[Oracle基础]-PL/SQL
[Oracle基础]-PL/SQL
[TOC]
1.PL/SQL程序设计
【1】什么是PL/SQL
PL/SQL(Procedure Language/SQL)
PLSQL是Oracle对sql语言的过程化扩展
指在SQL命令语言中增加了过程处理语句(如分支、循环等),使SQL语言具有过程处理能力
把SQL语言的数据操纵能力与过程语言的数据处理能力结合起来,使得PLSQL面向过程但比过程语言简单、高效、灵活和实用
Plsql(oracle), Transact-sql(SQL server)
PL/SQL 是一种高性能的基于事务处理的语言,能运行在任何ORACLE 环境中,支持所有数据处理命令。通过使用PL/SQL 程序单元处理SQL 的数据定义和数据控制元素。
PL/SQL 支持所有SQL 数据类型和所有SQL 函数,同时支持所有ORACLE 对象类型
PL/SQL 块可以被命名和存储在ORACLE 服务器中,同时也能被其他的PL/SQL 程序或SQL 命令调用,任何客户/服务器工具都能访问PL/SQL 程序,具有很好的可重用性。
可以使用ORACLE 数据工具管理存储在服务器中的PL/SQL 程序的安全性。可以授权或撤销数据库其他用户访问PL/SQL 程序的能力。
PL/SQL 代码可以使用任何ASCII 文本编辑器编写,所以对任何ORACLE 能够运行的操作系统都是非常便利的
对于SQL,ORACLE 必须在同一时间处理每一条SQL 语句,在网络环境下这就意味作每一个独立的调用都必须被oracle 服务器处理,这就占用大量的服务器时间,同时导致网络拥挤。而PL/SQL 是以整个语句块发给服务器,这就降低了网络拥挤
Plsql工具不像Eclipse那样提示错误,需要自己慢慢调试错误
案例分析
基本操作:写一段PL/SQL程序,在屏幕上打印“hello plsql”
打开cmd窗口,登录到相应的用户进行操作:sqlplus 用户名/密码
基本语法格式:
declare --声明
--如果没有要声明的变量可以不写
begin --开始
--此处定义要执行的语句内容
--输出字符串‘hello plsql’
dbms_output.put_line('hello pl/sql');
end; --结束
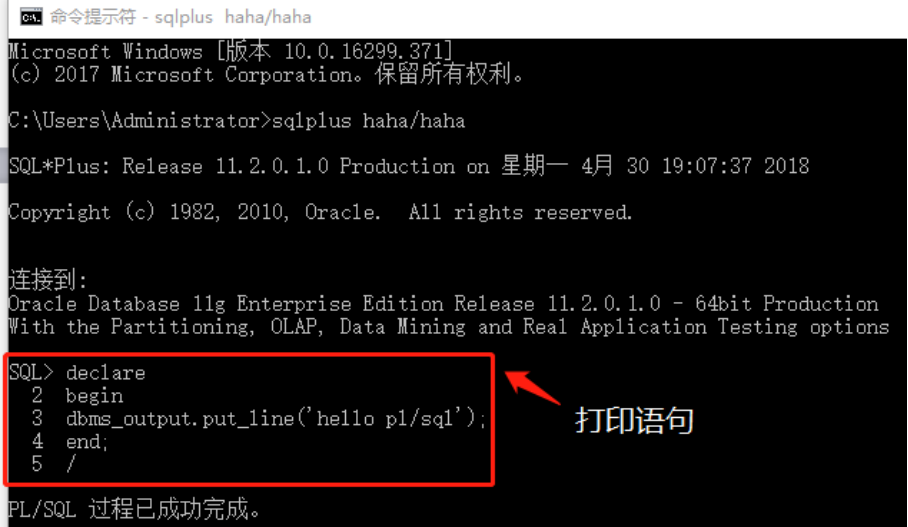
注意:如果要在屏幕上输出信息,需要将serveroutput开关打开:set serveroutput on
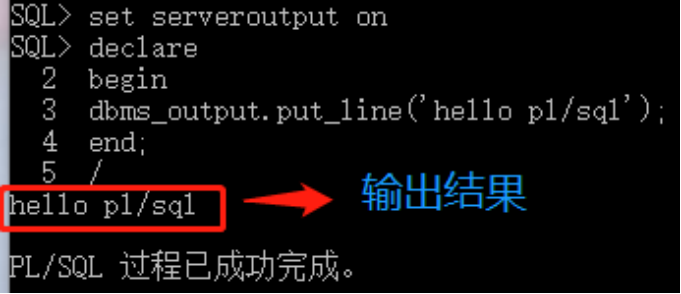
--打印Hello World
set serveroutput on
declare
--变量说明
begin
--程序体
dbms_output.put_line('Hello World');
end;
/ --表示指令输入结束
【2】PL/SQL程序结构
PL/SQL 是一种块结构的语言,组成PL/SQL 程序的单元是逻辑块,一个PL/SQL 程序包含了一个或多个逻辑块,每个块都可以划分为三个部分。与其他语言相同,变量在使用之前必须声明,PL/SQL 提供了独立的专门用于处理异常的部分,下面描述了PL/SQL 块的不同部分:
声明部分(Declaration section)
声明部分包含了变量和常量的数据类型和初始值。这个部分是由关键字DECLARE 开始,如果不需要声明变量或常量,那么可以忽略这一部分;需要说明的是游标的声明也在这一部分
执行部分(Executable section)
执行部分是PL/SQL 块中的指令部分,由关键字BEGIN 开始,所有的可执行语句都放在这一部分,其他的PL/SQL 块也可以放在这一部分
异常处理部分(Exception section)
这一部分是可选的,在这一部分中处理异常或错误,对异常处理的详细讨论我们在后面进行
declare
说明部分 (变量说明,光标申明,例外说明 〕
begin
语句序列 (DML语句〕…
exception
例外处理语句
end;
/
说明:
如果没有变量,就可以不写declare段
PL/SQL对大小写不敏感。
赋值是使用冒号等号“:=”(中间不能有空格)
注释使用“--”或是“/* ... */”(就是SQL注释)
注意最后的end后面有个分号
【3】基础语法结构
变量与赋值
说明变量(char, varchar2, date, number, boolean, long)
定义格式:变量名 数据类型 ;
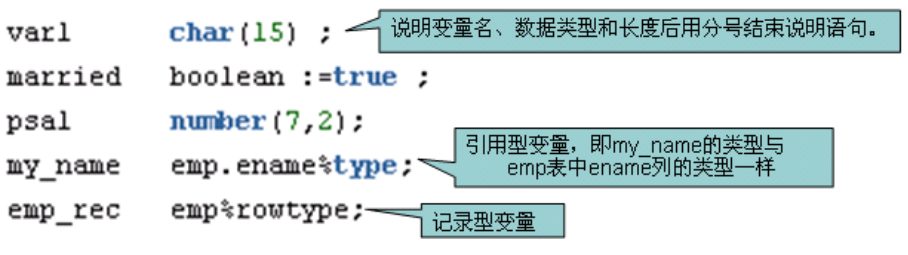
--1.plsql的基础用法
--a.输出指定的字符串
declare --声明
--如果没有要声明的变量可以不写
begin --开始
--此处定义要执行的语句内容
--输出字符串‘hello plsql’
dbms_output.put_line('hello pl/sql');
end; --结束
--查看输出显示
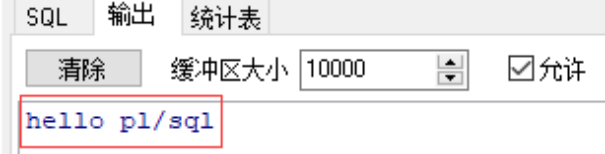
--b.定义带有变量的plsql
--变量可以在定义的时候直接赋值,也可以在执行语句中实现赋值
declare
--变量定义格式:变量名 变量类型 := 初始值;
