[Oracle基础]-数据库对象
[Oracle基础]-数据库对象
[TOC]
1.视图
【1】视图说明
视图基本概念
视图是一种虚表,只有逻辑定义,从相对概念上理解视图不占用物理空间(视图本身的定义语句还是要存储在数据字典中)
视图是建立在已有表的基础上,视图来源与建立的这些表称为基表(数据库中保存数据的实体)
向视图提供的语句为select语句,可以将视图理解为存储起来的select语句
视图向用户提供基表数据的另一种表现形式
视图的分类
- 关系视图
Oracle视图是作为数据库对象存在的,创建之后也可以通过工具或数据字典来查看视图的相关信息
create view 视图名称 as 查询语句|关系运算
- 内嵌视图
在from语句中,可以表改成一个子查询,如:
select a.id ,b.id from emp a,(select id from dept) b where a.id=b.id
内嵌视图是子查询的一种,可以与数据表、视图一样作为查询语句的数据源存在,但在形式上有较大的区别,内嵌视图不必使用create view命令进行创建,因此,在数据字典中也无法获得相应信息。内嵌视图的特点在于无须创建真正的数据库对象,而只是封装查询,因此会节约数据库资源,同时不会增加维护成本。但是内嵌视图不具有可复用性,因此当预期将在多处调用到同一查询定义时,还是应该使用关系视图。
- 对象视图
对象视图创建之后,同样可以在数据字典中获得其相应信息。利用Oracle内置视图user_views可以获得对象视图相关信息。Oracle中的对象数据实际仍然以关系数据的形式存储。但是,对象的特性,例如继承、封装等,都为开发人员提供了更加灵活的处理形式。同样,可以构造复杂的对象类型来封装复杂的多表查询。
对象类型在数据库编程中有许多好处,但有时,应用程序已经开发完成。为了迎合对象类型而重建数据表是不现实的。对象视图正是解决这一问题的优秀策略。
- 物化视图
常用于数据库的容灾,不是传统意义上虚拟视图,是实体化视图,和表一样可以存储数据、查询数据。主备数据库数据同步通过物化视图实现,主备数据库通过data link连接,在主备数据库物化视图进行数据复制。当主数据库垮掉时,备数据库接管,实现容灾
视图的优点
简化复杂的查询
隐藏数据的逻辑复杂性并简化查询语句
限制数据的访问
通过定义视图控制基表数据的访问,从而简化用户权限管理,限定敏感数据访问权限,提供安全性保证
基表数据的多样化展示
同样的数据,可以有不同的访问方式
注意:
不建议通过视图对表进行修改--->修改视图是修改的基表
视图是不能提高性能的
【2】创建视图
使用下面的语法格式创建视图
create [or replace] [force|noforce] view view_name
[(alias[,alias]...)]
as subquery
[with check option [constraint constraint_name]]
[with read only [constraint constraint_name]];
or replace:如果存在同名的视图, 则使用新视图"替代"已有的视图
force:"强制"创建视图,不考虑基表是否存在,也不考虑是否具有使用基表的权限
noforce:子查询存在(默认)
with check option: 指定对视图执行的dml操作必须满足“视图子查询”的条件,即对通过视图进行的增删改操作进行"检查",要求增删改操作的数据,必须是select查询所能查询到的数据,否则不允许操作并返回错误提示。 默认情况下, 在增删改之前"并不会检查"这些行是否能被select查询检索到
with read only:只能做查询操作
创建视图的步骤
(1)赋予权限
