HashMap的底层实现原理
HashMap的底层实现原理
HashMap是Java集合框架中的一个类,它实现了Map接口。JDK1.7中HashMap内部是通过数组+链表实现的,并且可以接受null键和值。在JDK1.8之后,当链表长度超过阈值(默认为8)时,链表将转换为红黑树以提高查询效率(即数组+链表+红黑树)。
以下是HashMap的一些关键属性:
DEFAULT_INITIAL_CAPACITY:默认初始容量,必须是2的幂。MAXIMUM_CAPACITY:最大容量,必须是2的幂,且小于2^30。DEFAULT_LOAD_FACTOR:默认负载因子,用于计算自动扩容的阈值。TREEIFY_THRESHOLD:当链表长度超过这个值会转换为红黑树。UNTREEIFY_THRESHOLD:当红黑树的节点数少于这个值会转换回链表。table:存储数据的数组,每个元素是一个链表的头节点。size:HashMap包含的键值对数量。threshold:扩容的阈值,等于容量乘以负载因子
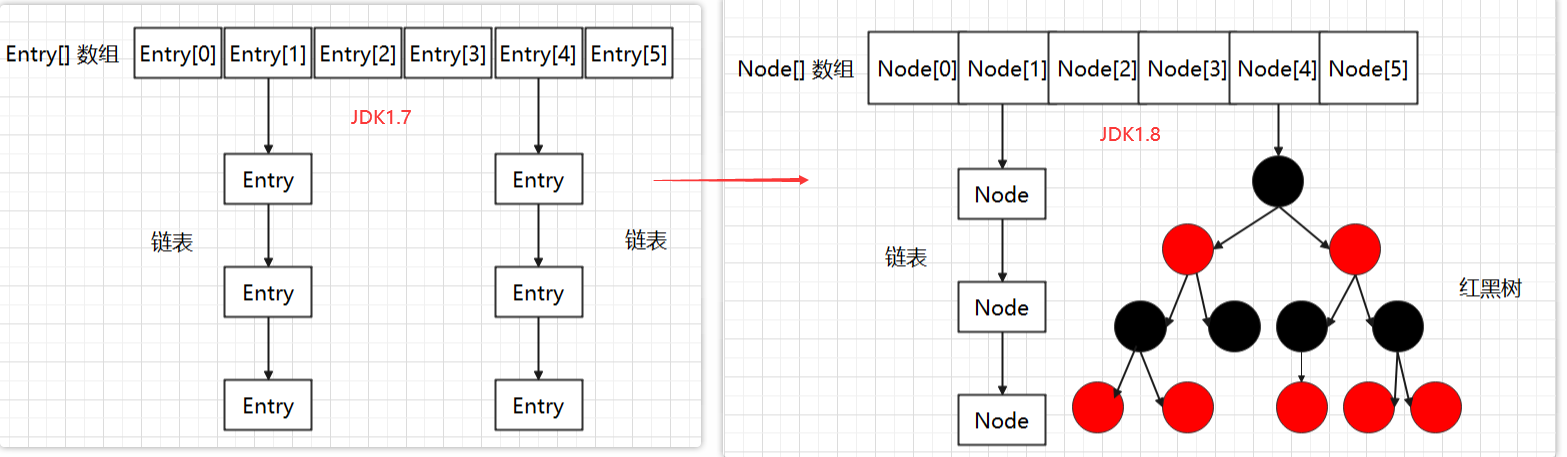
为什么要引入红黑树?