a number(4) := 10; --在定义变量的时候初始化
b number(4,2);
s1 varchar2(20) := 'hello guigu';
s2 varchar2(20);
begin
--在执行语句中实现变量的赋值
b := 2.56;
s2 := 'hello noob';
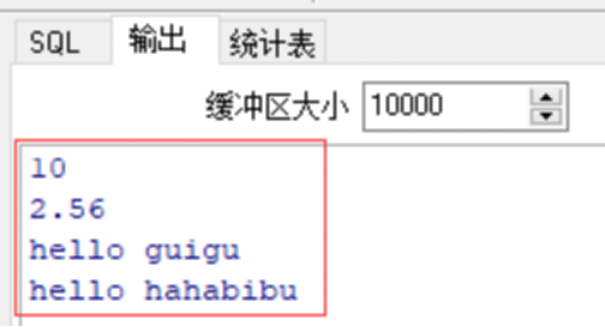
--输出指定的变量内容
dbms_output.put_line(a);
dbms_output.put_line(b);
dbms_output.put_line(s1);
dbms_output.put_line(s2);
end;
--查看输出显示
--c.定义带有用户输入的变量(由用户输入指定的变量值)
declare
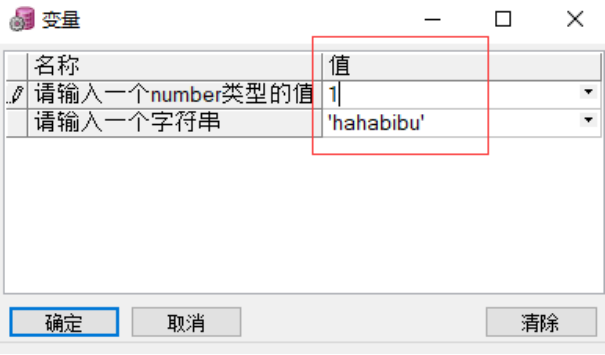
--定义格式: 变量名 变量类型 := &输入提示
a number(4) := &请输入一个number类型的值;
s varchar2(20);
begin
s := &请输入一个字符串;
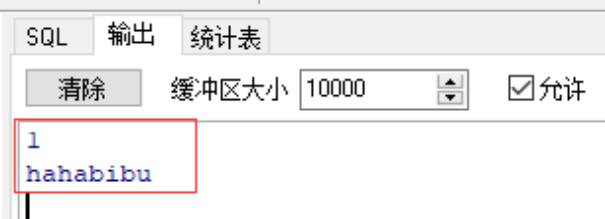
dbms_output.put_line(a);
dbms_output.put_line(s);
--用户输入字符串格式:'输入内容'(单引号)
end;
--查看输出显示
--d.可以从现有的表格中获取指定的数据
/*
定义格式:
select 列名1,列名2 ... into 变量1,变量2...
from 表名
[condictions];
*/
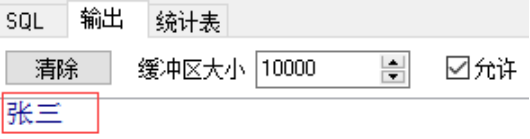
declare
v_name varchar2(20) ;
begin
select sname into v_name from student where sid = 20180001;
dbms_output.put_line(v_name);
end;
--查看输出显示
if语句和case语句
(1)if语句
注意:是ELSIF,不是ELSEIF
--a.流程控制if语句
--流程控制 IF
/**
IF的语法
1.if基础语法
if 条件
then 语句
end if
2.if-else语句
if 条件
then 语句
else
语句
end if
3.if-elsif语句
if 条件1
then 语句1
elsif 条件2
then 语句2
eleif 条件3
then 语句3
...
else 语句
end if
*/
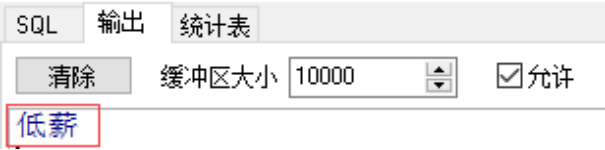
--eg1:查询指定编号的员工工资,如果工资大于3000输出高薪,否则输出低薪
declare (在scott用户下进行测试)
v_sal number(7,2);
begin
select sal into v_sal from emp where empno = 7369;
if v_sal>3000
then dbms_output.put_line('高薪');
else
dbms_output.put_line('低薪');
end if;
end;
--eg2:根据用户输入的分数进行判断
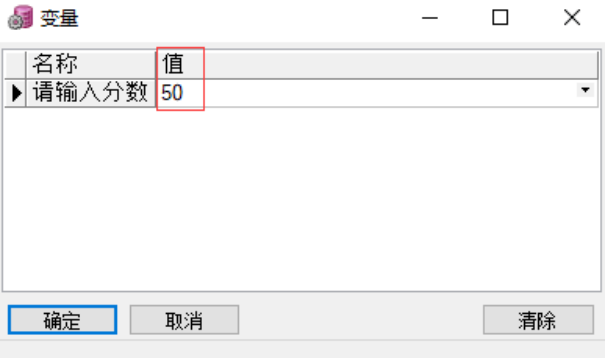
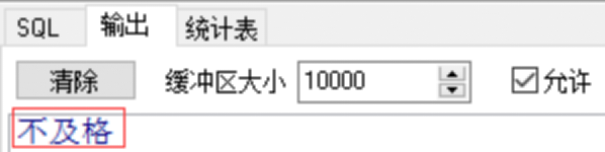
declare
score number(3) := &请输入分数;
begin
if score<60
then dbms_output.put_line('不及格');
elsif score>=60 and score<70
then dbms_output.put_line('及格');
elsif score>=70 and score<80
then dbms_output.put_line('中等');
elsif score>=80 and score<90
then dbms_output.put_line('良好');
elsif score>=90 and score<=100
then dbms_output.put_line('优秀');
else
dbms_output.put_line('成绩输入有误');
end if;
end;
(2)case语句
--b.流程控制case语句
/*
case定义格式:
类似于java中的 switch case,在plsql中 是case when
语法:
case selector
when expresssion1 then ...;
when expression2 then ...;
when expressionn then ...;
else ....;
end case;
*/
--根据输入的不同值,输出相应的提示内容
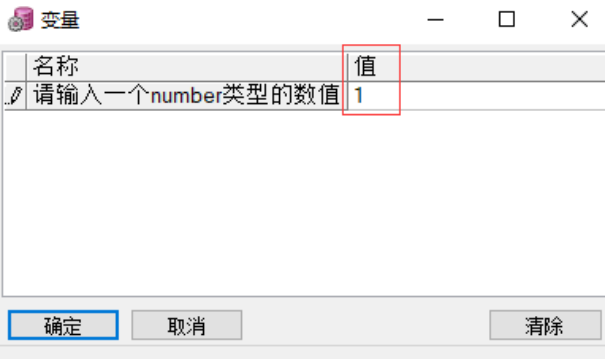
declare
num number(3) := &请输入一个number类型的数值;
begin
case num
when 0 then dbms_output.put_line('hello noob');