在超级管理员登录状态下完成“创建视图”的权限赋予
--a.赋予权限
/*
赋予权限的步骤:
1.登录到超级管理员状态
会话-->登录-->sys:sys:orcl:sysdba
2.执行命令
grant create any view to user(用户名);
*/
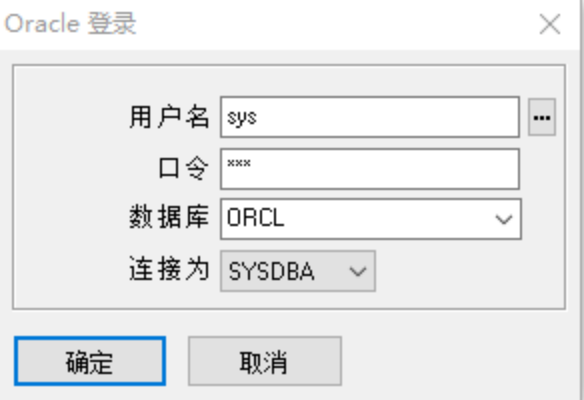
--赋予创建视图的权限给haha用户
grant create any view to haha;
--切回用户haha,完成视图的创建

(2)用相关指令完成视图的创建
--先完成相关表格的创建,插入数据,随后再完成视图的创建
--创建相应的部门表
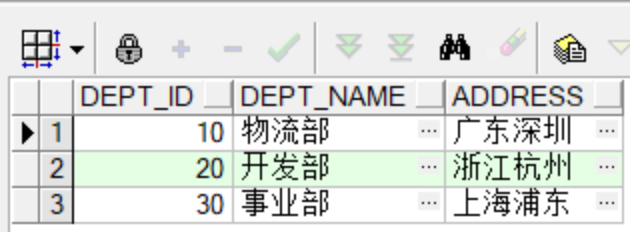
create table departments(
dept_id number(10) primary key,
dept_name varchar2(20) not null,
address varchar2(30)
);
--插入部门信息
insert into departments values(10,'物流部','广东深圳');
insert into departments values(20,'开发部','浙江杭州');
insert into departments values(30,'事业部','上海浦东');
select * from departments;
--创建相应的员工表
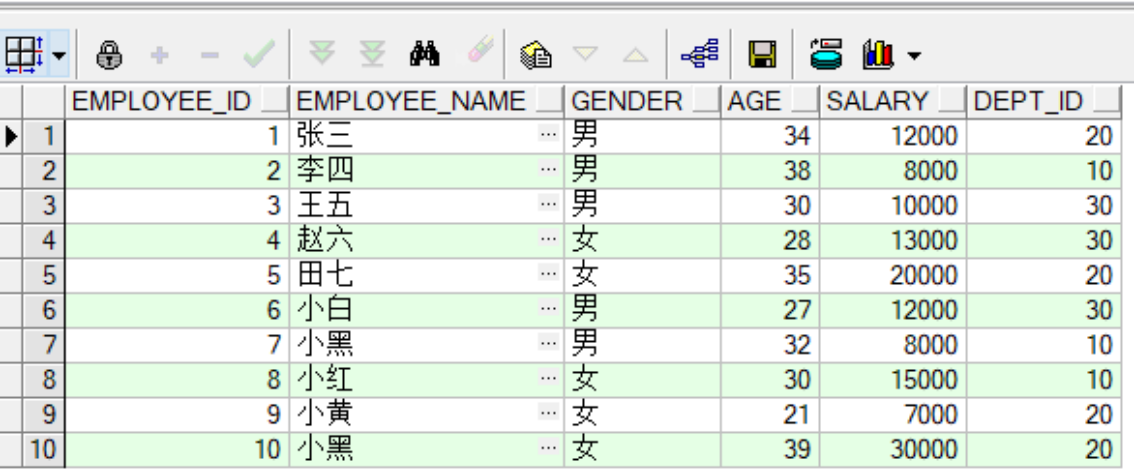
create table employees(
employee_id number(10) primary key,
employee_name varchar2(20) not null,
gender varchar2(4) check(gender='男' or gender='女'),
age number(3) check(age>=0 and age<=150),
salary number(6) not null,
dept_id number(10),
constraint fk_employees_departments foreign key(dept_id) references departments(dept_id)
);
insert into employees values(1,'张三','男',34,12000,20);
insert into employees values(2,'李四','男',38,8000,10);
insert into employees values(3,'王五','男',30,10000,30);
insert into employees values(4,'赵六','女',28,13000,30);
insert into employees values(5,'田七','女',35,20000,20);
insert into employees values(6,'小白','男',27,12000,30);
insert into employees values(7,'小黑','男',32,8000,10);
insert into employees values(8,'小红','女',30,15000,10);
insert into employees values(9,'小黄','女',21,7000,20);
insert into employees values(10,'小黑','女',39,30000,20);
select * from employees;
--b.创建视图
--简单视图的创建
