【search-platform】②项目开发
【search-platform】②项目开发
前端项目
前端项目构建官方文档:Ant Design Vue
1.项目构建配置
创建vue项目
引入vue-cli脚手架
npm install -g @vue/cli
# npm uninstall -g vue/cli 如果要切换版本则先卸载原有npm
如果安装过程中出现问题,则根据提示解决,例如出现npm ERR! code CERT_HAS_EXPIRED,CERT_HAS_EXPIRED是一个由Node.js和npm抛出的错误,表示你正在尝试访问的服务器的SSL证书已经过期
# npm config list 查看npm配置
# 关闭设置代理
npm config set proxy false
# 清除npm缓存
npm cache clean --force
# 取消ssl验证
npm config set strict-ssl false
# 如果上述两步操作不行则再尝试更换镜像源
npm config set registry http://registry.cnpmjs.org
npm config set registry http://registry.npm.taobao.org
如果现存版本不匹配,则相应调整版本,此处调整为vue-cli 3.0
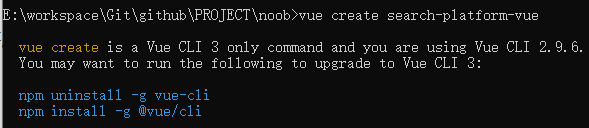
vue-cli在全局下已经有老版本的vue-cli(已经安装了2.0版本需要切换3.0版本),则需要相应卸载旧版本,但还是出现同样的问题则需要相应手动删除,找到C:\Users\【用户名】\AppData\Roaming\npm目录(这个目录存放安装在全局的vue相关的包),删除里面的vue文件随后重新执行指令安装
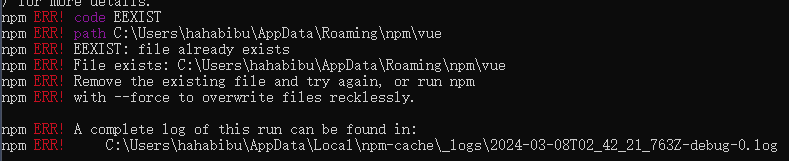
初始化vue项目(如果项目指令执行卡顿则考虑是网络加载问题,调整镜像耐心等待)
vue create search-platform-vue
根据提示完成项目配置
# 脚手架预设,要创建什么样的项目,要用到什么技术栈,一步步选择,此处可以选择整合的vue3,也可使用自定义特性构建
? Please pick a preset: (Use arrow keys)
> Default ([Vue 3] babel, eslint)
Default ([Vue 2] babel, eslint)
Manually select features
# 如果选择Manually则一步步操作即可(根据实际项目开发进行选择,避免项目臃肿)
Vue CLI v5.0.8
? Please pick a preset: Manually select features
# 根据提示上下移动,空格确认选择,enter进入下一步
? Check the features needed for your project: (Press <space> to select, <a> to toggle all, <i> to invert selection, and
<enter> to proceed)
