⑥JVM JVM故障问题排查
⑥JVM JVM故障问题排查
学习核心
- 内存泄漏问题排查
- GC引起CPU飙升问题排查(5个步骤一步步定位)
- 现场保留(瞬时信息和历史信息的记录保留,后续进行跟踪分析)
- 常用工具:jinfo、jstat、jstack、jhsdb(jmap)等工具,尤其是jmap(分析处理内存泄漏的利器)
- 一个卡顿实例分析(结合卡顿实例,掌握分析思路和实践过程)
- 高并发业务场景中启用swap造成的服务卡顿
- 内存泄漏 VS 内存溢出
- 区分内存泄漏(原因)和内存溢出(结果)概念
- 内存泄漏现象
- 内存泄漏案例(HashMap使用不当、文件操作资源未及时释放、JavaAPI使用不当、ThrealLocal使用误区)
学习资料
工具篇:
- Java虚拟机的监控及诊断工具
- 推荐学习:内存分析于相关工具上篇、下篇
扩展:
内存泄漏排查
JVM 是运行在操作系统之上的,操作系统的一些限制,会严重影响 JVM 的行为,例如最常见的系统发生 OOM。故障排查是一个综合性的技术问题,在日常项目开发中要增加自己的知识广度。多总结、多思考、多记录,这才是正确的晋级方式。
现在的互联网服务,一般都做了负载均衡。如果一个实例发生了问题,不要着急去重启。万能的重启会暂时缓解问题,但如果不保留现场,可能就错失了解决问题的根本,担心的事情还会到来。
所以,当实例发生问题的时候,第一步是隔离,第二步才是问题排查。所谓隔离,就是把你的这台机器从请求列表里摘除,比如把 nginx 相关的权重设成零。在微服务中,也有相应的隔离机制
掌握JVM 故障排查的涉及到的 Linux 命令并逐个击破
✨常用的监控和诊断内存工具
Java 是基于 JVM 上运行的,大部分内存都是在 JVM 的用户内存中创建的。一方面是需要监控整个服务器的内存使用情况,另一方面是要掌握JVM中的内存分配和使用情况
基于服务器的内存使用情况监控:使用Linux命令行工具
top:实时显示正在执行进程的 CPU 使用率、内存使用率以及系统负载等信息;还可进一步查看指定进程下具体线程的资源占用情况vmstat:一款指定采样周期和次数的功能性监测工具,可查看内存情况,常用作观察进程上下文切换pidstat:除了监测进程内存,还可深入到监测线程级别的内存使用情况
基于JVM的内存分配和使用情况监控(使用JDK自带的命令工具)
jstat:监测Java应用程序的实时运行情况(包括堆内存信息、垃圾回收信息)jstack:线程堆栈分析工具(查看线程状态、堆栈信息,常用于排查死锁异常)jamp:查看堆内存初始化配置信息、堆内存的使用情况(可确认堆内存的对象信息、产生什么对象、对象数量多少)
JDK 中就自带了很多命令工具可以监测到 JVM 的内存分配以及使用情况
top命令(Linux命令行工具)
top 命令可以实时显示正在执行进程的 CPU 使用率、内存使用率以及系统负载等信息。其中上半部分显示的是系统的统计信息,下半部分显示的是进程的使用率统计信息
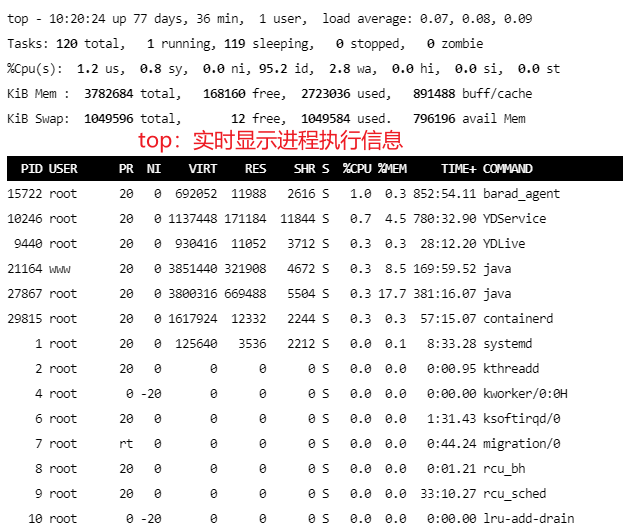
还可通过top -Hp $pid查看具体线程使用系统资源的情况
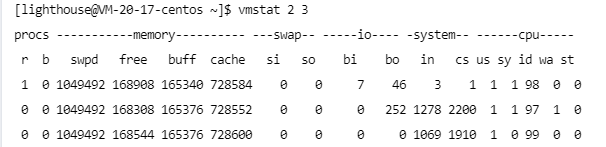
vmstat命令(Linux命令行工具)
vmstat 是一款指定采样周期和次数的功能性监测工具,它不仅可以统计内存的使用情况,还可以观测到 CPU 的使用率、swap 的使用情况。但 vmstat 一般很少用来查看内存的使用情况,而是经常被用来观察进程的上下文切换
vmstat、vmstat 1 5(每隔1s,采样次数为5)
| 列名 |
|---|
r:等待运行的进程数 |
b:处于非中断睡眠状态的进程数 |
swpd:虚拟内存使用情况 |
free:空闲的内存 |
buff:用来作为缓冲的内存数 |
si:从磁盘交换到内存的交换页数量 |
so:从内存交换到磁盘的交换页数量 |
bi:发送到块设备的块数 |
bo:从块设备接收到的块数 |
in:每秒中断数 |
cs:每秒上下文切换次数 |
us:用户 CPU 使用时间 |
sy:内核 CPU 系统使用时间 |
id:空闲时间 |
wa:等待 I/O 时间 |
st:运行虚拟机窃取的时间 |
pidstat命令(Linux命令行工具)
pidstat 是 sysstat 中的一个组件,也是一款功能强大的性能监测工具
通过命令:yum install sysstat 安装该监控组件(sudo yum install sysstat)
# 腾讯云宝塔安装pidstat工具
sudo apt-get update
sudo apt-get install -y sysstat
top 和 vmstat 两个命令都是监测进程的内存、CPU 以及 I/O 使用情况,而 pidstat 命令则是深入到线程级别。通过 pidstat -help 命令,查看到有以下几个常用的参数来监测线程的性能
pidstat --help
用法:pidstat [ 选项 ] [ <时间间隔> [ <计数> ] ] [ -e <程序> <参数> ]
选项:
[ -d ] [ -H ] [ -h ] [ -I ] [ -l ] [ -R ] [ -r ] [ -s ] [ -t ] [ -U [ <用户名> ] ]
[ -u ] [ -V ] [ -v ] [ -w ] [ -C <命令> ] [ -G <进程名> ]
[ -p { <pid> [,...] | SELF | ALL } ] [ -T { TASK | CHILD | ALL } ]
[ --dec={ 0 | 1 | 2 } ] [ --human ]
| 参数 |
|---|
-u:默认的参数,显示各个进程的 cpu 使用情况 |
-r:显示各个进程的内存使用情况 |
-d:显示各个进程的 I/O 使用情况 |
-w:显示每个进程的上下文切换情况 |
-p:指定进程号 |
-t:显示进程中线程的统计信息 |
# 案例分析
# 步骤1:查看相关进程ID
noob@noob-virtual-machine:~$ jps
53200 Jps
45530 OjCodeSandboxApplication
# 步骤2:监测进程的内存使用情况
noob@noob-virtual-machine:~$ pidstat -p 45530 -r 2 3
Linux 6.5.0-28-generic (noob-virtual-machine) 2024年06月02日 _x86_64_ (4 CPU)
11时05分19秒 UID PID minflt/s majflt/s VSZ RSS %MEM Command
11时05分21秒 1000 45530 0.00 0.00 5555300 220628 2.73 java
11时05分23秒 1000 45530 0.00 0.00 5555300 220628 2.73 java
11时05分25秒 1000 45530 0.00 0.00 5555300 220628 2.73 java
平均时间: 1000 45530 0.00 0.00 5555300 220628 2.73 java
# 步骤3:进一步查看进程下的线程内存使用率,添加-t选项
noob@noob-virtual-machine:~$ pidstat -p 45530 -r 2 3 -t
Linux 6.5.0-28-generic (noob-virtual-machine) 2024年06月02日 _x86_64_ (4 CPU)
11时11分40秒 UID TGID TID minflt/s majflt/s VSZ RSS %MEM Command
11时11分42秒 1000 45530 - 1.00 0.00 5555300 220628 2.73 java
11时11分42秒 1000 - 45530 0.00 0.00 5555300 220628 2.73 |__java
11时11分42秒 1000 - 45532 0.00 0.00 5555300 220628 2.73 |__java
11时11分42秒 1000 - 45533 0.00 0.00 5555300 220628 2.73 |__GC task thread#
11时11分42秒 1000 - 45542 0.00 0.00 5555300 220628 2.73 |__VM Thread
11时11分42秒 1000 - 45543 0.00 0.00 5555300 220628 2.73 |__Reference Handl
11时11分42秒 1000 - 45544 0.00 0.00 5555300 220628 2.73 |__Finalizer
11时11分42秒 1000 - 45545 0.00 0.00 5555300 220628 2.73 |__Signal Dispatch
11时11分42秒 1000 - 45548 0.00 0.00 5555300 220628 2.73 |__JDWP Event Help
【步骤1】使用ps、jps:查看相关进程ID
【步骤2】使用pidstat:监测该进程的内存使用情况
参数说明:-p指定进程ID、-r监控内存的使用情况、2:每隔2s、3:采样3次
关键指标说明:
Minflt/s:任务每秒发生的次要错误,不需要从磁盘中加载页Majflt/s:任务每秒发生的主要错误,需要从磁盘中加载页VSZ:虚拟地址大小,虚拟内存使用 KBRSS:常驻集合大小,非交换区内存使用 KB
jps(JDK工具)
jps:打印所有正在运行的Java进程
noob@noob-virtual-machine:~/logs/oomDemo$ jps
58761 Jps
45530 OjCodeSandboxApplication
55533 jar
jinfo(JDK工具)
jinfo:打印目标Java进程的配置参数,且可以改动其中的manageabe参数
noob@noob-virtual-machine:~/logs/oomDemo$ sudo jinfo 55533
Attaching to process ID 55533, please wait...
Debugger attached successfully.
Server compiler detected.
JVM version is 25.402-b06
Java System Properties:
java.runtime.name = OpenJDK Runtime Environment
java.vm.version = 25.402-b06
sun.boot.library.path = /usr/lib/jvm/java-8-openjdk-amd64/jre/lib/amd64
java.protocol.handler.pkgs = org.springframework.boot.loader
java.vendor.url = http://java.oracle.com/
java.vm.vendor = Private Build
path.separator = :
file.encoding.pkg = sun.io
java.vm.name = OpenJDK 64-Bit Server VM
sun.os.patch.level = unknown
sun.java.launcher = SUN_STANDARD
user.country = CN
user.dir = /home/noob/code/jars/target
java.vm.specification.name = Java Virtual Machine Specification
PID = 55533
java.runtime.version = 1.8.0_402-8u402-ga-2ubuntu1~22.04-b06
java.awt.graphicsenv = sun.awt.X11GraphicsEnvironment
os.arch = amd64
java.endorsed.dirs = /usr/lib/jvm/java-8-openjdk-amd64/jre/lib/endorsed
CONSOLE_LOG_CHARSET = UTF-8
line.separator =
java.io.tmpdir = /tmp
java.vm.specification.vendor = Oracle Corporation
os.name = Linux
FILE_LOG_CHARSET = UTF-8
sun.jnu.encoding = UTF-8
java.library.path = /usr/java/packages/lib/amd64:/usr/lib/x86_64-linux-gnu/jni:/lib/x86_64-linux-gnu:/usr/lib/x86_64-linux-gnu:/usr/lib/jni:/lib:/usr/lib
spring.beaninfo.ignore = true
java.specification.name = Java Platform API Specification
java.class.version = 52.0
sun.management.compiler = HotSpot 64-Bit Tiered Compilers
os.version = 6.5.0-28-generic
user.home = /home/noob
user.timezone = Asia/Shanghai
catalina.useNaming = false
java.awt.printerjob = sun.print.PSPrinterJob
file.encoding = UTF-8
java.specification.version = 1.8
catalina.home = /tmp/tomcat.8080.8994288621376893718
user.name = noob
java.class.path = OomDemo-0.0.1-SNAPSHOT.jar
java.vm.specification.version = 1.8
sun.arch.data.model = 64
sun.java.command = OomDemo-0.0.1-SNAPSHOT.jar
java.home = /usr/lib/jvm/java-8-openjdk-amd64/jre
user.language = zh
java.specification.vendor = Oracle Corporation
awt.toolkit = sun.awt.X11.XToolkit
java.vm.info = mixed mode
java.version = 1.8.0_402
java.ext.dirs = /usr/lib/jvm/java-8-openjdk-amd64/jre/lib/ext:/usr/java/packages/lib/ext
sun.boot.class.path = /usr/lib/jvm/java-8-openjdk-amd64/jre/lib/resources.jar:/usr/lib/jvm/java-8-openjdk-amd64/jre/lib/rt.jar:/usr/lib/jvm/java-8-openjdk-amd64/jre/lib/sunrsasign.jar:/usr/lib/jvm/java-8-openjdk-amd64/jre/lib/jsse.jar:/usr/lib/jvm/java-8-openjdk-amd64/jre/lib/jce.jar:/usr/lib/jvm/java-8-openjdk-amd64/jre/lib/charsets.jar:/usr/lib/jvm/java-8-openjdk-amd64/jre/lib/jfr.jar:/usr/lib/jvm/java-8-openjdk-amd64/jre/classes
java.awt.headless = true
java.vendor = Private Build
catalina.base = /tmp/tomcat.8080.8994288621376893718
java.specification.maintenance.version = 5
file.separator = /
java.vendor.url.bug = http://bugreport.sun.com/bugreport/
sun.io.unicode.encoding = UnicodeLittle
sun.cpu.endian = little
sun.desktop = gnome
sun.cpu.isalist =
VM Flags:
Non-default VM flags: -XX:CICompilerCount=3 -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=null -XX:InitialHeapSize=1048576000 -XX:MaxHeapSize=4194304000 -XX:MaxNewSize=1397751808 -XX:MinHeapDeltaBytes=524288 -XX:NewSize=349175808 -XX:OldSize=699400192 -XX:+PrintGC -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -XX:+UseCompressedClassPointers -XX:+UseCompressedOops -XX:+UseFastUnorderedTimeStamps -XX:+UseParallelGC
Command line: -Xms1000m -Xmx4000m -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/home/noob/logs/oomDemo/heapdump.hprof -XX:+PrintGCTimeStamps -XX:+PrintGCDetails -Xloggc:/home/noob/logs/oomDemo/heapTest.log
还可通过ps指令查看进程信息(例如此处通过关键字定位进程信息,并得到这个java进程的启动配置信息)
noob@noob-virtual-machine:~/logs/oomDemo$ ps -ef | grep OomDemo
noob 55533 5432 25 15:28 pts/0 01:11:45 java -jar -Xms1000m -Xmx4000m -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/home/noob/logs/oomDemo/heapdump.hprof -XX:+PrintGCTimeStamps -XX:+PrintGCDetails -Xloggc:/home/noob/logs/oomDemo/heapTest.log OomDemo-0.0.1-SNAPSHOT.jar
noob 58824 56459 0 20:10 pts/3 00:00:00 grep --color=auto OomDemo
jstat(JDK工具)
jstat 可以监测 Java 应用程序的实时运行情况,包括堆内存信息以及垃圾回收信息
# 查看关键参数信息(-help)
noob@noob-virtual-machine:~$ jstat -help
Usage: jstat -help|-options
jstat -<option> [-t] [-h<lines>] <vmid> [<interval> [<count>]]
Definitions:
<option> An option reported by the -options option
<vmid> Virtual Machine Identifier. A vmid takes the following form:
<lvmid>[@<hostname>[:<port>]]
Where <lvmid> is the local vm identifier for the target
Java virtual machine, typically a process id; <hostname> is
the name of the host running the target Java virtual machine;
and <port> is the port number for the rmiregistry on the
target host. See the jvmstat documentation for a more complete
description of the Virtual Machine Identifier.
