消息发送到微信的服务器,然后经过路由器(交换机)和路由规则的选择,经过一系列的网络传输过程,最终将消息发送到接收方的服务器。接收消息的人则会从他的服务器(交换机)中取出消息。 总的来说,这就是 AMOP 协议,也是我们在 RabbitMQ 消息队列中使用的基本模型。虽然不同的消息队列可能有不同的模型,但基本上都会涉及生产者、消费者和消息队列这三个部分。
2.安装
选择第二种方式安装,需要安装Erlang依赖
Erlang下载完成点击exe文件安装(傻瓜式安装),依赖安装完成,则可进一步安装rabbitmq(此处选择**rabbitmq3.12.0**)
rabbitmq选择安装路径,傻瓜式安装,然后打开服务管理查看rabbit服务是否启动

rabbitmq-plugins(插件管理),3-12版本
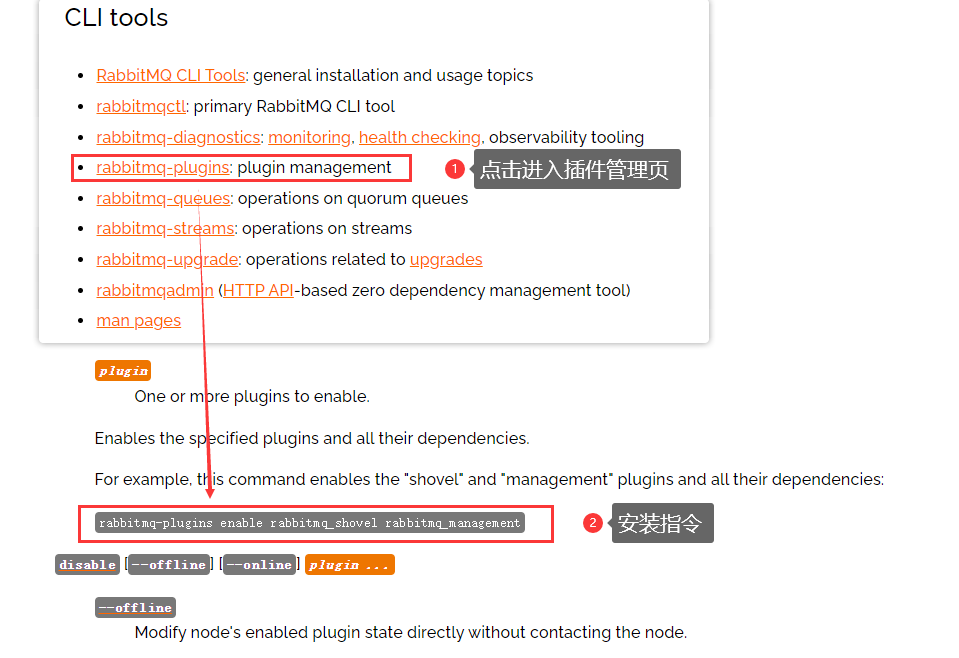
# 安装指令
rabbitmq-plugins enable rabbitmq_shovel rabbitmq_management
# window下安装指令
rabbitmq-plugins.bat enable rabbitmq_shovel rabbitmq_management
进入[RabbitMQ安装目录/sbin目录](D:\software\dev\config\mq\RabbitMQ Server\rabbitmq_server-3.12.0\sbin)(存放RabbitMQ执行脚本),然后执行指令
- rabbitmq-server.bat:操作RabbitMQ服务器相关命令
- rabbitmq-plugins.bat:用于安装RabbitMQ插件
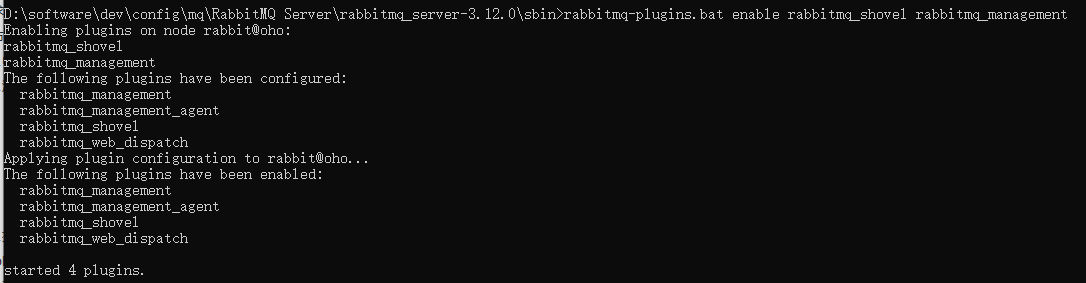
重启服务后才生效(可通过指令重启,也可在【服务】控制台重启)
# 关闭服务
net stop rabbitmq
# 开启服务
net start rabbitmq
重启后访问:http://localhost:15672/#/,账号密码默认guest(参考文档说明)
端口:5672、5671(应用程序之间通过5672端口和RabbitMQ做链接)。类似redis的6379、es的9200
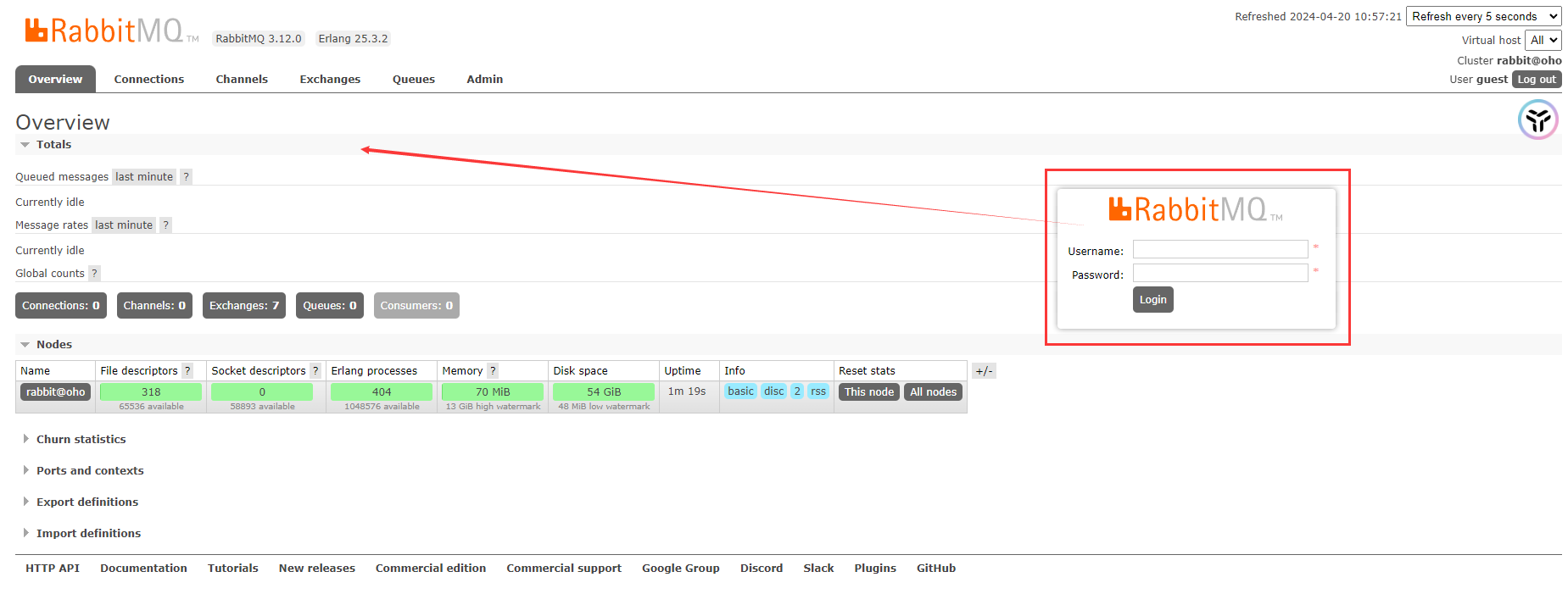
注意:如果你打算在自己的服务器上部署 RabbitMQ,你必须知道在默认设置下,使用 guest 账号是无法访问的。为何会这样呢?原因在于系统安全性的需求。如果你想从远程服务器访问管理面板,你需要创建一个新的管理员账号,不能使用默认的 guest 账号,否则会被系统拦截,导致无法访问或登录。点击右侧的 User guest,会发现该用户拥有管理员权限,但这仅限于本地访问。如果你直接上线并使用默认的管理员权限,你可以想象可能出现的问题。比如,攻击者可能会扫描你服务器的端口,并不断尝试用 guest 账号登录。一旦找到一个开放的端口并用 guest 登录,攻击者就可以入侵你的服务器,然后在消息队列中不断添加消息,填满你的服务器硬盘。因此,为了安全,系统默认关闭了 guest 账号的远程访问权限,这也是官方出于安全考虑的措施。关于如何创建管理员账号,在这里就不演示,可以参考官方文档进行操作 -- 官方文档 Add A User
3.快速入门
【1】一对一消息队列模型:Hello World
RabbitMQ安装、启动完成,则可参考官网文档完成一个demo示例
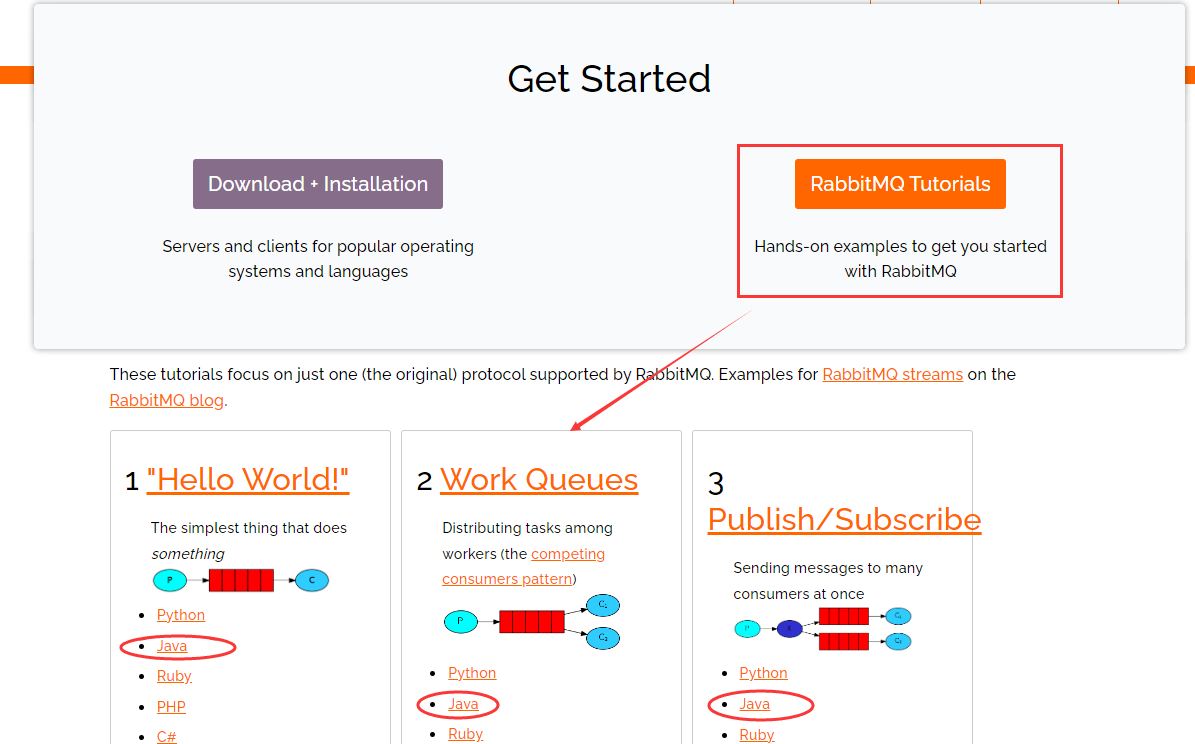
选择第一个HelloWorld示例
步骤1:引入maven依赖


根据提示,去maven仓库安装rabbitmq依赖:此处选择5.17.0版本
<!-- https://mvnrepository.com/artifact/com.rabbitmq/amqp-client -->
<dependency>
<groupId>com.rabbitmq</groupId>
<artifactId>amqp-client</artifactId>
<version>5.17.0</version>
</dependency>
步骤2:构建生产者(消息发送者)
继续下滑可以根据链接提示找到完整代码示例