>(*) Babel
(*) TypeScript # 前端项目校验
( ) Progressive Web App (PWA) Support # 移动端体验增强
(*) Router # vue的路由框架
( ) Vuex
( ) CSS Pre-processors
(*) Linter / Formatter
( ) Unit Testing
( ) E2E Testing
# 确认vue版本(选择3.0)
? Choose a version of Vue.js that you want to start the project with
> 3.x
2.x
# 确认是否使用类风格的组件语法(N,根据个人代码风格选择)
? Use class-style component syntax? No
# 确认是否要把babel和ts整合在一起(Y)
? Use Babel alongside TypeScript (required for modern mode, auto-detected polyfills, transpiling JSX)? Yes
# 选择路由方式(新手可以选择hash,N)
? Use history mode for router? (Requires proper server setup for index fallback in production) No
# 选择校验配置(如果比较介意强校验可以选只出现错误的时候校验,如果是做企业的项目则需要详细一点的校验)
? Pick a linter / formatter config:
ESLint with error prevention only
ESLint + Airbnb config
ESLint + Standard config
> ESLint + Prettier # 此处选择
# 选择什么时候进行校验(可以在保存的时候进行校验)
? Pick additional lint features: (Press <space> to select, <a> to toggle all, <i> to invert selection, and <enter> to
proceed)
>(*) Lint on save
( ) Lint and fix on commit
# 是否将Babel、ESLint等配置文件分离,可以直接选择默认即可
? Where do you prefer placing config for Babel, ESLint, etc.? (Use arrow keys)
> In dedicated config files
In package.json
# 是否保存项目预设
? Save this as a preset for future projects? No
# 选择哪种方式构建(此处选择npm进行构建)
? Pick the package manager to use when installing dependencies: (Use arrow keys)
> Use Yarn
Use NPM
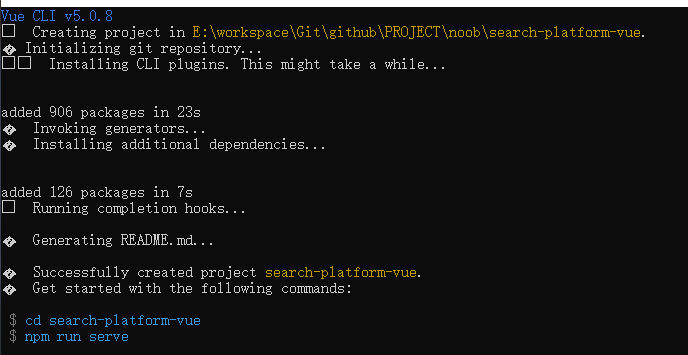