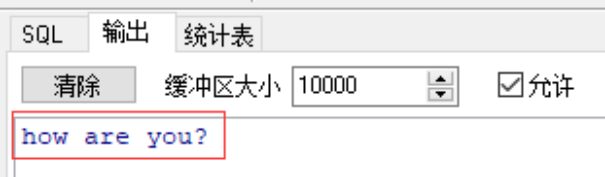
when 1 then dbms_output.put_line('how are you?');
when 2 then dbms_output.put_line('i am fine !');
when 3 then dbms_output.put_line('bye bye!');
else dbms_output.put_line('other....');
end case;
end;
循环语句
(1)loop
--输出1-10的内容
--a.loop循环
/*
loop循环定义格式:
loop
statement1;
..
..
..
exit [when condition];
end loop;
*/
declare
i number(2) := 0;
begin
loop
dbms_output.put_line('i='||i); --字符串拼接
i := i+1; --修改变量值
exit when(i>10);
end loop;
end;
--亦可通过loop结合流程控制if语句实现循环的控制
--输出结果与上方一致
/*
loop结合if语句,定义格式:
/*
loop循环定义格式:
loop
statement1;
..
..
..
if 条件
then exit;
end if;
end loop;
*/
*/
declare
i number(2) := 0;
begin
loop
dbms_output.put_line('i='||i); --字符串拼接
i := i+1; --修改变量值
if i>10
then exit;
end if;
end loop;
end;
(2)while
--b.while循环
/*
while condition
loop
...;
...;
end loop;
*/
declare
i number(2) := 0;
begin
while(i<=10)
loop
dbms_output.put_line('i='||i); --字符串拼接
i := i+1; --修改变量值
end loop;
end;
(3)for
--c.for循环
/*
定义格式:
for counter in lowerbound..upbound
loop
...
...
end loop;
*/
--for循环控制必须从小到大
declare
i number(2) := 0;
begin
for i in 1..10
loop
dbms_output.put_line('i='||i);
end loop;
end;
--如果需要反向输出数据,可通过关键字reverse实现
declare
i number(2) := 0;
begin
for i in reverse 1..10
loop
dbms_output.put_line('i='||i);
end loop;
end;
2.数据类型
【1】记录Record
记录是PL/SQL 的一种复合数据结构,意味着它是由一个或者多个元素组成的,记录非常类似于数据库表中的一行数据,但是记录的每个元素并不是单独存在的
PLSQL支持三种记录的类型:基于表的(table-based)、基于游标的(cursor-based)、程序员定义的
基于表的记录就是该记录的结构来自于数据库表中的某些字段的列表
基于游标的记录是记录的数据结构匹配预定于的游标的元素,为创建一个基于表或者基于游标的记录可以使用%rowtype属性;
--切换到用户scott/scott进行测试
/*
记录
*/
--1.记录的基本概念
--数据类型
--列的定义:表名.列名%type
--行的定义:表%rowtype
select * from emp;
declare
v_ename emp.ename%type;
--表示变量v_ename的类型与表emp中的ename列的类型一致
v_sal emp.sal%type;
--表示变量v_sal的类型与表emp中的sal列的类型一致
v_emp emp%rowtype;
--表示变量v_emp记录的是一行数据,其类型与emp表中定义的数据类型一致
begin
--为指定变量赋值
select ename,sal into v_ename,v_sal from emp where empno = 7369;
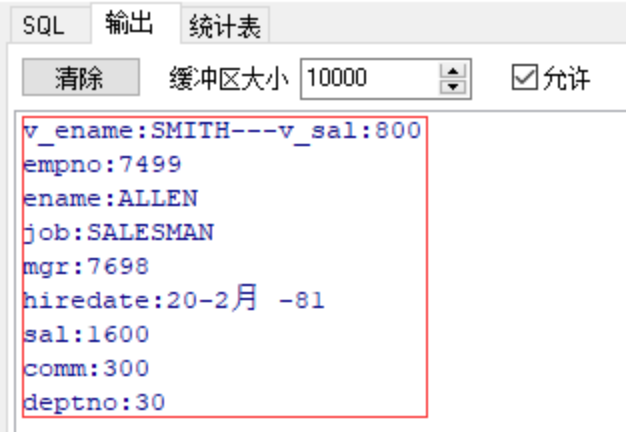
dbms_output.put_line('v_ename:'||v_ename||'---v_sal:'||v_sal);
--一行数据赋值,一一将数据打印
select * into v_emp from emp where empno = 7499;
dbms_output.put_line('empno:'||v_emp.empno);
dbms_output.put_line('ename:'||v_emp.ename);
dbms_output.put_line('job:'||v_emp.job);
dbms_output.put_line('mgr:'||v_emp.mgr);