// 定义SingerProducer:实现消息发送功能
public class SingerProducer {
// 定义静态常量(hello):表示向名为hello的队列发送信息
private final static String QUEUE_NAME = "hello";
public static void main(String[] argv) throws Exception {
// 创建ConnectionFactory对象,用于创建到RabbitMQ服务器的连接(设置factory的相关属性)
ConnectionFactory factory = new ConnectionFactory();
// 设置连接主机(如果修改了端口号、设定了用户名密码,则此处相应要设置,如果没有额外变动则默认即可)
factory.setHost("localhost");
// 创建连接:实现与RabbitMQ服务进行交互
try (Connection connection = factory.newConnection();
// 在通道声明一个队列,指定队列名为htllo
Channel channel = connection.createChannel()) {
channel.queueDeclare(QUEUE_NAME, false, false, false, null);
// 构建要发送的消息内容
String message = "Hello World!";
// 使用channel.basicPublish方法发布消息到指定队列
channel.basicPublish("", QUEUE_NAME, null, message.getBytes(StandardCharsets.UTF_8));
System.out.println(" [x] Sent '" + message + "'");
}
}
}
启动访问测试:
此时再访问http://localhost:15672/#/,查看消息队列
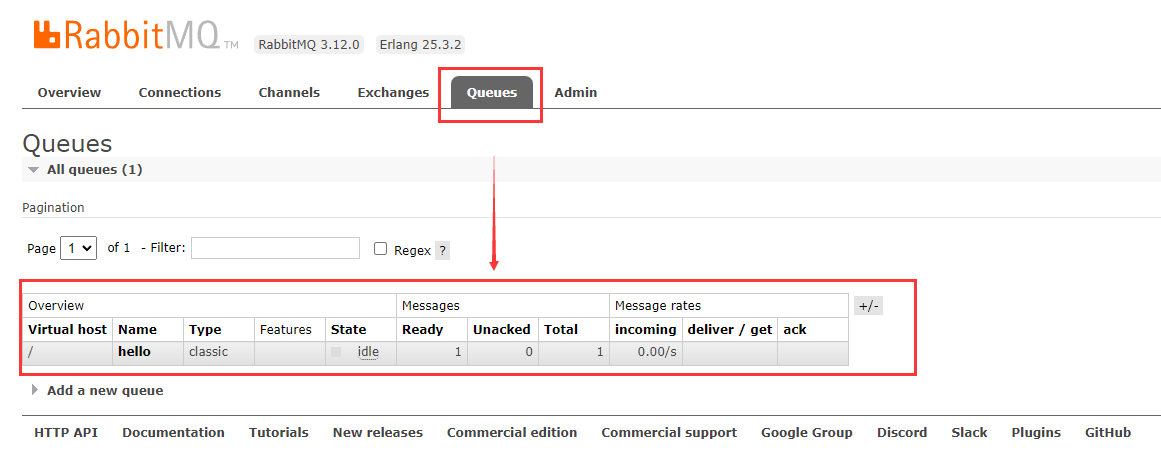
消息发送完成,则构建消费者去消费这个消息
步骤3:构建消费者
public class SingerConsumer {
// 定义静态常量(hello):表示正在监听的队列名称
private final static String QUEUE_NAME = "hello";
public static void main(String[] argv) throws Exception {
// 创建连接工厂,设置连接属性
ConnectionFactory factory = new ConnectionFactory();
factory.setHost("localhost");
// 从工厂获取一个姓的连接
Connection connection = factory.newConnection();
// 创建连接通道
Channel channel = connection.createChannel();
// 创建队列,在该频道中声明正在监听的队列
channel.queueDeclare(QUEUE_NAME, false, false, false, null);
System.out.println(" [*] Waiting for messages. To exit press CTRL+C");
// 处理消息:使用deliverCallback处理接收到的消息
DeliverCallback deliverCallback = (consumerTag, delivery) -> {
String message = new String(delivery.getBody(), StandardCharsets.UTF_8);
System.out.println(" [x] Received '" + message + "'");
};
// 在指定频道上消费队列中的消息,接收到的消息会传递给deliverCallback处理,持续阻塞
channel.basicConsume(QUEUE_NAME, true, deliverCallback, consumerTag -> { });
}
}
为什么要创建队列?