整合组件库
1.执行指令安装组件库
# 在指定项目目录下执行指令,安装 ant-design组件库
npm i --save ant-design-vue@next
2.在main.ts中引入代码配置引用(相应的样式文件也要单独引入)
官方文档可能有些许出入,需自行调整
// 引入ant-design组件库
import Antd from 'ant-design-vue';
import 'ant-design-vue/dist/antd.css';
// 配置引入
const app = createApp(App); // 此处App参数为main.ts中定义的
app.use(Antd);
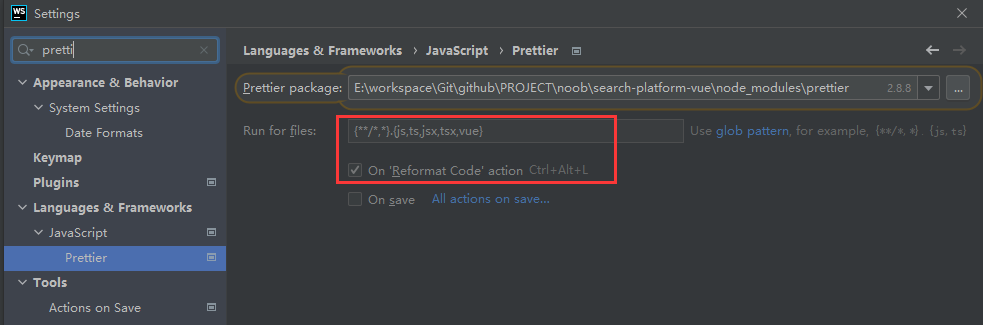
如果在用WebStorm进行前端项目编辑的时候出现飘红,可能是ESLint强校验触发校验,必须严格按照标准编写规范,可以在Settings下搜索Prettier自动代码美化插件进行配置,让它美化代码检测插件推动的语法(不建议关掉检测,要注意规范)
选择组件所在包:【项目目录】\search-platform-vue\node_modules\prettier
指定检测文件范围:(默认是没有对vue文件进行检测,需要相应配置加入即可)
勾选On Reformat Code action启用
完成上述配置点击应用,再回到开发页面,使用Ctrl+Alt+L快捷键便能一键自动美化代码
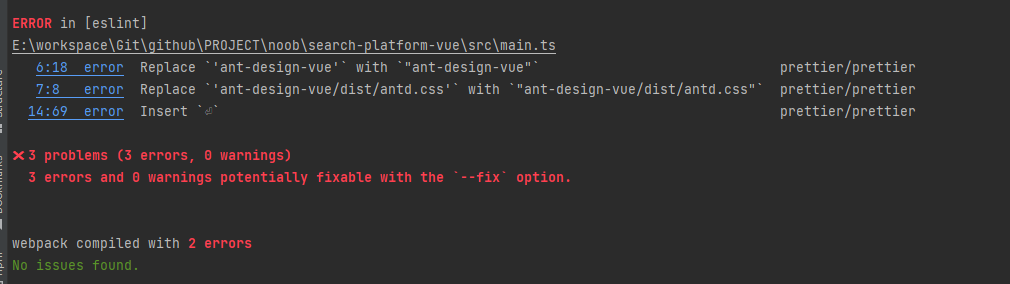
随后执行npm run serve指令启动前端项目,查看项目构建情况,确认无误进入下一步操作。如果出现下面这个问题则排查单双引号问题
除此之外,WebStorm还可安装Key Promoter X插件,用于提示快捷键输入(提示快捷键,便于熟悉快捷操作)
如果是VSCode则需要安装两个组件,随后根据组件提示处理即可
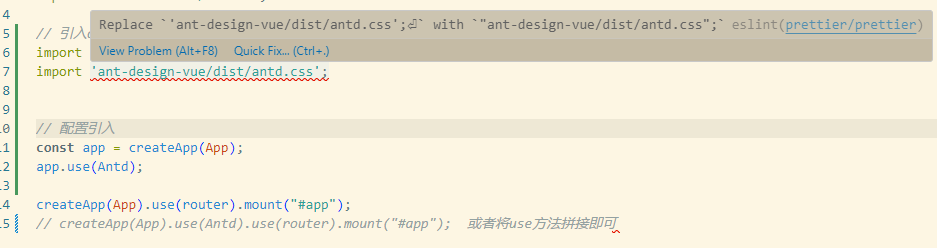
因为引入了ESLint校验,可能在日常开发过程中一点点代码格式都需要注意,如果引入文件路径不对则一一去排查文件路径,例如此处引入ant-design-vue的样式文件发现在对应node_modules下找不到该文件(需要单独引入)
项目瘦身
给基本的项目进行改造(调整为符合个人开发习惯即可,清理多余的页面)
此处去除多余的About.vue页面,修改views文件夹为pages,HomeView.vue重命名为IndexPage.vue
在重命名已有的文件时需要注意联动的变化,相应的index.ts中引用HomeView也要修改为对应的页面组件
【1】index.ts修改引用的主页组件
【2】App.vue删减无关的路由配置
(引入axios组件库:npm install --save axios)
为了更快理解项目功能模块实现,此处直接引入src相关文件内容,npm run install导入组件库,随后再根据代码结构和对应功能实现流程来理解代码构建的含义
2.模块功能开发说明
【1】如何实现页面操作双向同步
(PS:可以考虑借助第三方组件hooks操作,此处梳理逻辑自定义实现功能)