<lines> Number of samples between header lines.
<interval> Sampling interval. The following forms are allowed:
<n>["ms"|"s"]
Where <n> is an integer and the suffix specifies the units as
milliseconds("ms") or seconds("s"). The default units are "ms".
<count> Number of samples to take before terminating.
-J<flag> Pass <flag> directly to the runtime system.
# 查看jstat有哪些操作(-options)
noob@noob-virtual-machine:~$ jstat -options
-class
-compiler
-gc
-gccapacity
-gccause
-gcmetacapacity
-gcnew
-gcnewcapacity
-gcold
-gcoldcapacity
-gcutil
-printcompilation
| 参数说明 |
|---|
-class:显示 ClassLoad 的相关信息; |
-compiler:显示 JIT 编译的相关信息; |
-gc:显示和 gc 相关的堆信息; |
-gccapacity:显示各个代的容量以及使用情况; |
-gcmetacapacity:显示 Metaspace 的大小; |
-gcnew:显示新生代信息; |
-gcnewcapacity:显示新生代大小和使用情况; |
-gcold:显示老年代和永久代的信息; |
-gcoldcapacity :显示老年代的大小; |
-gcutil:显示垃圾收集信息; |
-gccause:显示垃圾回收的相关信息(通 -gcutil),同时显示最后一次或当前正在发生的垃圾回收的诱因; |
-printcompilation:输出 JIT 编译的方法信息 |
✨常用功能:使用jstat查看堆内存的使用情况
jstat -gc pid
# 步骤1:获取到指定进程ID
noob@noob-virtual-machine:~$ jps
45530 OjCodeSandboxApplication
53500 Jps
# 步骤2:查看堆内存的使用情况
noob@noob-virtual-machine:~$ jstat -gc 45530
S0C S1C S0U S1U EC EU OC OU MC MU CCSC CCSU YGC YGCT FGC FGCT GCT
12288.0 12288.0 0.0 0.0 144896.0 37732.0 90112.0 17517.4 35416.0 33015.1 4864.0 4299.8 6 0.061 2 0.072 0.133
| 参数说明 |
|---|
S0C:年轻代中 To Survivor 的容量(单位 KB) |
S1C:年轻代中 From Survivor 的容量(单位 KB) |
S0U:年轻代中 To Survivor 目前已使用空间(单位 KB) |
S1U:年轻代中 From Survivor 目前已使用空间(单位 KB) |
EC:年轻代中 Eden 的容量(单位 KB) |
EU:年轻代中 Eden 目前已使用空间(单位 KB) |
OC:Old 代的容量(单位 KB) |
OU:Old 代目前已使用空间(单位 KB) |
MC:Metaspace 的容量(单位 KB) |
MU:Metaspace 目前已使用空间(单位 KB) |
YGC:从应用程序启动到采样时年轻代中 gc 次数 |
YGCT:从应用程序启动到采样时年轻代中 gc 所用时间 (s) |
FGC:从应用程序启动到采样时 old 代(全 gc)gc 次数 |
FGCT:从应用程序启动到采样时 old 代(全 gc)gc 所用时间 (s) |
GCT:从应用程序启动到采样时 gc 用的总时间 (s) |
jstack(JDK工具)
jstack是一种线程堆栈分析工具,最常用的功能就是使用 jstack pid 命令查看线程的堆栈信息
通常会结合 top -Hp pid 或 pidstat -p pid -t 一起查看具体线程的状态,也经常用来排查一些死锁的异常
# jps:列出当前系统中正在运行的Java进程
noob@noob-virtual-machine:~$ jps
53625 Jps
45530 OjCodeSandboxApplication
# jstack pid
noob@noob-virtual-machine:~$ jstack 45530
2024-06-02 12:08:20
Full thread dump OpenJDK 64-Bit Server VM (25.402-b06 mixed mode):
"DestroyJavaVM" #39 prio=5 os_prio=0 tid=0x00007d0e10013000 nid=0xb1dc waiting on condition [0x0000000000000000]
java.lang.Thread.State: RUNNABLE
"http-nio-8090-Acceptor" #38 daemon prio=5 os_prio=0 tid=0x00007d0e10f4d800 nid=0xb227 runnable [0x00007d0db5fcf000]
java.lang.Thread.State: RUNNABLE
at sun.nio.ch.ServerSocketChannelImpl.accept0(Native Method)
at sun.nio.ch.ServerSocketChannelImpl.accept(ServerSocketChannelImpl.java:421)
at sun.nio.ch.ServerSocketChannelImpl.accept(ServerSocketChannelImpl.java:249)
- locked <0x00000000854281d8> (a java.lang.Object)
at org.apache.tomcat.util.net.NioEndpoint.serverSocketAccept(NioEndpoint.java:547)
at org.apache.tomcat.util.net.NioEndpoint.serverSocketAccept(NioEndpoint.java:79)
at org.apache.tomcat.util.net.Acceptor.run(Acceptor.java:129)
at java.lang.Thread.run(Thread.java:750)
可跟踪每个线程的堆栈信息,查看到线程ID、线程的状态(wait、sleep、running中等状态)、是否持有锁
jmap(JDK工具)
使用`jmap`查看堆内存初始化配置信息以及堆内存的使用情况。还可以使用 `jmap` 输出堆内存中的对象信息,包括产生了哪些对象,对象数量多少等
# jamp $pid (如果操作不允许,则添加sudo执行)
noob@noob-virtual-machine:~$ jmap -heap 45530
Attaching to process ID 45530, please wait...
ERROR: ptrace(PTRACE_ATTACH, ..) failed for 45530: 不允许的操作
Error attaching to process: sun.jvm.hotspot.debugger.DebuggerException: Can't attach to the process: ptrace(PTRACE_ATTACH, ..) failed for 45530: 不允许的操作
sun.jvm.hotspot.debugger.DebuggerException: sun.jvm.hotspot.debugger.DebuggerException: Can't attach to the process: ptrace(PTRACE_ATTACH, ..) failed for 45530: 不允许的操作
at sun.jvm.hotspot.debugger.linux.LinuxDebuggerLocal$LinuxDebuggerLocalWorkerThread.execute(LinuxDebuggerLocal.java:163)
at sun.jvm.hotspot.debugger.linux.LinuxDebuggerLocal.attach(LinuxDebuggerLocal.java:278)
at sun.jvm.hotspot.HotSpotAgent.attachDebugger(HotSpotAgent.java:671)
at sun.jvm.hotspot.HotSpotAgent.setupDebuggerLinux(HotSpotAgent.java:611)
at sun.jvm.hotspot.HotSpotAgent.setupDebugger(HotSpotAgent.java:337)
# sudo jamp $pid
noob@noob-virtual-machine:~$ sudo jmap -heap 45530
[sudo] noob 的密码:
Attaching to process ID 45530, please wait...
Debugger attached successfully.
Server compiler detected.
JVM version is 25.402-b06
using thread-local object allocation.
Parallel GC with 4 thread(s)
Heap Configuration:
MinHeapFreeRatio = 0
MaxHeapFreeRatio = 100
MaxHeapSize = 2071986176 (1976.0MB)
NewSize = 42991616 (41.0MB)
MaxNewSize = 690487296 (658.5MB)
OldSize = 87031808 (83.0MB)
NewRatio = 2
SurvivorRatio = 8
MetaspaceSize = 21807104 (20.796875MB)
CompressedClassSpaceSize = 1073741824 (1024.0MB)
MaxMetaspaceSize = 17592186044415 MB
G1HeapRegionSize = 0 (0.0MB)
Heap Usage:
Exception in thread "main" java.lang.reflect.InvocationTargetException
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at sun.tools.jmap.JMap.runTool(JMap.java:201)
at sun.tools.jmap.JMap.main(JMap.java:130)
Caused by: java.lang.RuntimeException: unknown CollectedHeap type : class sun.jvm.hotspot.gc_interface.CollectedHeap
at sun.jvm.hotspot.tools.HeapSummary.run(HeapSummary.java:144)
at sun.jvm.hotspot.tools.Tool.startInternal(Tool.java:260)
at sun.jvm.hotspot.tools.Tool.start(Tool.java:223)
at sun.jvm.hotspot.tools.Tool.execute(Tool.java:118)
at sun.jvm.hotspot.tools.HeapSummary.main(HeapSummary.java:49)
... 6 more
使用 jmap -histo[:live] pid 查看堆内存中的对象数目、大小统计直方图,如果带上 live 则只统计活对象
noob@noob-virtual-machine:~$ jmap -histo:live 45530 | more