主要是为了确保该队列的存在,否则在后续的操作中可能会出现错误。主要是为了这点,即便你的队列原本并不存在,此语句也能够帮你创建一个新的队列。但是需要特别注意一点,如果你的队列已经存在,并且你想再次执行声明队列的操作,那么所有的参数必须与之前的设置完全一致。这是因为一旦一个队列已经被创建,就不能再创建个与其参数不一致的同名队列。可以类比为,一旦你建好了一个快递站,就不能再在同一位置建立一个与之不同的快递站。
注意:请确保消费队列的名称与发送消息的队列名称保持一致。所以在这里,我们统一使用"hello"作为队列名。
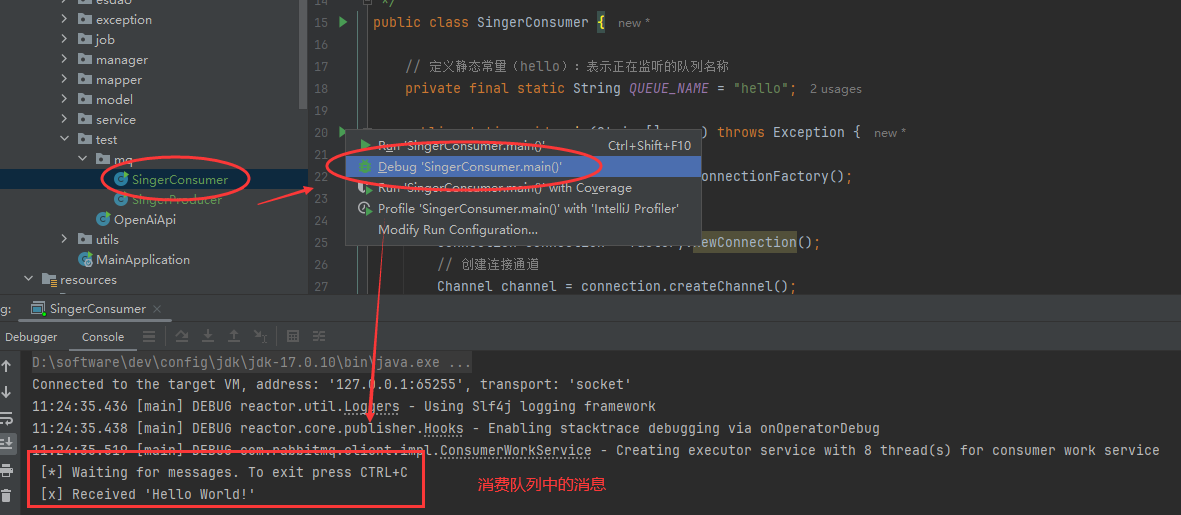
启动测试查看消费结果,可以看到已经获取到信息,此时再去RabbitMQ管理页面查看通道的队列信息,已经消费完了
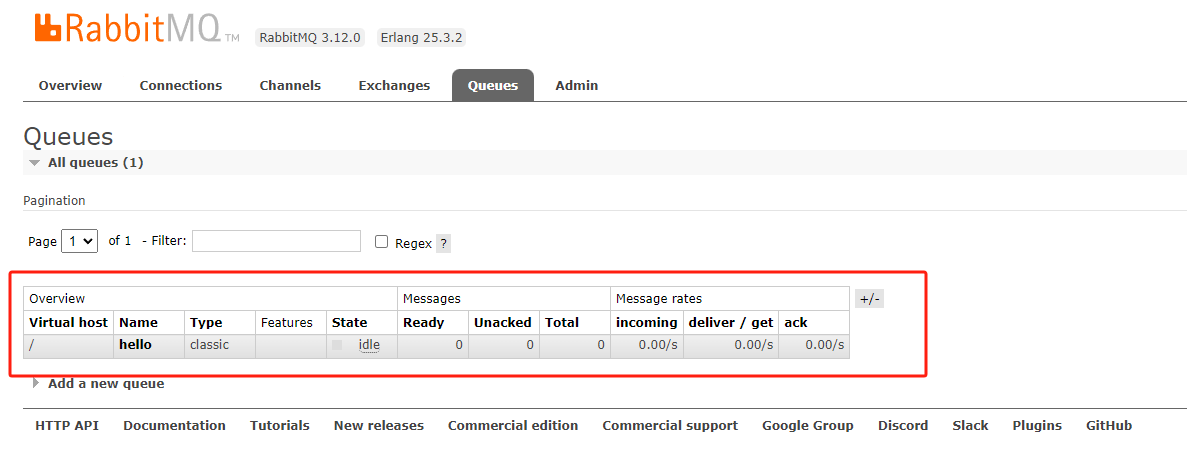
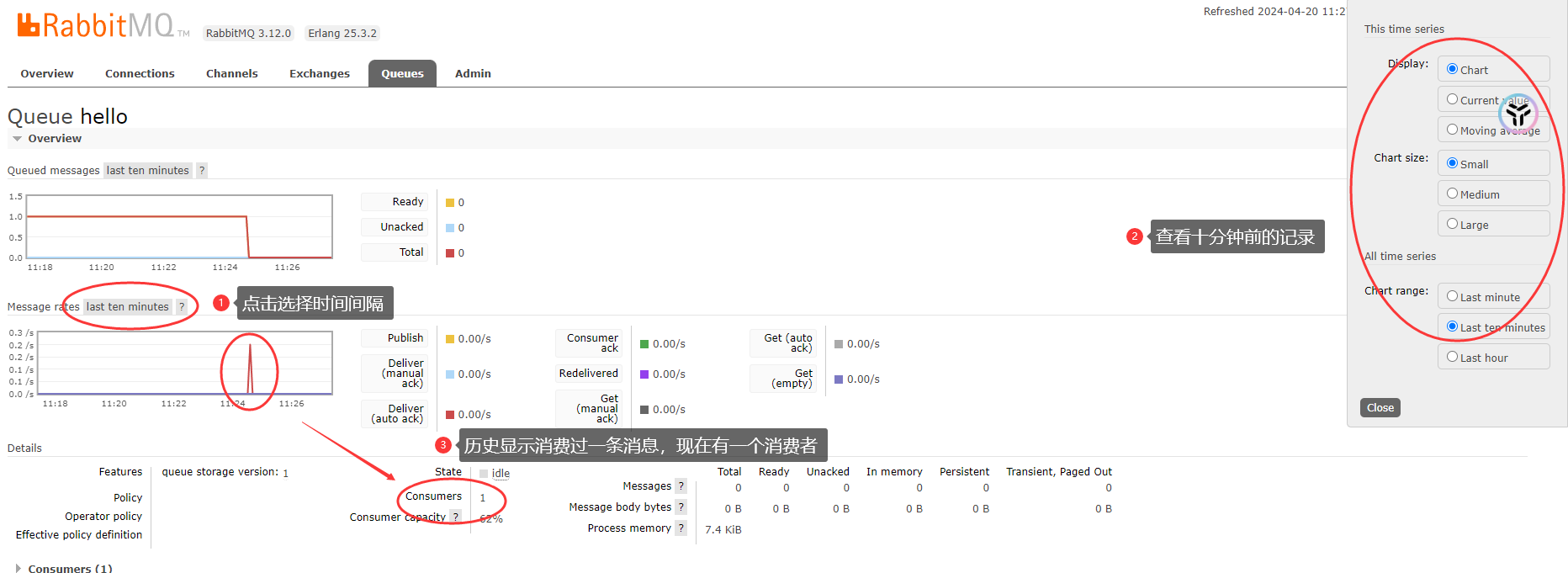
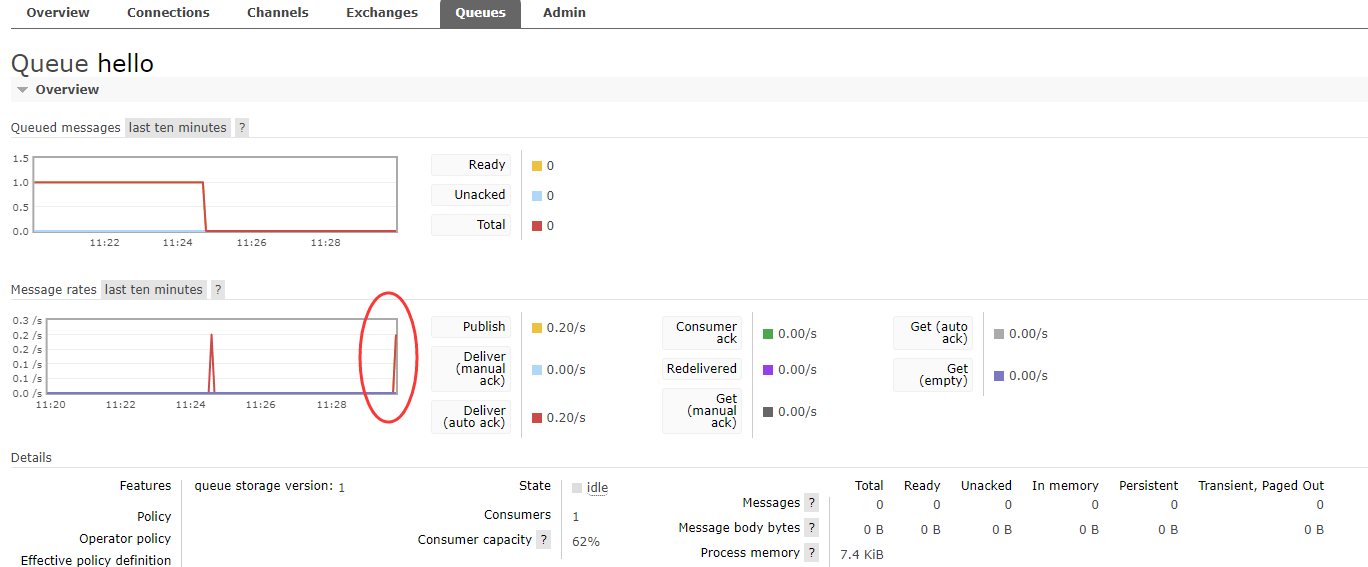
此时再次用生产者生产一条消息,然后在RabbitMQ页面查看消费记录(因为消费者启动后是持续监听、消费),可以看到生产的消息立马被消费了
【2】Work Queue
测试小技巧
(1)生产者通过Scanner控制输入模拟生产
(2)消费者通过for循环构建多个消费者,验证队列模型工作机制
继续第2个实例:Work Queue
这里消息队列的模型为:一个生产者给一个队列发消息,多个消费者 从这个队列取消息(1 对多)。这里的图和之前 hello word 的图有什么区别?是不是多了一个消费者;就像一个快递员都往一个快递站里发快递,但是取快递可以是多个人。
适用的场景:多个机器同时去接受并处理任务(尤其是每个机器的处理能力有限)
这有点像发布-订阅模型,适用于什么场景呢?假设我们有一个消费者,由于其性能有限,可能无法处理所有任务。此时,我们可以增加机器来提高处理能力。假设一个生产者在不断地生成任务,但一个消费者无法全部处理,那么我们可以增加一个消费者来共同完成这些任务。因此,这种场景特别适合于多个机器同时接收并处理任务,尤其是在每个机器的处理能力有限的情况下
思考:一个UP主发布的视频被百万粉丝观看,这个感觉像是发布-订阅模型。但实际上,这个场景与我们现在讨论的并不完全相同。
参考案例1,结合官方示例完成测试
涉及代码:
- NewTask.java.source:=》MultiProducer(基于原有代码基础调整消息输入为控制台输入控制)
- Worker.java.source:=》MultiConsumer
启动生产者生产信息
public class MultiProducer {
// 定义静态常量(hello):表示向名为hello的队列发送信息
private static final String TASK_QUEUE_NAME = "task_queue";
public static void main(String[] argv) throws Exception {
// 创建ConnectionFactory对象,用于创建到RabbitMQ服务器的连接(设置factory的相关属性)
ConnectionFactory factory = new ConnectionFactory();
factory.setHost("localhost");
// 创建连接:实现与RabbitMQ服务进行交互
try (Connection connection = factory.newConnection();