此处”双向同步”概念:用url记录页面搜索状态,当用户刷新页面时,能够从url还原之前的搜索状态
动态路由实现url与导航条联动,需要双向同步: url <=>页面状态,如果不借助第三方组件的话则可从另一个角度切入
核心小技巧:把同步状态改成单向,即只允许url来改变页面状态,不允许反向,从而避免双向联动导致状态变更异常
分步骤来实现,思路更清晰,而不用卡顿在两者互相改变的状态,只需控制一方主导
1.让用户在操作的时候,改变url地址(点击搜索框,搜索内容填充到url上;切换tab时,也要填充)
2.当url改变的时候,去改变页面状态(监听url的改变)
1.用户操作触发url联动
动态路由构建(切换不同的导航栏目的时候,url对应链接)
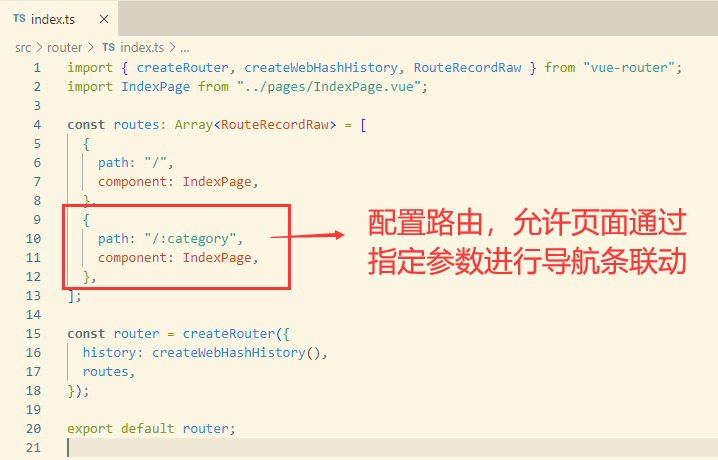
用户搜索的时候触发url联动变更(核心流程是监听用户点击搜索按钮,借助router组件参数联动修改拼接url)
实现效果:当用户输入文本信息,点击搜索的时候,会将搜索的内容自动将查询条件绑定到url中(http://localhost:8080/#/?text=用户搜索信息)
# 创建搜索条,添加监听触发方法
<template>
<div class="index-page">
<a-input-search
v-model:value="searchText"
placeholder="请输入搜索关键词"
enter-button="搜索"
size="large"
@search="onSearch"
/>
</div>
</template>
<script setup lang="ts">
// 1.引入useRoute方法
import { useRoute } from "vue-router";
// 2.构建router对象,用于传递参数
const router = useRouter();
const searchText = ref();
// 添加监听搜索触发方法,联动变更url
const onSearch = (value: string) => {
alter(value);
// 3.借助router将文本参数拼接到url,联动修改url内容
router.push({
query: {
text: value,
},
});
};
</script>
以此类推,当切换页面的时候也可通过监听tab切换对url进行联动变化
<script setup lang="ts">
// 监听tab变动的时候联动修改url
const onTabChange = (key: string) => {
router.push({
path: `/${key}`,
query: {
text: ""
}
});
};
</script>
<script setup lang="ts">
# 此处需注意url的联动修改受到两处影响,一是搜索触发、二是tab变更,因此在监听的时候还要将相关的参数带上,此外可能还涉及分页等参数,因此会出现多处的参数初始化复用
# 因此在设计上可以考虑将查询参数封装为一个变量,随后通过引用获取到相关变量值或者对其进行更改
// 1.初始化查询参数
