【nest】数据爬取
【nest】数据爬取
项目介绍
基于nest构建爬虫项目,用于自动爬取数据。
项目源码
- 爬虫项目:项目源码对应boss-jd-spider、jd-spider-demo模块
项目构建
- npm、nest
- 数据存储:mysql数据库
jd-spider-demo:jd数据爬取
1.项目基础构建
创建项目并初始化
mkdir jd-spider-demo
cd jd-spider-demo
npm init -y
导入puppeteer
npm install --save puppteer
编写爬取逻辑
import puppeteer from 'puppeteer';
const browser = await puppeteer.launch({
headless: false,
defaultViewport:{
width: 0,
height: 0
}
});
const page = await browser.newPage();
await page.goto('https://www.zhipin.com/web/geek/job');
await page.waitForSelector('.job-list-box');
await page.click('.city-label', {
delay: 500
});
await page.click('.city-list-hot li:first-child', {
delay: 500
});
await page.focus('.search-input-box input');
await page.keyboard.type('后端',{
delay: 200
});
await page.click('.search-btn',{
delay: 1000
});
测试
# 执行指令
node ./test.js
跑代码之前先将package.json设置type为module,支持es module的import,否则会提示下列错误
import puppeteer from 'puppeteer';
^^^^^^
SyntaxError: Cannot use import statement outside a module
at wrapSafe (node:internal/modules/cjs/loader:1389:18)
at Module._compile (node:internal/modules/cjs/loader:1425:20)
参考修改package.json
{
"name": "jd-spider-demo",
"version": "1.0.0",
"main": "index.js",
"type":"module",
"scripts": {
"test": "echo \"Error: no test specified\" && exit 1"
