【JAVA】集合框架
【JAVA】集合框架
学习核心
- 基础知识
学习资料
todo:Map、Set、Queue 学习
常用数据结构
数组:采用一段连续的存储单元来存储数据。对于指定下标的查找,时间复杂度为 O(1),但在数组中间以及头部插入数据时,需要复制移动后面的元素
链表:一种在物理存储单元上非连续、非顺序的存储结构,数据元素的逻辑顺序是通过链表中的指针链接次序实现的。
链表由一系列结点(链表中每一个元素)组成,结点可以在运行时动态生成。每个结点都包含“存储数据单元的数据域”和“存储下一个结点地址的指针域”这两个部分。
由于链表不用必须按顺序存储,所以链表在插入的时候可以达到 O(1) 的复杂度,但查找一个结点或者访问特定编号的结点需要 O(n) 的时间
哈希表:根据关键码值(Key value)直接进行访问的数据结构。通过把关键码值映射到表中一个位置来访问记录,以加快查找的速度。这个映射函数叫做哈希函数,存放记录的数组就叫做哈希表
树:由 n(n≥1)个有限结点组成的一个具有层次关系的集合,就像是一棵倒挂的树
集合概念
为了规范容器的行为,统一设计,JCF定义了15中容器接口(Collection Interfaces),关系说明如图所示
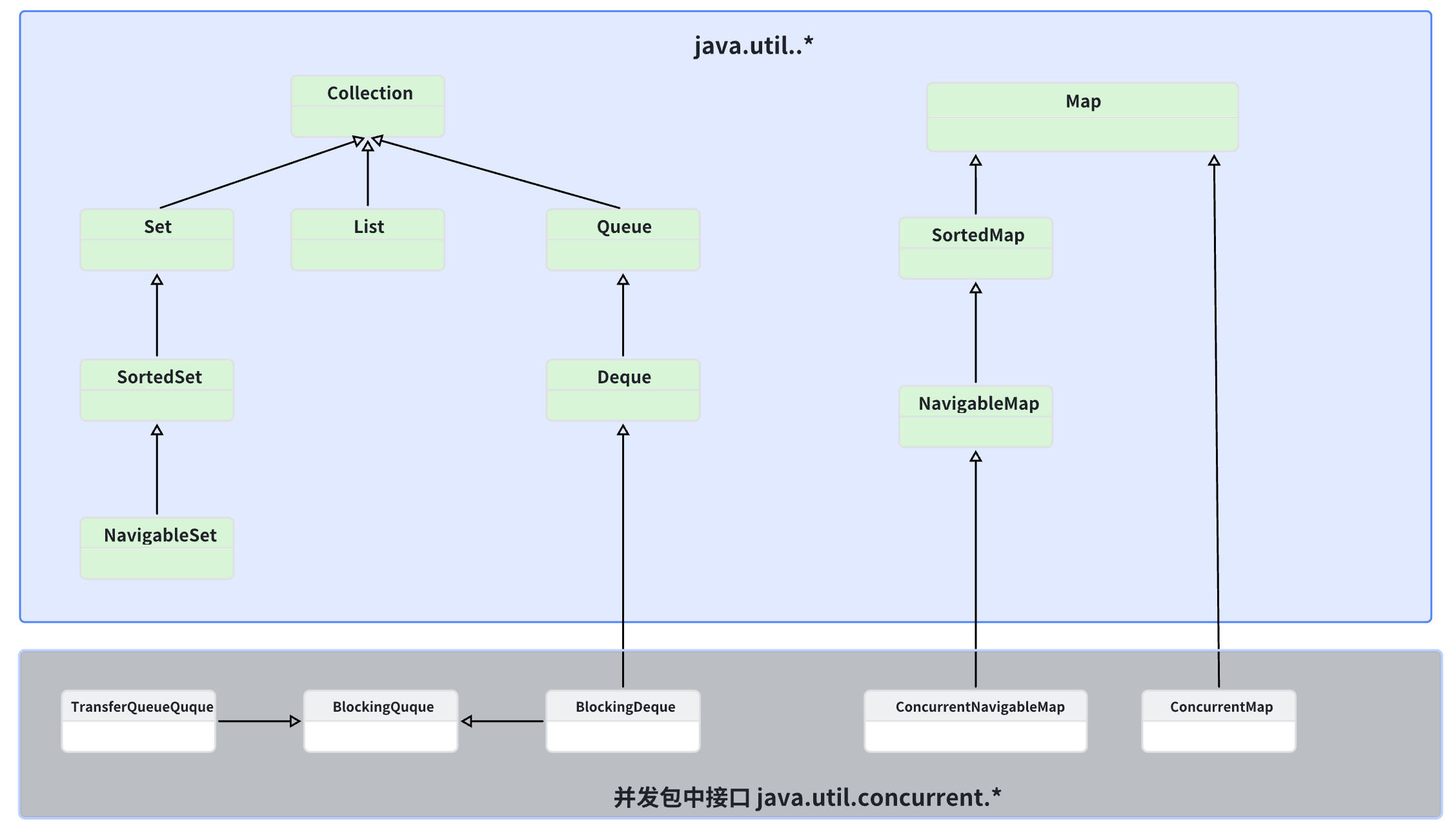
容器主要包括Collection和Map两大分类:
- Collection:存储对象集合
- Map:存储键值对的映射表(两个对象:key、value)
Map接口没有继承自Collection接口,因为Map表示的是关联式容器而不是集合,但是Java提供了从Map到Collection转化的方法,可以将Map切换到集合视图;且上图中Queue接口没有Stack(因为Stack的功能在JDK1.6中被引入的Deque取代了)
实现
java.util.*中的接口,通用实现类说明如下所示(关注接口的实现关系、类的继承关系、不同实现所用到的数据结构)。Java容器中只能存放对象,对于基本类型数据的存储(int、short、long、char等),需要将其包装成对象类型(Integer、Long、Float、Double)之后才能存放到容器中
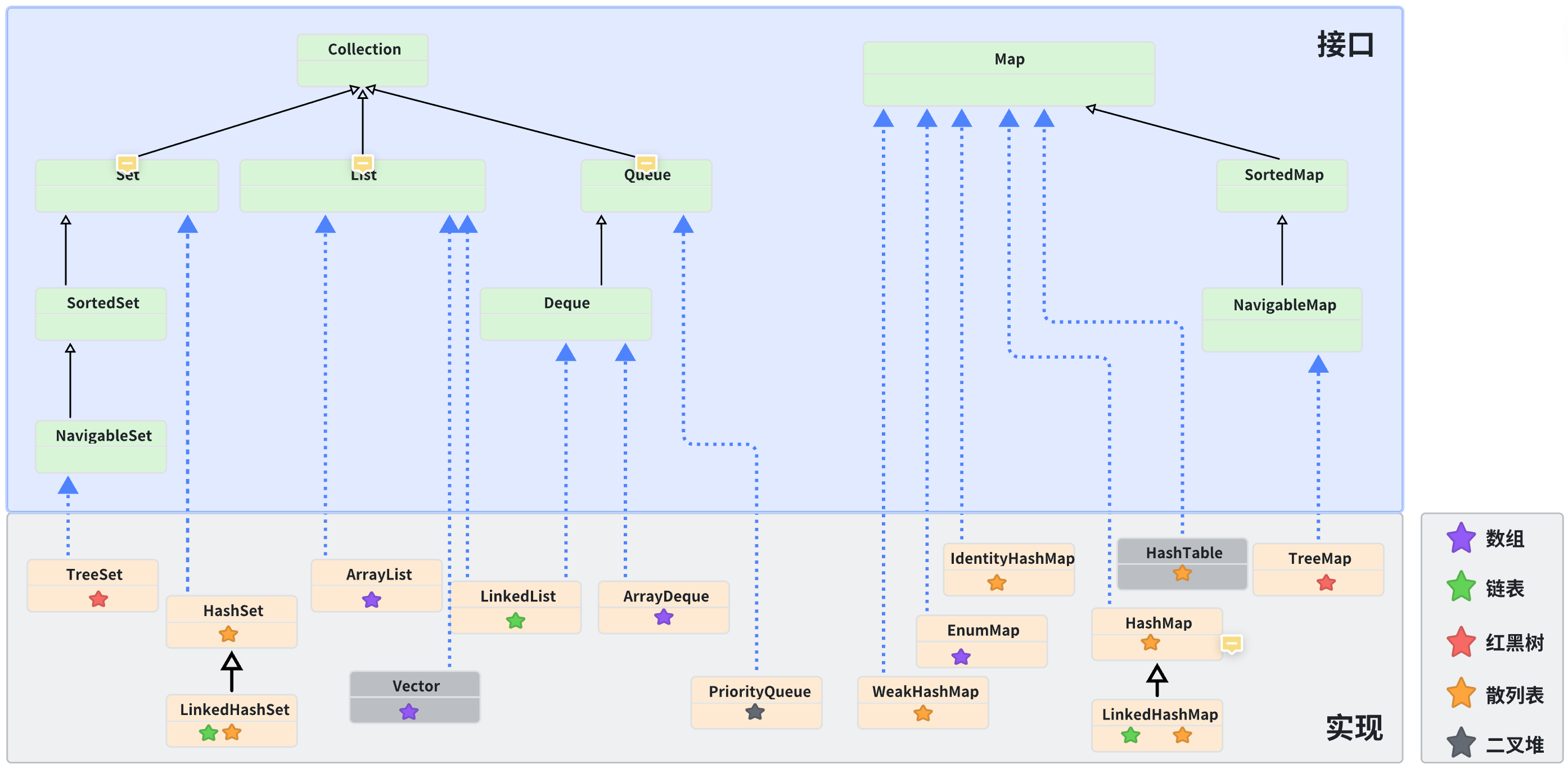
集合框架的选择
针对集合框架的应用,需要结合多个方面考究
- 底层结构
- 性能安全
- 场景应用
Map
Map:以键值对的形式存储和操作数据的容器类型
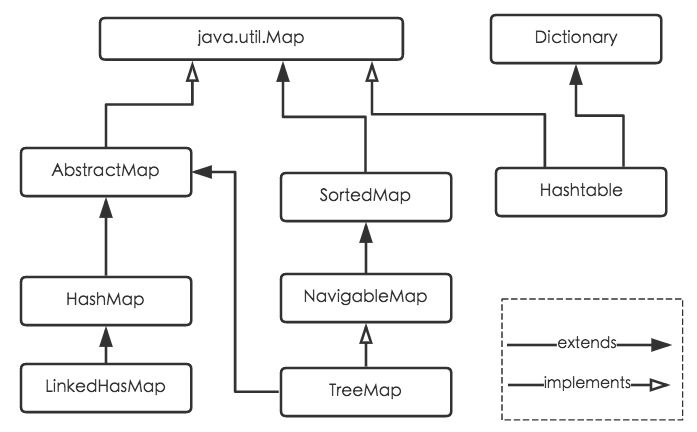
1.HashMap
核心概念:HashMap用于存储无序的键值对数据,key值不能重复(只允许一条key为null的数据,可以多条记录value为null)
数据结构:Java7:基于数组+链表实现;Java8:基于数组+链表+红黑树实现
性能安全:线程不安全,如需保证线程安全可使用JUC并发包中的ConcurrentHashMap或者用 Collections的synchronizedMap方法使HashMap具有线程安全的能力
👻HashMap原理分析
参考链接
(1)Java 7 - HashMap 实现分析
Java 7 中的HashMap采用的是数组+链表的方式实现。其解决hash冲突的方式是通过链表将元素串起来
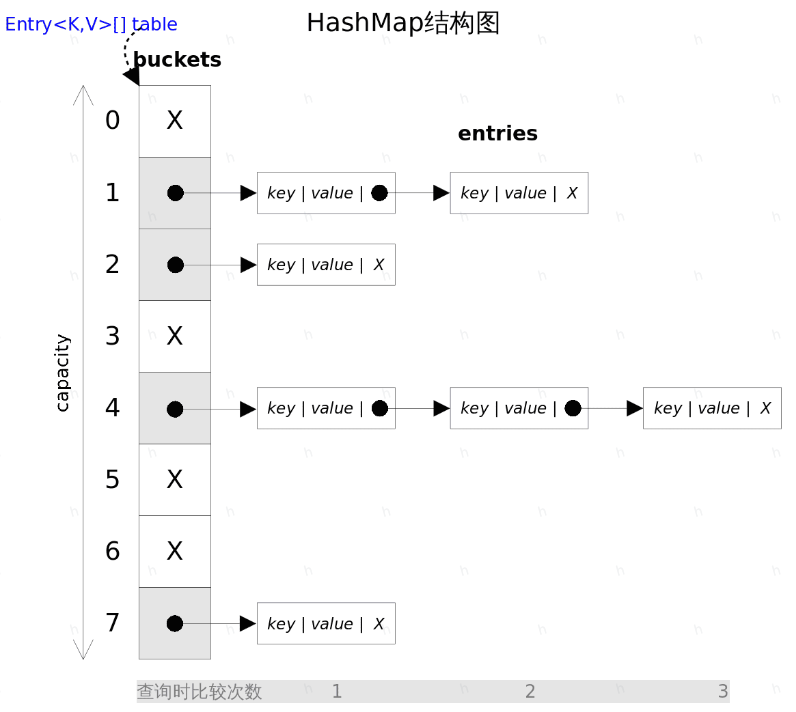
HashMap是一个数组结构,数组中的每一个元素是一个单向链表
当向HashMap中插入元素的时候,会根据键的hashCode值和散列算法将其插入到合适的位置,如果两个键的hashCode相同,则通过链表的方式将元素串接起来以解决hashCode冲突(即hashCode相同的元素会被存储到同一个位桶bucket中)
可以结合图示进一步了解每个元素的结构体:Entry
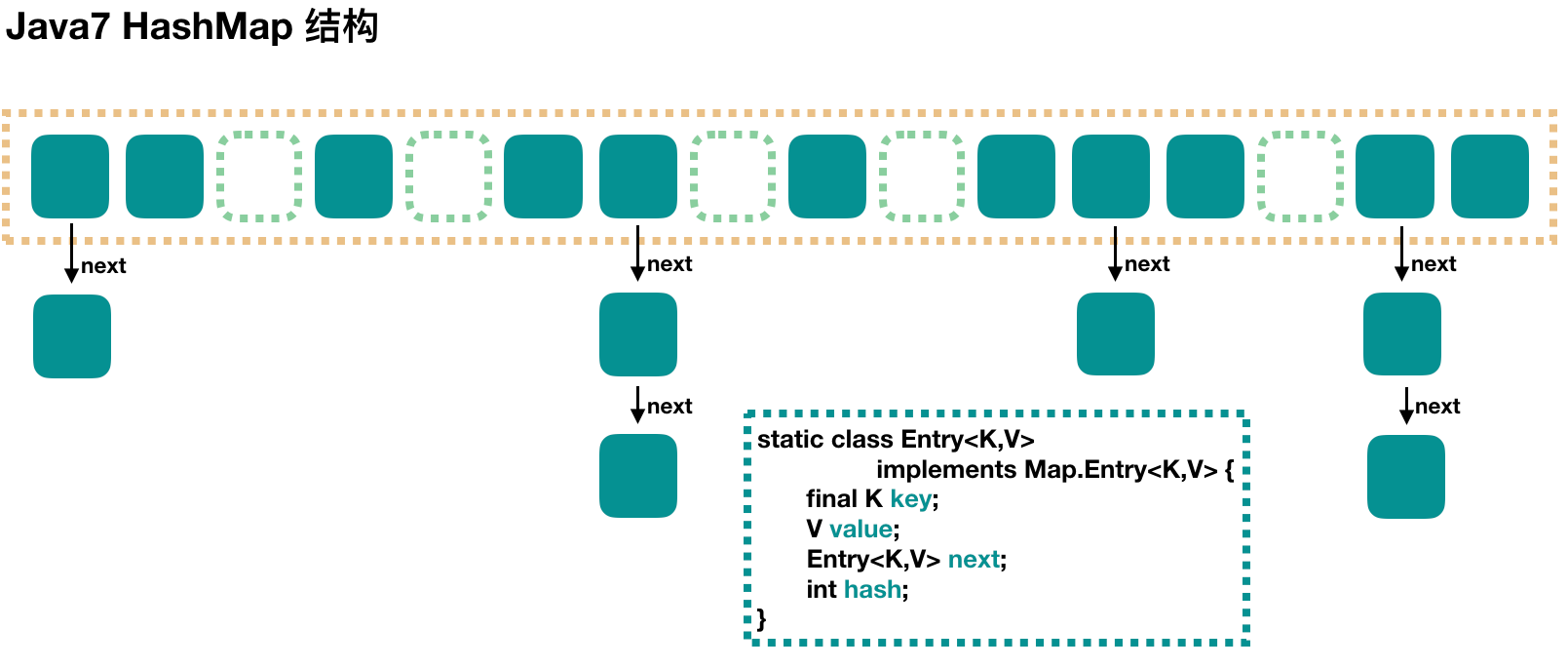
每个元素包括4个核心:key(键)、value(值)、hash(hashCode,对应数组下标)、next(用于单向链表,指向下一个节点)
1.构造函数
static finaL int DEFAULT INITIAL_CAPACITY = 1 << 4;
static final int MAXIMUM_CAPACITY = 1 << 30
static final fLOat DEFAULT_LOAD_FACTOR = 0.75f;
public HashMap(int initialCapacity, float loadFactor){
......
}
// HashMap构造函数源码
public HashMap(int initialCapacity, float loadFactor) {
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal initial capacity: " +
initialCapacity);
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal load factor: " +