dbms_output.put_line('hiredate:'||v_emp.hiredate);
dbms_output.put_line('sal:'||v_emp.sal);
dbms_output.put_line('comm:'||v_emp.comm);
dbms_output.put_line('deptno:'||v_emp.deptno);
end;
一一输出结果显示
创建记录
显式定义记录是在PL/SQL 程序块中创建记录变量之前在声明部分定义。使用type 命令定义记录,然后在创建该记录的变量。
语法如下
TYPE record_type IS RECORD (field_definition_list);
field_definition_list 是由逗号分隔的列表
用法:
type myname is record(
varname1 type,
varname2 type,
…
);
使用记录
用户可以给记录赋值、将值传递给其他程序。记录作为一种复合数据结构意味作他有两个层次可用。用户可以引用整个记录,使用select into 或 fetch 转移所有域,也可以将整个记录传递给一个程序或将所有域的值赋给另一个记录。在更低的层次,用户可以处理记录内单独的域,用户可以给单独的域赋值或者在单独的域上运行布尔表达式,也可以将一个或更多的域传递给另一个程序
--2.创建记录
/*
步骤:
a.定义记录
b.声明记录
c.将查询到的数据插入到记录表中
d.查询记录表中的数据
*/
declare
--a.定义记录
type emp_record is record(
v_empno emp.empno%type,
v_ename emp.ename%type,
v_sal emp.sal%type
);
--b.声明记录
r emp_record;
begin
--c.将查询到的数据插入到记录表中
select empno,ename,sal into r from emp where empno = 7369;
--d.查询记录表中的数据信息
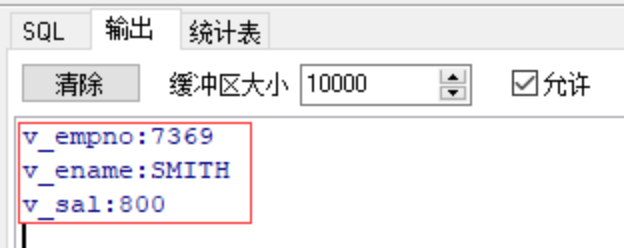
dbms_output.put_line('v_empno:'||r.v_empno);
dbms_output.put_line('v_ename:'||r.v_ename);
dbms_output.put_line('v_sal:'||r.v_sal);
end;
嵌套记录
--3.嵌套记录
--在记录中引用到其他的记录
declare
--定义两个记录
type record1 is record(
v_empno emp.empno%type,
v_ename emp.ename%type,
v_sal emp.sal%type
);
--在record2中引用到记录record1
type record2 is record(
v1 number(2),
v2 varchar2(10),
v3 record1
);
--声明两个记录
r1 record1;
r2 record2;
begin
--将数据插入到记录表中
select empno,ename,sal into r1 from emp where empno = 7369;
r2.v1 := 1;
r2.v2 := 'hello';
r2.v3 := r1;
--输出记录表中的数据
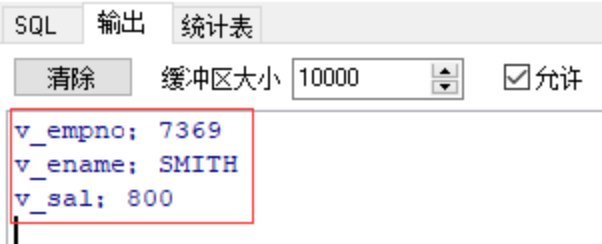
dbms_output.put_line('v_empno;'||r2.v3.v_empno);
dbms_output.put_line('v_ename;'||r2.v3.v_ename);
dbms_output.put_line('v_sal;'||r2.v3.v_sal);
end;
【2】集合
PL/SQL 有三种类型的集合
| 集合类型 | 说明 |
|---|---|
| Index_by 表 | 索引表 |
| nested table | 嵌套表 |
| VARRAY | 数组 |
这三种类型的集合之间有许多差异,包括数据绑定、稀疏性(sparsity)、数据库中的存储能力都不相同
三者之间的区别:
绑定涉及到集合中元素数量的限制,VARRAY 集合中的元素的数量是有限,索引表和嵌套表则是没有限制的。
稀疏性描述了集合的下标是否有间隔,索引表总是稀疏的,如果元素被删除了嵌套表可以是稀疏的,但VARRAY 类型的集合则是紧密的,它的下标之间没有间隔。
数据库中的存储能力索引表不能存储在数据库中,但嵌套表和VARRAY 可以被存储在数据库中
虽然这三种类型的集合有很多不同之处,但他们也由很多相似的地方:
都是一维的类似数组的结构
都有内建的方法
索引表
定义索引表:
type 索引表名称 is table of 索引表类型 [not null] index by 检索类型 ;
声明索引表:
实际索引表名称 索引表名称 ;
type type_name is table of element_type [not null]
index by element_type;
table_name type_name;