},
"keywords": [],
"author": "",
"license": "ISC",
"description": "",
"dependencies": {
"puppeteer": "^22.8.0"
}
}
测试效果
这段代码执行会自动打开一个页面,执行自动化脚本文件,然后访问boss内容,通过输入指定参数类型,进行自动检索,例如此处输入【后端】
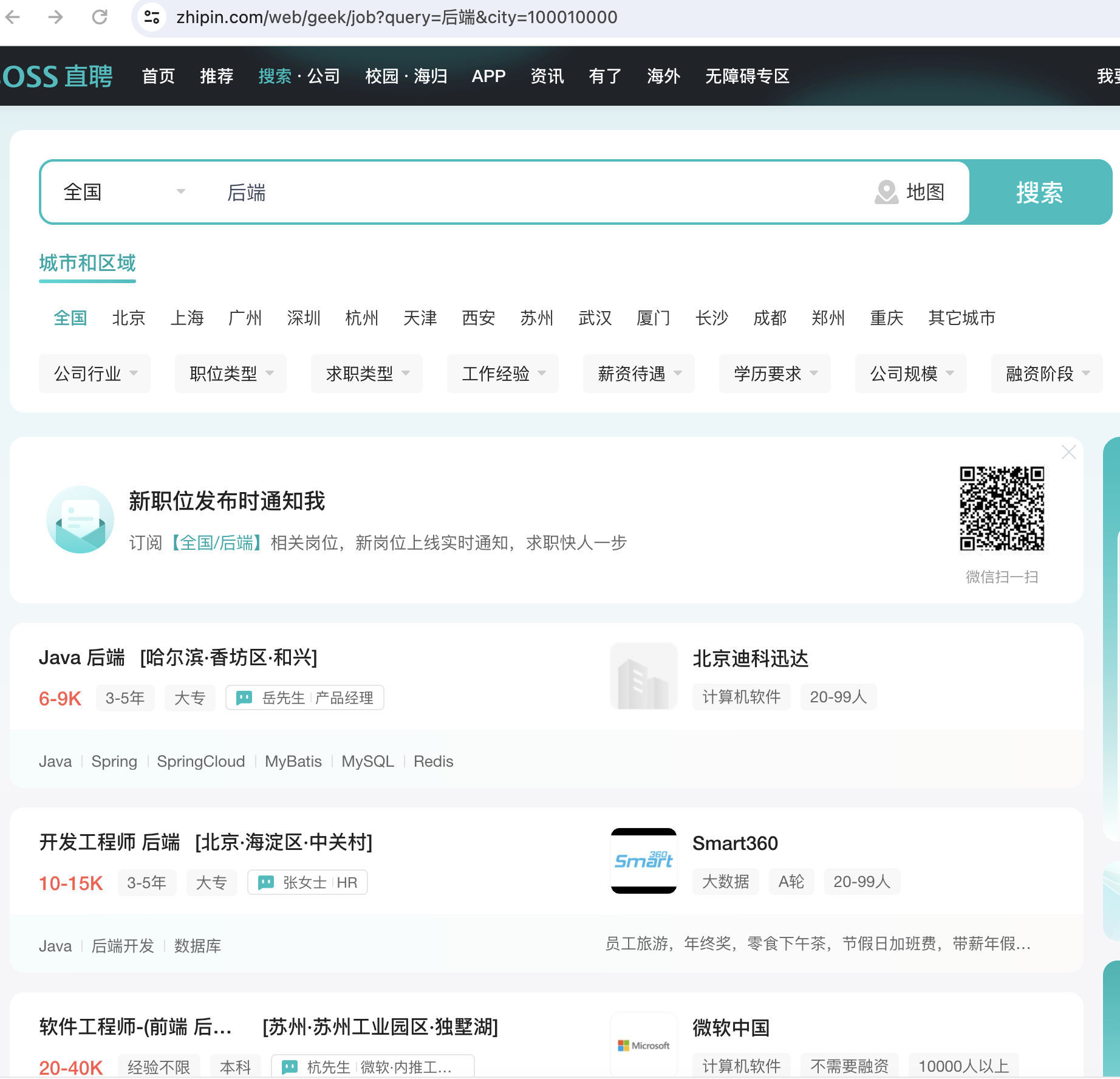
优化:查看检索的url,其实只要url带有type参数、city参数即可打开页面,不需要默认人工去进行检索,因此可以优化为直接访问指定配置的url
# 访问URL
https://www.zhipin.com/web/geek/job?query=后端&city=100010000
# testV2.js
import puppeteer from 'puppeteer';
const browser = await puppeteer.launch({
headless: false,
defaultViewport:{
width: 0,
height: 0
}
});
const page = await browser.newPage();
// 打开指定URL
await page.goto('https://www.zhipin.com/web/geek/job?query=后端&city=100010000');
await page.waitForSelector('.job-list-box');
2.解析爬取数据
经过上述步骤,获取到页面信息,随后根据捕获的页面信息,解析每个Elements参数,拿到数据记录
获取页数:options-pages 的倒数的第二个a标签信息
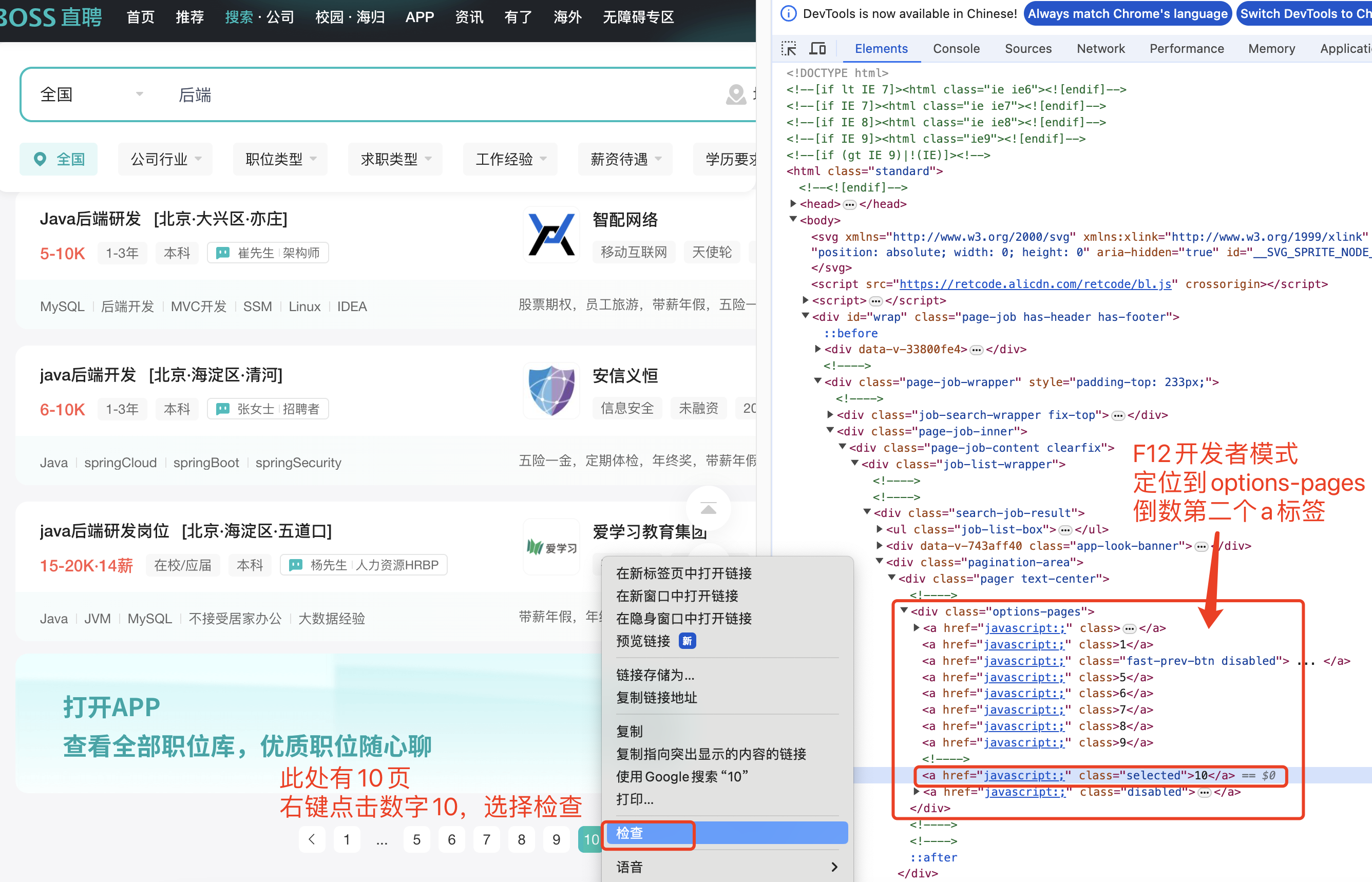
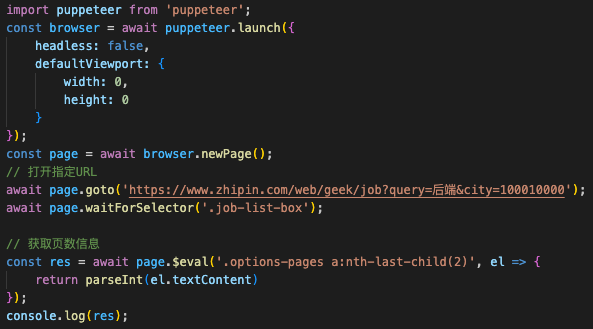
# 进一步完善代码,获取到结果信息
// 获取页数信息
const res = await page.$eval('.options-pages a:nth-last-child(2)',el =>{
return parseInt(el.textContent)
});
// 打印数据到控制台
console.log(res);
遍历数据列表:从每个dom中解析数据
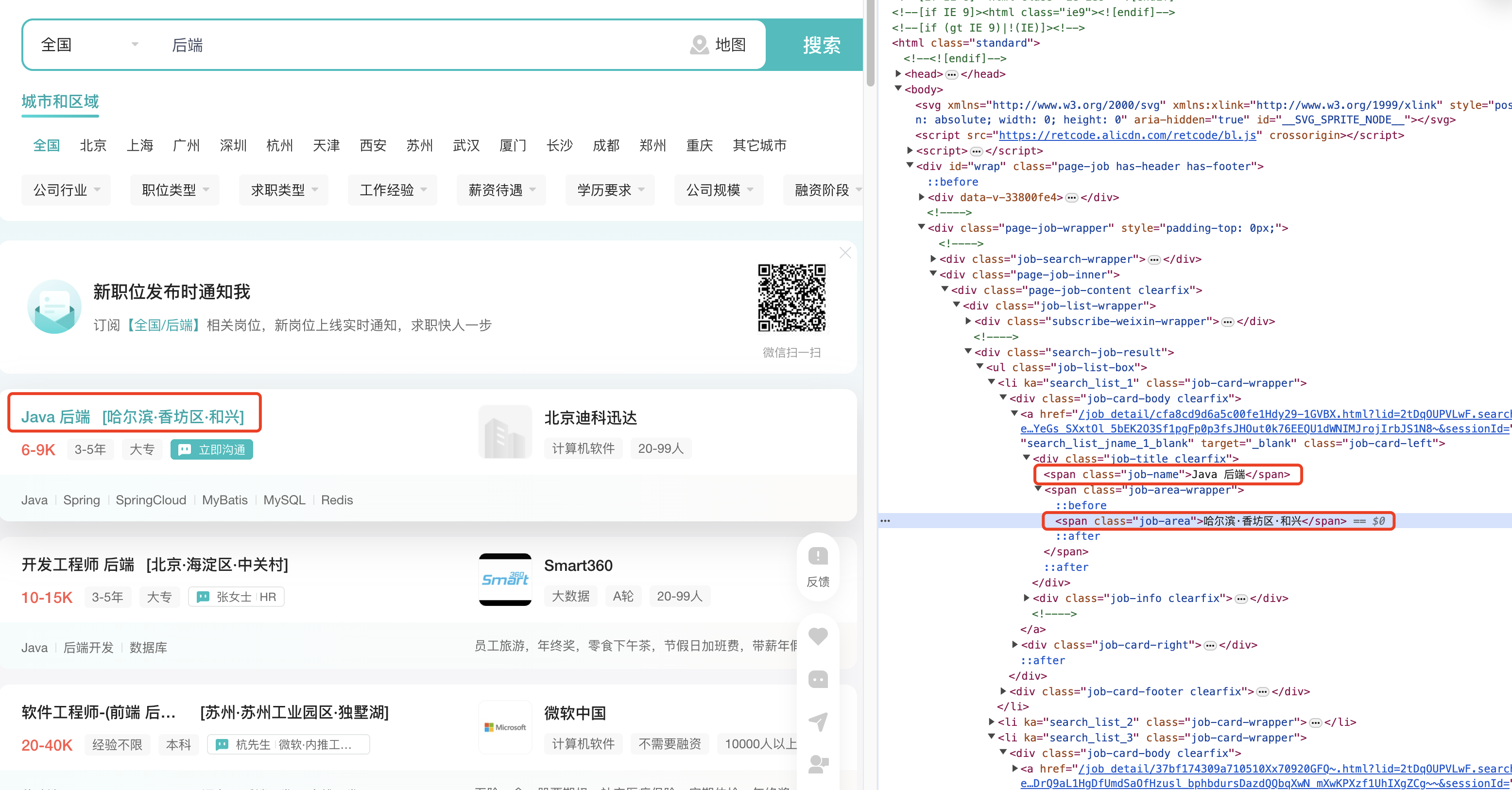
// 1.获取页数信息
const totalPage = await page.$eval('.options-pages a:nth-last-child(2)', el => {
return parseInt(el.textContent)
});
console.log('检索页数:',totalPage);