loadFactor);
this.loadFactor = loadFactor;
threshold = initialCapacity;
init();
}
HashMap初始化化可指定初始容量和负载因子,如果不指定则使用默认值
- initialCapacity:初始容量(默认16)
- loadFactor:负载因子(默认0.75,即元素个数达到总容量的75%会触发扩容操作)
初始容量指定了初始table的大小(即数组的长度),负载系数用于指定自动扩容的临界值,当entry元素个数超过capacity*load_factor临界值时,容器会自动扩容并重新哈希。对于插入元素较多的场景,可通过将初始容量设大以减少重新哈希的次数
如何理解重新哈希?:hash的本质是将元素分散到数组table的各个下标上,这个过程和数组的长度有关。重新hash的计算方式和扩容前是一样的,唯一的变化就是数组长度(容量的大小)变了
为什么负载因子是0.75?:因为对于使用链表法的哈希表来说,查找一个元素的平均时间是 O(1+n)(此处n 指的是遍历链表的长度),因此加载因子越大,对空间的利用就越充分,产生hash碰撞的几率也越高,这就意味着链表的长度越长,查找效率也就越低。如果设置的加载因子太小,那么哈希表的数据将过于稀疏,对空间造成严重浪费。因此0.75是一个折中选择
2.get()方法
public V get(Object key) {
// key 为 null 的话,会被放到 table[0],只要遍历下 table[0] 处的链表就可以了
if (key == null)
return getForNullKey();
// 调用getEntry方法获取节点元素
Entry<K,V> entry = getEntry(key);
// 返回查找到的值信息
return null == entry ? null : entry.getValue();
}
final Entry<K,V> getEntry(Object key) {
if (size == 0) {
return null;
}
int hash = (key == null) ? 0 : hash(key);
// 确定数组下标,然后从头开始遍历链表,直到找到为止
for (Entry<K,V> e = table[indexFor(hash, table.length)];
e != null;
e = e.next) {
Object k;
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
}
return null;
}
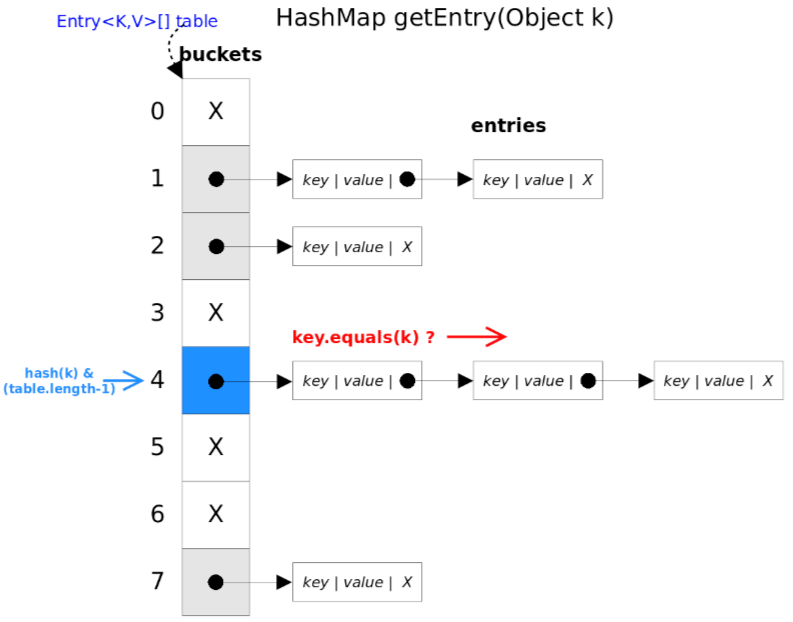
get:根据指定的key返回相应的value
原理分析:根据key的hashCode定位其在数组的位置(定位元素所在位桶),然后循环遍历该位桶下的所有元素(即遍历冲突链表),通过key.equals(k)方法来判断entry是否匹配,如果匹配则返回对应元素的值
- 计算key的hash值,根据hash值定位元素在数组的位置
- 循环遍历冲突链表,如果存在匹配key的entry则直接返回对应value
3.put()方法
public V put(K key, V value) {
// 当插入第一个元素的时候,需要先初始化数组大小
if (table == EMPTY_TABLE) {
inflateTable(threshold);
}
// 如果 key 为 null,最终会将这个 entry 放到 table[0] 中
if (key == null)
return putForNullKey(value);
// 1. 求 key 的 hash 值
int hash = hash(key);
// 2. 找到对应的数组下标
int i = indexFor(hash, table.length);
// 3. 遍历一下对应下标处的链表,看是否有重复的 key 已经存在,如果存在则覆盖并返回旧值
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
// 4. 不存在重复的 key,将此 entry 添加到链表中
addEntry(hash, key, value, i);
return null;
}
put:将指定元素存入的对应位置
原理分析:该方法的核心主要在于先查找确认指定key的元素是否存在,如果存在则进行替换;如果不存在则插入新值
- 根据key的hash值定位其在数组所在位置(该过程类似于get方法流程)
- 如果存在指定key(entry),则替换对应的数值
- 如果不存在指定key(entry),则调用addEntry方法插入新的键值对(插入操作还需考虑是否触发扩容等边界操作)
- 插入方式为【头插法】
- 先判断是否需要扩容,如果需要扩容则先扩容后再通过头插法插入元素
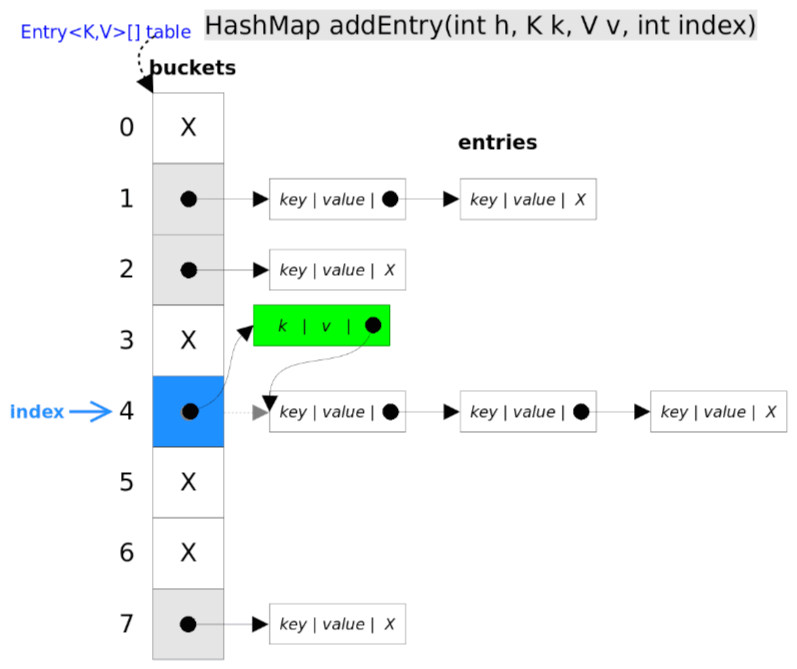
进一步剖析
数组初始化:在第一个元素插入 HashMap 的时候做一次数组的初始化,确定初始的数组大小,并计算数组扩容的阈值