// 创建新频道:声明队列参数(队列名称、是否持久化等)
Channel channel = connection.createChannel()) {
channel.queueDeclare(TASK_QUEUE_NAME, true, false, false, null);
// 创建输入扫描器,读取控制台输入内容发送
Scanner console = new Scanner(System.in);
while (console.hasNext()) {
// 读取控制台文本
String message = console.next();
// 发布消息队列,设置消息持久化
channel.basicPublish("", TASK_QUEUE_NAME,
MessageProperties.PERSISTENT_TEXT_PLAIN,
message.getBytes("UTF-8"));
System.out.println(" [x] Sent '" + message + "'");
}
}
}
}
启动消费者消费信息
public class MultiConsumer {
private static final String TASK_QUEUE_NAME = "task_queue";
public static void main(String[] argv) throws Exception {
// 创建连接工厂,设置连接信息
ConnectionFactory factory = new ConnectionFactory();
factory.setHost("localhost");
// 从工厂获取连接
final Connection connection = factory.newConnection();
// 创建新通道
final Channel channel = connection.createChannel();
// 声明一个队列:设置队列属性:队列名称、持久化、非排他、非自动删除、其他参数;如果队列不存在则创建
channel.queueDeclare(TASK_QUEUE_NAME, true, false, false, null);
System.out.println(" [*] Waiting for messages. To exit press CTRL+C");
// 设计预取计数为1,RabbitMQ给消费者新消息之前等待之前的消息被确认
// channel.basicQos(1);
// 创建消息回调函数,接收信息
DeliverCallback deliverCallback = (consumerTag, delivery) -> {
String message = new String(delivery.getBody(), "UTF-8");
try {
System.out.println(" [x] Received '" + message + "'");
// 模拟处理工作(设定模拟处理花费时间,计算机处理能力有限,接收一条消息之后20s后再接收下一条消息)
// doWork(message);
Thread.sleep(20000);
} catch (InterruptedException e) {
throw new RuntimeException(e);
} finally {
System.out.println(" [x] Done");
// 手动发送应答,告诉RabbitMQ消息已经被处理
channel.basicAck(delivery.getEnvelope().getDeliveryTag(), false);