// 2.遍历岗位信息数据列表
const allJobs = []; for (let i = 1; i <= totalPage; i++) {
// 依次打开每一页的内容
await page.goto('https://www.zhipin.com/web/geek/job?query=后端&city=100010000&page=' + i);
await page.waitForSelector('.job-list-box');
// 解析每个节点的数据
const jobs = await page.$eval('.job-list-box', el => {
return [...el.querySelectorAll('.job-card-wrapper')].map(item => {
return {
job: {
name: item.querySelector('.job-name').textContent,
area: item.querySelector('.job-area').textContent,
salary: item.querySelector('.salary').textContent
},
link: item.querySelector('a').href,
company: {
name: item.querySelector('.company-name').textContent
}
}
})
});
// 存储所有的数据信息
allJobs.push(...jobs);
}
console.log('检索结果:',allJobs);
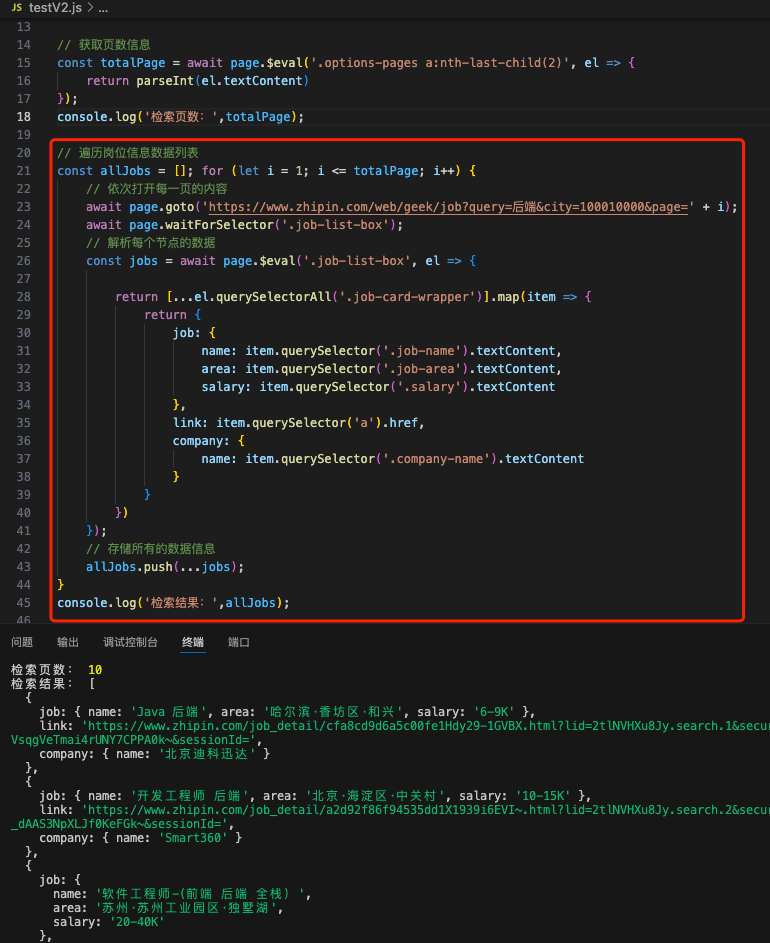
执行结果进行测试,可以拿到每个节点的岗位信息,程序执行会自动打开每一页并爬取岗位数据的基本信息。
岗位详情获取:基于上述,可以拿到每个列表子项信息,需要进一步点击链接进入详情页面拿到岗位详情信息
点击链接,查看岗位详情,确认岗位详情数据节点内容
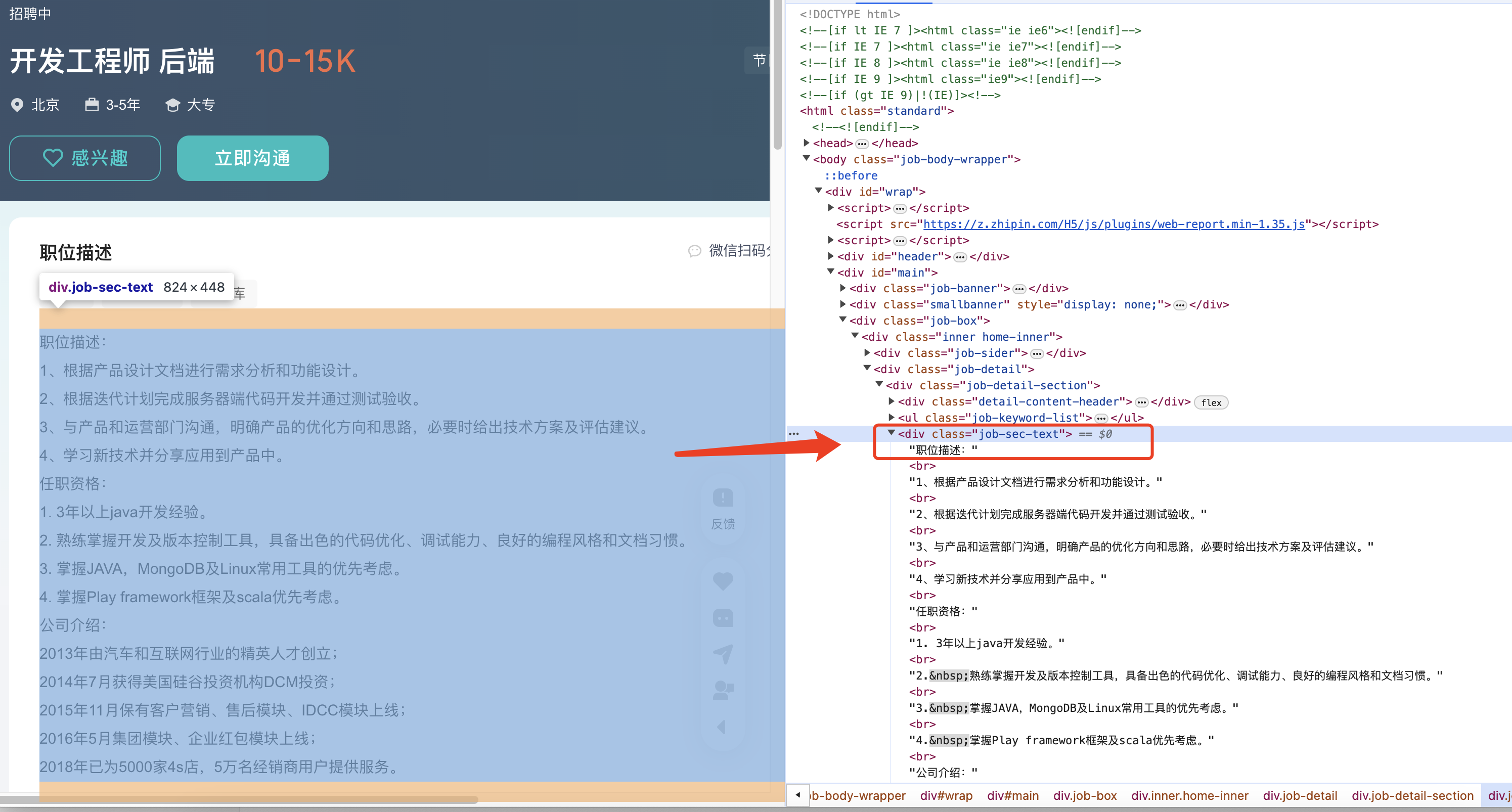
// 3.获取所有列表数据的详情信息
for(let i=0; i< allJobs.length;i ++){
await page.goto(allJobs[i].link);
try{
await page.waitForSelector('.job-sec-text');
const jd= await page.$eval('.job-sec-text', el => {
return el.textContent
});
allJobs[i].desc = jd;
console.log(allJobs[i]);
}catch(e){
// 捕获异常处理(例如页面打开可能会超时导致终止,直接跳过即可)
console.log('捕获异常....');
}
}