private void inflateTable(int toSize) {
// 保证数组大小一定是 2 的 n 次方。
// 比如这样初始化:new HashMap(20),那么处理成初始数组大小是 32
int capacity = roundUpToPowerOf2(toSize);
// 计算扩容阈值:capacity * loadFactor
threshold = (int) Math.min(capacity * loadFactor, MAXIMUM_CAPACITY + 1);
// 初始化数组
table = new Entry[capacity];
initHashSeedAsNeeded(capacity); //ignore
}
计算下标位置:根据hash和length设定规则
static int indexFor(int hash, int length) {
// assert Integer.bitCount(length) == 1 : "length must be a non-zero power of 2";
return hash & (length-1);
}
因为有些数据计算出的哈希值差异主要在高位,而 HashMap 里的哈希寻址是忽略容量以上的高位的,那么这种处理就可以有效避免类似情况下的哈希碰撞。该方法的设计就是为了尽量打乱hashCode真正参与运行的低16位;
添加节点到链表中,其核心逻辑是先判断是否需要扩容,如果需要则先扩容,然后再将新数据插入到扩容后的数组相应位置处的链表表头
void addEntry(int hash, K key, V value, int bucketIndex) {
// 如果当前 HashMap 大小已经达到了阈值,并且新值要插入的数组位置已经有元素了,那么要扩容
if ((size >= threshold) && (null != table[bucketIndex])) {
// 扩容
resize(2 * table.length);
// 扩容以后,重新计算 hash 值
hash = (null != key) ? hash(key) : 0;
// 重新计算扩容后的新的下标
bucketIndex = indexFor(hash, table.length);
}
// 调用方法创建节点
createEntry(hash, key, value, bucketIndex);
}
// 将新值放到链表的表头,然后 size++
void createEntry(int hash, K key, V value, int bucketIndex) {
Entry<K,V> e = table[bucketIndex];
table[bucketIndex] = new Entry<>(hash, key, value, e);
size++;
}
数组扩容机制:在插入新值的时候,如果当前的size已经到达阈值,则触发扩容(扩容后大小变为原来的2倍(双倍扩容)),其核心就是创建一个新的大数组,将旧数组元素全部迁移到新的数组中。
数组扩容后会重新计算hash,将所有的元素按照规则分拆到指定的位置
4.remove()方法
remove:移除指定key对应的entry
原理分析:根据key对应的hash定位元素所在位置,如果找到指定key对应的entry则进行删除操作(修改链表的相应引用),其查找过程和get()方法过程类似

(2)Java 8 - HashMap 实现分析
Java8中对HashMap进行了一些修改操作,引入红黑树优化检索效率。Java8中HashMap的实现是采用【数组+链表+红黑树】的方式实现
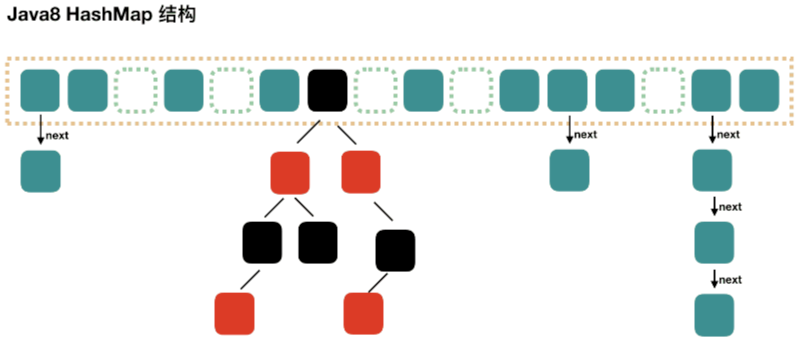
Java8的原理分析可以基于Java7的流程进行分析,主要关注Java8中的优化项
🐶为什么要引入红黑树?
Java7中的HashMap,在检索的过程中,需要根据key的hash快速定位数组的具体下标,确认对应位桶之后会顺着链表(冲突链表)一个个数据进行比较,其时间复杂度取决于该链表的长度(O(n))。
数据量大的场景下可能存在冲突链表长而导致检索效率下降的问题:假设一种场景,如果在数据量比较大的情况,可能会存在某个数组下标对应的冲突链表比较长,再设定一种极端情况:所要查找的元素在链表尾部或者根本不存在,那么检索指定元素的时候就需要一个个遍历冲突链表直到确认结果,那么这部分的检索开销是很大的。
为了降低上面所说的检索开销,在Java8中设定了一个冲突链表阈值8,也就是说当同一个hash指向的冲突链表长度达到8时,程序会自动将链表转化为红黑树,进而降低检索的时间复杂度为O(logN)
扩容:数组扩容问题(todo),扩容是为了分散hash,让冲突链表不要太长
Entry VS Node
Java 7中使用的是Entry来代表每个HashMap的数据节点,而Java 8中使用的是Node,其本质上没有任何区别(基本属性:key、value、hash、next),不过Java8中的Node是用于链表的情况,而红黑树所使用的是TreeNode
Java 8 对HashMap做了什么优化?