}
};
// 开始消费信息,传入队列名称、是否自动确认、投递回调、消费者取消回调
channel.basicConsume(TASK_QUEUE_NAME, false, deliverCallback, consumerTag -> { });
}
}
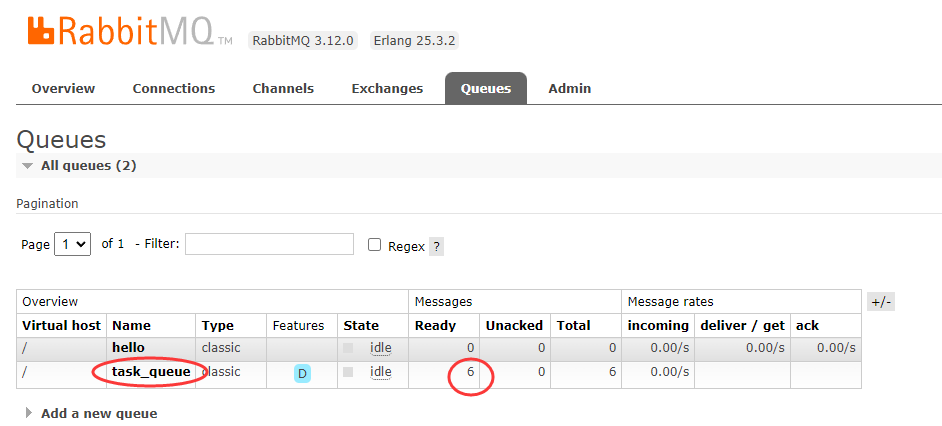
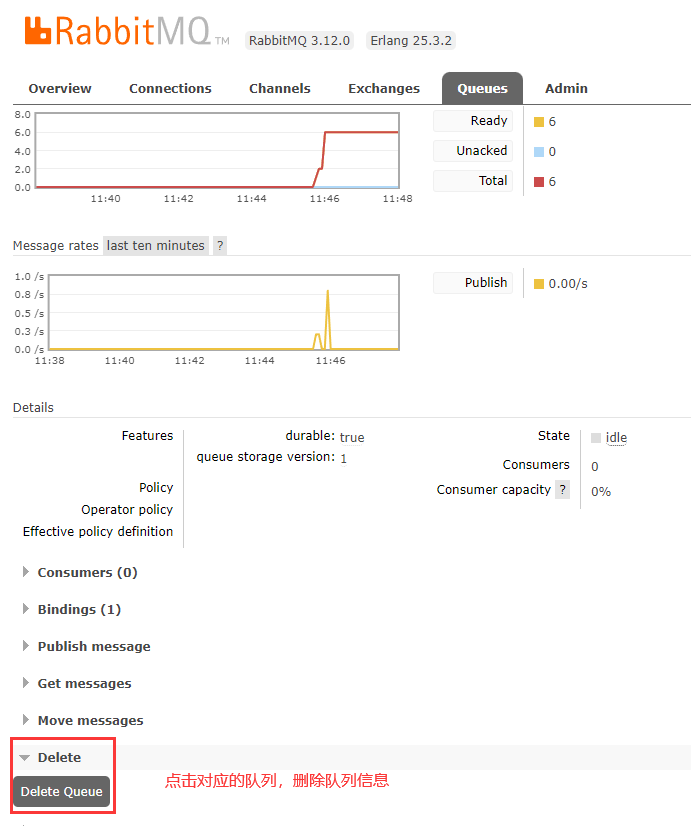
消费者消费完队列所有信息,查看控制台光标闪烁,说明目前还在监听队列。此时再通过生产者控制台输入消息发送模拟生产,再查看RabbitMQ控制台和消费者控制台输出情况
基于目前的设定,消费者要每隔20s处理完当前信息之后才能继续消费下一个消息(可以理解为计算机处理能力有限,只能一个个处理),那么思考一个问题?如何在处理能力有限的情况下提高并发能力:此处先取消预计取数channel.basicQos(1)(控制单个消费者的处理任务积压数)
# 设定channel.basicQos(1);
// 设计预取计数为1,RabbitMQ给消费者新消息之前等待之前的消息被确认
// channel.basicQos(1);
# 将创建通道的代码通过for封装(类似构建不同的通道访问)
for (int i = 0; i < 2; i++) {
// 通道创建、消费消息、回调响应处理
}
private static void publishMessage02() throws Exception {
// 创建连接工厂,设置连接信息
ConnectionFactory factory = new ConnectionFactory();
factory.setHost("localhost");
// 从工厂获取连接
final Connection connection = factory.newConnection();
// 将通道创建的代码通过for封装
for (int i = 0; i < 2; i++) {
// 创建新通道
final Channel channel = connection.createChannel();
// 声明一个队列:设置队列属性:队列名称、持久化、非排他、非自动删除、其他参数;如果队列不存在则创建
channel.queueDeclare(TASK_QUEUE_NAME, true, false, false, null);
System.out.println(" [*] Waiting for messages. To exit press CTRL+C");
// 设计预取计数为1,RabbitMQ给消费者新消息之前等待之前的消息被确认
channel.basicQos(1);
// 创建消息回调函数,接收信息
DeliverCallback deliverCallback = (consumerTag, delivery) -> {
String message = new String(delivery.getBody(), "UTF-8");
try {
System.out.println(" [x] Received '" + message + "'");
// 模拟处理工作(设定模拟处理花费时间,计算机处理能力有限,接收一条消息之后20s后再接收下一条消息)
Thread.sleep(20000);
} catch (InterruptedException e) {
throw new RuntimeException(e);
} finally {