num #instances #bytes class name
----------------------------------------------
1: 33340 2903960 [C
2: 33273 798552 java.lang.String
3: 7148 791648 java.lang.Class
4: 14304 457728 java.util.concurrent.ConcurrentHashMap$Node
5: 7695 373312 [Ljava.lang.Object;
6: 1190 291480 [B
7: 6120 244800 java.util.LinkedHashMap$Entry
8: 2549 224312 java.lang.reflect.Method
9: 2410 222416 [Ljava.util.HashMap$Node;
10: 6912 221184 java.util.HashMap$Node
11: 122 177696 [Ljava.util.concurrent.ConcurrentHashMap$Node;
12: 9130 146080 java.lang.Object
13: 2500 140000 java.util.LinkedHashMap
14: 2804 131272 [I
15: 1381 77336 java.lang.invoke.MemberName
16: 2772 64360 [Ljava.lang.Class;
17: 1556 62240 java.lang.ref.SoftReference
18: 2348 56352 java.util.ArrayList
19: 1248 49920 java.lang.invoke.MethodType
20: 953 49096 [Ljava.lang.String;
通过jmap命令把堆内存的使用情况dump到文件中,然后将文件下载下来,使用MAT工具(EclipseMemoryAnalyzerTool)打开文件进行分析
1.GC引起CPU飙升
CPU占用过高排查思路
问题场景:线上应用:单节点在运行一段时间后,CPU 的使用会飙升
一旦飙升,一般怀疑某个业务逻辑的计算量太大,或者是触发了死循环(比如HashMap 高并发引起的死循环)但也排除是GC 的问题
在 Linux 上,分析哪个线程引起的 CPU 问题,通常有一个固定的步骤
| 步骤 | 指令 | 说明 |
|---|---|---|
| 1 | top | 查找CPU最多的某个进程,记录pid 使用shift+P快捷键可按CPU使用率进行排序 |
| 2 | top -Hp $pid | 查看某个进程中使用CPU最多的某个线程,记录线程ID(tid) |
| 3 | printf %x &tid | 使用printf函数,将10进制的tid转化为16进制 |
| 4 | jstack $pid>$pid.log | 使用jstack命令,查看Java进程的线程栈(输出到指定文件) |
| 5 | less $pid.log | 使用less命令查看生成的文件,并查找步骤3中获取到的16进制的tid,找到发生问题的线程上下文 |
其中步骤4、步骤5可以调整为直接查看堆栈信息
- 查看堆栈信息定位
jstack pid |grep tid的十六进制 -A 30
参考jstack日志分析:
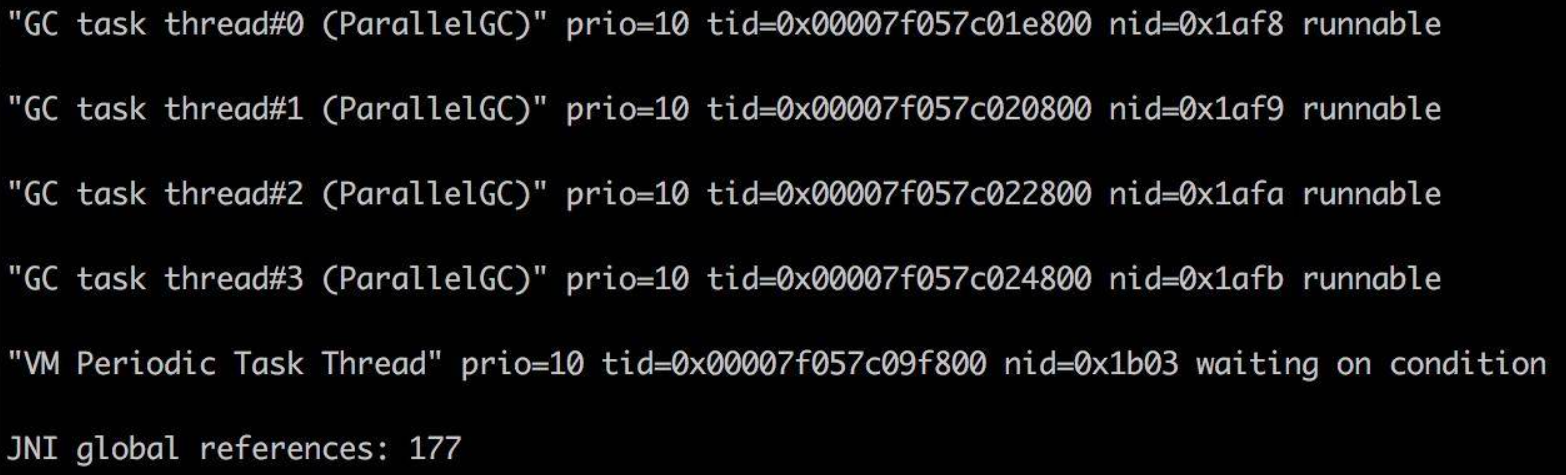
结合上述日志分析:问题发生的根源,是堆已经满了,但是又没有发生 OOM,于是 GC 进程就一直在那里回收,回收的效果又非常一般,造成 CPU 升高应用假死
接下来的具体问题排查,就需要把内存 dump 一份下来,使用 MAT 等工具分析具体原因
GC问题排查分析
结合jstack日志,如果发现CPU占用过高的线程在进行大量的GC,则需进行GC问题排查,排查思路参考如下:
| 步骤 | 指令 | 说明 |
|---|---|---|
| 1 | top | 查看占用cpu高的进程信息 |
| 2 | jstat -gcutil pid | 查看gc状况 |
| 3 | jmap -dump:format=b,file=name.dump pid | 导出dump文件 |
| 4 | visualVM、MAT工具分析 | 用visualVM分析dump文件 |
2.现场保留
现场保留过程是繁杂而冗长的,需要记忆很多内容。现场保留可以使用自动化方式将必要的信息保存下来,需要了解一般在线上系统会保留哪些信息。
瞬时态和历史态
此处引入瞬时态和历史态概念:瞬时态是指当时发生的、快照类型的元素;历史态是指按照频率抓取的,有固定监控项的资源变动图
有很多信息,比如 CPU、系统内存等,瞬时态的价值就不如历史态来的直观一些。因为瞬时状态无法体现一个趋势性问题(比如斜率、求导等),而这些信息的获取一般依靠监控系统的协作。
但对于 lsof、heap 等,这种没有时间序列概念的混杂信息,体积都比较大,无法进入监控系统产生有用价值,就只能通过瞬时态进行分析。在这种情况下,瞬时态的价值反而更大一些。常见的堆快照,就属于瞬时状态。
问题不是凭空产生的,在分析时,一般要收集系统的整体变更集合,比如代码变更、网络变更,甚至数据量的变化
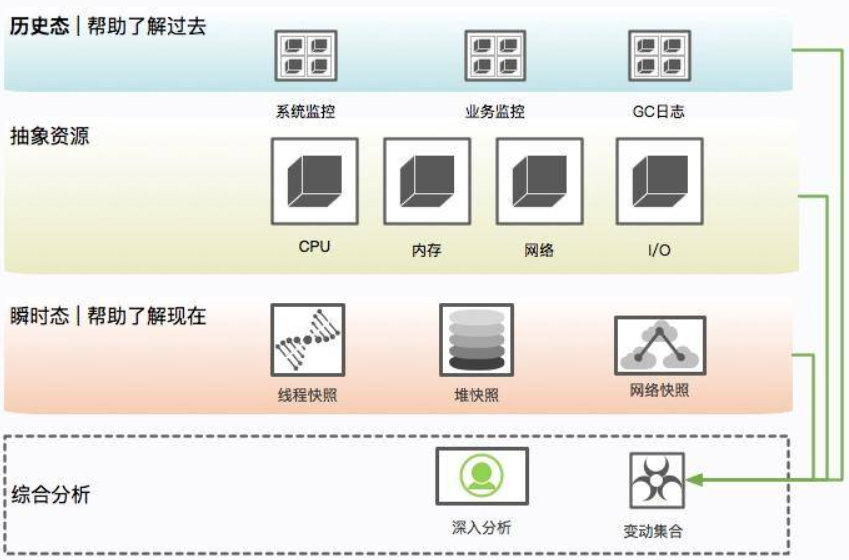
保留信息
(1)系统当前网络连接
# ss 命令将系统的所有网络连接输出到 ss.dump 文件中
ss -antp > $DUMP_DIR/ss.dump 2>&1
使用 ss 命令而不是 netstat 的原因:netstat 在网络连接非常多的情况下,执行非常缓慢
排查分析:可通过查看各种网络连接状态的梳理,来排查 TIME_WAIT 或者 CLOSE_WAIT,或者其他连接过高的问题
案例分析:线上有个系统更新之后,监控到 CLOSE_WAIT 的状态突增,最后整个 JVM 都无法响应。CLOSE_WAIT 状态的产生一般都是代码问题,使用 jstack 最终定位到是因为 HttpClient 的不当使用而引起的,多个连接不完全主动关闭
(2)网络状态统计
# netstat 命令将网络统计状态输出到 netstat-s.dump 文件中(能够按照各个协议进行统计输出,对把握当时整个网络状态有非常大的作用)
netstat -s > $DUMP_DIR/netstat-s.dump 2>&1
# 使用 sar 输出当前的网络流量
sar -n DEV 1 2 > $DUMP_DIR/sar-traffic.dump 2>&1
在一些速度非常高的模块上,比如 Redis、Kafka,就经常发生跑满网卡的情况。如果Java 程序和它们在一起运行,资源则会被挤占,表现形式就是网络通信非常缓慢
(3)进程资源
# 通过lsof指令查看进程(可跟踪打开了哪些文件)
lsof -p $PID > $DUMP_DIR/lsof-$PID.dump
通过lsof指令查看进程(可跟踪打开了哪些文件),可以以进程的维度来查看整个资源的使用情况,包括每条网络连接、每个打开的文件句柄、连接到哪些服务、使用了什么资源。这个命令在资源非常多的情况下,输出稍慢,请耐心等待。
(4)CPU 资源
# 输出当前系统的 CPU 和负载,便于事后排查。这几个命令的功能,有不少重合,使用时要注意甄别
mpstat > $DUMP_DIR/mpstat.dump 2>&1
vmstat 1 3 > $DUMP_DIR/vmstat.dump 2>&1
sar -p ALL > $DUMP_DIR/sar-cpu.dump 2>&1
uptime > $DUMP_DIR/uptime.dump 2>&1
(5)I/O 资源
# 使用iostat命令输出每块磁盘的基本性能信息,用来排查 I/O 问题
iostat -x > $DUMP_DIR/iostat.dump 2>&1
一般情况下如果是以计算为主的服务节点,I/O 资源会比较正常,但有时也会发生问题,比如日志输出过多,或者磁盘问题等
(6)内存问题
# free 命令能够大体展现操作系统的内存概况
free -h > $DUMP_DIR/free.dump 2>&1
free 命令能够大体展现操作系统的内存概况,这是故障排查中一个非常重要的点,比如 SWAP 影响了 GC,SLAB 区挤占了 JVM 的内存
(7)其他全局
ps -ef > $DUMP_DIR/ps.dump 2>&1
dmesg > $DUMP_DIR/dmesg.dump 2>&1
sysctl -a > $DUMP_DIR/sysctl.dump 2>&1
dmesg 是许多静悄悄死掉的服务留下的最后一点线索。ps 作为执行频率最高的一个命令,它当时的输出信息,也必然有一些可以参考的价值
由于内核的配置参数,会对系统和 JVM 产生影响,因此也输出了一份用作排查
(8)进程快照,最后的遗言(jinfo)
# 输出 Java 的基本进程信息,包括环境变量和参数配置
${JDK_BIN}jinfo $PID > $DUMP_DIR/jinfo.dump 2>&1
此命令将输出 Java 的基本进程信息,包括环境变量和参数配置,可以查看是否因为一些错误的配置造成了 JVM 问题
(9)dump 堆信息
${JDK_BIN}jstat -gcutil $PID > $DUMP_DIR/jstat-gcutil.dump 2>&1
${JDK_BIN}jstat -gccapacity $PID > $DUMP_DIR/jstat-gccapacity.dump 2>&1
jstat 将输出当前的 gc 信息(一般,基本能大体看出一个端倪),如果不能分析出来,可将借助 jmap 来进行分析
(10)堆信息
${JDK_BIN}jmap $PID > $DUMP_DIR/jmap.dump 2>&1
${JDK_BIN}jmap -heap $PID > $DUMP_DIR/jmap-heap.dump 2>&1
${JDK_BIN}jmap -histo $PID > $DUMP_DIR/jmap-histo.dump 2>&1
${JDK_BIN}jmap -dump:format=b,file=$DUMP_DIR/heap.bin $PID > /dev/null 2>&1
jmap 将会得到当前 Java 进程的 dump 信息。如上所示,其实最有用的就是第 4 个命令,但是前面三个能够让你初步对系统概况进行大体判断。
因为,第 4 个命令产生的文件,一般都非常的大。而且,需要下载下来,导入 MAT 这样的工具进行深入分析,才能获取结果。这是分析内存泄漏一个必经的过程
(11)JVM 执行栈
# jstack 将会获取当时的执行栈(一般会多次取值,此处取一次),能够还原 Java 进程中的线程情况
${JDK_BIN}jstack $PID > $DUMP_DIR/jstack.dump 2>&1
# 使用top 命令,来获取进程中所有线程的 CPU 信息(得到更加精细的信息),据此可以可能到资源到底消耗在什么地方
top -Hp $PID -b -n 1 -c > $DUMP_DIR/top-$PID.dump 2>&1
(12)高级替补
有时候,jstack 并不能够运行(有很多原因,比如 Java 进程几乎不响应了等之类的情况)。尝试向进程发送 kill -3 信号,这个信号将会打印 jstack 的 trace 信息到日志文件中,是 jstack 的一个替补方案
# jstack的替补方案,打印jstack的trace信息到日志文件
kill -3 $PID
对于 jmap 无法执行的问题,也有替补,那就是 GDB 组件中的 gcore,将会生成一个 core 文件
gcore -o $DUMP_DIR/core $PID
可以使用如下的命令去生成 dump
${JDK_BIN}jhsdb jmap --exe ${JDK}java --core $DUMP_DIR/core --binaryheap
3.一个卡顿实例
卡顿问题场景:
- 有一个关于服务的某个实例,经常发生服务卡顿,由于服务的并发量是比较高的,所以表现也非常明显,每多停顿 1 秒钟,几万用户的请求就会感到延迟
问题排查过程分析:
统计、类比了此服务其他实例的 CPU、内存、网络、I/O 资源,区别并不是很大,所以一度怀疑是机器硬件的问题
随后对比了节点的 GC 日志,发现无论是 Minor GC,还是 Major GC,这个节点所花费的时间,都比其他实例长得多
通过仔细观察,发现在 GC 发生的时候,vmstat 的 si、so 飙升的非常严重,这和其他实例有着明显的不同
使用 free 命令再次确认,发现 SWAP 分区,使用的比例非常高,引起的具体原因是什么呢?