- 查询优化
- Java7:如果某个位桶的链表过长,则其查找效率就会低下
- Java8:引入红黑树解决链表过长导致查找效率低下的问题,当链表长度超出阈值8自动转化为红黑树
- 扩容优化:(todo)
- Java7:头插法插入数据(从旧数组的链表头部依次取出数据,计算hash值后再依次通过头插法存入数组对应位置)
- Java8:通过与运算重新分配索引,能将之前哈希冲突的元素再随机分配到不同的索引中
2.HashTable
核心概念:HashTable的功能和HashMap类似,且是线程安全的,但是不再推荐使用,因为并发的效率低。
Hashtable是遗留类,很多映射的常用功能与HashMap类似,不同的是它承自Dictionary类,并且是线程安全的,任一时间只有一个线程能写Hashtable,并发性不如ConcurrentHashMap,因为ConcurrentHashMap引入了分段锁。Hashtable不建议在新代码中使用,不需要线程安全的场合可以用HashMap替换,需要线程安全的场合可以用ConcurrentHashMap替换
3.LinkedHashMap
核心概念:LinkedHashMap是HashMap的子类,使用双向链表来维护元素的插入顺序,通过Iterator遍历可以拿到这个顺序
- 其顺序为插入顺序或者LRU顺序(LRU:最近很少使用顺序),可以在构造时指定顺序
LRU机制可以用于建设对象的缓存和淘汰机制,将最近很少访问的对象给释放掉
案例分析:顺序:插入顺序
public class LinkedHashMapDemo {
public static void main(String[] args) {
LinkedHashMap<Integer, String> defaultMap = new LinkedHashMap<>();
defaultMap.put(1, "JAVA");
defaultMap.put(2, "PYTHON");
defaultMap.put(5, "C");
defaultMap.put(3, "GO");
defaultMap.put(4, "C++");
defaultMap.put(3, "GO LANG");
// 迭代器遍历数据
Iterator it1 = defaultMap.entrySet().iterator();
while (it1.hasNext()) {
System.out.println(it1.next());
}
}
}
// output
1=JAVA
2=PYTHON
5=C
3=GO LANG
4=C++
从上述结果分析可以看到默认使用的是插入顺序,通过迭代器获取到的集合顺序是按照插入顺序进行排序返回的
且再次调用put方法去替换key为3的元素,可以看到实际的defaultMap的顺序还是按照插入顺序进行排序,对用同样的key只是做值的覆盖而不会改变其顺序位置
案例分析:顺序:LRU顺序
public class LinkedHashMapDemo {
public static void main(String[] args) {
LinkedHashMap<Integer, String> lruMap = new LinkedHashMap<>(16, 0.75f, true);
lruMap.put(1, "JAVA");
lruMap.put(2, "PYTHON");
lruMap.put(3, "GO");
lruMap.put(4, "C++");
lruMap.put(5, "C");
// 迭代器遍历数据
Iterator it2 = lruMap.entrySet().iterator();
while (it2.hasNext()) {
System.out.println(it2.next());
}
System.out.println("------校验LRU机制------");
lruMap.put(3, "GO LANG");
Iterator it3 = lruMap.entrySet().iterator();
while (it3.hasNext()) {
System.out.println(it3.next());
}
}
}
// output
1=JAVA
2=PYTHON
3=GO
4=C++
5=C
------校验LRU机制------
1=JAVA
2=PYTHON
4=C++
5=C
3=GO LANG
在初始化LinkedHashMap的时候指定了容量、负载因子、accessOrder(跟踪访问顺序)
此处设定accessOrder为true,让LinkedHashMap跟踪访问顺序并在访问顺序上进行排序,结合上述测试结果,因为lruMap中key为3的元素在最后又被访问了一次(调用put方法),所以它的顺序也相应被更新了(这点可以对比前面案例中的defaultMap)。由此可以知道通过设定accessOrder可以让LinkedHashMap跟踪元素的访问顺序。
由于LinkedHashMap并不直接提供LRU(Least Recently Used)缓存实现,但是可以基于上述的accessOrder参数设定来模拟LRU缓存行为
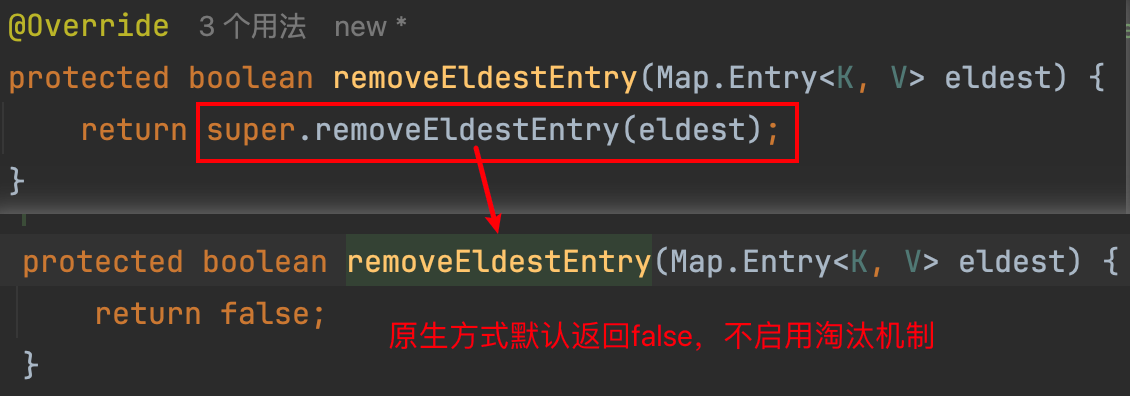
构建思路:自定义LRUCache子类继承LinkedHashMap,重载removeEldestEntry淘汰方法
class LRUCache<K,V> extends LinkedHashMap<K,V> {
private final int capacity;
public LRUCache(int capacity) {
// 初始化容量16,负载因子0.75,访问顺序排序
super(capacity, 0.75f, true);
this.capacity = capacity;
}
@Override
protected boolean removeEldestEntry(Map.Entry<K, V> eldest) {
// return super.removeEldestEntry(eldest);
return size() > capacity;
}
}
/**
* 基于LinkedHashMap模拟LRU缓存机制
*/
public class LRUCacheDemo {
public static void main(String[] args) {
LRUCache<Integer,String> cache = new LRUCache<>(5);
cache.put(1, "JAVA");
cache.put(2, "PYTHON");
cache.put(3, "GO");
cache.put(4, "C++");
cache.put(5, "C");
System.out.println("-------初始化缓存内容--------");
System.out.println(cache);
System.out.println("-------验证超出容量--------");
cache.put(6,"C#");
System.out.println(cache);
System.out.println("-------验证LRU缓存机制---------");
cache.get(2);
System.out.println(cache);
cache.put(7, "REDIS");
System.out.println(cache);
}
}
// output
-------初始化缓存内容--------
{1=JAVA, 2=PYTHON, 3=GO, 4=C++, 5=C}
-------验证超出容量--------
{2=PYTHON, 3=GO, 4=C++, 5=C, 6=C#}
-------验证LRU缓存机制---------
{3=GO, 4=C++, 5=C, 6=C#, 2=PYTHON}
{4=C++, 5=C, 6=C#, 2=PYTHON, 7=REDIS}
基于上述结果分析,分析自定义的LRUCache缓存执行流程:
- 初始化设定缓存大小为5,因此插入5个数据,此时刚好达到定义的容量大小
{1=JAVA, 2=PYTHON, 3=GO, 4=C++, 5=C}
- 当再次插入第6个数据,会触发淘汰机制,剔除掉最开始访问的那个数据,然后插入新数据
{2=PYTHON, 3=GO, 4=C++, 5=C, 6=C#}
- 执行get(2),访问数据,然后再查看此时的列表顺序(key为2的元素被访问,顺序被更新)
{3=GO, 4=C++, 5=C, 6=C#, 2=PYTHON}
- 执行put操作插入第7个数据,此时会触发淘汰机制,根据LRU机制剔除掉最近很少访问的数据(此处为key为3的元素),然后再插入新数据,此时更新后的数据顺序如下
{4=C++, 5=C, 6=C#, 2=PYTHON, 7=REDIS}
4.TreeMap
核心概念:基于红黑树实现的一种顺序访问的Map,存储的元素是有序的;TreeMap实现SortedMap接口,能够把它保存的记录根据键排序
- 实现SortedMap接口:将元素根据key排序(默认升序列),使用Iterator遍历会得到一个升序的记录序列
- 排序规则:可以通过指定Comparator决定key排序的逻辑(比较大小的逻辑),或者根据key的自然顺序来进行判断
5.ConcurrentHashMap
可以理解为ConcurrentHashMap是HashMap线程安全的实现,它的基本原理和HashMap类似,只不过在此基础上引入了线程安全机制
ConcurrentHashMap的key、value为什么不能为null?:主要是为了避免二义性。null是是一个特殊的值,表示没有对象或者没有引用,如果使用null作为key则无法区分集合中是否真正存储这个null,还是因为找不到键而返回的null
- HashMap:单线程环境下,可以通过
contains(key)来做判断是否存在这个键值对,从而做相应的处理,也就不存在二义性问题(因此HashMap允许存储一个key为null的元素) - ConcurrentHashMap:多线程环境下,可能存在多个线程对集合进行操作,因此无法通过
contains(key)来做判断,因此无法解决二义性问题
6.Map扩展概念
HashMap VS HashTable
- 底层数据结构
- HashMap:Java7、Java8 的底层处理不同,Java 8优化了检索性能
- HashTable:没有这样的优化机制
- 对Null Key、Null Value的支持
- HashMap:只可以存储一个key为null的元素(key要确保唯一性),允许存储多个value为null的元素
- HashTable:不允许存储key、value为null的元素(会抛出NPE)
- 效率
- 因为线程安全问题,HashMap的效率较高,但HashTable已经基本被淘汰了
- 线程安全
- HashMap:非线程安全,如果要确保线程安全可使用ConcurrentHashMap
- HashTable:线程安全(其内部方法都通过synchroinzed修饰)
HashMap VS HashSet
HashSet 的底层是基于HashMap实现的,其大部分方法都是调用HashMap方法实现
HashMap | HashSet |
|---|---|
实现了 Map 接口 | 实现 Set 接口 |
| 存储键值对 | 仅存储对象 |
调用 put()向 map 中添加元素 | 调用 add()方法向 Set 中添加元素 |
HashMap 使用键(Key)计算 hashcode | HashSet 使用成员对象来计算 hashcode 值,对于两个对象来说 hashcode 可能相同,所以equals()方法用来判断对象的相等性 |
HashMap VS TreeMap
HashMap 和 TreeMap 都是Map接口的子类实现,其中TreeMap还实现了NavigableMap接口和SortedMap 接口,使得TreeMap成为处理有序集合搜索的清大工具
对比HashMap而言,TreeMap多了对集合元素的key排序和搜索能力
HashMap VS HashSet
List
ArrayList和Vector基于数组实现;LinkedList使用双向链表实现
ArrayList
构建核心:非线程安全
- 实现List接口、继承AbstractList抽象类,支持所有List操作
- 实现RandomAccess接口,支持随机访问
- 实现Cloneable、Serializable接口,支持克隆和序列化
核心原理:
- 数据结构:两个核心要素(size、elementData)
- size:动态数组的实际大小(默认为10)
- 序列化:实现Serializable接口引入外部序列化,但是保存元素的数组不一定全部被使用,无需全部进行序列化
- 存储元素的数组Object用transient修饰,可被Java默认序列化方式忽略
- ArrayList 重写writeObject、readObject 方法自定义内部元素的序列化机制
- 元素操作
- 添加元素
- 动态扩容会自动扩容为原来的1.5倍(原理Arrays.copyof()=>新建数组,迁移旧数据)
- 删除元素
- 删除元素会导致后面的数组重组,有一定的性能开销
- 访问元素
- 通过数组下标访问元素(时间复杂度O(1))
- 底层基于数组,支持随机访问
- 添加元素
- fail-fast机制:
- 添加/删除元素是会通过modCount计数,如果在序列化或者迭代操作时发现操作前后modCount改变的话就会抛出ConcurrentModificationException
LinkedList
构建核心:非线程安全
- 实现List接口、继承AbstractSequentialList抽象类,支持所有List操作
- 实现Deque接口,可以被当作队列(Queue)、双端队列(Deque)使用
- 实现Cloneable、Serializable接口,支持拷贝和序列化
核心原理:
- 数据结构:内部维护了一个双链表(四要素)
- size:双链表节点个数(初始化为0)
- first:头节点
- last:尾节点
- Node:内部类节点定义(表示链表中的元素实例)
- 序列化:实现Serializable接口引入外部序列化
- size、first、last 被transient修饰,使其可以被Java默认序列化机制忽略
- 重写writeObject、readObject方法,自定义内部属性的序列化机制
- 元素操作:
- 访问元素:根据index拆分前半部分、后半部分进行检索
- 如果是前半部分从头节点开始找;如果是后半部分从尾节点开始找
- 底层实现是双向链表,数据存储在不连续的空间并通过指针构建关联,顺序访问效率高,随机访问效率低
- 新增元素:链表尾插法
- 删除元素:改变指针指向
- 访问元素:根据index拆分前半部分、后半部分进行检索
1.ArrayList
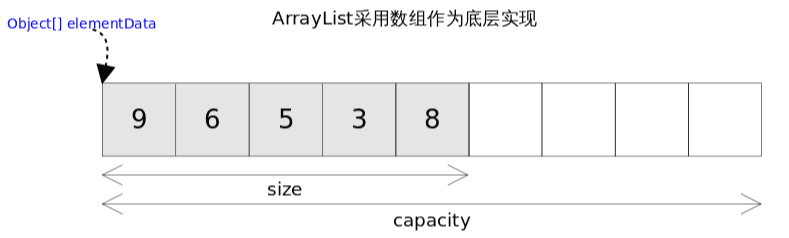
底层实现:可视为支持动态扩容的线性表
- 基于动态数组(Object[])存储数据,可容纳任何类型的对象
并发场景:线程不安全
参数说明
size:当前数组实际存储的元素个数
capacity(容量):数组可容纳的元素个数(new一个默认的ArrayList初始化容量是0,只有当第一次插入元素之后容量会变为DEFAULT_CAPACITY=10)
结构分析
ArrayList底层是基于动态数组实现的,基本和数组特性一致
- 性能:查找效率高,支持快速随机访问。数组中间的元素插入和删除操作效率较低
- 扩容机制
- 当插入新元素时,会先校验数组大小是否能容纳所有元素,如果不满足时需要扩容
- 扩容会创建一个新的数组,将现有的数组数据拷贝到新数组
- 扩容大小
- 每次数组容量的增长大约是原容量的1.5倍(这种代价是很高的,实际使用应尽量避免数组容量的扩张)
- 预设:构造ArrayList实例的时候就指定预估的容量大小,避免数组扩容的发生
- 动态调配:根据实际插入数据情况,提前通过调用ensureCapacity方法来手动增加ArrayList实例的容量,以减少递增式再分配的数量(确保数组可容纳量,而不是等插入过程中再去多次扩容)
源码分析(JDK1.8)
public class ArrayList<E> extends AbstractList<E>
implements List<E>, RandomAccess, Cloneable, java.io.Serializable
{
// --- 核心属性 ---
// 默认容量
private static final int DEFAULT_CAPACITY = 10;
// 对象数组
transient Object[] elementData;
// 数组长度
private int size;
}
ArrayList继承AbstractList抽象类并实现List接口。此外还实现了RandomAccess(标志接口),用于标志只要实现了该接口的List类都能实现快速随机访问;实现Cloneable和Serializable接口,支持克隆和序列化
问题1:如何理解ArrayList实现了序列化接口Serializable,但是内部elementData属性用trabsient关键字修饰?(transient关键字修饰字段表示该属性不会被序列化)
结合【ArrayList是基于数组实现】这点继续宁说明,因为ArrayList的数组是基于动态扩展的,并不是所有被分配的内存空间都存储了数据
ArrayList实现了序列化接口(采用外部序列化实现数组的序列化),会序列化整个数组。ArrayList为了避免这些没有存储数据的内存空间被序列化,提供了两个私有方法:writeObject、readObject来完成自我序列化和反序列化,进而在序列化和反序列化数组时节省空间和时间。因此采用transient修饰数组是为了防止对象数组被其他外部方法序列化。
ArrayList的构造方法:
public ArrayList(int initialCapacity) {
if (initialCapacity > 0) {
this.elementData = new Object[initialCapacity];
} else if (initialCapacity == 0) {
this.elementData = EMPTY_ELEMENTDATA;
} else {
throw new IllegalArgumentException("Illegal Capacity: "+
initialCapacity);
}
}
/
public ArrayList() {
this.elementData = DEFAULTCAPACITY_EMPTY_ELEMENTDATA;
}
public ArrayList(Collection<? extends E> c) {
elementData = c.toArray();
if ((size = elementData.length) != 0) {
// c.toArray might (incorrectly) not return Object[] (see 6260652)
if (elementData.getClass() != Object[].class)
elementData = Arrays.copyOf(elementData, size, Object[].class);
} else {
// replace with empty array.