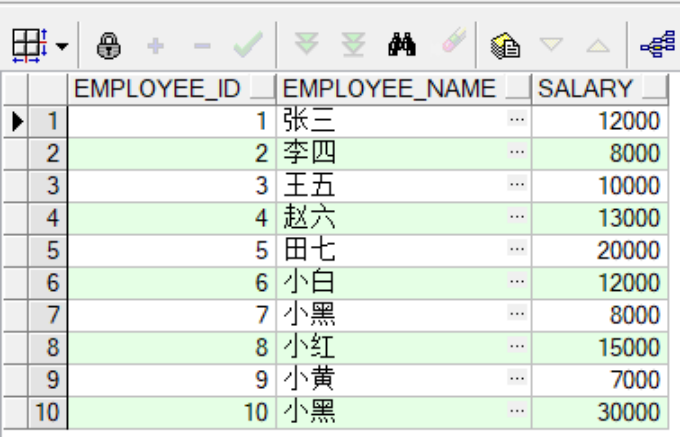
--显示员工的id、姓名、工资
create view employees_view
as
select e.employee_id,e.employee_name,e.salary
from employees e;
--查看创建的视图
select *
from employees_view;
--为了不影响之后的测试,删除创建的视图
drop view employees_view;
---------------------------------------------------------------------
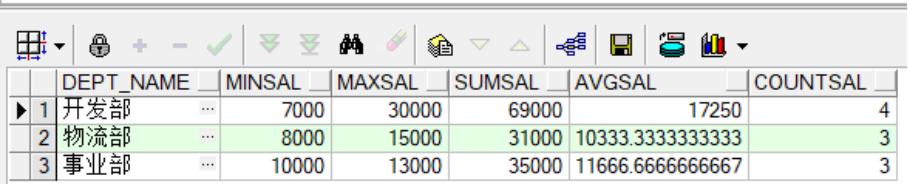
--复杂视图的创建:会使用一个或者多个基表,涉及组函数和分组函数 /*
显示员工的每个部门的部门名称及其最低工资、最高工资、求和、
平均值、统计部门人数,并以工资高低进行排序
*/
create view emp_dept__view(dept_name,minSal,maxSal,sumSal,avgSal,countSal)
as
select d.dept_name,min(e.salary), max(e.salary),
sum(e.salary), avg(e.salary), count(*)
from employees e,departments d
where e.dept_id = d.dept_id
group by d.dept_name
order by min(e.salary);
--查看创建的视图
select *
from emp_dept_view;
【3】查询视图
--查询视图
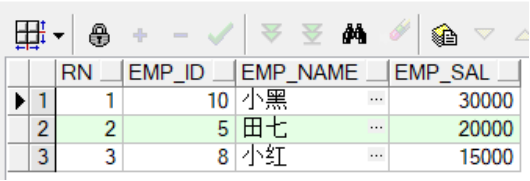
--获取权限、创建视图
--将employees工资最高的三个员工信息抽离出来
create view emp_maxsal_view(rn,emp_id,emp_name,emp_sal)
as
select rownum,a.employee_id,a.employee_name,a.sal
from (select e.employee_id,e.employee_name,e.salary sal
from employees e
order by e.salary desc)a
where rownum<=3;
--查看视图
--查看指定的视图:
select * from emp_maxsal_view;
--查看当前用户所拥有的全部视图:使用数据字典查询user_views
select *
from user_views;

【4】修改视图
--修改视图
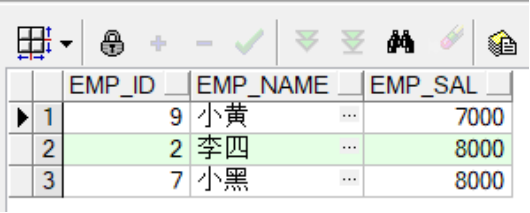
--1.修改显示的信息(调整select语句)
--在之前的基础上将employees工资最低的三个员工信息抽离出来
create or replace view emp_maxsal_view(emp_id,emp_name,emp_sal)
as
select a.employee_id,a.employee_name,a.sal
from (select e.employee_id,e.employee_name,e.salary sal
from employees e
order by e.salary)a
where rownum<=3;
--查看修改后的视图,显示出相应的信息
select *
from emp_maxsal_view;
--2.更新视图的内容(不推荐使用)
/*
更新格式:update 视图名称
set 列名 = value