const initSearchParams = {
type: activeKey,
text: "",
pageSize: 10,
pageNum: 1,
};
// 2.构建参数引用
const searchParams = ref(initSearchParams);
// 3.将对应参数直接传递给指定组件
const onTabChange = (key: string) => {
router.push({
path: `/${key}`,
query: searchParams.value,
});
};
</script>
2.url改变触发页面同步
# 监听url改变,将这个url数据的内容回传给页面进行封装
# 实现效果:监听url路由改变,当发生变化时将url的查询参数回绑给对应的查询框内容
<script setup lang="ts">
import { useRoute } from "vue-router";
import { ref, watchEffect } from "vue";
// 1.通过route拿到页面信息:路由参数
const route = useRoute();
// 2.通过vue提供的watchEffect方法监听(只要在这个函数里面用到的变量发生了改变,这个函数都会重新执行,进而实现监听)
watchEffect(() => {
// 3.改变searchParams参数
searchParams.value = {
text: route.query.text as string
} ;
});
</script>
# 扩展:类似的url变化除了联动文本框绑定之外,还要考虑其他查询参数的联动
<script setup lang="ts">
import { useRoute } from "vue-router";
import { ref, watchEffect } from "vue";
// 1.通过route拿到页面信息:路由参数
const route = useRoute();
// 2.通过vue提供的watchEffect方法监听(只要在这个函数里面用到的变量发生了改变,这个函数都会重新执行,进而实现监听)
watchEffect(() => {
// 3.改变searchParams参数
searchParams.value = {
...initSearchParams, // 对查询参数做一个兜底,就算没有数据也要对应传入查询参数
text: route.query.text,
type: route.params.category, // 获取路由后面跟的参数,与前面index.ts路由配置中参数名一致
} as any;
});
</script>
【2】前后端联调
axios交互
使用Axios向后端发送请求,可参考官方文档操作,核心步骤:
【1】前端整合Axios
npm install --save axios
【2】自定义Axios实例
在plugins文件夹中创建myAxios.ts,自定义规则,参考官网默认如下,可以在此基础上进一步完善(设置请求信息、添加各种拦截器等)