执行测试,页面在获取到所有的岗位信息之后,会根据当前捕获到的岗位详情,随后依次打开所有的数据列表详情信息,进一步解析岗位详情
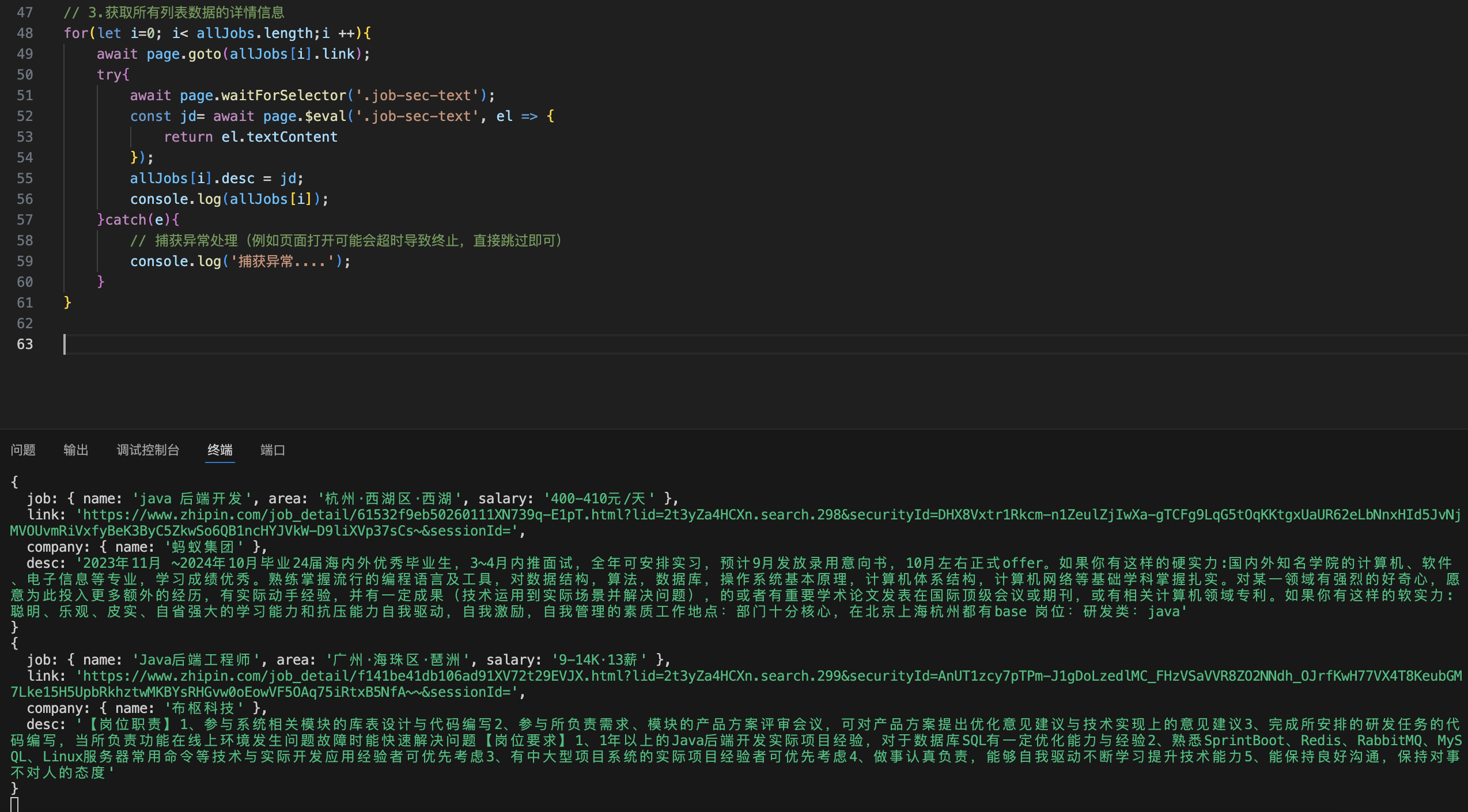
3.数据入库
项目初始化
基于上述解析完成的内容,则可构建后台进行数据入库,此处新建一个nest项目(boss-jd-spider),进行数据入库
# 如果没有安装nest需要手动安装(手动全局安装),否则提示zsh: command not found: nest
npm i -g @nestjs/cli
# 创建一个nest项目
nest new boss-jd-spider
- 会提示package管理器,按需选择(npm、yarn、pnpm)
# 切换到对应项目,启动
cd boss-jd-spider
npm run start
# 浏览器输入http://localhost:3000/访问,则可以看到Hello World
数据库环境配置
mysql数据库配置
配置数据库环境,此处使用mysql数据库。
项目配置数据库连接
在nest项目中使用TypeORM连接mysql数据库,先安装所需依赖
mysql2:数据库驱动,typeorm:orm框架、nestjs/typeorm是nest集成typeorm框架所需
npm install --save @nestjs/typeorm typeorm mysql2
1)在AppModule中引入TypeORM,指定数据库连接配置,src/app.module.ts参考源码文件如下
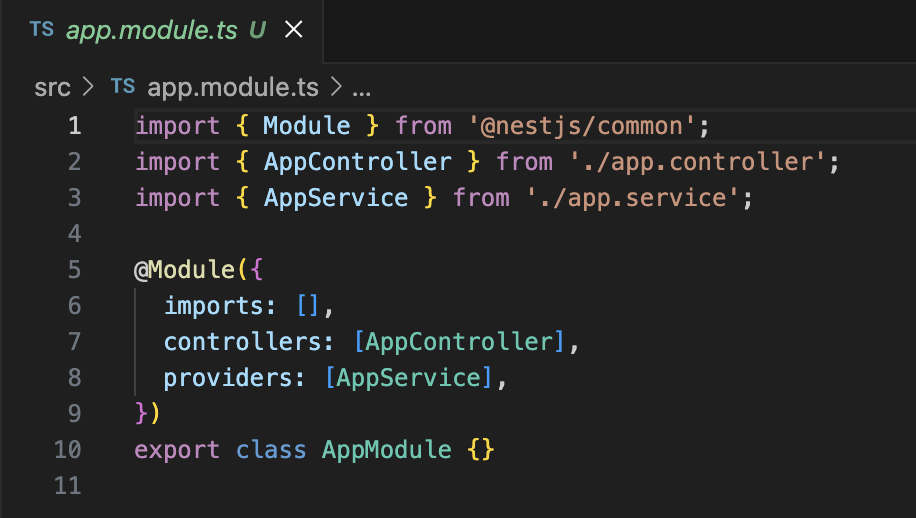
import { Module } from '@nestjs/common';
import { AppController } from './app.controller';
import { AppService } from './app.service';
import { TypeOrmModule } from '@nestjs/typeorm';
@Module({
imports: [
TypeOrmModule.forRoot({
type: "mysql",
host: "localhost",
port: 3306,
username: "root",
password: "root",
database: "boss-js-spider",
synchronize: true,
logging: true,
entities: [],
poolSize: 10,
connectorPackage: 'mysql2',
extra: {
authPlugin: 'sha256 password',
}
}),
],
controllers: [AppController],
providers: [AppService],
})
export class AppModule { }