查看更详细的操作系统内存分布,从 /proc/meminfo 文件中可以看到具体的逻辑内存块大小,有多达 40 项的内存信息,这些信息都可以通过遍历 /proc 目录的一些文件获取。进一步注意到 slabtop 命令显示的有一些异常,dentry(目录高速缓冲)占用非常高
问题最终定位到是由于某个运维工程师执行了一句命令:
find / | grep "x",其目的是想找一个叫做 x 的文件,看看在哪台服务器上,结果因为这些老服务器由于文件太多,扫描后这些文件信息都缓存到了 slab 区上。而服务器开了 swap,操作系统发现物理内存占满后,并没有立即释放 cache,导致每次 GC 都要和硬盘打一次交道
解决方案
解决方式就是关闭 SWAP 分区
swap 是很多性能场景的万恶之源,建议禁用。当应用真正高并发了,SWAP 绝对能让你体验到它魔鬼性的一面:进程倒是死不了了,但 GC 时间长的却让人无法忍受
4.内存泄漏 VS 内存溢出
内存泄漏 VS 内存溢出
内存泄漏:申请内存资源并使用完成后无法正常释放资源导致的情况(例如不再被使用的对象、没有被回收、没有及时切断与 GC Roots 的联系,其主要是因为一些错误的编程方式,或者过多的无用对象创建引起的),内存泄漏最终会导致内存溢出
内存溢出:内存不够用了,当无法为新对象分配足够的内存的情况。(内存溢出的原因有内存空间不足、配置错误等因素)
内存溢出是一个结果,而内存泄漏是一个原因
内存泄漏现象
jmap 命令在 9 版本里被干掉了,取而代之的是 jhsdb,可以像下面的命令一样使用
jhsdb jmap --heap --pid 37340
jhsdb jmap --pid 37288
jhsdb jmap --histo --pid 37340
jhsdb jmap --binaryheap --pid 37340
heap 参数能够体现大体的内存布局,以及每一个年代中的内存使用情况,且由于它是命令行,所以使用更加广泛。
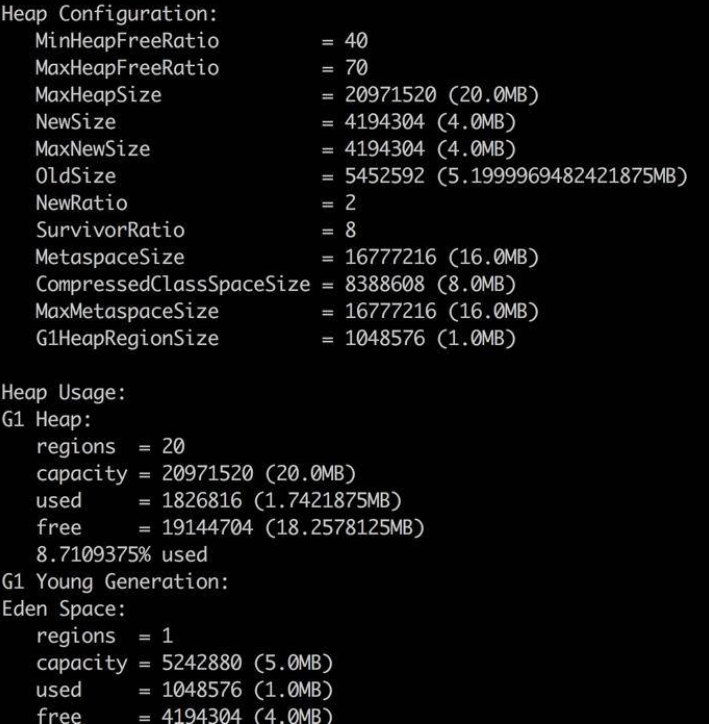
histo 能够大概的看到系统中每一种类型占用的空间大小,用于初步判断问题。比如某个对象 instances 数量很小,但占用的空间很大,这就说明存在大对象。但它也只能看大概的问题,要找到具体原因,还是要 dump 出当前 live 的对象
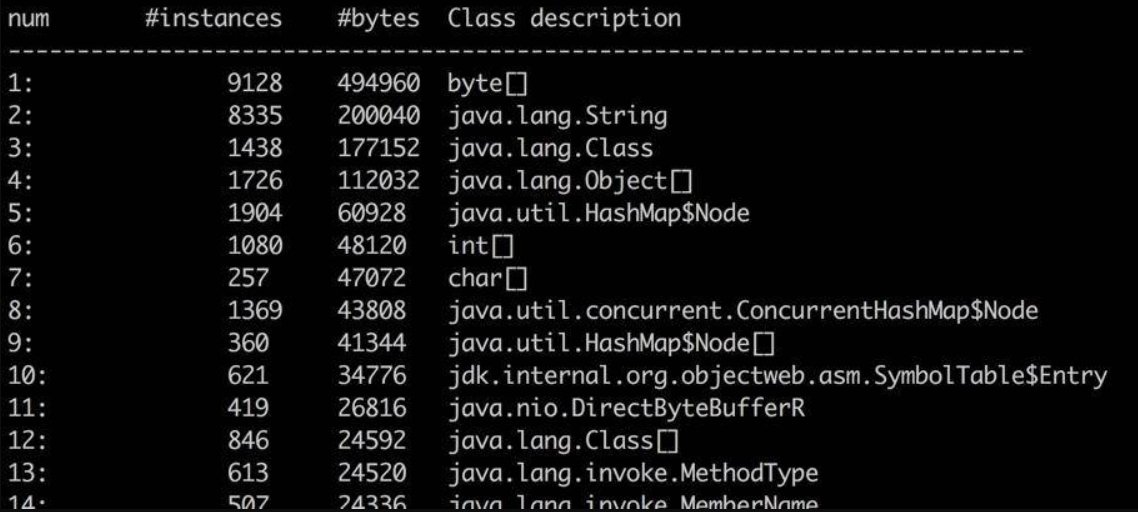
一般内存溢出,表现形式就是 Old 区的占用持续上升,即使经过了多轮 GC 也没有明显改善。我们在前面提到了 GC Roots,内存泄漏的根本就是,有些对象并没有切断和 GC Roots 的关系,可通过一些工具,能够看到它们的联系
内存泄漏案例
案例1:(由HashMap引起的内存泄漏)未限定HashMap缓存策略
例如项目中使用了 HashMap 做缓存,但是并没有设置超时时间或者 LRU 策略,造成了放入 Map 对象的数据越来越多,从而产生了内存泄漏
案例2:(由HashMap引起的内存泄漏)使用自定义对象作为HashMap的key值,但是没有重写自定义对象的hashCode、equals方法
就算重写了hashCode、equals方法,也应尽量避免使用自定义对象作为key值
例如此处由于没有重写 Key 类的 hashCode 和 equals 方法,造成了放入 HashMap 的所有对象都无法被取出来(和外界失联了)
import java.util.HashMap;
import java.util.Map;
public class HashMapLeakDemo {
public static class Key {
String title;
public Key(String title) {
this.title = title;
}
}
public static void main(String[] args) {
Map<Key, Integer> map = new HashMap<>();
map.put(new Key("1"), 1);
map.put(new Key("2"), 2);
map.put(new Key("3"), 2);
Integer integer = map.get(new Key("2"));
System.out.println(integer);
}
}
// output
null
案例3:文件操作异常没有正确地在finally块关闭资源,造成了文件句柄的泄漏
关于文件处理器的应用,在读取或者写入一些文件之后,由于发生了一些异常,close 方法又没有放在 finally 块里面,进而造成了文件句柄的泄漏。由于文件处理十分频繁,产生了严重的内存泄漏问题
案例4:对Java API的使用不当,也会造成内存泄漏
String 的 intern 方法,但如果字符串本身是一个非常长的字符串,而且创建之后不再被使用,则会造成内存泄漏
public class InternDemo {
static String getLongStr() {
StringBuilder sb = new StringBuilder();
for (int i = 0; i < 100000; i++) {
sb.append(UUID.randomUUID().toString());
}
return sb.toString();
}
public static void main(String[] args) {
while (true) {
getLongStr().intern();
}
}
}
案例5:ThreadLocal使用不当,导致内存泄漏,进而触发OOM
模拟对每个线程设置一个本地变量。运行以下代码,访问接口,系统一会儿就发送了内存溢出异常
@RequestMapping(value = "/testThreadLocalOom")
public String testThreadLocalOom(HttpServletRequest request) {
ThreadLocal<Byte[]> localVariable = new ThreadLocal<Byte[]>();
localVariable.set(new Byte[4096*1024]);// 为线程添加变量
return "success";
}
设置启动参数,开启堆内存异常日志
java -jar -Xms1000m -Xmx4000m -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/tmp/heapdump.hprof -XX:+PrintGCTimeStamps -XX:+PrintGCDetails -Xloggc:/tmp/heapTest.log heapTest-0.0.1-SNAPSHOT.jar
模拟请求接口,然后查看接口请求是否出现异常:
- 步骤1:创建Springboot项目,然后编写接口测试本地可否正常访问
- 步骤2:导出jar并上传到指定的服务器运行
- 步骤3:JMeter压测工具模拟多次请求,查看接口请求是否异常
具体分析步骤参考实践应用
GC问题排查
JVM问题排查和性能调优主要基于监控数据来进行
- 指标监控
- 指定JVM启动内存(结合实际场景调整内存大小)
- 指定垃圾收集器(JDK8默认ParallelGC,可指定G1)
- 开启GC日志进行排查,打印并分析GC日志
结合GC性能维度进行分析(确认性能指标是否基本满足、保持资源占用在合理范围)
- STW:停顿时间(暂停用户线程,如果STW时间过长则可能导致用户体验极差),GC中影响延迟的主要因素就是STW
- GC回收速率和存活对象的多少有关,例如CMS追求的是STW尽可能短,会导致吞吐量相对较低(结合打扫教室案例分析)
- 吞吐量:看业务线程消耗的CPU资源百分比
- 系统容量:硬件配置、服务能力等
一般场景下会借助一些操作指令来排查JVM故障,尤其是一些GC问题(内存泄露、内存溢出等),但很多时候可能无法实时跟踪线上的情况,而是需要事后通过日志去分析相关的内容,因此可以通过设置JVM参数来完成“现场保留”操作。(但需注意的是,不同JDK版本的JVM参数配置不同,在实际应用的场景下一定要选择兼容自己版本的参数配置,否则会出现各种意想不到的问题)
一般情况下不用去强制死记硬背这些参数信息,可以说明会配置哪些GC日志信息,用于跟踪什么:例如,一般在项目中输出详细的 GC 日志,并加上可读性强的 GC 日志的时间戳。特别情况下还会追加一些反映对象晋升情况和堆详细信息的日志,用来排查问题。另外,OOM 时自动 Dump 堆栈,也会进行配置
==简化记忆:==输出GC日志的详细信息,跟踪堆栈信息等,也会根据dump的文件信息,借助GC日志分析工具可视化跟踪GC情况
1.启动日志配置
Java8版本
#!/bin/sh
LOG_DIR="/tmp/logs"
JAVA_OPT_LOG=" -verbose:gc"
JAVA_OPT_LOG="${JAVA_OPT_LOG} -XX:+PrintGCDetails"
JAVA_OPT_LOG="${JAVA_OPT_LOG} -XX:+PrintGCDateStamps"
JAVA_OPT_LOG="${JAVA_OPT_LOG} -XX:+PrintGCApplicationStoppedTime"
JAVA_OPT_LOG="${JAVA_OPT_LOG} -XX:+PrintTenuringDistribution"
JAVA_OPT_LOG="${JAVA_OPT_LOG} -Xloggc:${LOG_DIR}/gc_%p.log"
JAVA_OPT_OOM=" -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=${LOG_DIR} -XX:ErrorFile=${LOG_DIR}/hs_error_pid%p.log "
JAVA_OPT="${JAVA_OPT_LOG} ${JAVA_OPT_OOM}"
JAVA_OPT="${JAVA_OPT} -XX:-OmitStackTraceInFastThrow"
# 合并一行展示
-verbose:gc -XX:+PrintGCDetails -XX:+PrintGCDateStamps
-XX:+PrintGCApplicationStoppedTime -XX:+PrintTenuringDistribution
-Xloggc:/tmp/logs/gc_%p.log -XX:+HeapDumpOnOutOfMemoryError
-XX:HeapDumpPath=/tmp/logs -XX:ErrorFile=/tmp/logs/hs_error_pid%p.log
-XX:-OmitStackTraceInFastThrow
| 参数 | 意义 |
|---|---|
-verbose:gc | 打印 GC 日志 |
PrintGCDetails | 打印详细 GC 日志 |
PrintGCDateStamps | 系统时间,更加可读,PrintGCTimeStamps 是 JVM 启动时间 |
PrintGCApplicationStoppedTime | 打印 STW 时间 |
PrintTenuringDistribution | 打印对象年龄分布,对调优 MaxTenuringThreshold 参数帮助很大 |
loggc | 将以上 GC 内容输出到文件中 |
| 参数配置说明 | 意义 |
| HeapDumpOnOutOfMemoryError | OOM 时 Dump 信息,非常有用 |
| HeapDumpPath | Dump 文件保存路径 |
| ErrorFile | 错误日志存放路径 |
| OmitStackTraceInFastThrow | 缩减日志输出 |
其中OmitStackTraceInFastThrow用于缩减日志输出,例如如果发生了多次空指针异常,就会打印如下类型信息
java.lang.NullPointerException
java.lang.NullPointerException
java.lang.NullPointerException
java.lang.NullPointerException
在实际生产环境中默认开启,就会导致排查问题非常不方便。如果关闭的话就会输出所有的异常堆栈,日志会特别的多。
Java13版本
从 Java 9 开始,移除了 40 多个 GC 日志相关的参数。具体参见 JEP 158。所以这部分的日志配置有很大的变化。
#!/bin/sh
LOG_DIR="/tmp/logs"
JAVA_OPT_LOG=" -verbose:gc"
JAVA_OPT_LOG="${JAVA_OPT_LOG} -Xlog:gc,gc+ref=debug,gc+heap=debug,gc+age=trace:file=${LOG_DIR}/gc_%p.log:tags,uptime,time,level"
JAVA_OPT_LOG="${JAVA_OPT_LOG} -Xlog:safepoint:file=${LOG_DIR}/safepoint_%p.log:tags,uptime,time,level"
JAVA_OPT_OOM=" -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=${LOG_DIR} -XX:ErrorFile=${LOG_DIR}/hs_error_pid%p.log "
JAVA_OPT="${JAVA_OPT_LOG} ${JAVA_OPT_OOM}"
JAVA_OPT="${JAVA_OPT} -XX:-OmitStackTraceInFastThrow"
echo $JAVA_OPT
# 合并一行展示
-verbose:gc -Xlog:gc,gc+ref=debug,gc+heap=debug,gc+age=trace:file
=/tmp/logs/gc_%p.log:tags,uptime,time,level -Xlog:safepoint:file=/tmp
/logs/safepoint_%p.log:tags,uptime,time,level -XX:+HeapDumpOnOutOfMemoryError
-XX:HeapDumpPath=/tmp/logs -XX:ErrorFile=/tmp/logs/hs_error_pid%p.log
-XX:-OmitStackTraceInFastThrow