this.elementData = EMPTY_ELEMENTDATA;
}
}
ArrayList新增元素:
当ArrayList新增元素的时候,如果存储的元素超过已有大小,它会计算元素大小之后再进行动态扩容。数组的扩容会导致整个数组进行一次内存复制。因此在初始化的时候可以预设指定一个合理的数组初始化大小,减少数组扩容次数,进而提升系统性能
// 将元素加到数组的末尾
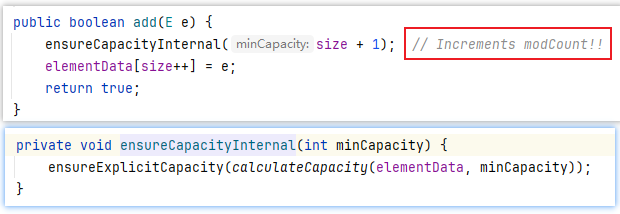
public boolean add(E e) {
ensureCapacityInternal(size + 1); // Increments modCount!!
elementData[size++] = e;
return true;
}
// 将元素加到数组的任意位置
public void add(int index, E element) {
rangeCheckForAdd(index);
ensureCapacityInternal(size + 1); // Increments modCount!!
System.arraycopy(elementData, index, elementData, index + 1,
size - index);
elementData[index] = element;
size++;
}
在添加元素之前,两种方法都会确认容量大小,如果容量足够大则不用进行扩容;如果容量不够大则扩为原来的1.5倍,扩容之后需要将数组复制到新分配的内存地址。这两种add方式也有不同之处:
添加到末尾:在没有发生扩容的前提下,不会有元素复制排序过程
添加到任意位置:会导致在该位置后的所有元素都需要重新排列
ArrayList删除元素:
ArrayList删除元素的方法和添加任意位置元素的方法有异曲同工之妙。ArrayList在每一次有效的删除操作之后都要进行数组的重组,且删除元素的位置越靠前,数组重组的开销越大
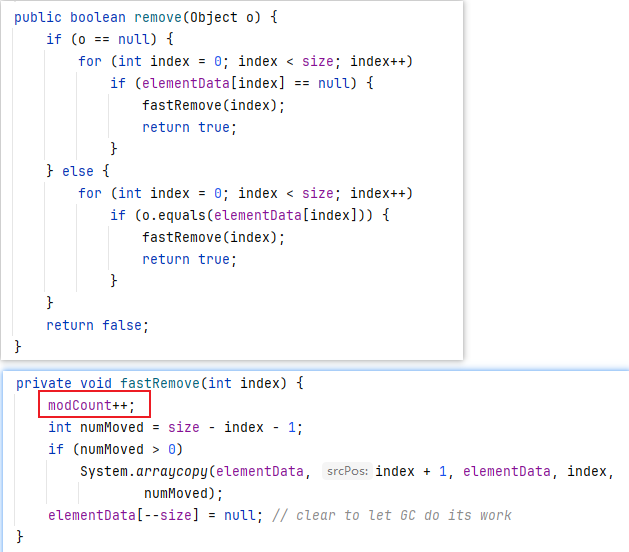
public E remove(int index) {
rangeCheck(index);
modCount++;
E oldValue = elementData(index);
int numMoved = size - index - 1;
if (numMoved > 0)
System.arraycopy(elementData, index+1, elementData, index,
numMoved);
elementData[--size] = null; // clear to let GC do its work
return oldValue;
}
ArrayList遍历元素:
因为ArrayList底层是基于是数组实现的,所以在获取元素的时候是非常快捷的。
public E get(int index) {
rangeCheck(index);
checkForComodification();
return ArrayList.this.elementData(offset + index);
}
ArrayList 的Fail-Fast:
ArrayList 使用 modCount 来记录结构发生变化的次数。结构发生变化是指添加或者删除至少一个元素的所有操作,或者是调整内部数组的大小,仅仅只是设置元素的值不算结构发生变化。在进行序列化或者迭代等操作时,需要比较操作前后 modCount 是否改变,如果发生改变,ArrayList 会抛出 ConcurrentModificationException。
private void writeObject(java.io.ObjectOutputStream s)
throws java.io.IOException{
// Write out element count, and any hidden stuff
int expectedModCount = modCount;
s.defaultWriteObject();
// Write out size as capacity for behavioural compatibility with clone()
s.writeInt(size);
// Write out all elements in the proper order.
for (int i=0; i<size; i++) {
s.writeObject(elementData[i]);
}
if (modCount != expectedModCount) {
throw new ConcurrentModificationException();
}
}
2.LinkedList
双向链表和双向循环链表
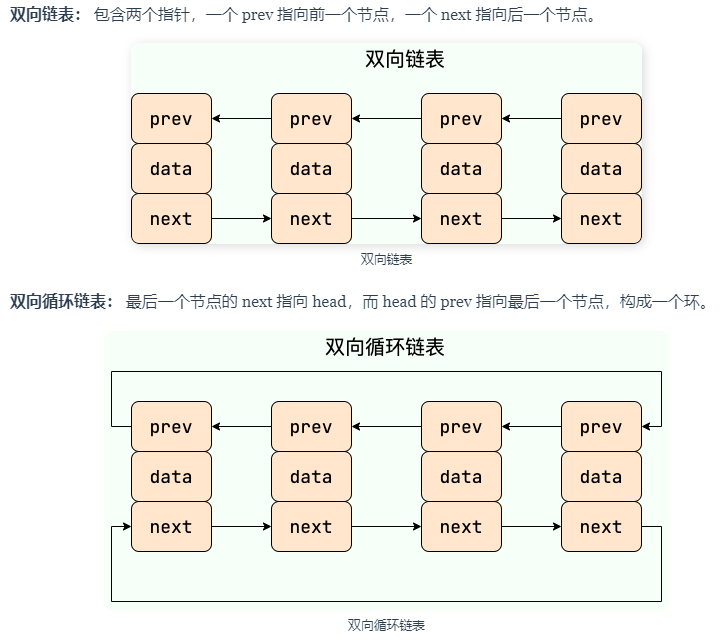
LinkedList就是一个由Node结构对象连接而成的双向链表;
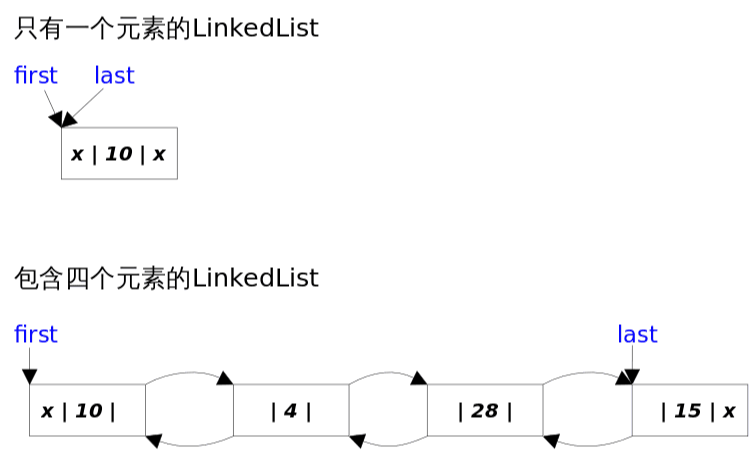
- 节点:列表中的所有元素包装为Node节点
- 双向链表结构:Node节点有前后指针,头节点的向前指针和尾节点的向后指针都指向null
- 头尾指针:链表维护了两个指针,分别指向LinkedList的头和尾
- 当链表元素尾0,这两个指针指向null
- 因为可以快速找到头尾元素,所以LInkedList可以用作栈、队列、双向队列
- 并发场景:线程不安全(可用Collections.synchronizedList()包装为线程安全)
结构分析
public class LinkedList<E>
extends AbstractSequentialList<E>
implements List<E>, Deque<E>, Cloneable, java.io.Serializable
{
transient int size = 0;
/**
* Pointer to first node.