注意:需要两个步骤声明索引表。首先使用TYPE语句声明表结构,其中type_name是使用类型的名称,用于声明一个实际的表,element_type是PLSQL中任何合法的PL/SQL数据类型,如number ,varchar2或者date等。其他的集合类型对数据库的数据类型都有限制,但Index_by表不能存储在数据库中,所以没有这些限制
--1.索引表
/*
操作步骤:
a.定义一个索引表,指定索引表的数据类型以及检索类型
b.声明索引表
c.向索引表中插入数据
d.从索引表中取出数据
*/
--案例1
declare
--定义一个索引表,索引表的数据类型为number
type num_table is table of number index by binary_integer;
--声明索引表
a num_table;
begin
--向索引表中插入数据
for i in 1..10
loop
a(i) := i;
end loop;
--从索引表中取出数据
--根据索引取出数据
for i in 1..10
loop
dbms_output.put_line(a(i));
end loop;
end;
--案例2
declare
--定义一个索引表,索引表存储的数据类型为varchar2类型
type var_table is table of varchar(30) index by varchar2(10);
--声明索引表
a var_table;
begin
--向索引表中插入数据
a('guangzhou') := 'guangdong';
a('hangzhou') := 'zhejiang';
a('jinan') := 'shandong';
a('guilin') := 'guangxi';
--根据指定的索引,从索引表中取出数据
dbms_output.put_line(a('guangzhou'));
dbms_output.put_line(a('hangzhou'));
dbms_output.put_line(a('jinan'));
dbms_output.put_line(a('guilin'));
end;
--案例3
declare
--定义索引表,索引表的数据类型与emp的一致
type emp_table is table of emp%rowtype index by binary_integer;
--声明索引表
e emp_table;
begin
--向索引表中插入数据
--bulk collect批量操作,将emp中所有的数据批量插入到emp_table索引表中
select * bulk collect into e from emp where empno = 7369;
--从索引表中取出数据
for i in e.first..e.last
loop
dbms_output.put_line(e(i).ename||'--'||e(i).job);
end loop;
end;
嵌套表
嵌套表非常类似于索引表,创建的语法也非常相似。使用TYPE 语句,只是没有INDEX BY BINARY_INTEGER 子串
定义嵌套表结构:
type 嵌套表名称 is table of 嵌套表类型 [not null] ;
声明嵌套表:
嵌套表实体名称 嵌套表名称 ;
type type_name is table of element_type [not null];
table_name type_name;
嵌套表和VARRAY 都能作为列存储在数据库表中,所以集合自身而不是单个的元素可以为NULL,ORACLE 称这种整个集合为NULL 的为"自动设置为NULL(atomically NULL)"以区别元素为NULL 的情况。当集合为NULL 时,即使不会产生异常,用户也不能引用集合中的元素。用户可以使用IS NULL 操作符检测集合是否为NULL。
存储在一个数据库中的嵌套表并不与表中的其它数据存放在同一个数据块中,它们实际上被存放在第二个表中。正如没有order by 子句select 语句不能保证返回任何有顺序的数据,从数据库中取回的嵌套表也不保证元素的顺序。由于集合数据是离线存储的,对于大型集合嵌套表是一个不错的选择
--2.嵌套表
declare
--定义一个嵌套表 存储的数据类型和emp表中的sal的数据类型一致
type vsal_table is table of emp.sal%type;
--声明嵌套表
a vsal_table;
begin
a:=vsal_table(1000,111,3456,1237);
dbms_output.put_line(a(3)); --按照索引的位置进行取值
end;
--定义一个嵌套表 用来存储用户的姓名
create type stu_name is table of varchar(30);
create table stu(
sid number(10) primary key,
sage number(4),
sname stu_name
)nested table sname store as stu_name_table;
select * from stu;
insert into stu values (1,33,stu_name('三丰','张'));
数组