where condiction;
更新视图就是对基表(原表)进行更新,所以不推荐对视图进行任何修改
*/
--a.在之前的基础上,给工资最低的1名员工工资嘉奖500元
update emp_maxsal_view
set emp_sal = emp_sal + 500
where rownum = 1;
/*
结果显示出错:ORA-01732:此视图的数据操作操纵非法
原因在于视图的更新只能是基于简单视图进行操作,
对于数据更新还要有限制,由于在创建emp_maxsal_view视图
的时候使用了order by子句,因此视图无法进行更新
*/
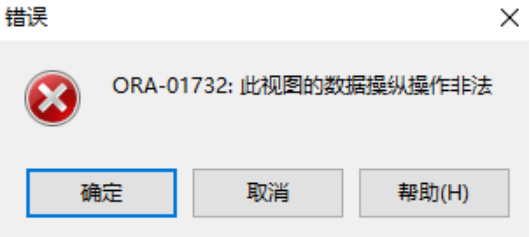
--b.创建普通视图进行测试
--显示employee_id小于等于5的员工信息
create view emp_view(eid,ename,salary)
as
select e.employee_id,e.employee_name,e.salary
from employees e
where employee_id<=5;
--查看创建的视图信息
select *
from emp_view;
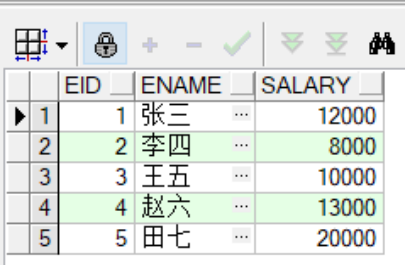
--通过视图对原表employees进行更新
--将id小于等于5的所有员工工资+500
update emp_view
set salary = salary+500;
--查看修改后的视图信息
select *
from emp_view;
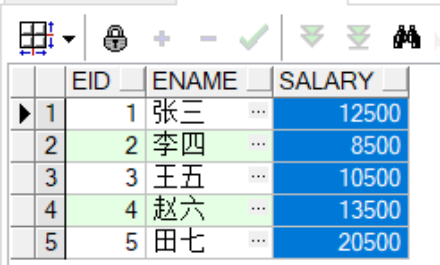
--查看修改后的基表内容
select *
from employees;
视图中使用DML的规定
可以在简单的视图中执行DML操作
当视图定义了以下元素不能使用delete
组函数
Group by 子句
Distinct关键字
Rownum伪列
当视图定义了以下元素不能使用update
组函数
Group by
Distinct关键字
Rownum伪列
列的定义为表达式
当视图定义了以下元素不能使用insert
组函数
Group by子句
Distinct关键字
Rownum伪列
列的定义为表达式
表中非空列在视图中未包含
屏蔽DML操作
可以使用
read-only选择对视图进屏蔽,只允许读操作,其他的不能执行任何DML操作都会返回一个错误
--屏蔽DML操作,设置只读属性
create or replace view my_view
as
select e.employee_id,e.employee_name,e.salary
from employees e
with read only; --设置视图只读
--尝试更新视图的内容:会报错
update my_view
set salary = 0 ;
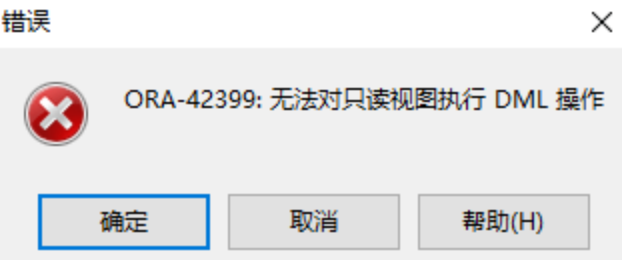
【5】删除视图
--删除视图
/*
删除视图格式:
drop view 视图名称
drop view view_name
*/
drop view employees_view;
drop view emp_dept_view;
drop view emp_maxsal_view;
drop view emp_view;
drop view my_view;
2.序列
【1】序列的概念
序列:可以提供多个用户产生唯一数值的数据库对象
自动提供唯一的数值
共享对象
主要提供主键的值
将序列装入内存中提高访问效率
【2】创建序列
序列的创建
--a.创建序列:CREATE SEQUENCE 语句
create sequence myseq