2)创建entites/Job.ts(实体类构建):定义岗位信息(链接和描述可能会比较长,设置为text类型大文本存储)
import { Column, Entity, PrimaryGeneratedColumn } from "typeorm";
@Entity()
export class Job {
@PrimaryGeneratedColumn()
id: number;
@Column({
length: 30,
comment: '职位名称'
})
name: string;
@Column({
length: 20,
comment: '区域'
})
area: string;
@Column({
length: 10,
comment: '薪资范围'
})
salary: string;
@Column({
length: 600,
comment: '详情页链接'
})
link: string;
@Column({
length: 30,
comment: '公司名'
})
company: string;
@Column({
type: 'text',
comment: '职位描述'
})
desc: string;
}
3)然后在AppModule中引入实体定义
import { Job } from './entites/Job';
@Module({
imports: [
TypeOrmModule.forRoot({
...... 其他定义 ......
entities: [Job],
...... 其他定义 ......
}),
],
})
export class AppModule { }
4)启动项目,TypeORM会自动建表
如果数据库连接失败,则需检查AppModule的数据库连接配置
npm run start

此时可以查看mysql数据库确认数据表是否构建完成
数据解析入库
安装puppeteer依赖
npm install --save puppeteer
1)在AppController(src/app.controller.ts)中添加一个启动爬虫的接口(startSpider)
import { Controller, Get } from '@nestjs/common';
import { AppService } from './app.service';
@Controller()
export class AppController {
constructor(private readonly appService: AppService) {}
@Get()
getHello(): string {
return this.appService.getHello();
}
// 启动爬虫接口
@Get('start-spider')
startSpider(){
this.appService.startSpider();