System.out.println(" [x] Done");
// 手动发送应答,告诉RabbitMQ消息已经被处理
channel.basicAck(delivery.getEnvelope().getDeliveryTag(), false);
}
};
// 开始消费信息,传入队列名称、是否自动确认、投递回调、消费者取消回调
channel.basicConsume(TASK_QUEUE_NAME, false, deliverCallback, consumerTag -> {
});
}
}
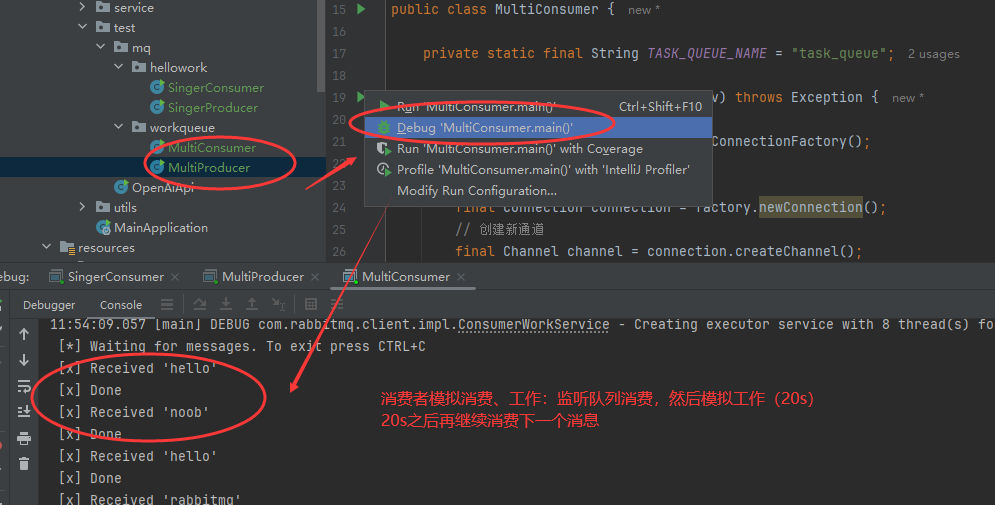
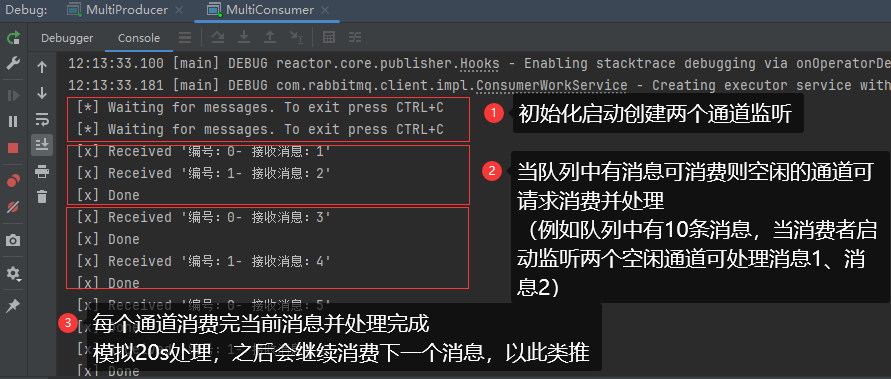
生产者再次生产多个消息(先发布到队列中),然后查看消费者监听和消费情况,可以看到下面的内容效果(构建不同通道可以理解为设置多个不同的消费者模拟消费)
消费确认机制
这里有个很有意思的地方,叫 autoack,默认为 false -- 消息确认机制。消息队列如何确保消费者已经成功取出消息呢?它依赖一个称为消息确认的机制。当消费者从队列中取走消息后必须对此进行确认。这就像在收到快递后确认收货一样,这样消息队列才能知道消费者已经成功取走了消息,并能安心地停止传输。因此,整个过程就像这样。 思考一个问题:如何保证消息不会丢失,例如当业务流程失败时该怎么办,可以回答:“可以选择拒绝接收失败的消息,并重新启动。重新启动或进行其他处理可以指定拒绝某条消息。
为了保证消息成功被消费(快递成功被取走),rabbitmq 提供了消息确认机制,当消费者接收到消息后,比如要给一个反馈:
- ack:消费成功
- nack:消费失败
- reject:拒绝
如果告诉 rabbitmg 服务器消费成功,服务器才会放心地移除消息
channel.basicConsume(TASK_QUEUE_NAME, false, deliverCallback, consumerTag -> {});
但是,如果在接收到消息后,工作尚未完成,是否就不需要确认成功呢?这种情况,建议将 autoack 设置为false 根据实际情况手动进行确认了
// 指定确认某条消息
channel.basicAck(delivery.getEnvelope().getDeliveryTag(), false);
- 参数1:要确认消息
- 参数2:multiple 批量确认,是否需要一次性确认所有的历史消息,直到当前这条消息为止
- 参数3: requeue 是否重新入列,可用于重试
// 指定拒绝某条消息
channel.basicNack(delivery.getEnvelope().getDeliveryTag(), false);
在消息消费的流程中,如果你拒绝处理某条消息,那么该消息将被标记为失败。这意味着它将返回到队列中,等待重新处理。如果你选择不重新入队该消息,那么这条消息将被丢弃,不会再被消费者处理。因此,拒绝消息相当于将其废弃掉,不再进行后续处理。这是保证消息不丢失的一部分流程。
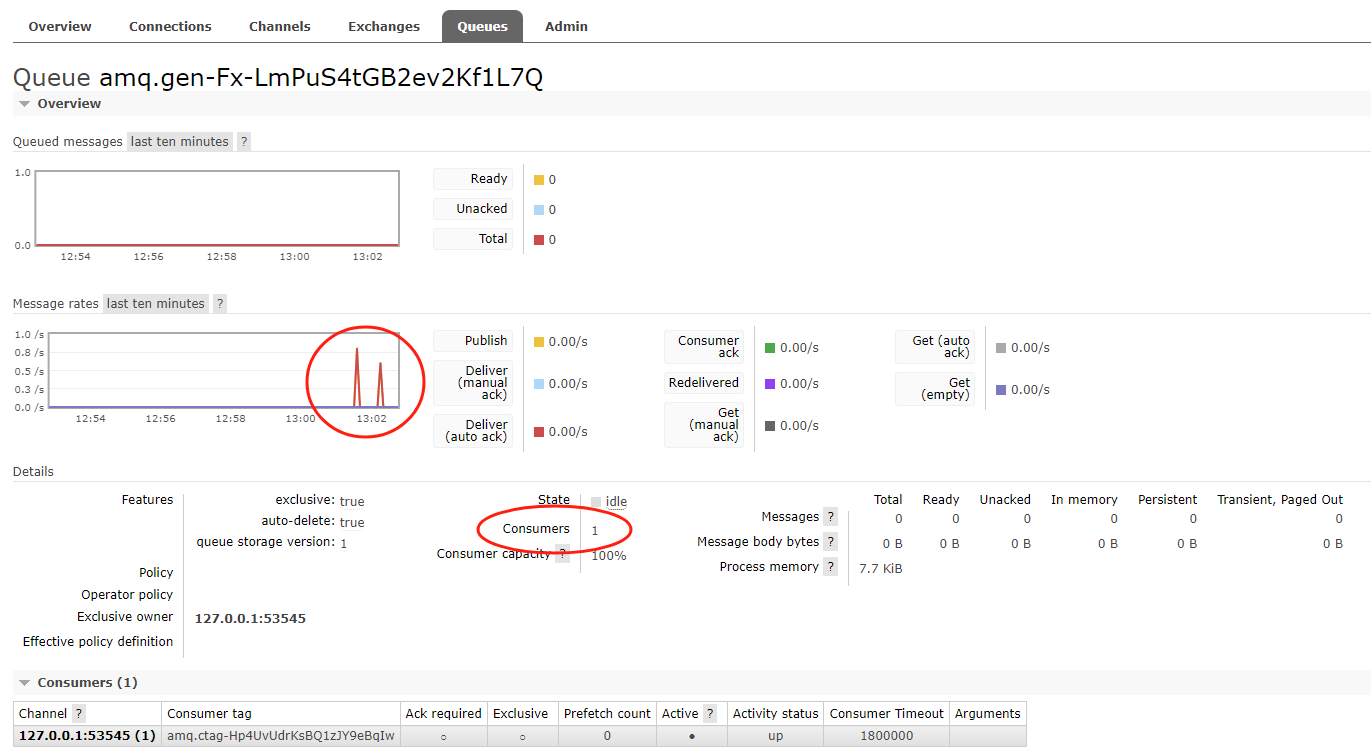
断点测试:设置为手动应答,重启生产者、消费者项目,然后debug:生产者生产消息,可以看到消息立马被处理且进入断点为止,随后在RabbitMQ处查看消息的确认情况
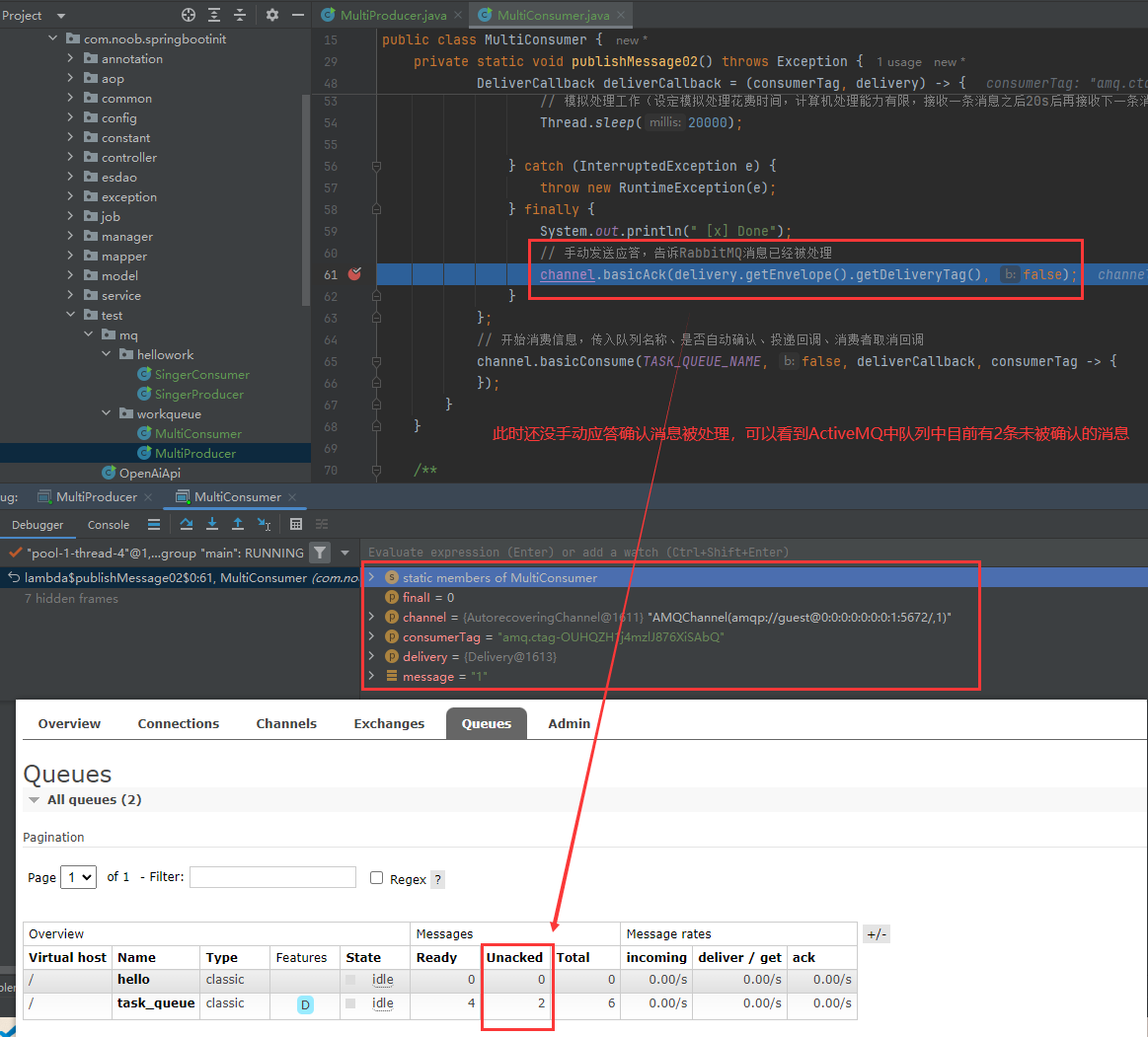
确认放行,然后再查看RabbitMQ控制台消息的消费情况,可以看到Unacked为0,说明手动确认成功

【3】发布/订阅模式
概念梳理
什么是交换机?