increment by 1 -- 每次递增的数值
start with 1 --- 序列的初始值
maxvalue 999999 -- 指定序列的最大值
nocache --不缓存
nocycle --不循环
--dual万能表
select myseq.nextval from dual;
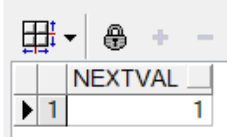
NEXTVAL和CURRVAL伪列
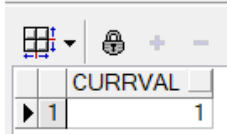
--b.nextval与currval
--nextval 是当前值的下一个值
--currval 是当前的值
select myseq.currval from dual;
select myseq.nextval from dual;
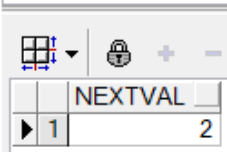
序列应用举例
--序列的使用举例分析
--创建学生序列stu_seq
create sequence stu_seq
increment by 1 -- 每次递增的数值
start with 20180001 --- 序列的初始值
maxvalue 99999999 -- 指定序列的最大值
nocache --不缓存
nocycle --不循环
--序列一般作为主键使用,实现主键递增
--a.创建student表进行测试
create table student(
sid number(10) primary key,
sname varchar2(20) not null,
sage number(3) check(sage>=0 and sage<=150)
);
select * from student;
--b.插入数据进行测试
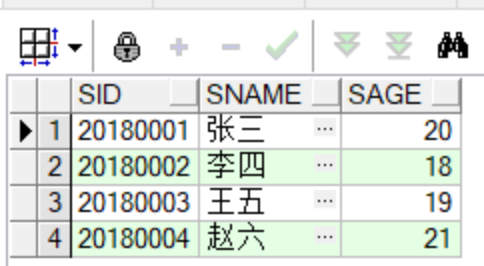
insert into student values(stu_seq.nextval,'张三',20);
insert into student values(stu_seq.nextval,'李四',18);
insert into student values(stu_seq.nextval,'王五',19);
insert into student values(stu_seq.nextval,'赵六',21);
select *from student;
--清除数据信息
drop sequence stu_seq;
truncate table student;
【3】使用序列
将序列装入内存中可以提高访问效率
序列在下列情况会出现裂缝
回滚
系统异常
多个表共用一个序列
【4】修改序列
--修改序列
/*
序列一经定义便不能修改其初始值,修改序列只能修改最大值、最小值、循环项、
是否装入内存 但是无法修改初始值。
nocache 如果要缓存是在内存中提前生成一定数量的数据,使用的时候直接从
内存中取出,如果不缓存是指不会提前把生产的数据放入到内存中,而是在使
用的时候在生成唯一的数据
*/
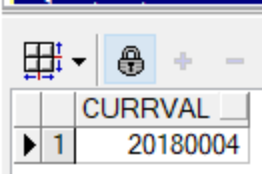
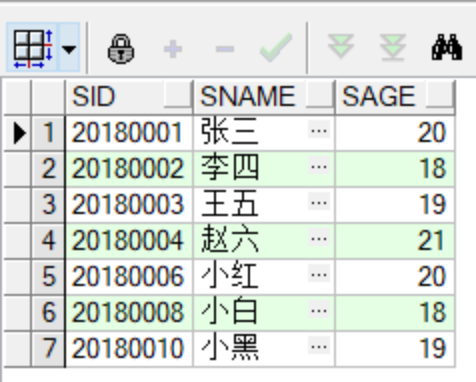
--修改上述创建的stu_seq序列,每次递增2,最大值为20180010
alter sequence stu_seq
increment by 2 -- 每次递增的数值
maxvalue 20180010-- 指定序列的最大值
nocache --不缓存
nocycle --不循环
--打印当前的序列号
select stu_seq.currval from dual;