--3.数组
declare
--定义一个数组 存储的数据类型是emp表中的ename的类型 并且容量是4
type v_ename is varray(4) of emp.ename%type;
--声明 数组
v1 v_ename:=v_ename('guigu','zhangsan','lisi','wangwu');
begin
--改变数组中现有的值
select ename into v1(3) from emp where empno=7369;
dbms_output.put_line(v1(3));
end;
【3】批量SQL

forall语句



--批量sql操作
--批量处理SQL 提升效率
create table teacher(
tid number(20) primary key,
tname varchar2(30)
)
--利用索引表 向teacher表中插入10万条数据
--普通的方式进行插入
declare
--定义两个索引表 分别用于存储tid和 tname
type id_table_type is table of number(20) index by binary_integer;
type name_table_type is table of varchar2(30) index by binary_integer;
--声明索引表
id_table id_table_type;
name_table name_table_type;
--定义两个变量用于记录时间
start_time number(10);
end_time number(10);
begin
for i in 1..100000 loop
--对索引表完成赋值
id_table(i):=i;
name_table(i):='guigu_'||to_char(i);
end loop;
--记录开始插入teacher表之间的时间
start_time:=dbms_utility.get_time;
--把索引表的数据 直接插入到teacher表中
for i in 1..id_table.count loop
insert into teacher values(id_table(i),name_table(i));
end loop;
--记录插入数据完成后的时间
end_time:=dbms_utility.get_time;
--计算插入十万条数据总的耗时时间、
dbms_output.put_line(to_char(end_time-start_time)/100);
end;
-- 5.13
select * from teacher where tid>99999
--可以使用forall 批量处理提升效率
declare
--定义两个索引表 分别用于存储tid和 tname
type id_table_type is table of number(20) index by binary_integer;
type name_table_type is table of varchar2(30) index by binary_integer;
--声明索引表
id_table id_table_type;
name_table name_table_type;
--定义两个变量用于记录时间
start_time number(10);
end_time number(10);
begin
for i in 1..100000 loop
--对索引表完成赋值
id_table(i):=i;
name_table(i):='guigu_'||to_char(i);
end loop;
--记录开始插入teacher表之间的时间
start_time:=dbms_utility.get_time;
--把索引表的数据 直接插入到teacher表中
forall i in 1..id_table.count
insert into teacher values(id_table(i),name_table(i));
--记录插入数据完成后的时间
end_time:=dbms_utility.get_time;
--计算插入十万条数据总的耗时时间、
dbms_output.put_line(to_char(end_time-start_time)/100);
end;
--0.25
drop table teacher;
instance of 子句
在forall 语句上可以跳空值
-- indices of子句 forall效率比较高
declare
type id_table_type is table of number(6);
id_table id_table_type;
begin
--对嵌套表完成赋值
id_table:=id_table_type(1,null,3,null,5,null,9,6,null);
forall i in indices of id_table --这里使用的 indices of 可以忽略其中涉及到的空值 提升效率
delete from teacher where tid =id_table(i);
end;
select * from teacher where tid=1
Bulk collect子句
Bulk collect子句
bulk collect 子句用于取得批量数据,它只适用于select into语句,fetch into语句,和dml返回子句。通过使用该子句,可以将批量数据存放到plsql集合变量中。
语法:
… bulk collect into collection_name
在select into语句中使用bulk collect子句
-- Bulk collect子句 批量处理
declare
--定义一个索引表 其中存储的数据类型是emp对象
type emp_table_type is table of emp%rowtype index by binary_integer;
--声明索引表
emp_table emp_table_type;
begin
select * bulk collect into emp_table from emp;--批量操作
--测试索引表中是否存在数据
for i in 1..emp_table.count loop
dbms_output.put_line(emp_table(i).ename);
end loop;
end;
3.子程序

【1】存储过程

语法:
create or replace procedure proc_name
arg1 mode datatype,
arg2 mode datatype
is/as
pl/sql
存储过程中定义的形式参数,不能指定长度,否则报错
plsql中declare中的部分必须制定长度,否则报错
不带参数的存储过程
--1.不带参数的存储过程
--输入系统时间
create or replace procedure printTime
is
begin
dbms_output.put_line(systimestamp); --获取当前系统的具体时间
end;
--调用存储过程
call printTime();
带输入参数
create or replace procedure p1(
--定义参数
a in number,
b in varchar2
)
is
begin
dbms_output.put_line(a);
dbms_output.put_line(b);
end;
--调用上述带有两个输入参数的存储过程
call p1(18,'noob');
带有输出参数
create or replace procedure p2(
--定义参数
x in number,
y in number,
z out number
)
as
begin
z:=x+y;
end;
--可通过cmd窗口进行操作,调用存储过程,查看输出结果
var result number;
exec 存储过程名称(参数1,参数2....,:返回结果);
print result;(打印运行结果)
带有in、out的参数
定义一个参数即可以是输入参数 也可以是输出参数
--4.带有in out的参数
create or replace procedure test3(
a in out number,
b in out number-- a和b变量即可以看做输入参数 也可以看做输出参数
)
as
begin
dbms_output.put_line(a); --- 这里a作为输入参数
dbms_output.put_line(b);--这里b作为输入参数
a:=200; --这里的a是输出参数
b:=30; --这里的b也是输出参数
end;
--------------------------------------------------------------------
declare
s1 number:=20;
s2 number:=31;
begin
test3(s1,s2);
dbms_output.put_line(s1);
dbms_output.put_line(s2);
end;
组合应用
--5.组合应用
create or replace procedure test4(
v1 in varchar2,
v2 out number
)
is
--声明变量
vsal number;
begin
--根据输入参数 获取指定用户的工资插入到vsal中
select sal into vsal from emp where ename=v1;
if vsal>2000 then
v2:=30000;
else
v2:=10;
end if;
end;
declare
v1 varchar2(10):='KING';
v2 number;
begin
test4(v1,v2);
dbms_output.put_line(v2);
end;
--一般存储过程是用于执行特定的操作 比如插入员工数据、比如定时任务、都可以使用存储过程实现
查看过程源码