return "爬虫已启动";
}
}
2)在AppService中实现爬虫接口(src/app.service.ts),并将上述步骤1、2中的爬虫实现搬过来
此处唯一需要变动的地方是需要将headless设置为true,此处不需要界面
import { Injectable } from '@nestjs/common';
import puppeteer from 'puppeteer';
@Injectable()
export class AppService {
getHello(): string {
return 'Hello World!';
}
// 实现爬虫
async startSpider() {
const browser = await puppeteer.launch({
headless: true, // 将headless设置为true,此处不需要界面
defaultViewport: {
width: 0,
height: 0
}
});
const page = await browser.newPage();
// 打开指定URL
await page.goto('https://www.zhipin.com/web/geek/job?query=后端&city=100010000');
await page.waitForSelector('.job-list-box');
// 1.获取页数信息
const totalPage = await page.$eval('.options-pages a:nth-last-child(2)', el => {
return parseInt(el.textContent)
});
console.log('检索页数:', totalPage);
// 2.遍历岗位信息数据列表
const allJobs = []; for (let i = 1; i <= totalPage; i++) {
// 依次打开每一页的内容
await page.goto('https://www.zhipin.com/web/geek/job?query=后端&city=100010000&page=' + i);
await page.waitForSelector('.job-list-box');
// 解析每个节点的数据
const jobs = await page.$eval('.job-list-box', el => {
return [...el.querySelectorAll('.job-card-wrapper')].map(item => {
return {
job: {
name: item.querySelector('.job-name').textContent,
area: item.querySelector('.job-area').textContent,