*/
transient Node<E> first;
/**
* Pointer to last node.
*/
transient Node<E> last;
private static class Node<E> {
E item;
Node<E> next;
Node<E> prev;
Node(Node<E> prev, E element, Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}
}
- 性能:下表相关的操作都是线性时间,在首段或者末尾删除元素只需要常数时间
- 插入和删除:因为链表和数组的特性差异,LinkedList的插入和删除操作不会导致前后的元素移动,而只需要指针的变换
源码分析(JDK1.8)
public class LinkedList<E>
extends AbstractSequentialList<E>
implements List<E>, Deque<E>, Cloneable, java.io.Serializable
{
// 核心属性
transient int size = 0;
transient Node<E> first;
transient Node<E> last;
}
LinkedList继承AbstractSequentialList抽象类,又实现了List、Deque接口,使得LinkedList即有List类型又有Queue类型的特点;它还是实现了Cloneable、Serializable接口,可以实现克隆和序列化
由于 LinkedList 存储数据的内存地址是不连续的,而是通过指针来定位不连续地址,因此,LinkedList 不支持随机快速访问,LinkedList 也就不能实现 RandomAccess 接口
LinkedList 的核心属性有size(大小)、first(头节点)、last(尾节点),这三个属性都被transient修饰,在序列化的时候不会只对头尾进行序列化,所以 LinkedList 也是自行实现 readObject 和 writeObject 进行序列化与反序列化
LinkedList新增元素
// 默认add方法:加到队尾
public boolean add(E e) {
linkLast(e);
return true;
}
void linkLast(E e) {
final Node<E> l = last;
final Node<E> newNode = new Node<>(l, e, null);
last = newNode;
if (l == null)
first = newNode;
else
l.next = newNode;
size++;
modCount++;
}
Linked 默认add方法添加元素实现原理:将添加的元素加到队尾
- 将last元素置换到临时变量中
- 生成一个新的Node,然后将last引用指向新节点对象
- 将之前的last对象(临时变量)的后指针指向新节点对象
// 指定元素位置的添加方法
public void add(int index, E element) {
checkPositionIndex(index);
if (index == size)
linkLast(element);
else
linkBefore(element, node(index));
}
void linkBefore(E e, Node<E> succ) {
// assert succ != null;
final Node<E> pred = succ.prev;
final Node<E> newNode = new Node<>(pred, e, succ);
succ.prev = newNode;
if (pred == null)
first = newNode;
else
pred.next = newNode;
size++;
modCount++;
}
LinkedList 添加指定元素到任意位置(添加到任意两个元素的中间位置),添加操作只会改变前后元素的前后指针(指向新添加的元素),对比ArrayList的添加操作而言,LinkedList的性能优势更明显。
,
LinkedList删除元素
public boolean remove(Object o) {
if (o == null) {
for (Node<E> x = first; x != null; x = x.next) {
if (x.item == null) {
unlink(x);
return true;
}
}
} else {
for (Node<E> x = first; x != null; x = x.next) {
if (o.equals(x.item)) {
unlink(x);
return true;
}
}
}
return false;
}
E unlink(Node<E> x) {
// assert x != null;
final E element = x.item;
final Node<E> next = x.next;
final Node<E> prev = x.prev;
if (prev == null) {
first = next;
} else {
prev.next = next;
x.prev = null;
}
if (next == null) {
last = prev;
} else {
next.prev = prev;
x.next = null;
}
x.item = null;
size--;
modCount++;
return element;
}
如果要删除的元素为null则用==比较,否则用equals比较,通过遍历整个链表定位第一个匹配的节点,并调用unlink方法删除Node
LinkedList 遍历元素:
LinkedList 的获取元素操作实现跟 LinkedList 的删除元素操作基本类似,通过分前后半段来循环查找到对应的元素。但是通过这种方式来查询元素是非常低效的,特别是在 for 循环遍历的情况下,每一次循环都会去遍历半个 List。
所以在 LinkedList 循环遍历时,可以使用 iterator 方式迭代循环,直接拿到匹配的元素,而不需要通过循环查找 List
3.Vector(不推荐使用)
基于数组实现,特性和ArrayList类似,不推荐使用
- 线程安全:使用线程同步能力,多线程互斥写入Vector
4.各种List的对比
(1)ArrayList和LinkedList的效率陷阱
对比ArrayList和LinkedList的底层原理,结合使用场景分析:在一般情况下可能会认为新增、删除元素的时候LinkedList效率大于ArrayList,而在遍历元素的时候ArrayList的效率大于LinkedList
ArrayList底层基于数组,LinkedList底层基于双向链表
- 新增元素:
- ArrayList:涉及到动态扩容问题(如果动态扩容则要进行数组内容拷贝,开销较大)
- LinkedList:新增元素创建一个Node节点,然后根据存入的位置改变节点的头尾指针指向
- 删除元素
- ArrayList:每有效删除一个数据,需要进行数组的重组,且删除元素的位置越靠前,数组重组的开销越大
- LinkedList:删除元素其实是剔除节点的引用
- 遍历元素
- ArrayList:存储数据的内存地址连续,可以支持随机快速访问(实现RandomAccess接口用于标志)
- LinkedList:其存储数据的内存地址是不连续的,而是通过指针来定位不连续地址,因此LinkedList 不支持随机快速访问
基于上述对比分析,可以初步佐证上述的结论正确性。但是这只能是大方向的一个考察,在一些场景下这个结论反而未必正确
- 新增元素:分别从集合的头部、中间、尾部新增元素,两种方式的花费时间参考如下
- 头部:ArrayList>LinkedList
- 中间:ArrayList<LinkedList
- 尾部:ArrayList<LinkedList
由于 ArrayList 是数组实现(一块连续的内存空间),在添加元素到数组头部的时候,需要对头部以后的数据进行复制重排,所以效率很低;而 LinkedList 是基于链表实现,在添加元素的时候,首先会通过循环查找到添加元素的位置,如果要添加的位置处于 List 的前半段,就从前往后找;若其位置处于后半段,就从后往前找,因此 LinkedList 添加元素到头部是非常高效的。
ArrayList 在添加元素到数组中间时,同样有部分数据需要复制重排,效率也不是很高;LinkedList 将元素添加到中间位置,是添加元素最低效率的,因为靠近中间位置,在添加元素之前的循环查找是遍历元素最多的操作。
而在添加元素到尾部的操作中,在没有扩容的情况下,ArrayList 的效率要高于 LinkedList。这是因为 ArrayList 在添加元素到尾部的时候,不需要复制重排数据,效率非常高。而 LinkedList 虽然也不用循环查找元素,但 LinkedList 中多了 new 对象以及变换指针指向对象的过程,所以效率要低于 ArrayList。
此处验证结论是基于 ArrayList 初始化容量足够,排除动态扩容数组容量的情况下进行的测试,如果有动态扩容的情况,ArrayList 的效率也会降低
类似地,因为删除元素和新增元素的原理是类似的,因此分别从集合头部、中间、尾部删除元素的操作得到的效率比较和新增场景是差不多的,原理也是一样
- 遍历元素:分别基于for循环和迭代器循环
- for循环:LinkedList的效率低于ArrayList
- 迭代器循环:两者的迭代效率差不多
LinkedList 基于链表实现的,在使用 for 循环的时候,每一次 for 循环都会去遍历半个 List,所以严重影响了遍历的效率(在遍历LinkedList的时候避免使用for循环);ArrayList 则是基于数组实现的,并且实现了 RandomAccess 接口标志,意味着 ArrayList 可以实现快速随机访问,所以 for 循环效率非常高
(2)Vector、ArrayList、LinkedList有什么区别?
对比三者的区别可以分别从底层实现、线程安全、应用场景多方面继续阐述
- 底层实现:
- ArrayList、Vector底层都是基于数组实现
- LinkedList是基于双向链表实现
- 线程安全:
- ArrayList:线程不安全(性能较好)
- Vector:线程安全(同步需要额外开销)
- LinkedList:线程不安全
- 应用场景:
- 新增频繁:
- ArrayList、Vector 新增元素如果涉及到动态扩容,需要进行数组拷贝造成性能开销。其中ArrayList扩容为原来的1.5倍,Vector扩容为原来的2倍
- LinkedList 新增元素本质是新增一个节点,调整对应位置元素的指针引用,效率较高
- 数据检索:
- ArrayList、Vector 底层基于动态数组构建,支持随机访问,检索效率较高
- LinkedList 底层基于链表构建,数据存储在不连续的地址(通过指针构建联系),随机访问性能较差
- 新增频繁:
Set
Set用于存储无序、不重复元素
- 无序性:存储的数据在底层的数组并非按照数组索引顺序添加,而是根据元素的hash值决定
- 不可重复性:添加的元素不可重复,重写equals、hashCode方法构建校验规则
1.TreeSet
原理分析
TreeSet基于红黑树实现:使用二叉树原理对元素进行排序。
- 在插入元素时需要调整树结构,将元素放到指定的位置,支持自然顺序访问
- 添加、删除、包含等操作会相对低效(log(n)时间)
排序:具备比较大小的能力
- 基础包装类Integer、String等可以支持默认排序
- 自定义类需要实现Comparable接口(自定义对象的大小比较规则)
2.HashSet
HashSet的实现逻辑基本和HashMap一致
其底层使用HashMap存储数据,使用Map的key作为Set集合,所有元素的Value值统一为PRESENT。
public class HashSet<E>
extends AbstractSet<E>
implements Set<E>, Cloneable, java.io.Serializable
{
@java.io.Serial
static final long serialVersionUID = -5024744406713321676L;
private transient HashMap<E,Object> map;
private static final Object PRESENT = new Object();
}
其操作几乎都是调用HashMap的方法来实现的
// 添加元素
public boolean add(E e) {
return map.put(e, PRESENT)==null;
}
// 移除元素
public boolean remove(Object o) {
return map.remove(o)==PRESENT;
}
扩展问题:HashSet如何检查重复?(参考《Head first java》第二版)
- 先通过计算对象的hashCode来判断对象加入的位置
- 如果hashCode不冲突,则认为当前操作对象没有重复出现
- 如果hashCode冲突,则进一步调用equals方法确认对象是否相同
- 如果equals返回true,则认为对象重复出现
- 如果equals返回false,则认为对象不重复
// 添加元素
public boolean add(E e) {
return map.put(e, PRESENT)==null;
}
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
跟踪上述HashSet 的 add 方法代码,可以看到在JDK8中的实现是无论HashSet中是否存在某元素,HashSet都会直接插入,只不过在add方法执行会返回一个插入前是否存在相同元素的标志(boolean)
3.LinkedHashSet
- 底层通过LInkedHashMap保存所有元素
- 继承HashSet,操作上和父类相同,直接调用父类方法
public class LinkedHashSet<E>