对比以前的版本,GC日志的打印方式参数规整了许多。除了GC日志的输出,也输出了safepoint日志信息
safepoint 是 JVM 中非常重要的一个概念,指的是可以安全地暂停线程的点。当发生 GC 时,用户线程必须全部停下来,才可以进行垃圾回收,这个状态可以认为 JVM 是安全的(safe),整个堆的状态是稳定的

如果在 GC 前,有线程迟迟进入不了 safepoint,那么整个 JVM 都在等待这个阻塞的线程,会造成了整体 GC 的时间变长。
所以呢,并不是只有 GC 会挂起 JVM,进入 safepoint 的过程也会。
2.GC日志的含义(todo)
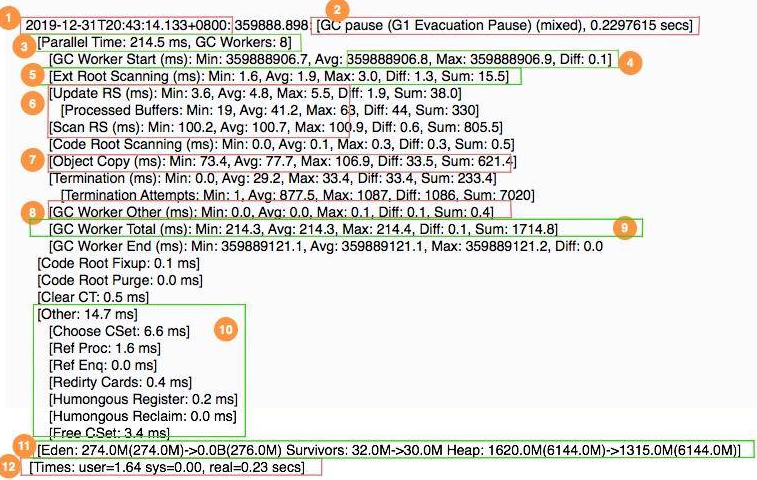
- 1 表示 GC 发生的时间,一般使用可读的方式打印;
- 2 表示日志表明是 G1 的“转移暂停: 混合模式”,停顿了约 223ms;
- 3 表明由 8 个 Worker 线程并行执行,消耗了 214ms;
- 4 表示 Diff 越小越好,说明每个工作线程的速度都很均匀;
- 5 表示外部根区扫描,外部根是堆外区。JNI 引用,JVM 系统目录,Classloaders 等;
- 6 表示更新 RSet 的时间信息;
- 7 表示该任务主要是对 CSet 中存活对象进行转移(复制);
- 8 表示花在 GC 之外的工作线程的时间;
- 9 表示并行阶段的 GC 总时间;
- 10 表示其他清理活动;
- 11表示收集结果统计;
- 12 表示时间花费统计
GC日志描述了垃圾回收器过程中的几乎每一个阶段。但即使了解了这些数值的意义,在分析问题时也会感到吃力,一般使用图形化的分析工具进行分析
结合最后一行数据来看,GC消耗的时间涉及到3个数值(可以在linux环境输入指令time ls /查看结果进行分析)
- real 实际花费的时间,指的是从开始到结束所花费的时间。比如进程在等待 I/O 完成,这个阻塞时间也会被计算在内;
- user 指的是进程在用户态(User Mode)所花费的时间,只统计本进程所使用的时间,注意是指多核;
- sys 指的是进程在核心态(Kernel Mode)花费的 CPU 时间量,指的是内核中的系统调用所花费的时间,只统计本进程所使用的时间
结合上述GC日志分析,会发现real < user + sys:因为使用了多核进行垃圾收集,所以实际发生的时间会比(user+sys)少很多,在多核机器上这是很常见的
如果是串行垃圾收集器收集的GC示例(参考:[Times: user=0.29 sys=0.00, real=0.29 secs] ),因为串行垃圾收集器始终只有一个线程在做回收工作,因此实际使用时间=用户时间+系统时间
==思考:统计GC以哪个时间为准?==一般情况下用户只关心系统停顿了多少秒,对实际的影响时间非常感兴趣。至于背后是怎么实现的,是多核还是单核,是用户态还是内核态,它们都不关心,因此选择real字段作为参考
3.GC日志分析
方式1:借助可视化工具(需要经历日志导出、上传、分析,不便于实时跟踪)
todo:可以借助一些在线分析平台(例如gceasy)
方式2:借助JDK命令行工具(jstat指令)
# 指定Java进程ID,指定间隔时间(毫秒)
jstat -gcutil $pid 1000
S0 S1 E O M CCS YGC YGCT FGC FGCT GCT
0.00 0.00 72.03 0.35 54.12 55.72 11122 16.019 0 0.000 16.019
0.00 0.00 95.39 0.35 54.12 55.72 11123 16.024 0 0.000 16.024
0.00 0.00 25.32 0.35 54.12 55.72 11125 16.025 0 0.000 16.025
0.00 0.00 37.00 0.35 54.12 55.72 11126 16.028 0 0.000 16.028
0.00 0.00 60.35 0.35 54.12 55.72 11127 16.028 0 0.000 16.028
如果直接看上面的内容可能会比较迷惑,结合垃圾回收机制图示去理解这些参数所代表的含义
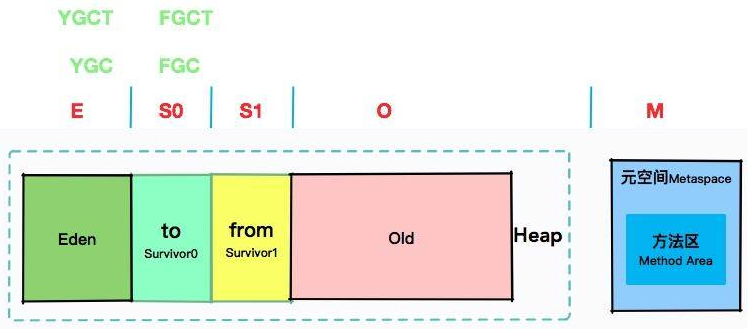
- 年轻代:S0(Survivor0:to)、S1(Survivor1:from)、E:Eden(伊甸空间)、O:老年代、M(元空间:Metaspace)
- YGC:年轻代回收次数;YGCT:年轻代回收耗时
- FGC:Full GC次数;FGCT:Full GC回收耗时
jstat配置说明:常用的有 gc、gcutil、gccause、gcnew 等,其他的可简单了解
- gc: 显示和 GC 相关的 堆信息;
- gcutil: 显示 垃圾回收信息;
- gccause: 显示垃圾回收 的相关信息(同 -gcutil),同时显示 最后一次 或 当前 正在发生的垃圾回收的 诱因;
- gcnew: 显示 新生代 信息;
- gccapacity: 显示 各个代 的 容量 以及 使用情况;
- gcmetacapacity: 显示 元空间 metaspace 的大小;
- gcnewcapacity: 显示 新生代大小 和 使用情况;
- gcold: 显示 老年代 和 永久代 的信息;
- gcoldcapacity: 显示 老年代 的大小;
- printcompilation: 输出 JIT 编译 的方法信息;
- class: 显示 类加载 ClassLoader 的相关信息;
- compiler: 显示 JIT 编译 的相关信息;
如果GC的问题特别明显,可以通过jstat快速发现,例如在命令行中指定参数-t,则可输出从程序启动到现在的时间。如果 FGC 和启动时间的比值太大,就证明系统的吞吐量比较小,GC 花费的时间太多了。另外,如果老年代在 Full GC 之后,没有明显的下降,那可能内存已经达到了瓶颈,或者有内存泄漏问题
参考命令:在基命令基础上追加GC时间的增量和GC时间比率
jstat -gcutil -t 90542 1000 | awk 'BEGIN{pre=0}{if(NR>1) {print $0 "\t" ($12-pre) "\t" $12*100/$1 ; pre=$12 } else { print $0 "\tGCT_INC\tRate"} }'
Timestamp S0 S1 E O M CCS YGC YGCT FGC FGCT GCT GCT_INC Rate
18.7 0.00 100.00 6.02 1.45 84.81 76.09 1 0.002 0 0.000 0.002 0.002 0.0106952
19.7 0.00 100.00 6.02 1.45 84.81 76.09 1 0.002 0 0.000 0.002 0 0.0101523
4.GC日志"捣蛋"场景
ElasticSearch 的速度是非常快的,我们为了压榨它的性能,对磁盘的读写几乎是全速的。它在后台做了很多 Merge 动作,将小块的索引合并成大块的索引。还有 TransLog 等预写动作,都是 I/O 大户。
使用 iostat -x 1 可以看到具体的 I/O 使用状况。
现有场景:有一套 ES 集群,在访问高峰时,有多个 ES 节点发生了严重的 STW 问题。有的节点竟停顿了足足有 7~8 秒。
[Times: user=0.42 sys=0.03, real=7.62 secs]
从日志可以看到在 GC 时用户态只停顿了 420ms,但真实的停顿时间却有 7.62 秒。盘点一下资源,唯一超额利用的可能就是 I/O 资源了(%util 保持在 90 以上),GC 可能在等待 I/O
这种情况是真实存在的,其原因就在于,写 GC 日志的 write 动作,是统计在 STW 的时间里的。在已有的场景中,由于 ES 的索引数据,和 GC 日志放在了一个磁盘,GC 时写日志的动作,就和写数据文件的动作产生了资源争用。
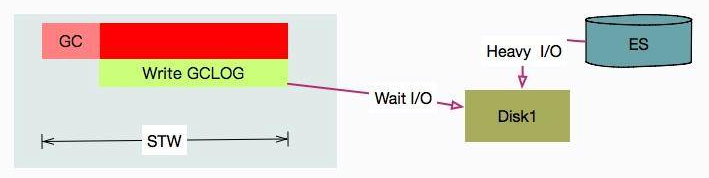
解决方案:把 ES 的日志文件,单独放在一块普通 HDD 磁盘上就可以了
CPU 100%问题排查
1.命令行方式
CPU飙升问题排查一般有相应的步骤,按照这个步骤去定位相应的问题(案例可参考**【JVM-JVM排查实践之GC篇】**,分析现实场景中是如何一步步排查定位JVM问题)
👻参考步骤说明(todo:具体案例分析)
| 步骤 | 说明 |
|---|---|
【1】top | 查看每个进程的CPU占用情况 |
【2】top -Hp $pid | 查看指定进程中CPU占用最高的线程(确认CPU占用最高的线程PID) |
【3】jstack pid > out.log | 保存线程的堆栈信息(通过jstack指令将占用CPU最高的线程的堆栈信息并进行保存、分析) 该指令将某个进程的堆栈信息输出到out.log文件中 |
| 【4】分析线程栈信息 | 转化:先将CPU占用最高的线程的PID转化为16进制 检索:随后在步骤3中输出的堆栈信息日志文件之进行检索,分析其堆栈信息 分析:跟踪线程名称、线程状态 |
jstack用于生成 Java 进程的线程快照(thread dump)。线程快照是一个关于 Java 进程中所有线程当前状态的快照,包括每个线程的堆栈信息。通过分析线程快照,可以了解 Java 进程中各个线程的运行状态、锁信息等
问题排查定位思路
- 如果cpu使用率上涨,用jstack查看cpu占用最高的线程,确认线程在跑什么代码
- 如果是GC线程,则进一步跟踪GC曲线是否正常(进行GC排查)
- 正常情况:看堆内存曲线,正常的曲线是锯齿形的
- 异常情况:一次full GC之后内存没有明显下降,基本可以推断发生内存泄漏了
- 如果怀疑是内存泄漏的问题,可通过jmap进行分析:
- 分析1:
jmap -heap $pid查看堆内存占用情况 - 分析2:
jmap -histo[:live] pid)查看具体的堆内存对象(分析存活对象数量和内存占用情况) - 分析3:使用
jamp dump文件,并拉到MAT等工具进行分析
- 分析1:
- 如果怀疑是内存泄漏的问题,可通过jmap进行分析:
2.Arthas(todo)
Arthas 是阿里开源的一款线上监控诊断产品,通过全局视角实时查看应用 load、内存、gc、线程的状态信息,并能在不修改应用代码的情况下,对业务问题进行诊断,包括查看方法调用的出入参、异常,监测方法执行耗时,类加载信息等,大大提升线上问题排查效率。
用 Arthas 查找占用 CPU 最高的方法只是一个开胃小菜,除此之外,它最大的用途是在不改代码、不重启服务的情况下对程序进行动态监控。如果你碰到了线上诡异问题,可以用 Arthas 尝试找一找问题,开阔眼界。(用 Arthas 达到前面用 jstack 同样的目的)
Arthas安装(jar:下载、启动)
# 下载jar
curl -O https://arthas.aliyun.com/arthas-boot.jar
# 启动
java -jar arthas-boot.jar
启动之后,会列出当前这台服务器上的所有 Java 进程,然后选择要排查的那个服务即可
系统排查
参考学习资料:https://mp.weixin.qq.com/s/Ue1HMTAWD5YaV7l5g1g5-w
https://afghl.github.io/2017/09/16/production-cpu-100-tracing.html
死锁问题排查
1.死锁概念
死锁是一种特定的程序状态,在实体之间,由于循环依赖导致彼此一直处于等待之中,没有任何个体可以继续前进。死锁不仅仅是在线程之间会发生,存在资源独占的进程之间同样也可能出现死锁。通常来说,大多是聚焦在多线程场景中的死锁,指两个或多个线程之间,由于互相持有对方需要的锁,而永久处于阻塞的状态。
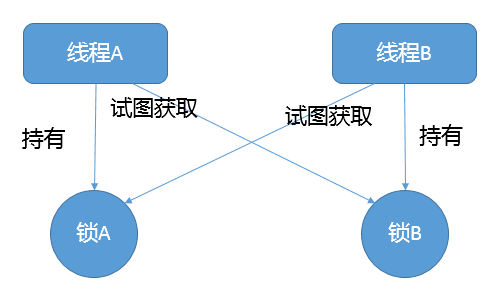
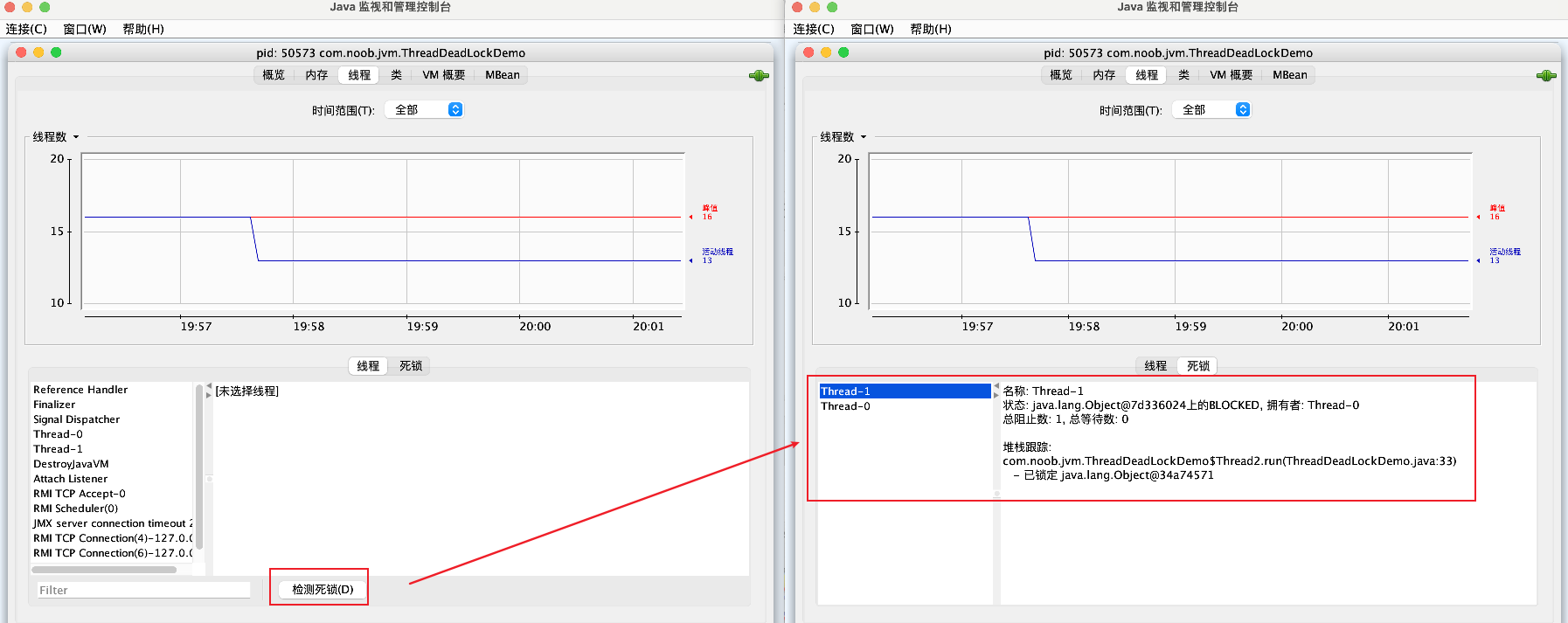
定位死锁最常见的方式就是利用jstack等工具获取线程栈,然后定位互相之间的依赖关系,进而找到死锁。如果是比较明显的死锁,往往jstack等就能直接定位,类似JConsole甚至可以在图形界面进行有限的死锁检测。
如果程序运行时发生了死锁,绝大多数情况下都是无法在线解决的,只能重启、修正程序本身问题。所以,代码开发阶段互相审查,或者利用工具进行预防性排查,往往也是很重要的
大部分死锁本身并不难定位,掌握基本思路和工具使用,理解线程相关的基本概念(各种线程状态和同步、锁、Latch等并发工具)来应对死锁场景。常见的死锁考察思路:
- 抛开字面上的概念,手撕一个可能死锁的程序:死锁概念、基本的线程编程
- 诊断死锁有哪些工具,如果是分布式环境,可能更关心能否用API实现吗?
- 如何在编程中尽量避免一些典型场景的死锁,有其他工具辅助吗?
案例分析1:死锁程序(两个嵌套的synchronized获取锁)
(1)死锁场景模拟
/**
* 死锁案例场景
*/
public class DeadLockDemo extends Thread {
private String first;
private String second;
public DeadLockDemo(String threadName,String first, String second) {
super(threadName);
this.first = first;
this.second = second;
}
// 重写run方法
@Override
public void run() {
// 使用synchronized嵌套获取锁
synchronized (first){
System.out.println(this.getName() + "obtained:" + first);
// 模拟等待时长
try {
Thread.sleep(1000L);
// 嵌套Synchronized获取锁
synchronized (second){
System.out.println(this.getName() + "obtained:" + second );
}
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
}
// 死锁测试
public static void main(String[] args) throws InterruptedException {
String lockA = "lockA";