交换机 是消息队列中的一个组件,其作用类似于网络路由器。它负责将我们发送的消息转发到相应的目标,就像快递站将快递发送到对应的站点,或者网络路由器将网络请求转发到相应的服务器或客户端一样。交换机的主要功能是提供转发消息的能力,根据消息的路由规则将消息投递到合适的队列或绑定的消费者。我们可以理解为,如果说一个快递站已经承受不了那么多的快递了,就建多个快递站。
交换机:一个生产者给 多个 队列发消息(1 个生产者对多个队列)。
交换机的作用:提供消息转发功能,类似于网络路由器。
要解决的问题:怎么把消息转发到不同的队列上,好让消费者从不同的队列消费
(核心概念)绑定:交换机和队列关联起来,也可以叫路由,算是一个算法或转发策略。
交换机的类别:fanout、direct,topic, headers(每种类别的应用场景都不同)
// 绑定代码
channel.queueBind(queueName,EXCHANGE_NAME,"绑定规则");
fanout
扇出:将消息广播到所有绑定到该交换机的队列的过程。它得名于扇形扩散的形状,类似于把一条消息从交换机传播到多个队列,就像扇子展开一样
广播:将消息发送到所有与该交换机绑定的队列的过程。当发布者将消息发送到 fanout 交换机时,交换机会立即将该消息复制并传递给所有绑定的队列,无论目标队列的数量是多少
特点:消息会被转发到所有绑定到该交换机的队列
场景:很适用于发布订阅的场景。比如写日志,可以多个系统间共享
涉及代码:
- EmitLog.java.source:=》FanoutProducer(基于原有代码基础调整消息输入为控制台输入控制)
- EmitLog.java.source:=》FanoutConsumer
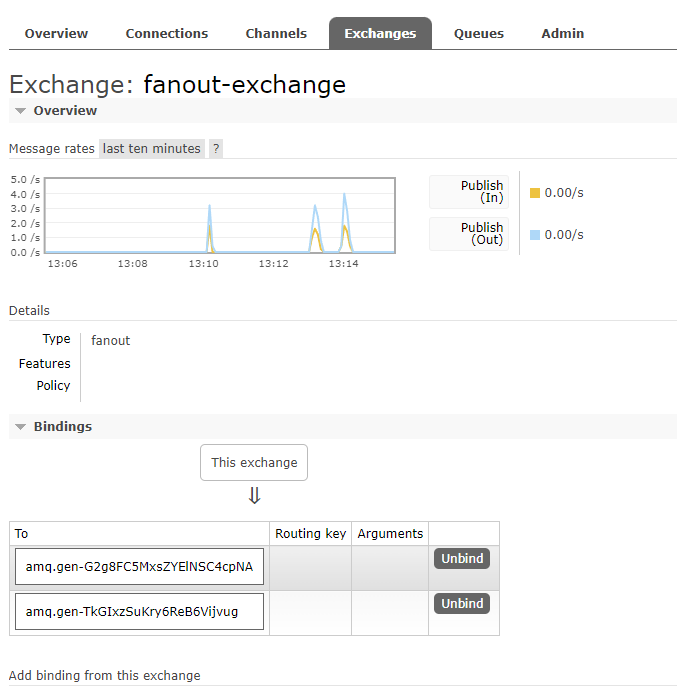
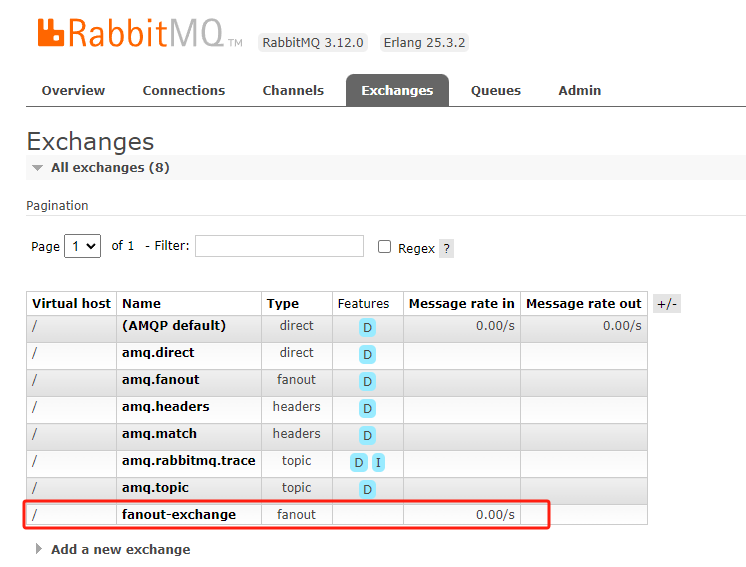
启动生产者,然后生产消息,随后可在RabbitMQ的Exchanges中跟踪
public class FanoutProducer {
// 定义要使用的交换机名称
private static final String EXCHANGE_NAME = "fanout-exchange";
public static void main(String[] argv) throws Exception {
// 创建连接工厂,设置属性
ConnectionFactory factory = new ConnectionFactory();
factory.setHost("localhost");
// 创建连接、通道
try (Connection connection = factory.newConnection();
Channel channel = connection.createChannel()) {
// 声明交换机类型
channel.exchangeDeclare(EXCHANGE_NAME, BuiltinExchangeType.FANOUT);
// 创建Scanner模拟生产(通过控制台输入生产消息)
Scanner scanner = new Scanner(System.in);
while (scanner.hasNextLine()) {
String message = scanner.next();
// 将消息发送到指定的交换机(fanout交换机),不指定路由键(空字符串)
channel.basicPublish(EXCHANGE_NAME, "", null, message.getBytes("UTF-8"));
// 打印发送的消息内容
System.out.println(" [x] Sent '" + message + "'");
}
}
}
}
启动消费者
public class FanoutConsumer {
private static final String EXCHANGE_NAME = "fanout-exchange";
public static void main(String[] argv) throws Exception {
// 创建工厂,设置属性
ConnectionFactory factory = new ConnectionFactory();
factory.setHost("localhost");
// 创建连接和通道
Connection connection = factory.newConnection();
Channel channel = connection.createChannel();
channel.exchangeDeclare(EXCHANGE_NAME, BuiltinExchangeType.FANOUT);
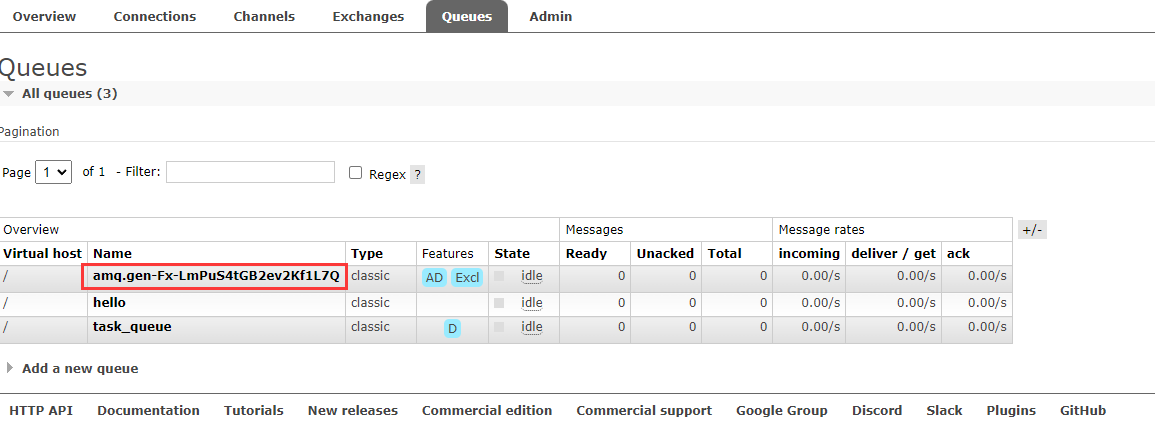
String queueName = channel.queueDeclare().getQueue();
// 绑定交换机
channel.queueBind(queueName, EXCHANGE_NAME, "");
System.out.println(" [*] Waiting for messages. To exit press CTRL+C");
// 回调处理