--在student表中插入数据进行测试
--三条数据插入正常
insert into student values(stu_seq.nextval,'小红',20);
insert into student values(stu_seq.nextval,'小白',18);
insert into student values(stu_seq.nextval,'小黑',19);
--打印当前的序列号
select stu_seq.currval from dual;
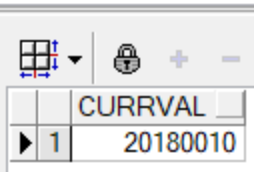
--在插入第4条数据的时候预测sid为20180012,超出序列定义的最大值,无法执行操作
insert into student values(stu_seq.nextval,'小黄',21);
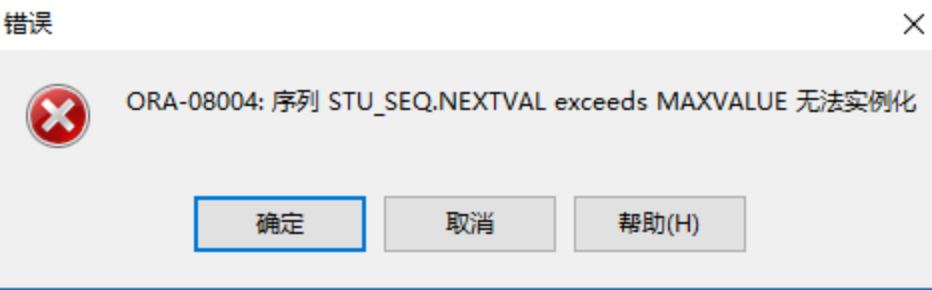
--输出最终存储的学生信息
select * from student;
【5】删除序列
--删除序列
/*
删除格式:
drop sequence 序列名称
*/
drop sequence myseq;
drop sequence stu_seq;
3.索引
【1】索引说明
索引是用来提高查询效率的数据库对象,使用索引可以快速定位数据,减少磁盘操作
一种独立于表模式的对象,可以存储在于表不同的磁盘表空间
索引被删除或者被破坏不会对表产生影响,只会影响查询速度
索引一旦创建完毕,oracle管理系统会对其自动维护,而且oracle管理系统决定何时使用什么索引,用户不需要在查询语句中指定使用哪个索引
在删除一个表的时候所有基于该表的索引都会被自动删除
通过指针加速oracle 服务器的查询速度
通过快速定位的方法检索磁盘I/O
索引分类
唯一性索引和非唯一性索引
按照索引字段是否允许出现重复进行划分
单字段索引和联合索引
按照字段基于索引的数目进行划分
普通索引和函数索引
按照索引锁基于的是普通字段还是复合表达式进行划分
B树索引和位图索引(Bitmap)
按照索引的数据结构进行划分
【2】创建索引
自动创建
在建表、创建约束的时候,primary key 和unique约束在创建的时候自动创建唯一性索引
手动创建
用户可以在其他列上创建非唯一性索引,加速查询
--索引的创建
--创建表格进行测试:创建teacher表
create table teacher(
tid number(10) primary key,
tname varchar2(20) not null,
descr varchar2(30),
address varchar2(50)
);
--插入数据进行测试
insert into teacher values(1,'张三','我是张三','浙江杭州');
insert into teacher values(2,'李四','我是李四','浙江温州');
insert into teacher values(3,'王五','我是王五','浙江台州');
insert into teacher values(4,'赵六','我是赵六','广东深圳');
select * from teacher;
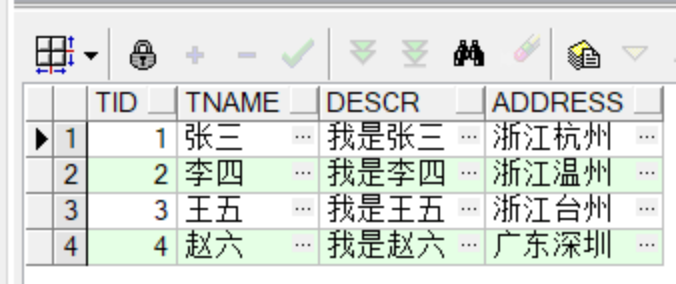
--删除数据
drop table teacher;
/*
创建索引的目的是加快查询速度,减少磁盘的操作
只需要创建相应的索引即可,系统会自行管理、调用相应的索引
*/
/*
1.创建普通索引:
create index 索引名称
on 表名(列名);
*/
--创建基于tname
create index teacher_tname_index