extends HashSet<E>
implements Set<E>, Cloneable, java.io.Serializable {
@java.io.Serial
private static final long serialVersionUID = -2851667679971038690L;
public LinkedHashSet(int initialCapacity, float loadFactor) {
super(initialCapacity, loadFactor, true);
}
public LinkedHashSet(int initialCapacity) {
super(initialCapacity, .75f, true);
}
public LinkedHashSet() {
super(16, .75f, true);
}
public LinkedHashSet(Collection<? extends E> c) {
super(Math.max(2*c.size(), 11), .75f, true);
addAll(c);
}
@Override
public Spliterator<E> spliterator() {
return Spliterators.spliterator(this, Spliterator.DISTINCT | Spliterator.ORDERED);
}
}
4.Set 扩展概念
Comparable VS Comparator
Comparable 和 Comparator 都是Java中用于排序的接口,在实现类对象直接大小的比较、排序中发挥重要作用
Comparable
来自
java.lang包,提供compareTo(Object o)方法
构建Person类,实现Comparable接口,重写方法实现按照年龄排序
// Comparable排序
class Person implements Comparable<Person>{
private String name;
private int age;
public Person(String name, int age) {
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
// 重写compareTo方法实现按照年龄排序
@Override
public int compareTo(Person o) {
if (this.age > o.getAge()) {
return 1;
}
if (this.age < o.getAge()) {
return -1;
}
return 0;
}
}
/**
* 排序 demo
*/
public class SortDemo {
public static void main(String[] args) {
// 1.Comparable验证
TreeMap<Person,String> persons = new TreeMap<Person,String>();
persons.put(new Person("John", 27),"John");
persons.put(new Person("Jane", 18),"Jane");
persons.put(new Person("Jack", 6),"Jack");
persons.put(new Person("Jill", 34),"Jill");
Set<Person> keys = persons.keySet();
for (Person key : keys) {
System.out.println(key.getName() + " " + key.getAge());
}
}
}
// output
Jack 6
Jane 18
John 27
Jill 34
Comparator
来自
java.util包,提供compare(T o1, T o2)方法
public class SortDemo {
public static void main(String[] args) {
// 2.Comparator验证(Comparator定制排序)
ArrayList<Integer> arrayList = new ArrayList<Integer>();
arrayList.add(-1);
arrayList.add(3);
arrayList.add(3);
arrayList.add(-5);
arrayList.add(7);
arrayList.add(4);
arrayList.add(-9);
arrayList.add(-7);
System.out.println("原始数组:" + arrayList);
Collections.reverse(arrayList);// void reverse(List list):反转
System.out.println("Collections.reverse(arrayList):"+ arrayList);
Collections.sort(arrayList); // void sort(List list),按自然排序的升序排序
System.out.println("Collections.sort(arrayList):" + arrayList);
// 定制排序的用法
Collections.sort(arrayList, new Comparator<Integer>() {
@Override
public int compare(Integer o1, Integer o2) {
return o2.compareTo(o1);
}
});
System.out.println("定制排序后:" + arrayList);
}
}
// output
原始数组:[-1, 3, 3, -5, 7, 4, -9, -7]
Collections.reverse(arrayList):[-7, -9, 4, 7, -5, 3, 3, -1]
Collections.sort(arrayList):[-9, -7, -5, -1, 3, 3, 4, 7]
定制排序后:[7, 4, 3, 3, -1, -5, -7, -9]
TreeSet、HashSet、LinkedHashSet 三者的异同
- 定义
- 三者都是Set接口的实现类,用于存储不重复的元素,但不是线程安全的
- 底层实现
- TreeSet:红黑树(存储有序、不重复元素,支持自然排序和定制排序)
- HashSet:哈希表(基于HashMap实现)
- LinkedHashSet:链表+哈希表,元素的插入、取出顺序满足FIFO
- 应用场景
- 结合其底层实现选择适配的应用场景
Queue
PriorityQueue基于堆结构实现,可以用它实现优先队列
Collections集合工具类
Collections常用方法:
- 排序
- 查找替换
- 同步控制(不推荐,建议使用JUC包下的并发集合)
1.排序操作
void reverse(List list)//反转
void shuffle(List list)//随机排序
void sort(List list)//按自然排序的升序排序
void sort(List list, Comparator c)//定制排序,由Comparator控制排序逻辑
void swap(List list, int i , int j)//交换两个索引位置的元素
void rotate(List list, int distance)//旋转。当distance为正数时,将list后distance个元素整体移到前面。当distance为负数时,将 list的前distance个元素整体移到后面
2.查找替换
int binarySearch(List list, Object key)//对List进行二分查找,返回索引,注意List必须是有序的
int max(Collection coll)//根据元素的自然顺序,返回最大的元素。 类比int min(Collection coll)
int max(Collection coll, Comparator c)//根据定制排序,返回最大元素,排序规则由Comparatator类控制。类比int min(Collection coll, Comparator c)
void fill(List list, Object obj)//用指定的元素代替指定list中的所有元素
int frequency(Collection c, Object o)//统计元素出现次数
int indexOfSubList(List list, List target)//统计target在list中第一次出现的索引,找不到则返回-1,类比int lastIndexOfSubList(List source, list target)
boolean replaceAll(List list, Object oldVal, Object newVal)//用新元素替换旧元素
3.线程安全
Collections 提供了多个synchronizedXxx()方法·,该方法可以将指定集合包装成线程同步的集合,从而解决多线程并发访问集合时的线程安全问题。
HashSet,TreeSet,ArrayList,LinkedList,HashMap,TreeMap 都是线程不安全的。Collections 提供了多个静态方法可以把他们包装成线程同步的集合。
但这些方法效率非常低,需要线程安全的集合类型时考虑使用 JUC 包下的并发集合
synchronizedCollection(Collection<T> c) //返回指定 collection 支持的同步(线程安全的)collection。
synchronizedList(List<T> list)//返回指定列表支持的同步(线程安全的)List
synchronizedMap(Map<K,V> m) //返回由指定映射支持的同步(线程安全的)Map
synchronizedSet(Set<T> s) //返回指定 set 支持的同步(线程安全的)set
集合使用注意事项
参考《阿里巴巴Java开发手册》,掌握场景场景中集合使用的注意事项和原理分析
1.集合判空
判断集合内部元素是否为空,建议使用isEmpty()方法,而不是size()==0
因为isEmpty()的可读性更好,且时间复杂度为O(1);一些集合的size方法的时间复杂度不为O(1)
2.集合转Map
使用 java.util.stream.Collectors 类的 toMap() 方法转为 Map 集合时,一定要注意当 value 为 null 时会抛 NPE 异常
class User{
private String name;
private String email;
public User(String name, String email) {
this.name = name;
this.email = email;
}
// getter\setter
}
// 集合转Map
class ListToMapDemo{
public static void main(String[] args) {
List<User> users = new ArrayList<User>();
users.add(new User("John", "123456@qq.com"));
users.add(new User("Jane", null));
// NPE
users.stream().collect(Collectors.toMap(User::getName, User::getEmail));
}
}
// output
Exception in thread "main" java.lang.NullPointerException
at java.util.HashMap.merge(HashMap.java:1225)
at java.util.stream.Collectors.lambda$toMap$58(Collectors.java:1320)
at java.util.stream.ReduceOps$3ReducingSink.accept(ReduceOps.java:169)
at java.util.ArrayList$ArrayListSpliterator.forEachRemaining(ArrayList.java:1380)
at java.util.stream.AbstractPipeline.copyInto(AbstractPipeline.java:481)
at java.util.stream.AbstractPipeline.wrapAndCopyInto(AbstractPipeline.java:471)
at java.util.stream.ReduceOps$ReduceOp.evaluateSequential(ReduceOps.java:708)
at java.util.stream.AbstractPipeline.evaluate(AbstractPipeline.java:234)
at java.util.stream.ReferencePipeline.collect(ReferencePipeline.java:499)
at com.noob.collection.ListToMapDemo.main(CollectionDemo.java:40)
根据源码分析:toMap=》map.merge =》对value做非空判断
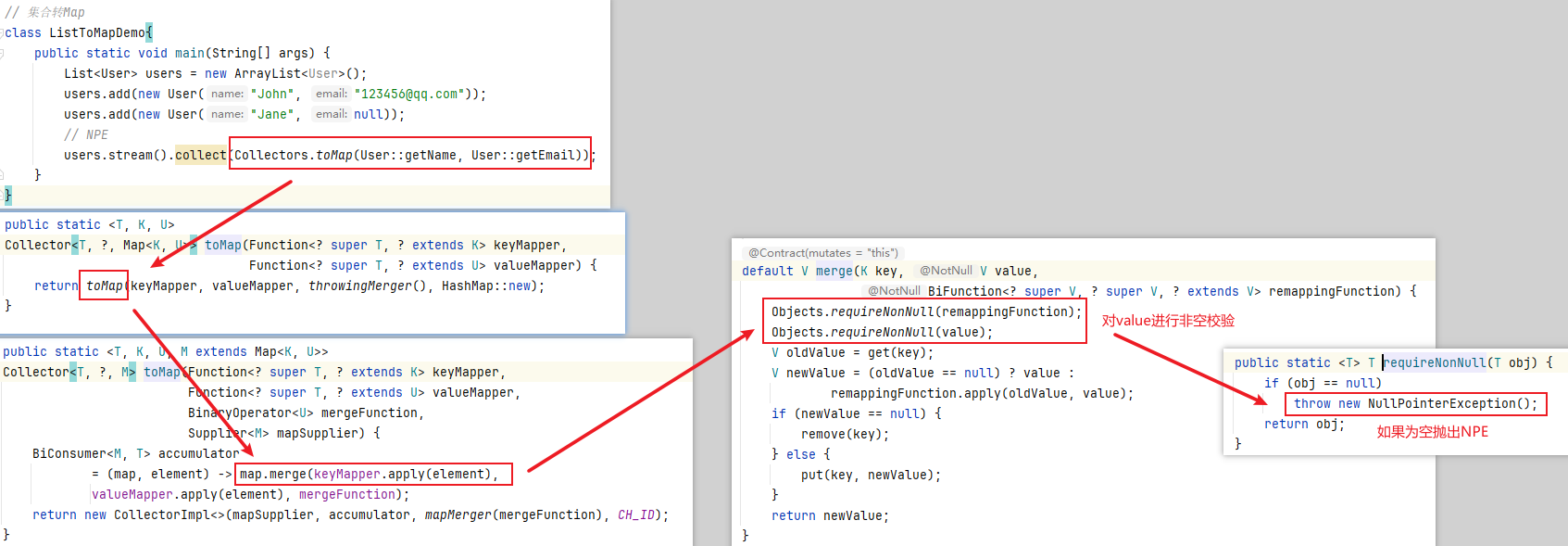
3.集合遍历
不要在 foreach 循环里进行元素的 remove/add 操作。remove 元素请使用 Iterator 方式,如果并发操作,需要对 Iterator 对象加锁
// 集合遍历(不要做增、删元素操作)
class IteratorDemo{
public static void main(String[] args) {
List<String> strList = new ArrayList<>();
strList.add("John");