salary: item.querySelector('.salary').textContent
},
link: item.querySelector('a').href,
company: {
name: item.querySelector('.company-name').textContent
}
}
})
});
// 存储所有的数据信息
allJobs.push(...jobs);
}
console.log('检索结果:', allJobs);
// 3.获取所有列表数据的详情信息
for (let i = 0; i < allJobs.length; i++) {
await page.goto(allJobs[i].link);
try {
await page.waitForSelector('.job-sec-text');
const jd = await page.$eval('.job-sec-text', el => {
return el.textContent
});
allJobs[i].desc = jd;
console.log(allJobs[i]);
} catch (e) {
// 捕获异常处理(例如页面打开可能会超时导致终止,直接跳过即可)
console.log('捕获异常....');
}
}
}
}
3)启动程序,访问爬虫接口确认是否可以正常爬取数据
访问http://localhost:3000/start-spider
访问成功页面返回:爬虫已启动,检查控制台信息

出现上述问题是因为爬虫响应超时,需要调整代码。TimeoutError: Waiting for selector .job-list-box failed: Waiting failed: 3 这个错误通常发生在使用像是 Puppeteer 这样的浏览器自动化工具时,当试图等待页面上的一个选择器(在这个例子中是 .job-list-box 类)出现并且可以操作时。错误表明工具在指定的时间内没有能够找到或者交互(操作)这个选择器,因此触发了超时。
解决方法:
【1】增加等待时间:你可以增加等待选择器的时间来解决这个问题。在 Puppeteer 中,可以使用 page.waitForSelector(selector[, options]) 方法,通过传递一个带有更长 timeout 值的 options 对象来实现。
await page.waitForSelector('.job-list-box', { timeout: 60000 }); // 增加到60秒
【2】检查选择器是否正确:确保 .job-list-box 是正确的类名或其他选择器,并且它确实存在于页面上(这点可以通过前面的testV2.js进行排查)
【3】检查页面加载情况:确保在尝试等待选择器之前页面已经完全加载。可以使用 page.goto(url[, options]) 方法,并等待其 'load' 事件来确保页面加载完成