【2】函数
函数用于返回特定的值

不带参数
--1.不带参数
--用于执行特定的代码 并且返回特定的数据
create or replace function f1
return varchar2
is
v_ename varchar(50);
begin
select ename into v_ename from emp where empno=7369;
return v_ename;
end;
select f1 from dual;
带有in参数
--2.带有in参数
--给定一个用户的姓名返回这个人的工资
create or replace function get_sal(
v_ename in varchar2
)
return number
is
v_sal emp.sal%type;
begin
select sal into v_sal from emp where upper(ename)=upper(v_ename) ;
return v_sal;
end;
select get_sal('KING') from dual
带有out参数
--3.带有out参数
--根据姓名查询这个人部门所在的名称 和工作职位
create or replace function get_info(
e_name varchar2,
e_job out varchar2
)
return varchar2
as
deptname dept.dname%type;
begin
select a.job, b.dname into e_job,deptname from emp a,dept b where a.deptno=b.deptno and upper(a.ename)=upper(e_name);
return deptname;
end;
declare
e_job varchar2(20);
result varchar2(20);
begin
result:=get_info('smith',e_job);
dbms_output.put_line(e_job);
dbms_output.put_line(result);
end;
select * from emp where empno=7369
带有in、out参数
--4.带有in out参数
create or replace function f2(
num1 number,
num2 in out number
)
return number
as
v_result number(6);
begin
v_result:= num1/num2 ; --num1 num2是输入参数
num2:=mod(num1,num2); --第一个num2输出参数 第二个num2就是输入参数
return v_result;
end;
declare
res number;
nu number:=5;
begin
res:= f2(100,nu);
dbms_output.put_line(res);
dbms_output.put_line(nu);
end;
【3】包
包是一种将过程、函数和数据结构捆绑在一起的容器;包由两个部分组成:外部可视包规范,包括函数头,过程头,和外部可视数据结构;另一部分是包主体(package body),包
主体包含了所有被捆绑的过程和函数的声明、执行、异常处理部分。
打包的PL/SQL 程序和没有打包的有很大的差异,包数据在用户的整个会话期间都一直存在,当用户获得包的执行授权时,就等于获得包规范中的所有程序和数据结构的权限。但不能只对包中的某一个函数或过程进行授权。包可以重载过程和函数,在包内可以用同一个名字声明多个程序,在运行时根据参数的数目和数据类型调用正确的程序。

包
包头 包规范 类似于java中的接口
包体 包实现 类似于java中的实现类
在包头定义的方法,必须在包体中实现
包体中可以有自己的方法,也就是说在包头中未定义过,但是这些方法只能内部使用。
创建包必须首先创建包规范,创建包规范的语法如下:
CREATE [OR REPLACE] PACKAGE package_name
{AS|IS}
public_variable_declarations |
public_type_declarations |
public_exception_declarations |
public_cursor_declarations |
function_declarations |
procedure_specifications
END [package_name]
创建包主体使用CREATE PACKAGE BODY 语句:
CREATE [OR REPLACE] PACKAGE BODY package_name
{AS|IS}
private_variable_declarations |
private_type_declarations |
private_exception_declarations |
private_cursor_declarations |
function_declarations |
procedure_specifications
END [package_name]
私有数据结构是那些在包主体内部,对被调用程序而言是不可见的
建立包规范:包规范就是包与应用程序之间的接口,用于定义包的共用组件,例如:常量 变量 游标 过程 函数等
建立包规范的时候,需要注意,为了实现信息隐藏,不应将所有组件全部放在包规范定义,而应该只定义共用组件
语法:
create or replace package_name
AS|IS
public type and item declarations
subprogram specifications End package_name;
--定义包体
public interface UserDAO{
int did =30;
public void add_employee(int eno, String ename,int salary, int dno);
public int get_sal(int eno);
}
public class UserDAOImpl(){
public boolean validata_deptno(int deptno){
}
public void add_employee(int eno, String ename,int salary, int dno){
}
public int get_sal(int eno){
}
}
--定义包规范
create or replace package emp_package
is
--定义全局变量
g_deptno number(4):=30;
--定义存储过程 声明
procedure add_employee(eno number, ename varchar2,salary number, dno number default g_deptno);
--定义函数 声明
function get_sal(eno number) return number;
end emp_package ;
--创建包的实现
create or replace package body emp_package
is
--在包体中定义的函数的声明
--这个函数的作用是 根据用户传递的 deptno判断部门是否存在
function validata_deptno(v_deptno number) return boolean
is
v_temp int;
begin
select 1 into v_temp from dept where deptno=v_deptno;
return true;
exception
when no_data_found then
return false;
end;
--实现包头中定义的所有的存储过程和函数
procedure add_employee(eno number, ename varchar2,salary number, dno number default g_deptno)
is
begin
if validata_deptno(dno) then
insert into myemp(empno,ename,sal,deptno) values(eno,ename,salary,dno);
else
raise_application_error(-20001,'不存在该部门');
end if;
end;
function get_sal(eno number) return number
is
v_sal myemp.sal%type;
begin
select sal into v_sal from myemp where empno=eno;
return v_sal;
exception
when no_data_found then
raise_application_error(-20002,'该员工不存在');
end;
end emp_package ;
--根据员工编号 查询工资 传递数据 直接保存员工信息
select * from myemp;
select emp_package.get_sal(7499) from dual;
declare
begin
emp_package.add_employee(1,'归谷',66666,30);
end;
通过函数和存储过程,实现员工的增删改查以及多表的增删改变
4.触发器

触发器是存放在数据库中,并被隐含执行的存储过程。
DML触发器 、INSTEAD OF 触发器
授予创建触发器的权限:grant create any trigger to user_name;
授予管理数据库触发器的权限grant administer database trigger to user_name;
【1】DML触发器
基础概念
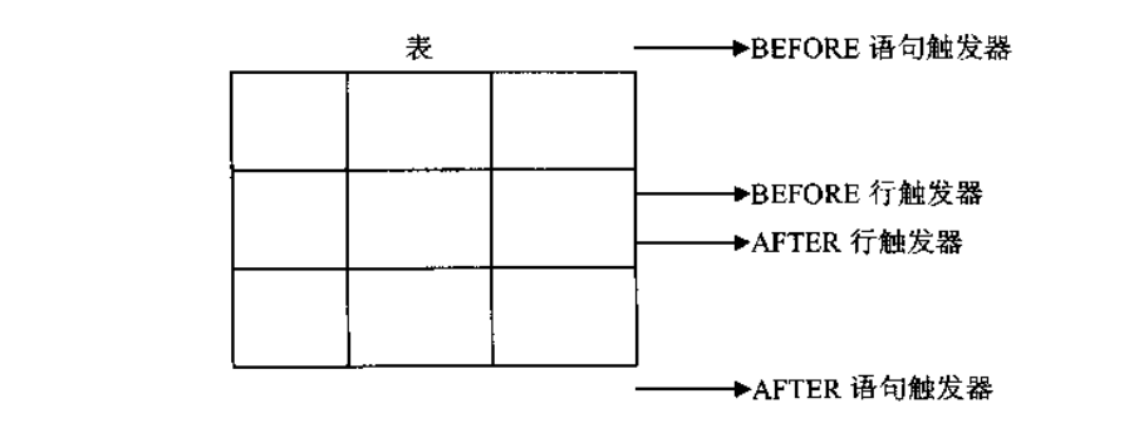
当发生特定的事件时,oracle会自动执行触发器相应的代码,触发器由触发事件、触发条件、触发操作组成