const instance = axios.create({
baseURL: 'https://some-domain.com/api/',
timeout: 1000,
headers: {'X-Custom-Header': 'foobar'}
});
【3】发送请求
// 1.引入自定义的axios组件
import myAxios from "@/plugins/myAxios";
// 2.自定义封装请求参数
const postQuery = {
key: value,
};
// 3.调用post方法与后台接口进行交互(此处会自动拼接myAxios配置的baseURL)
myAxios.post("search/all", postQuery).then((res: any) => {
// 请求成功后触发操作
console.log(res);
});
axios扩展
结合上面简单的案例可以实现前端与后端接口的交互,但基于这个基础上会考虑到一些通用的业务场景需要对一些交互进行封装
例如对返回结果的处理,通过请求返回的res包括了很多数据,需要对这个数据进行摘取进而拿到后端响应的数据(res.data),但是如果说每个请求都要这样处理的话,则考虑通过配置响应拦截器对数据统一进行处理,此外常见的还有一些错误处理等情况
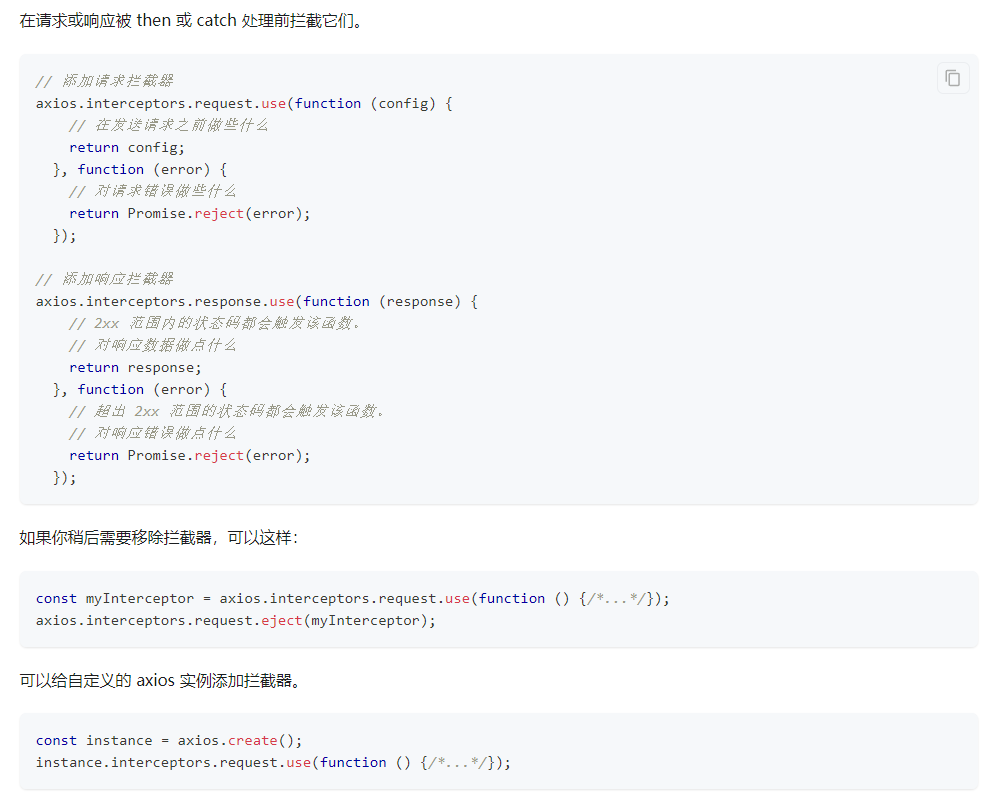
此处添加的是响应拦截器,当发出请求响应时进行拦截处理
import axios from "axios";
const instance = axios.create({
baseURL: "http://localhost:8102/api", // 调整请求本地后台接口
timeout: 10000, // 超时时间设置
headers: {}, // 请求头设置
});
// 添加响应拦截器
instance.interceptors.response.use(
function (response) {
// 2xx 范围内的状态码都会触发该函数。
// 处理响应数据
const data = response.data;
// 根据不同的状态码进行不同情况处理
if (data.code === 0) {
return data.data;
}
console.error("request error", data);
// 返回响应书局
return response.data;
},
function (error) {
// 超出 2xx 范围的状态码都会触发该函数。
// 对响应错误做点什么
return Promise.reject(error);
}
);
export default instance;
请求交互实现
结合上述操作可以构建前后端交互桥梁,随后根据业务逻辑编写代码完成数据交互,此处要实现的功能为用户搜索操作触发请求后端响应数据,随后刷新页面展示数据
在处理数据的时候不要想着一步到位,而是要思考自己拿到的是什么数据、要处理成什么结果。例如通过后台交互拿到的是一个数据列表,则可查看vue组件有什么好的方式去展示这个数据。