await page.goto(url, { waitUntil: 'load' });
await page.waitForSelector('.job-list-box');
【4】使用异步等待:如果是在循环中等待,可以考虑使用异步等待,以避免无限期阻塞事件循环
while (!document.querySelector('.job-list-box')) {
await new Promise(resolve => setTimeout(resolve, 100));
}
根据上述【1】、【2】方案调整均还是出现超时问题
此处将 需要将headless设置为false,让页面正常加载才能拿到数据(有待考究:测试下win、mac版本),控制台正常打印,爬取数据
或者大概预测爬取时间,增加等待选择器时间
4)数据库存储
在AppService中,定义实体将爬取到的数据封装好并存入数据库中
import { Job } from './entites/Job';
import { EntityManager } from 'typeorm';
@Injectable()
export class AppService {
@Inject(EntityManager)
private entityManager: EntityManager;
async startSpider() {
// ...... 数据爬取并解析 ......
// 数据入库(单条依次插入)
const job = new Job();
job.name = allJobs[i].job.name;
job.area = allJobs[i].job.area;
job.salary = allJobs[i].job.salary;
job.link = allJobs[i].link;
job.company = allJobs[i].company.name;
job.desc = allJobs[i].desc;
await this.entityManager.save(Job, job);
}
}
5)检查数据是否入库
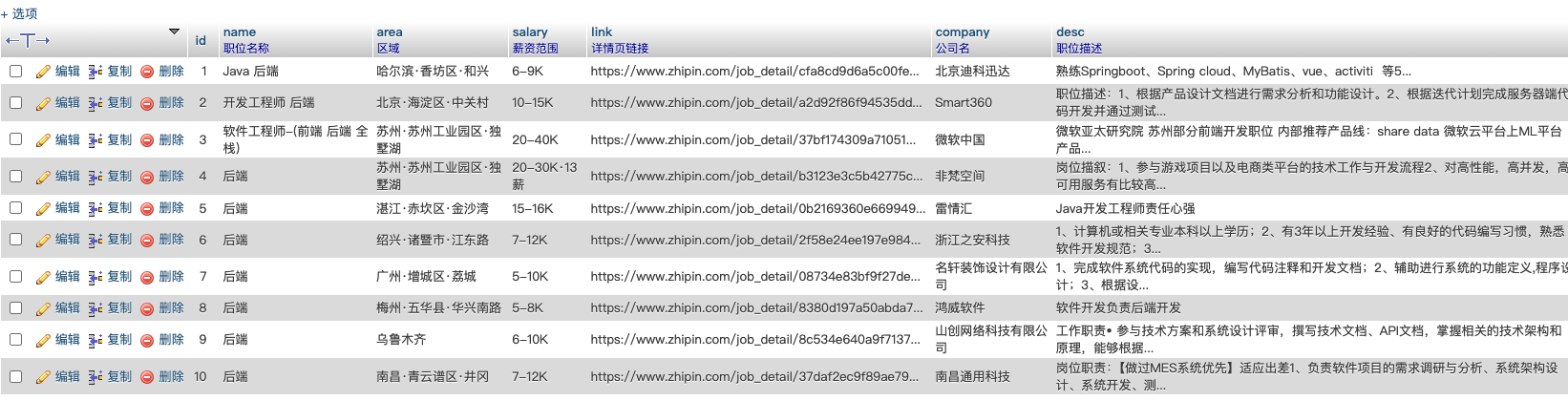
如果想要在前端实时查看爬取到的数据,可以通过sse来实时返回
// 实时查看爬取的数据
@Sse('stream')
stream() {
return new Observable((observer) => {
observer.next({ data: { msg: 'aaa' } });
/*
setTimeout(() => {
observer.next({ data: { msg: 'bbb' } });
}, 2000);
setTimeout(() => {
observer.next({ data: { msg: 'ccc' } });
}, 5000);
*/
});