on teacher(tname);
/*
2.创建联合索引:
create index 索引名称
on 表名(列名1,列名2...);
*/
--创建基于tid和tname的联合索引
create index teacher_tid_tname_index
on teacher(tid,tname);
/*
3.创建唯一性索引
create unique index 索引名称
on 表名(列名);
*/
--创建基于descr唯一性索引
create unique index teacher_descr_index
on teacher(descr);
/*
4.创建位图索引
create bitmap index 索引名称
on 表名(列名);
*/
--4.创建位图索引
create bitmap index teacher_bitmap_index
on teacher(address);
-------------------------------------------------
--查询索引信息:user_indexes、user_ind_columns
--a.查询现有的索引
select *
from user_indexes;
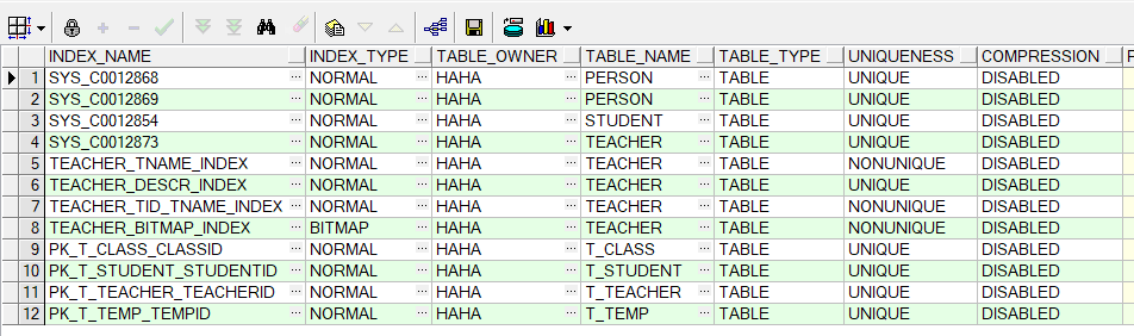
--b.查询索引具体的字段
select *
from user_ind_columns
where table_name='TEACHER';

--创建表的时候系统会根据主键自动生成一个索引
select * from user_ind_columns
where table_name='STUDENT'

案例说明
下列哪些约束会自动创建索引
/*
测试:
下述哪些约束会在创建的时候自动创建索引
a.primary key b.unique
c.not null d.foreign key
e.check
--预测结果:primary key 、 unique
*/
create table person(
pid number(10) primary key,
pname varchar(10) not null,
gender varchar2(4) check(gender='男' or gender='女'),
descr varchar2(30) unique
);
--查询当前的索引
select *
from user_ind_columns
where table_name = 'PERSON';
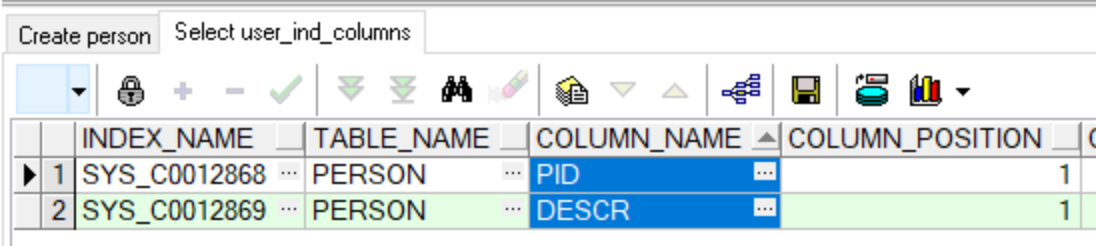
创建索引的时间
并不是索引越多越好根据业务情况确定是否需要索引,然后根据具体情况建立合适的索引
索引的不足之处
创建索引和维护索引要耗费时间,这种时间随着数据量的增加而增加
索引需要占物理空间,除了数据表占数据空间之外,每一个索引还要占一定的物理空间,如果要建立聚簇索引,那么需要的空间就会更大
当对表中的数据进行增加、删除和修改的时候,索引也要动态的维护,这样就降低了数据的维护速度。
什么时候需要创建索引
列中数据分布范围很广,字段中包含大量的空值
列经常在where子句连接条件中出现
表经常被访问数据量很大,访问的量仅占数据量的2%-4%之间
什么时候不需要创建索引
表很小
列不经常作为连接条件,或者出现在where子句中
查询的数据 大于4%
表经常更新(修改性能远远大于检索性能)
限制索引
限制索引是一些没有经验的开发人员经常犯的错误之一,在SQL中有很多陷阱会使一些索引无法使用,下面讨论一些常见的问题:
(1)使用不等于操作符(<>、!=)
下面的查询使得即使在cust_rating列有一个索引,查询语句仍然执行一次全表扫描