一开始以数组+链表的形式存储,当数据量比较少可通过链表快速定位数据。但是数据量比较大的时候,链表就会越来越长(导致链表后面的数据查找效率就会越来越低)
引入红黑树是为了提高查找效率,当插入链表的元素达到阈值8的时候,会自动将链表转化为红黑树。
结合官方文档说明,如果hashCode 分布良好(hash计算的结果离散好),红黑树这种形式是很少会被用到的,因为各个值都分布均匀,比较少会出现链表非常长的情况(在理想情况下,链表长度符合泊松分布,各个长度的命中概率依次递减,当长度为 8 的时候,概率仅为 0.00000006),一般来说Map不会存储太多的数据,因此比较少情况会出现红黑树转化。
而链表长度超过 8 就转为红黑树的设计,更多的是为了防止用户自己实现了不好的哈希算法时导致链表过长,从而导致查询效率低, 而此时转为红黑树更多的是一种保底策略,用来保证极端情况下查询的效率
红黑树的进化条件
红黑树进化的条件还需考虑数组长度:当链表长度大于阈值8会先判断数组容量(如果小于64则先进行数组扩容),如果数组容量大于64则链表进化为红黑树
为什么要这样设计:在数组比较小时如果出现红黑树结构,反而会降低效率,因为红黑树需要进行左旋右旋,变色这些操作来保持平衡,同时数组长度小于64时,搜索时间相对要快些,所以综上所述为了提高性能和减少搜索时间
HashMap加载因子为什么是 0.75?
HashMap的加载因子表示的是Hash表中元素填满的程度。
加载因子越大,数组空间利用率越高,但hash冲突的机会越大,会导致链表/红黑树的数据越多,当数据查找到这个位桶的时候查找效率较低
加载因子越小,数组空间利用率越低,虽然hash冲突机会较少,提升了查询性能,但是也浪费了空间
因此结合测算,取一个相对平均的数字(折中因子)作为加载因子,当负载因子为 0.75 时代入到泊松分布公式,计算出来长度为 8 时,概率 = 0.00000006,概率很小了,链表长度为 8 时转红黑树
HashMap的默认长度为什么是16?
如果两个元素不相同,但是 hash 函数的值相同,这两个元素就是一个碰撞。为了减少 hash 值的碰撞,需要实现一个尽量均匀分布的 hash 函数
HashMap 的默认长度为 16,是为了降低 hash 碰撞的几率
为什么重写 equals 方法的时候需要重写 HashCode 方法呢?
java 中所有的对象都是继承于 Object 类,而 Ojbect类中有两个方法 equals、HashCode,这两个方法都是用来比较两个对象是否相等的。
在未重写 equals 方法时是继承了 Object 类的 equals 方法,那里的 equals 是比较两个对象的内存地址。HashMap 是通过 key 的 HashCode 去寻找 index 的,如果 index 的值一样就会形成链表,比如:”张三“ 和 ”李四“ 的 index 有可能都是 1,并且在一个链表上面。
这时如果去查询,根据 key 去 hash 最后计算出 index 为 1,即出现hash碰撞无法定位是哪个对象。因此重写 equals一定要对 HashCode 方法重写,这样可以保证相同的对象返回相同的 hash 值,不同的对象返回不同的 hash 值。
如果两个键key的hashcode相同,如何存储键值对
hashcode相同则会进一步调用equals比较内容是否相同,如果相同则用新值覆盖旧值,如果不相同则认为是新的元素插入直接链接到链表后面
put(key, value)方法
(1)计算key的hash值,定位到数组中的具体位置
(2)查看位置有没有元素,根据当前位桶关联的是链表还是红黑树执行相关的操作(插入过程中,判断两个key是否相等的条件hash值相等,且==或者equals返回true)
- 没有的话直接插入key-value(如果是红黑树则执行树的插入操作;如果是链表则尾插法到链表末尾,并且需校验插入后链表长度是否超出阈值/转化为红黑树)
- 如果有元素,且满足相等条件,替换旧值
(3)判断扩容条件:插入则执行size ++,如果size > threshold,进行扩容
resize()扩容
. 如果插入一个元素后的size满足size>threshold则进行扩容,HashMap每次扩容都会扩大到之前的两倍
扩展理解为什么是2倍?是为了降低hash冲突,保证key 索引值的均匀分布