String lockB = "lockB";
Thread threadA = new DeadLockDemo("threadA",lockA,lockB);
Thread threadB = new DeadLockDemo("threadB",lockB,lockA);
// 启动线程
threadA.start();
threadB.start();
threadA.join();
threadB.join();
}
}
// output
threadBobtained:lockB
threadAobtained:lockA
结合上述结果分析如下:
- 虽然线程A优于线程B先启动,但是线程B先执行。这是因为线程的执行依赖于操作系统调度(可设定优先级优先抢占调度资源),但是具体什么时候执行由操作系统决定
- 发生死锁时,程序不会报异常,但是线程会一直处于阻塞状态,都在等待对方释放资源
- 例如此处B先占据锁B,A又占据了锁A,线程B在等到锁A被释放,而线程A又在等到锁B被释放,双方陷入僵持,都希望对方先释放资源自己才能执行完成(即互相持有对方需要的锁而无法释放,线程永久阻塞)
(2)死锁排查:jstack
排查思路:选择jstack进行排查
- 【步骤1】利用jps或者系统的ps命令、任务管理器等工具确认进程ID
# 使用jps获取当前正在执行的java进程
24291 Main
25627 Jps
25230 Launcher
25231 DeadLockDemo
- 【步骤2】使用jstack获取线程栈信息(treminal对应系统环境JDK为17)
# 使用jstack获取线程栈信息(jstack $pid)
jstack 25321
// output
Full thread dump OpenJDK 64-Bit Server VM (25.412-b08 mixed mode):
"Attach Listener" #15 daemon prio=9 os_prio=31 tid=0x00007f7dd782c800 nid=0x6c03 waiting on condition [0x0000000000000000]
java.lang.Thread.State: RUNNABLE
"threadB" #14 prio=5 os_prio=31 tid=0x00007f7db6814000 nid=0x7003 waiting for monitor entry [0x000000030f483000]
java.lang.Thread.State: BLOCKED (on object monitor)
at com.noob.jvm.DeadLockDemo.run(DeadLockDemo.java:27)
- waiting to lock <0x000000071573d680> (a java.lang.String)
- locked <0x000000071573d6b8> (a java.lang.String)
"threadA" #13 prio=5 os_prio=31 tid=0x00007f7db6813000 nid=0x714b waiting for monitor entry [0x000000030f380000]
java.lang.Thread.State: BLOCKED (on object monitor)
at com.noob.jvm.DeadLockDemo.run(DeadLockDemo.java:27)
- waiting to lock <0x000000071573d6b8> (a java.lang.String)
- locked <0x000000071573d680> (a java.lang.String)
"Service Thread" #12 daemon prio=9 os_prio=31 tid=0x00007f7dd6818800 nid=0x7507 runnable [0x0000000000000000]
java.lang.Thread.State: RUNNABLE
"C1 CompilerThread3" #11 daemon prio=9 os_prio=31 tid=0x00007f7dd6817800 nid=0x6103 waiting on condition [0x0000000000000000]
java.lang.Thread.State: RUNNABLE
"C2 CompilerThread2" #10 daemon prio=9 os_prio=31 tid=0x00007f7dd681c800 nid=0x6003 waiting on condition [0x0000000000000000]
java.lang.Thread.State: RUNNABLE
"C2 CompilerThread1" #9 daemon prio=9 os_prio=31 tid=0x00007f7d97012000 nid=0x7a03 waiting on condition [0x0000000000000000]
java.lang.Thread.State: RUNNABLE
"C2 CompilerThread0" #8 daemon prio=9 os_prio=31 tid=0x00007f7d97010800 nid=0x5e0f waiting on condition [0x0000000000000000]
java.lang.Thread.State: RUNNABLE
"JDWP Command Reader" #7 daemon prio=10 os_prio=31 tid=0x00007f7dd6817000 nid=0x5c03 runnable [0x0000000000000000]
java.lang.Thread.State: RUNNABLE
"JDWP Event Helper Thread" #6 daemon prio=10 os_prio=31 tid=0x00007f7da6831000 nid=0x5903 runnable [0x0000000000000000]
java.lang.Thread.State: RUNNABLE
"JDWP Transport Listener: dt_socket" #5 daemon prio=10 os_prio=31 tid=0x00007f7dd883c800 nid=0x7d0b runnable [0x0000000000000000]
java.lang.Thread.State: RUNNABLE
"Signal Dispatcher" #4 daemon prio=9 os_prio=31 tid=0x00007f7dd781a000 nid=0x7e03 runnable [0x0000000000000000]
java.lang.Thread.State: RUNNABLE
"Finalizer" #3 daemon prio=8 os_prio=31 tid=0x00007f7dd8008800 nid=0x511f in Object.wait() [0x000000030e751000]
java.lang.Thread.State: WAITING (on object monitor)
at java.lang.Object.wait(Native Method)
- waiting on <0x0000000715588f00> (a java.lang.ref.ReferenceQueue$Lock)
at java.lang.ref.ReferenceQueue.remove(ReferenceQueue.java:144)
- locked <0x0000000715588f00> (a java.lang.ref.ReferenceQueue$Lock)
at java.lang.ref.ReferenceQueue.remove(ReferenceQueue.java:165)
at java.lang.ref.Finalizer$FinalizerThread.run(Finalizer.java:188)
"Reference Handler" #2 daemon prio=10 os_prio=31 tid=0x00007f7d9700a800 nid=0x4323 in Object.wait() [0x000000030e64e000]
java.lang.Thread.State: WAITING (on object monitor)
at java.lang.Object.wait(Native Method)
- waiting on <0x0000000715586b98> (a java.lang.ref.Reference$Lock)
at java.lang.Object.wait(Object.java:502)
at java.lang.ref.Reference.tryHandlePending(Reference.java:191)
- locked <0x0000000715586b98> (a java.lang.ref.Reference$Lock)
at java.lang.ref.Reference$ReferenceHandler.run(Reference.java:153)
"main" #1 prio=5 os_prio=31 tid=0x00007f7dd7809800 nid=0x2303 in Object.wait() [0x000000030db2d000]
java.lang.Thread.State: WAITING (on object monitor)
at java.lang.Object.wait(Native Method)
- waiting on <0x000000071573d6f0> (a com.noob.jvm.DeadLockDemo)
at java.lang.Thread.join(Thread.java:1257)
- locked <0x000000071573d6f0> (a com.noob.jvm.DeadLockDemo)
at java.lang.Thread.join(Thread.java:1331)
at com.noob.jvm.DeadLockDemo.main(DeadLockDemo.java:44)
"VM Thread" os_prio=31 tid=0x00007f7da6830000 nid=0x4203 runnable
"GC task thread#0 (ParallelGC)" os_prio=31 tid=0x00007f7dd880c000 nid=0x3a0b runnable
"GC task thread#1 (ParallelGC)" os_prio=31 tid=0x00007f7dd880d000 nid=0x3903 runnable
"GC task thread#2 (ParallelGC)" os_prio=31 tid=0x00007f7dd880d800 nid=0x3703 runnable
"GC task thread#3 (ParallelGC)" os_prio=31 tid=0x00007f7dd880e800 nid=0x2e03 runnable
"GC task thread#4 (ParallelGC)" os_prio=31 tid=0x00007f7dd880f000 nid=0x3003 runnable
"GC task thread#5 (ParallelGC)" os_prio=31 tid=0x00007f7dd8810000 nid=0x3203 runnable
"GC task thread#6 (ParallelGC)" os_prio=31 tid=0x00007f7dd8810800 nid=0x3303 runnable
"GC task thread#7 (ParallelGC)" os_prio=31 tid=0x00007f7dd8811800 nid=0x4003 runnable
"GC task thread#8 (ParallelGC)" os_prio=31 tid=0x00007f7dd8812000 nid=0x4103 runnable
"VM Periodic Task Thread" os_prio=31 tid=0x00007f7dd6819800 nid=0x7403 waiting on condition
JNI global references: 1496
Found one Java-level deadlock:
=============================
"threadB":
waiting to lock monitor 0x00007f7d9680f748 (object 0x000000071573d680, a java.lang.String),
which is held by "threadA"
"threadA":
waiting to lock monitor 0x00007f7d9680f8a8 (object 0x000000071573d6b8, a java.lang.String),
which is held by "threadB"
Java stack information for the threads listed above:
===================================================
"threadB":
at com.noob.jvm.DeadLockDemo.run(DeadLockDemo.java:27)
- waiting to lock <0x000000071573d680> (a java.lang.String)
- locked <0x000000071573d6b8> (a java.lang.String)
"threadA":
at com.noob.jvm.DeadLockDemo.run(DeadLockDemo.java:27)
- waiting to lock <0x000000071573d6b8> (a java.lang.String)
- locked <0x000000071573d680> (a java.lang.String)
Found 1 deadlock.