select cust_Id,cust_name
from customers
where cust_rating <> 'aa';
把上面的语句改成如下的查询语句,如此一来,在采用基于规则的优化器而不是基于代价的优化器(更智能)时,将会使用索引。(避免使用 !=、<>)
select cust_Id,cust_name
from customers
where cust_rating < 'aa' or cust_rating > 'aa';
特别注意:通过把不等于操作符改成OR条件,就可以使用索引,以避免全表扫描
(2)使用IS NULL 或IS NOT NULL
使用IS NULL 或IS NOT NULL同样会限制索引的使用。因为NULL值并没有被定义,在SQL语句中使用NULL会有很多的麻烦。因此建议开发人员在建表时,把需要索引的列设成 NOT NULL。如果被索引的列在某些行中存在NULL值,就不会使用这个索引(除非索引是一个位图索引)
(3)使用函数
如果不使用基于函数的索引,那么在SQL语句的WHERE子句中对存在索引的列使用函数时,会使优化器忽略掉这些索引。
下面的查询不会使用索引(只要它不是基于函数的索引)
select empno,ename,deptno
from emp
where trunc(hiredate)='01-MAY-81';
把上面的语句改成下面的语句,这样就可以通过索引进行查找
select empno,ename,deptno
from emp
where hiredate<(to_date('01-MAY-81')+0.9999);
(4)使用不匹配的数据类型
比较不匹配的数据类型是比较难于发现的性能问题之一,注意下面查询的例子,account_number是一个VARCHAR2类型,在account_number字段上有索引
下面的语句将执行全表扫描:
select bank_name,address,city,state,zip
from banks
where account_number = 990354;
Oracle可以自动把where子句变成to_number(account_number)=990354,这样就限制了索引的使用,改成下面的查询就可以使用索引:
select bank_name,address,city,state,zip
from banks
where account_number ='990354';
特别注意:不匹配的数据类型之间比较会让Oracle自动限制索引的使用
【3】查询索引
可以使用数据字典视图user_indexs 和user_ind_columns查看索引的信息
【4】删除索引
/*
删除索引
drop index 索引名称
*/
删除一个表,其对应的索引也相应删除
4.同义词
为创建的数据库对象创建一个别名(便于记忆、使用),一个用户要想创建同义词需要获取相应的权限
--同义词创建
/*
a.登录到超级管理员
sys -- sys -- orcl -- sysdba
b.赋予权限
grant create synonym to 用户名;
c.创建同义词
create synonym 别名 for 表名;
*/
grant create synonym to haha;
--权限赋予完毕后切换到普通用户haha
--为表student创建同义词stu
create synonym stu for student;
--通过同义词stu查询信息
select * from stu;
--查看所有的同义词:数据字典dba_synonyms
select *
from user_synonyms;

--删除同义词:drop synonym 同义词名称;
drop synonym stu;