触发顺序:
触发器代码只能包含DML和select语句,不能包含ddl和事务控制语句。
建立触发器
create or replace trigger name
timing event1 or event2 or event3
on table_name
plsql block
timing 是出发时机,before或after
event 是出发事件 insert update delete
【2】语句触发器
-- 触发器
--先创建自己的表格进行操作myemp,数据来源于emp
create table myemp
as
select *
from emp;
select * from myemp;
/*
触发器操作
a.语句触发器:针对的是整张表的操作
before语句触发器
after语句触发器
b.行触发器:针对的是指定某一行数据
before行触发器
after行触发器
*/
before语句触发器

/*
1.before语句触发器简单示例
before语句触发器指的是在对某张表进行相关操作之前进行拦截
用法:
create or replace trigger 触发器名称
before 操作1 or 操作2 ... on 表名
begin
--抛出相应的数据库异常提示
raise_application_error(错误代码,'异常提示');
--错误代码格式为-xxxxx 5位数字
--异常提示为自行指定的相应的数据提示
end;
*/
--禁止用户对myemp进行除查询之外的操作
create or replace trigger tr_seq_myemp
before insert or update or delete on myemp
begin
raise_application_error(-20001,'员工表不允许修改');
end;
--测试对myemp的增删改查
select * from myemp;
insert into myemp(empno,ename,sal) values(1001,'noob',10000);
delete from myemp where empno = 7369;
update myemp set sal=sal+200 where empno = 7499;
使用条件谓词

--结合条件谓词的使用
create or replace trigger tr_seq_myemp
before insert or update or delete on myemp
begin
case when inserting then
raise_application_error(-20001,'员工表不允许增加数据');
when updating then
raise_application_error(-20002,'员工表不允许修改数据');
when deleting then
raise_application_error(-20003,'员工表不允许删除数据');
end case;
end;
--测试对myemp的增删改查
select * from myemp;
insert into myemp(empno,ename,sal) values(1001,'noob',10000);
delete from myemp where empno = 7369;
update myemp set sal=sal+200 where empno = 7499;
--每次测试结束后要删除之前创建的触发器,以免对后续的测试造成影响
after语句触发器


/*
2.after语句触发器
通过after语句触发器记录用户对某张表进行了几次增删改
格式:
a.先创建一个临时表格,用以记录操作信息
create table 表名(
用户名 数据类型,
操作1 数据类型,
操作2 数据类型,
............
开始时间 date,
结束时间 date
);
b.创建after语句触发器用以记录表格内容的变动
create or replace trigger 触发器名称
after 操作1 or 操作2 or ... on 表名
declare
--声明变量
begin
--判断、记录
end;
*/
--a.创建临时表记录表格内容变动信息
create table myemp_change(
username varchar2(30),
insert_num number(10),
delete_num number(10),
update_num number(10),
start_time date,
end_time date
);
--b.创建after语句触发器用以记录表格内容的变动
create or replace trigger tr_seq_myemp
after insert or delete or update on myemp
declare
【3】行触发器
DML操作的时候,每操作一行就一次触发器。
create or replace trigger trigger_name
timing event1 or …
on table_name
referencing old as old | new as new
for each row
when condition
plsql block
timing 是出发时机 before还是after
event 是出发事件 insert update delete
referencing字句用于指定引用新、旧数据的方式,默认使用old引用旧的,new引用新的
for each row 表示行触发器
when是指定出发条件
建立before行触发器

-- 建立 before 行触发器
--要求:员工更新后的工资不能比之前的低
create or replace trigger tr_emp_sal
before update of sal on myemp
for each row --针对表每一行数据、
begin
if :new.sal<:old.sal then --:old 代表之前的数据 :new 代表更新之后的数据
raise_application_error(-20001,'更新后的工资小于原来的工资,禁止更新');
end if;
end;
-- 更新测试
update myemp set sal=sal+200 where empno=7654
select * from myemp
建立after行触发器

-- 建立 after 行触发器
--记录用户改变myemp表中的数据:谁更新的、更新之前的数据和更新之后的数据以及更新的时间
create table audit_table_change(
username varchar2(30),
oldsal number(10),
newsal number(10),
time date
)
create or replace trigger tr_sal_change
after update of sal on myemp
for each row --行触发器 针对每一行数据
declare
v_temp int;
begin
--查询某个用户的更新的数据是否存在
select count(*) into v_temp from audit_table_change where username=:old.ename;
if v_temp =0 then
insert into audit_table_change values(:old.ename,:old.sal,:new.sal,sysdate);
else
update audit_table_change set oldsal=:old.sal,newsal=:new.sal,time=sysdate where username=:old.ename;
end if;
end;
-- 更新测试
update myemp set sal=sal+200 where empno=7521
select * from audit_table_change
select * from myemp
--非工作时间进行修改员工的数据 before语句触发器
create or replace trigger tr_emp_time
before insert or update or delete on myemp
begin
if(to_char(sysdate,'HH24')) not between '09' and '17' then
raise_application_error('-20001','非工作时间进行修改数据');
end if;
end;
-- 更新测试
update myemp set sal=sal+200 where empno=7654