从显示结果分析,堆栈信息很明显指出线程信息、线程状态、代码文件定位等信息。参考图示相同颜色的圈注进行分析:
- 线程B持有锁
0x000000071573d6b8并等待0x000000071573d680锁,线程A持有锁0x000000071573d680并等待0x000000071573d6b8,双方都持有对方需要的锁
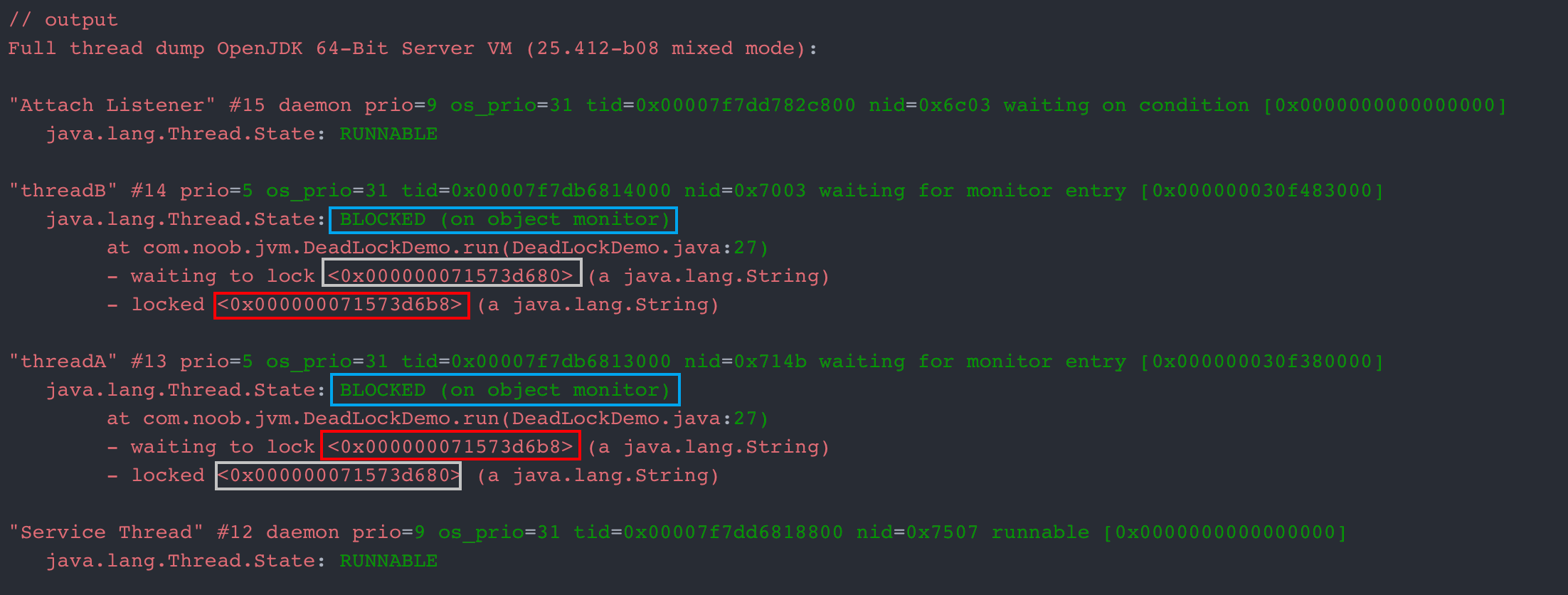
结合上述案例可以通过jstack快速定位死锁问题,但是在实际场景应用中类死锁未必有如此清晰的输出(场景复杂度不一样),但是整体分析思路可以梳理为:区分线程状态=》查看等待目标=》对比Monitor等持有状态。理解线程基本状态和并发相关元素是定位问题的关键,然后配合程序调用栈结构,基本就可以定位到具体的问题代码
(3)死锁排查:程序化方式
如果是开发自己的管理工具,需要用更加程序化的方式扫描服务进程、定位死锁,可以考虑使用Java提供的标准管理API:ThreadMXBean,其直接就提供了findDeadlockedThreads()方法用于定位。在DeadLockDemo基础上构建案例(main中定义方法)如下所示:
// 死锁测试
public static void main(String[] args) throws InterruptedException {
ThreadMXBean mbean = ManagementFactory.getThreadMXBean();
Runnable dlCheck = new Runnable() {
@Override
public void run() {
long[] threadIds = mbean.findDeadlockedThreads();
if (threadIds != null) {
ThreadInfo[] threadInfos = mbean.getThreadInfo(threadIds);
System.out.println("Detected deadlock threads:");
for (ThreadInfo threadInfo : threadInfos) {
System.out.println(threadInfo.getThreadName());
}
}
}
};
ScheduledExecutorService scheduler = Executors.newScheduledThreadPool(1);
// 稍等5秒,然后每10秒进行一次死锁扫描
scheduler.scheduleAtFixedRate(dlCheck, 5L, 10L, TimeUnit.SECONDS);
// ---------- 死锁样例代码 ----------
String lockA = "lockA";
String lockB = "lockB";
Thread threadA = new DeadLockDemo("threadA",lockA,lockB);
Thread threadB = new DeadLockDemo("threadB",lockB,lockA);
// 启动线程
threadA.start();
threadB.start();
threadA.join();
threadB.join();
}
// output
threadAobtained:lockA
threadBobtained:lockB
Detected deadlock threads:
threadB
threadA
Detected deadlock threads:
threadB
threadA
Detected deadlock threads:
threadB
threadA
重新编译执行,周期性地进行死锁扫描,可以看到死锁被定位并输出。在实际应用中,就可以据此收集进一步的信息,然后进行预警等后续处理。但是要注意的是,对线程进行快照本身是一个相对重量级的操作,还是要慎重选择频度和时机
2.死锁预防
首先分析例子中死锁的产生包含哪些基本元素。基本上死锁的发生是因为:
- 互斥条件,类似Java中Monitor都是独占的,要么是我用,要么是你用
- 互斥条件是长期持有的,在使用结束之前,自己不会释放,也不能被其他线程抢占
- 循环依赖关系,两个或者多个个体之间出现了锁的链条环
可以据此分析可能的避免死锁的思路和方法
方法1:尽可能避免使用多个锁,并且只有需要时才持有锁
尽量避免使用多个锁,并且只有需要时才持有锁。否则,即使是非常精通并发编程的工程师,也难免会掉进坑里,嵌套的synchronized或者lock非常容易出问题。
一个JDK改进死锁例子, Java NIO的实现代码向来以锁多著称,一个原因是,其本身模型就非常复杂,某种程度上是不得不如此;另外是在设计时,考虑到既要支持阻塞模式,又要支持非阻塞模式。直接结果就是,一些基本操作如connect,需要操作三个锁以上,在其中一个JDK改进中,就发生了死锁现象。简化伪代码如下,分析其栈信息
// Thread HttpClient-6-SelectorManager: 持有readLock/writeLock
readLock.lock();
writeLock.lock();
// 调用close()试图获得closeLock
close();
// Thread HttpClient-6-Worker-2 持有closeLock
implCloseSelectableChannel (); //想获得readLock
在close发生时, HttpClient-6-SelectorManager线程持有readLock/writeLock,试图获得closeLock;与此同时,另一个HttpClient-6-Worker-2线程,持有closeLock,试图获得readLock,这就不可避免地进入了死锁。简单来说线程1一开始持有锁A、锁B,在调用close方法的时候试图获取锁C,但是与此同时线程2持有锁C,且试图获取锁A,双方互相占用对方所需要的锁,因此不可避免进入死锁。结合官方案例的线程栈信息

参考线程栈的死锁说明
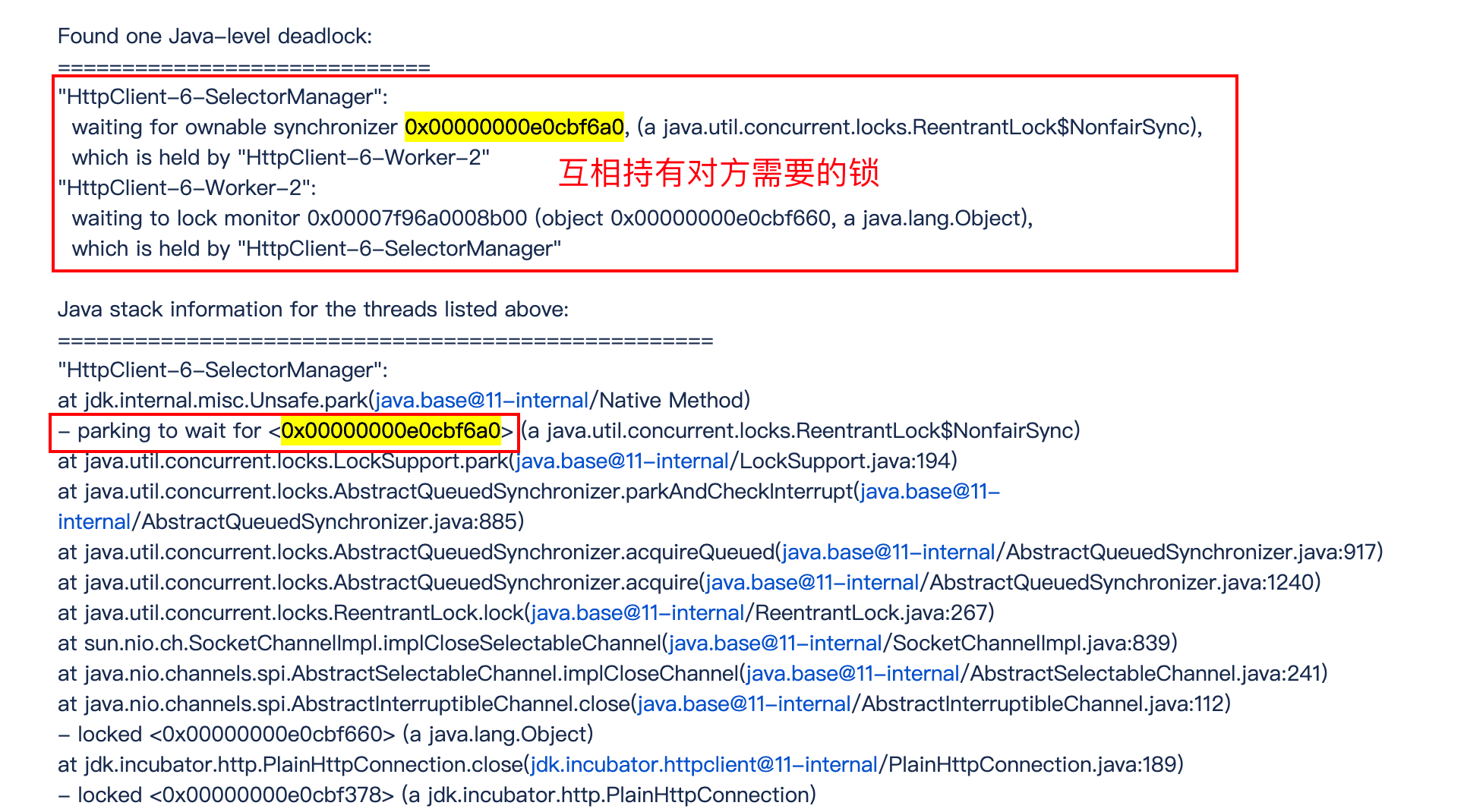
结合上述线程栈信息提示,可以跟踪到具体代码的实现:查看SocketChannelImpl的663行,对比implCloseSelectableChannel()方法实现和AbstractInterruptibleChannel.close()在109行的代码。即调用close方法需要获取到closeLock

从程序设计的角度反思,如果赋予一段程序太多的职责,出现“既要…又要…”的情况时,可能就需要重新审视下设计思路或目的是否合理了。对于类库,因为其基础、共享的定位,比应用开发往往更加令人苦恼,需要仔细斟酌之间的平衡。
方法2:如果必须使用多个锁,必须设计好锁的获取顺序
扩展:理解银行家算法
如果必须使用多个锁,必须设计好锁的获取顺序,但实践起来往往比较复杂,参考银行家算法。一般情况下,可以考虑才去一些简单的辅助手段,例如以图示的方式进行分析,以前面的DeadLockDemo为例,其分析步骤如下所示
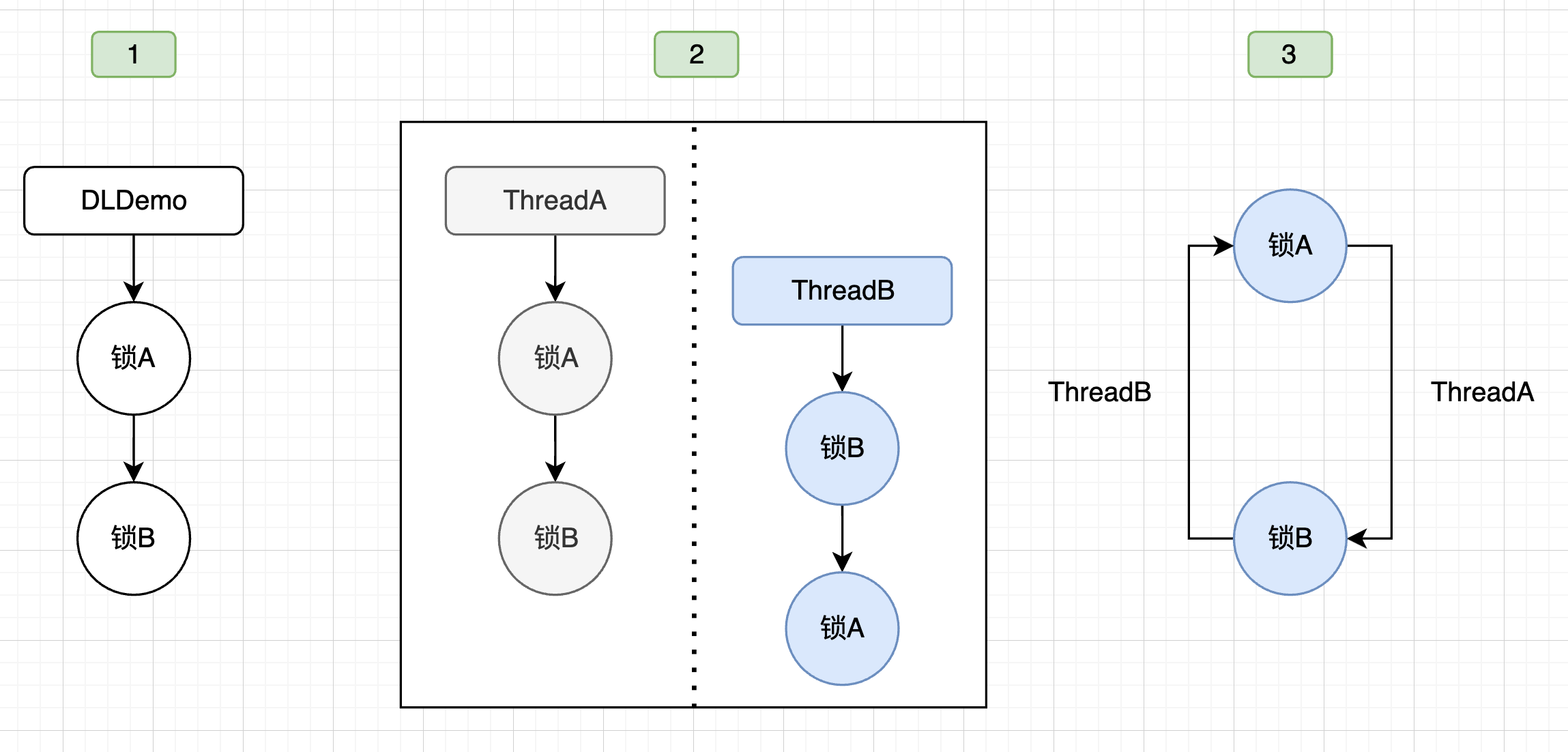
【步骤1】抽离对象(方法)和锁的关系(用图形化的方式进行展示)
【步骤2】根据对象之间组合、调用的关系对比,考虑调用时序
【步骤3】按照可能时序进行合并,发现可能死锁的场景
方法3:超时处理
使用带超时的方法,为程序带来更多可控性。
类似Object.wait(…)或者CountDownLatch.await(…),都支持所谓的timed_wait,完全可以就不假定该锁一定会获得,指定超时时间,并为无法得到锁时准备退出逻辑。
并发Lock实现,如ReentrantLock还支持非阻塞式的获取锁操作tryLock(),这是一个插队行为(barging),并不在乎等待的公平性,如果执行时对象恰好没有被独占,则直接获取锁。有时,如果希望条件允许就尝试插队,不然就按照现有公平性规则等待,一般采用下面的方法:
if (lock.tryLock() || lock.tryLock(timeout, unit)) {
// ...