DeliverCallback deliverCallback = (consumerTag, delivery) -> {
String message = new String(delivery.getBody(), "UTF-8");
System.out.println(" [x] Received '" + message + "'");
};
channel.basicConsume(queueName, true, deliverCallback, consumerTag -> { });
}
}
场景模拟(老板下发任务到交换机,不同员工处理)
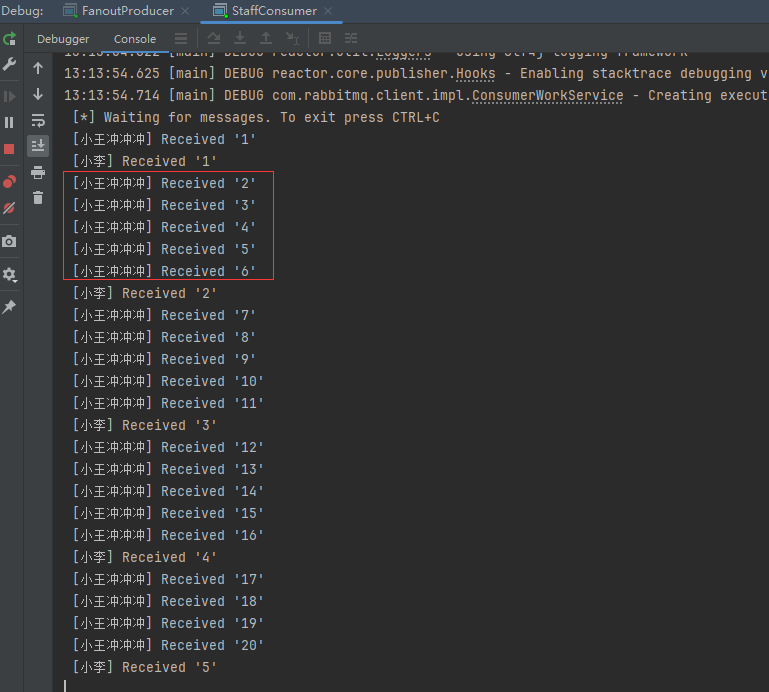
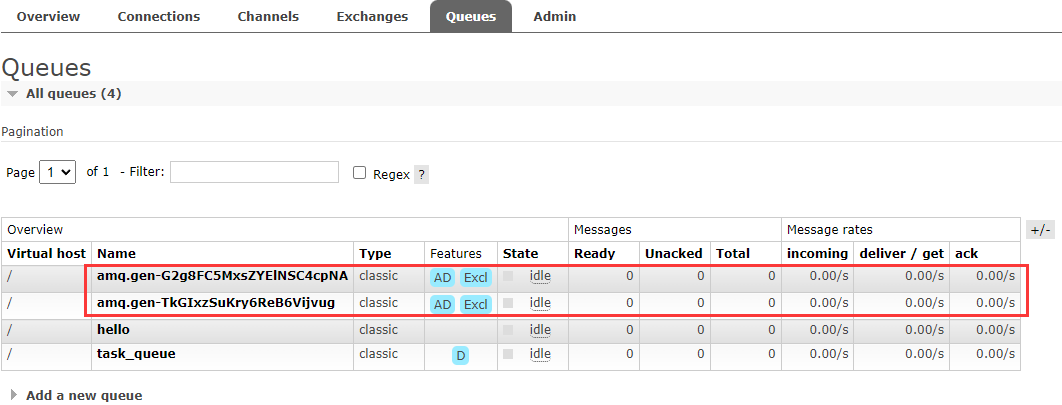
场景分析:有两个消费者,分别是员工小王和员工小李。创建了两个任务队列,一个是小王的任务队列,另一个是小李的任务队列。老板要下发任务了,这时候需要使用交换机。老板将任务发送给交换机,然后交换机会将任务广播给所有的消息队列,也就是小王的任务队列和小李的任务队列。接下来员工小王和小李作为消费者,从各自的任务队列中获取任务消息。现在使用代码来实现这个场景。
public class StaffConsumer {
private static final String EXCHANGE_NAME = "fanout-exchange";
public static void main(String[] argv) throws Exception {
// 创建工厂,设置属性
ConnectionFactory factory = new ConnectionFactory();
factory.setHost("localhost");
// 创建连接和通道
Connection connection = factory.newConnection();
// 1.分别创建两个通道(模拟员工小王和小李):分别声明交换机、创建队列并绑定交换机
Channel channelWang = connection.createChannel();
channelWang.exchangeDeclare(EXCHANGE_NAME, BuiltinExchangeType.FANOUT);
String queueWang = channelWang.queueDeclare().getQueue();
channelWang.queueBind(queueWang, EXCHANGE_NAME, "");
Channel channelLi = connection.createChannel();
channelLi.exchangeDeclare(EXCHANGE_NAME, BuiltinExchangeType.FANOUT);
String queueLi = channelLi.queueDeclare().getQueue();
channelLi.queueBind(queueLi, EXCHANGE_NAME, "");
// 打印等待信息
System.out.println(" [*] Waiting for messages. To exit press CTRL+C");
// 2.分别创建两个交付回调函数(模拟小王和小李回调交付)
DeliverCallback deliverCallbackWang = (consumerTag, delivery) -> {
String message = new String(delivery.getBody(), "UTF-8");
System.out.println(" [小王冲冲冲] Received '" + message + "'");
// 模拟工作(小王工作效率高:2s处理一个任务)
doWork(2000);
};
DeliverCallback deliverCallbackLi = (consumerTag, delivery) -> {
String message = new String(delivery.getBody(), "UTF-8");
System.out.println(" [小李] Received '" + message + "'");
// 模拟工作(小李工作效率低:10s处理一个任务)
doWork(10000);
};
// 3.开始消费队列
channelWang.basicConsume(queueWang, true, deliverCallbackWang, consumerTag -> { });
channelLi.basicConsume(queueLi, true, deliverCallbackLi, consumerTag -> { });
}
/**
* 模拟工作
* @param time
*/
private static void doWork(int time) {
// 模拟工作
try {
Thread.sleep(time);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
}
关闭所有测试,然后重启生产者模拟生产消息,启动StaffConsumer模拟消费(假设设定小王处理的效率较高),两个员工分别从各自的队列获取任务并处理