strList.add("Jane");
strList.add("noob");
// 错误示范:在for、foreach遍历集合的时候增删元素
for (String str : strList) {
// strList.remove(str); // ConcurrentModificationException
// strList.add("new"); // ConcurrentModificationException
}
// 正确示例
Iterator<String> iterator = strList.iterator();
while (iterator.hasNext()) {
String str = iterator.next();
if ("noob".equals(str)) {
iterator.remove();
}
}
System.out.println(strList);
}
}
foreach语法(语法糖)底层还是依赖与Iterator(可以通过反编译确认),但是在循环过程中的增删操作都是调用集合自己的方法,而不是Iterator的add、remove方法,Iterator就会莫名其妙发现自己已有元素被add、remove,此时集合中的fail-fast机制就会被触发,即抛出一个ConcurrentModificationException异常来提示用户发生了并发修改异常。
fail-fast是一种错误检测机制,一旦检测到可能发生错误,就立马抛出异常,程序不继续往下执行,此处Java集合通过引入fail-fast机制,当多个线程对同一个集合的内容进行操作时,就可能会产生fail-fast事件。但结合上述案例分析,单线程场景下也可能会触发fail-fast事件
进一步跟踪错误信息,可以看到集合中定义了一个modCount用于记录集合被实际修改的次数,expectedModCount 是 ArrayList中的一个内部类——Itr中的成员变量,用于表示这个迭代器预期该集合被修改的次数。其值随着Itr被创建而初始化。只有通过迭代器对集合进行操作,该值才会改变。
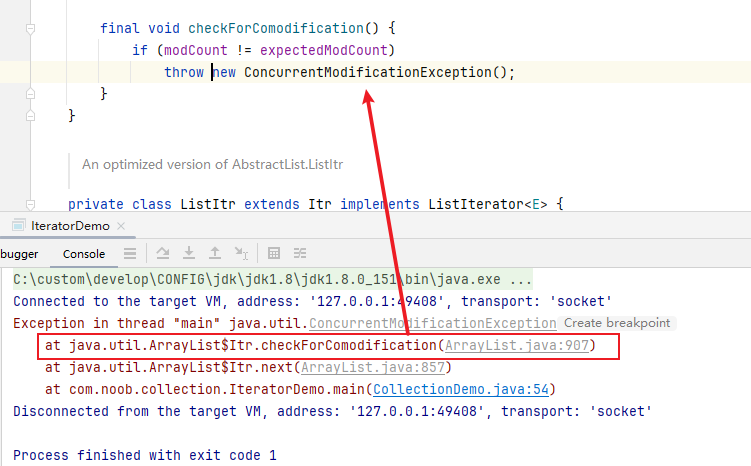
确认add、remove方法(此处注意跟踪的是ArrayList的add、remove方法(而非迭代器中的add、remove方法)),会发现在执行add、remove方法的时候对modCount进行了修改,就会导致modCount和expectedModCount 不一致,进而抛出ConcurrentModificationException异常
Java8开始,可以使用 Collection#removeIf()方法删除满足特定条件的元素
// Java8 可使用removeIf来删除满足特定条件的元素
List<Integer> list = new ArrayList<>();
for (int i = 1; i <= 10; ++i) {
list.add(i);
}
list.removeIf(filter -> filter % 2 == 0); /* 删除list中的所有偶数 */
System.out.println(list); /* [1, 3, 5, 7, 9] */
除了Iterator进行遍历操作,还可使用普通的for循环或者使用fail-safe的集合类
java.util包下面的所有的集合类都是 fail-fast 的,而java.util.concurrent包下面的所有的类都是 fail-safe 的
4.集合去重
可以利用 Set 元素唯一的特性,可以快速对一个集合进行去重操作,避免使用 List 的 contains() 进行遍历去重或者判断包含操作
// 集合去重
class RemoveDuplicateDemo{
// Set 去重代码示例
public static <T> Set<T> removeDuplicateBySet(List<T> data) {
if (CollectionUtils.isEmpty(data)) {
return new HashSet<>();
}
return new HashSet<>(data);
}
// List 去重代码示例
public static <T> List<T> removeDuplicateByList(List<T> data) {
if (CollectionUtils.isEmpty(data)) {
return new ArrayList<>();
}
List<T> result = new ArrayList<>(data.size());
for (T current : data) {
if (!result.contains(current)) {
result.add(current);
}
}
return result;
}
}
5.集合转数组
使用集合转数组的方法,必须使用集合的 toArray(T[] array),传入的是类型完全一致、长度为 0 的空数组。
toArray(T[] array) 方法的参数是一个泛型数组,如果 toArray 方法中没有传递任何参数的话返回的是 Object类型数组
class ListToArrayDemo{
public static void main(String[] args) {
String [] sArr = new String[]{
"dog", "lazy", "a", "over", "jumps", "fox", "brown", "quick", "A"
};
List<String> list = Arrays.asList(sArr);
Collections.reverse(list);
// 没有指定类型的话会报错
sArr = list.toArray(new String[0]);
for (String s : sArr) {
System.out.print(s + "-");
}
}
}
// output
A-quick-brown-fox-jumps-over-a-lazy-dog-
由于 JVM 优化,new String[0]作为Collection.toArray()方法的参数现在使用更好,new String[0]就是起一个模板的作用,指定了返回数组的类型,0 是为了节省空间,因为它只是为了说明返回的类型
6.数组转集合
Arrays.asList():将一个数组转化为集合
`Arrays.asList()`class ArrayToListDemo{
public static void main(String[] args) {
String[] myArray = {"Apple", "Banana", "Orange"};
List<String> myList = Arrays.asList(myArray); // 等价于List<String> myList = Arrays.asList("Apple","Banana", "Orange");
System.out.println(myList);
}
}
a.注意转化的数组类型
Arrays.asList() 是泛型方法,传递的数组必须是对象数组,而不是基本类型
例如此处案例:直接传入myArray原生数据类型数组,此时通过Arrays.asList 转化获取到的不是数组中的元素,而是将整个数组对象当作一个元素进行转化,此时获取到的List只有一个int[]类型的数组。
int[] myArray = {1, 2, 3};
// 传入原生数据类型数组,Arrays.asList得到的参数不是数组中的元素而是数组对象本身
List myList = Arrays.asList(myArray);
System.out.println(myList.size());// 1
System.out.println(myList.get(0));// 数组地址值
// System.out.println(myList.get(1));// 报错:ArrayIndexOutOfBoundsException
// 即此时List中的唯一元素就是这个myArray数组(也就解释了上面的越界异常)
int[] array = (int[]) myList.get(0);
System.out.println(array[1]);// 2
要解决上面的问题,回归方法本身,将基本类型数组转化为对象类型数组即可,此处则引用到包装类型数组进行转化即可
// 更正:调整为对应的包装类型,数组中的每个元素转为对应的List元素
Integer[] arr = {1, 2, 3};
List transferList = Arrays.asList(arr);
System.out.println(transferList.size()); // 3
b.使用集合的修改方法会抛出异常
// 误区2:使用集合的修改方法:add()、remove()、clear()会抛出异常
List list = Arrays.asList(1, 2, 3);
list.add(4);//运行时报错:UnsupportedOperationException
list.remove(1);//运行时报错:UnsupportedOperationException
list.clear();//运行时报错:UnsupportedOperationException
跟踪Arrays.asList源码,可以看到该方法返回的并不是 java.util.ArrayList ,而是 java.util.Arrays 的一个内部类,且这个内部类并没有实现集合的修改方法或者说并没有重写这些方法,进而导致异常。
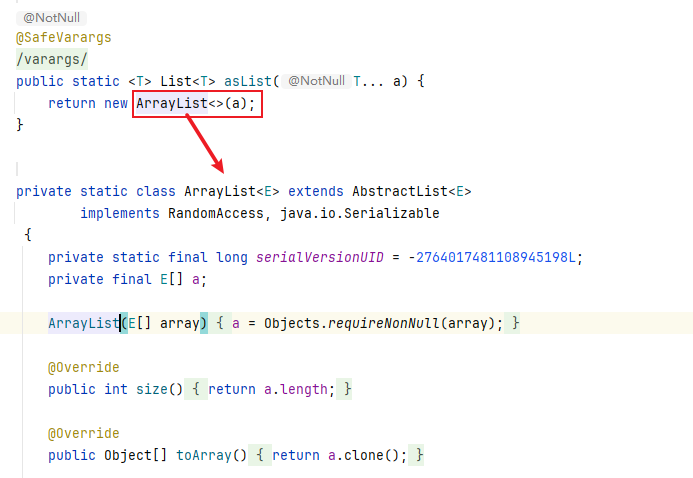
可以查看其继承的AbstractList抽象类,对这些方法进行了定义,如果子类没有重写这些方法就会使用父类的方法,则可定位到具体的问题(可看到AbstractList的实现是抛出异常)
public E remove(int index) {
throw new UnsupportedOperationException();
}
public boolean add(E e) {
add(size(), e);
return true;
}
public void add(int index, E element) {
throw new UnsupportedOperationException();
}
public void clear() {
removeRange(0, size());
}
protected void removeRange(int fromIndex, int toIndex) {
ListIterator<E> it = listIterator(fromIndex);
for (int i=0, n=toIndex-fromIndex; i<n; i++) {
it.next();
it.remove();
}
}
为了解决上面的问题,则要正确地将数组转化为ArrayList,可参考多种实现方式
方案1:
//JDK1.5+
static <T> List<T> arrayToList(final T[] array) {
final List<T> l = new ArrayList<T>(array.length);
for (final T s : array) {
l.add(s);
}
return l;
}
Integer [] myArray = { 1, 2, 3 };
System.out.println(arrayToList(myArray).getClass());//class java.util.ArrayList
方案2:最简便地方法
List list = new ArrayList<>(Arrays.asList("a", "b", "c"))
方案3:Java8的Stream
Integer [] myArray = { 1, 2, 3 };
List myList = Arrays.stream(myArray).collect(Collectors.toList());
//基本类型也可以实现转换(依赖boxed的装箱操作)
int [] myArray2 = { 1, 2, 3 };
List myList = Arrays.stream(myArray2).boxed().collect(Collectors.toList());
方案4:Guava
对于不可变集合,你可以使用ImmutableListopen in new window类及其of()open in new window与copyOf()open in new window工厂方法:(参数不能为空)
List<String> il = ImmutableList.of("string", "elements"); // from varargs
List<String> il = ImmutableList.copyOf(aStringArray); // from array
对于可变集合,你可以使用Listsopen in new window类及其newArrayList()open in new window工厂方法:
List<String> l1 = Lists.newArrayList(anotherListOrCollection); // from collection
List<String> l2 = Lists.newArrayList(aStringArray); // from array
List<String> l3 = Lists.newArrayList("or", "string", "elements"); // from varargs
方案5:Apache Commons Collections
List<String> list = new ArrayList<String>();
CollectionUtils.addAll(list, str);
方案6:使用 Java9 的 List.of()方法
Integer[] array = {1, 2, 3};
List<Integer> list = List.of(array);