}
方法4:其他方式
也有一些其他方面的尝试,比如通过静态代码分析(如FindBugs)去查找固定的模式,进而定位可能的死锁或者竞争情况。实践证明这种方法也有一定作用,请参考相关文档
除了典型应用中的死锁场景,其实还有一些更令人头疼的死锁,比如类加载过程发生的死锁,尤其是在框架大量使用自定义类加载时,因为往往不是在应用本身的代码库中,jstack等工具也不见得能够显示全部锁信息,所以处理起来比较棘手。对此,Java有官方文档进行了详细解释,并针对特定情况提供了相应JVM参数和基本原则
概念扩展
JVM内部线程
启动一个简单的“Hello World”示例程序,也会在 Java 进程中创建几十号线程,这几十个线程主要是 JVM 内部线程,以及 Lib 相关的线程(例如引用处理器、终结者线程等等)
JVM 内部线程主要分为以下几种:
- VM 线程:单例的 VMThread 对象,负责执行 VM 操作,下文将对此进行讨论;
- 定时任务线程:单例的 WatcherThread 对象,模拟在 VM 中执行定时操作的计时器中断;
- GC 线程:垃圾收集器中,用于支持并行和并发垃圾回收的线程;
- 编译器线程:将字节码编译为本地机器代码;
- 信号分发线程:等待进程指示的信号,并将其分配给 Java 级别的信号处理方法。
JVM 中的所有线程都是 Thread 实例,而所有执行 Java 代码的线程都是(Thread 的子类)JavaThread 的实例
JVM 在链表 Threads_list 中跟踪所有线程,并使用 Threads_lock 来保护(这是 JVM 内部使用的一个核心同步锁)
1.线程转储
线程转储(简而言之,线程转储就是线程快照)
线程转储(Thread Dump)是 JVM 中所有线程状态的快照。一般是文本格式,可以将其保存到文本文件中,然后可以人工查看和分析,也可以通过程序自动分析。
每个线程的状态都可以通过调用栈来表示(StackTrace方法调用栈)。线程转储展示了各个线程的行为,对于诊断和排查问题非常有用
JVM 支持多种方式来进行线程转储,包括:
- JDK 工具,包括:jstack 工具、jcmd 工具、jconsole、jvisualvm、Java Mission Control 等;
- Shell 命令或者系统控制台, 比如 Linux 的
kill -3、Windows 的Ctrl + Break等; - JMX 技术,主要是使用 ThreadMxBean,可以在程序中嵌入
(1)jstack
一般使用 JDK 自带的命令行工具来获取 Java 应用程序的线程转储(jstack)
# jstack指令用于执行线程转储的。一般连接本地 JVM:
jstack [-F] [-l] [-m] <pid>
# 参考示例(导出指定线程的线程转储信息到指定文件)
jstack 8848 > ./threandump.txt
pid 是指对应的 Java 进程 id,使用时支持如下的选项:
-F选项强制执行线程转储;有时候jstack pid会假死,则可以加上-F标志-l选项,会查找堆内存中拥有的同步器以及资源锁-m选项,额外打印 native 栈帧(C 和 C++ 的)
(2)jcmd
向JVM发送一串命令
jcmd 8248 Thread.print
(3)JMX方式
JMX方式技术支持各种各样的花式操作,可以通过 ThreadMxBean 来线程转储
import java.lang.management.*;
/**
* 线程转储示例
*/
public class JMXDumpThreadDemo {
public static void main(String[] args) {
String threadDump = snapThreadDump();
System.out.println("=================");
System.out.println(threadDump);
}
public static String snapThreadDump() {
StringBuffer threadDump = new StringBuffer(System.lineSeparator());
ThreadMXBean threadMXBean = ManagementFactory.getThreadMXBean();
for (ThreadInfo threadInfo : threadMXBean.dumpAllThreads(true, true)) {
threadDump.append(threadInfo.toString());
}
return threadDump.toString();
}
}
// output
=================
"JDWP Command Reader" Id=7 RUNNABLE (in native)
"JDWP Event Helper Thread" Id=6 RUNNABLE
"JDWP Transport Listener: dt_socket" Id=5 RUNNABLE
"Signal Dispatcher" Id=4 RUNNABLE
"Finalizer" Id=3 WAITING on java.lang.ref.ReferenceQueue$Lock@55f96302
at java.lang.Object.wait(Native Method)
- waiting on java.lang.ref.ReferenceQueue$Lock@55f96302
at java.lang.ref.ReferenceQueue.remove(ReferenceQueue.java:144)
at java.lang.ref.ReferenceQueue.remove(ReferenceQueue.java:165)
at java.lang.ref.Finalizer$FinalizerThread.run(Finalizer.java:188)
"Reference Handler" Id=2 WAITING on java.lang.ref.Reference$Lock@3d4eac69
at java.lang.Object.wait(Native Method)
- waiting on java.lang.ref.Reference$Lock@3d4eac69
at java.lang.Object.wait(Object.java:502)
at java.lang.ref.Reference.tryHandlePending(Reference.java:191)
at java.lang.ref.Reference$ReferenceHandler.run(Reference.java:153)
"main" Id=1 RUNNABLE
at sun.management.ThreadImpl.dumpThreads0(Native Method)
at sun.management.ThreadImpl.dumpAllThreads(ThreadImpl.java:496)
at sun.management.ThreadImpl.dumpAllThreads(ThreadImpl.java:484)
at com.noob.jvm.JMXDumpThreadDemo.snapThreadDump(JMXDumpThreadDemo.java:16)
at com.noob.jvm.JMXDumpThreadDemo.main(JMXDumpThreadDemo.java:9)
线程dump结果:简单分析上述线程栈信息
- JDWP 相关的线程
- Signal Dispatcher,将操作系统信号(例如
kill -3)分发给不同的处理器进行处理,也可以在程序中注册自己的信号处理器 - Finalizer,终结者线程,处理 finalize 方法进行资源释放
- Reference Handler,引用处理器
- main,这是主线程,属于前台线程,本质上和普通线程没什么区别
- 如果程序运行时间比较长,除了业务线程之外还会有一些GC线程
2.死锁案例
参考前面的死锁案例(和下面的案例类似),实际上实现逻辑就是:两个锁获取的顺序不同、两个线程都在死等对方的资源,可以设计一个死锁案例,思路如下:
- 定义两个锁(Object)
- 分别定义两个线程:t1、t2
- 线程t1的run方法:先获取锁A,然后获取锁B
- 线程t2的run方法:先获取锁B,然后获取锁A
- main方法中分别启动这两个线程然后查看死锁情况
/**
* 线程死锁Demo
*/
public class ThreadDeadLockDemo {
// 定义锁
private static Object lockA = new Object();
private static Object lockB = new Object();
public static class Thread1 extends Thread{
@Override
public void run() {
synchronized (lockA){
System.out.println(Thread.currentThread().getName() + "占据了锁A");
synchronized (lockB){
System.out.println(Thread.currentThread().getName() + "占据了锁B");
}
}
}
}
public static class Thread2 extends Thread{
@Override
public void run() {
synchronized (lockB){
System.out.println(Thread.currentThread().getName() + "占据了锁B");
synchronized (lockA){
System.out.println(Thread.currentThread().getName() + "占据了锁A");
}
}
}
}
public static void main(String[] args) {
Thread1 t1 = new Thread1();
Thread2 t2 = new Thread2();
t1.start();
t2.start();
}
}
// output
Thread-1占据了锁B
Thread-0占据了锁A
启动程序,然后可以通过命令行工具转储线程栈信息
- jps查看当前Java进程
- jstack $pid:转储线程栈信息
- jcmd $pid:转出线程栈信息到指定文件
3.可视化工具
jconsole可视化工具
jconsole:参考学习文章,此处以mac进行演示
(1)死锁案例分析
【1】输入jconsole指令,弹出窗口(本地进程:类似jps效果,获取到当前的Java进程)
【2】选择本地进程,进入分析页面
【3】确认要分析的进程,点击进入,分析内容
Tab页面:概述、内存、线程、类、VM概要、Mbean
- 内存Tab等价于可视化的jstat命令
- 线程Tab等价于可视化的jstack命令
【4】选择【线程Tab】,检查死锁
(2)案例场景
案例1:模拟按照一定速率向堆中填充数据,借助jconsole工具查看内存变化
案例2:线程监控
线程监控相当于可视化的jstack,遇到线程停顿的时候,可以使用它来监控。 线程长时间停顿的主要原因:等待外部资源(数据库连接、网络资源、设备资源等)、死循环、锁等待。
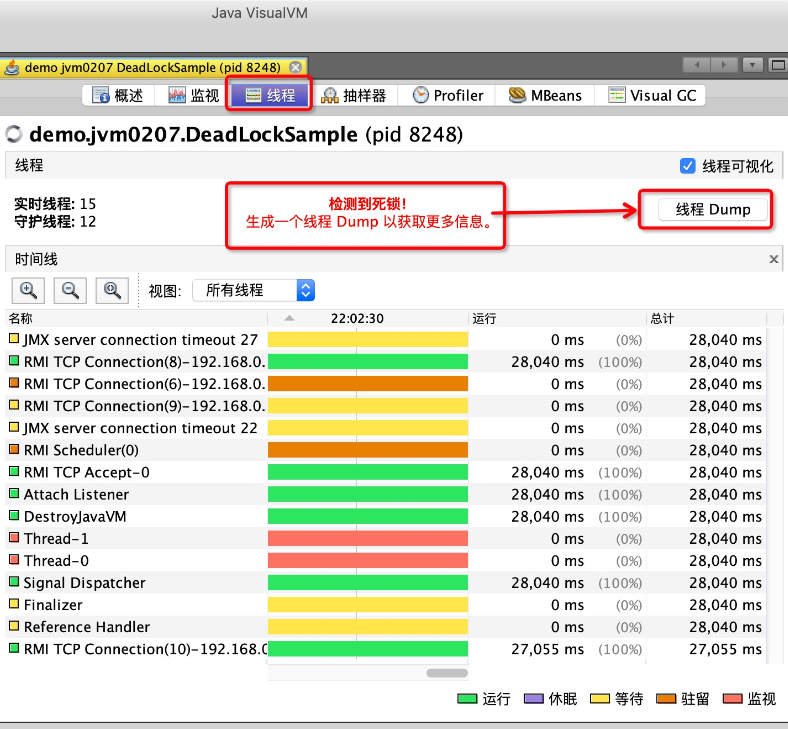
Java Visual VM