将IndexPage进行拆分:针对每个不同的栏目设置相应的组件进行处理,随后在IndexPage中引入这些组件进行数据交互
// 此处以文章展示为例子,创建PostList.vue构建文章展示信息
<template>
<a-list item-layout="horizontal" :data-source="props.postList">
<template #renderItem="{ item }">
<a-list-item>
<a-list-item-meta :description="item.content">
<template #title>
<a href="https://www.antdv.com/">{{ item.title }}</a>
</template>
<template #avatar>
<a-avatar :src="gege" />
</template>
</a-list-item-meta>
</a-list-item>
</template>
</a-list>
</template>
<script setup lang="ts">
import gege from "../assets/gege.jpg";
import { withDefaults, defineProps } from "vue";
interface Props {
postList: any[];
}
const props = withDefaults(defineProps<Props>(), {
postList: () => [],
});
</script>
<style scoped>
.gege {
width: 200px;
}
</style>
// IndexPage.vue中控制交互
后端项目
1.项目构建配置
项目配置
【1】引入springbootinit项目,构建通用模板配置
【2】创建数据库表,连接mysql数据库,修改数据库连接配置启动项目测试
接口测试
项目启动访问:http://localhost:8101/api/doc.html#/home,可在对应的controller进行接口测试交互
2.模块功能开发说明
如何获取不同的数据源?
【1】数据抓取流程
- 分析数据源,怎么获取?
- 拿到数据后,怎么处理?
- 写入数据库等存储
【2】数据抓取的方式
【1】直接请求数据接口
直接请求数据接口(最方便),可使用HttpClient、OKHttp、RestTemplate、Hutool(https://hutool.cn/)等客户端发送请求
如果有现成的数据接口,且该接口没有做一些复杂的防护(加密、验证等),则可通过调用接口获取数据
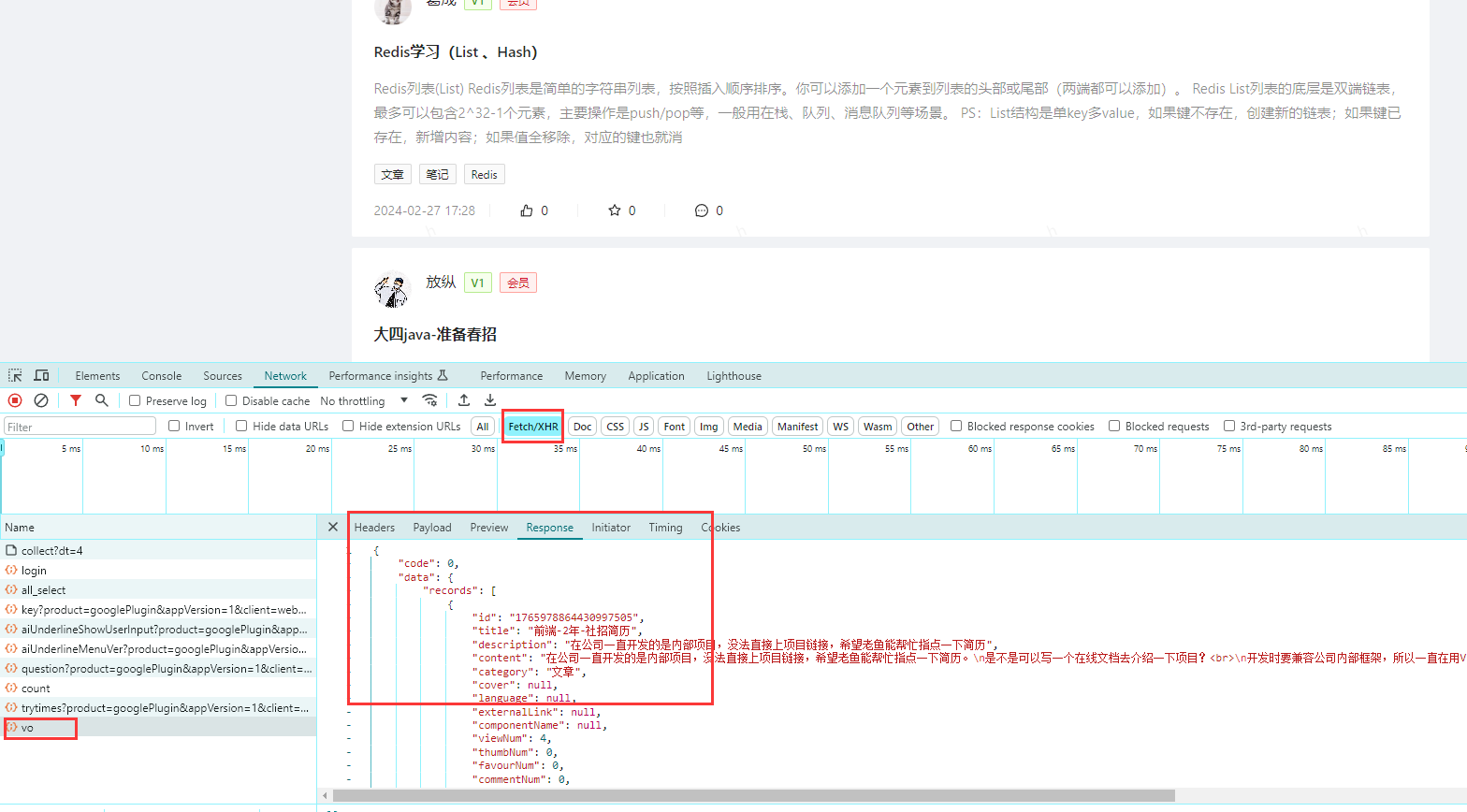
基于请求数据接口,则查看接口响应的数据与自身的数据库进行匹配,即通过程序请求某个数据接口获取数据,将对方接口的数据对应到自己的数据源中,然后再进行数据展示(此时页面展示可以通过自己的库去查询)
此处用hutool(一个大而全的java工具包)进行操作:在test包下测试创建数据爬取测试CrawlerTest
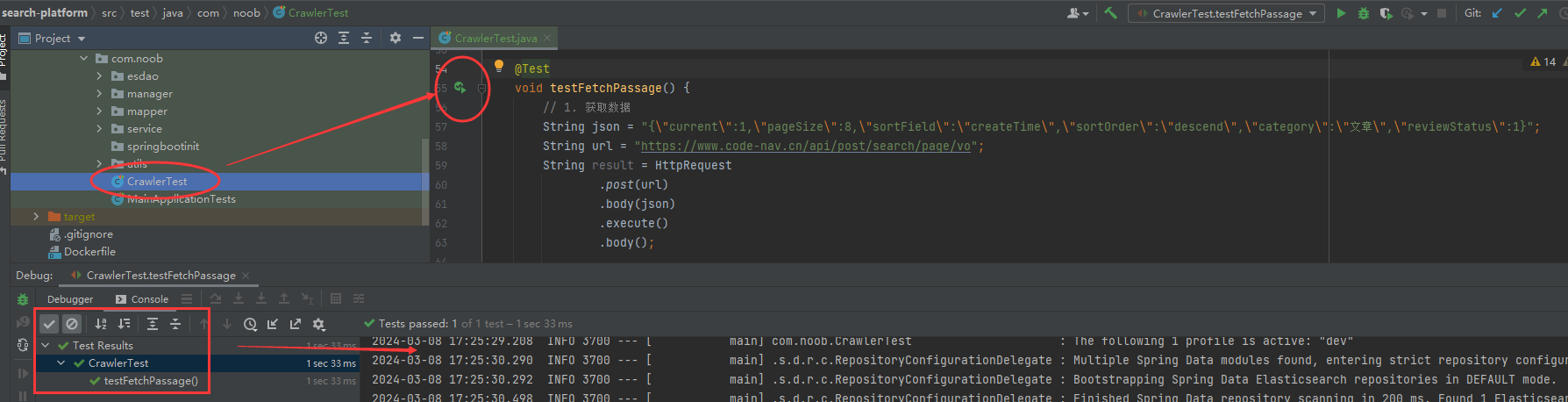
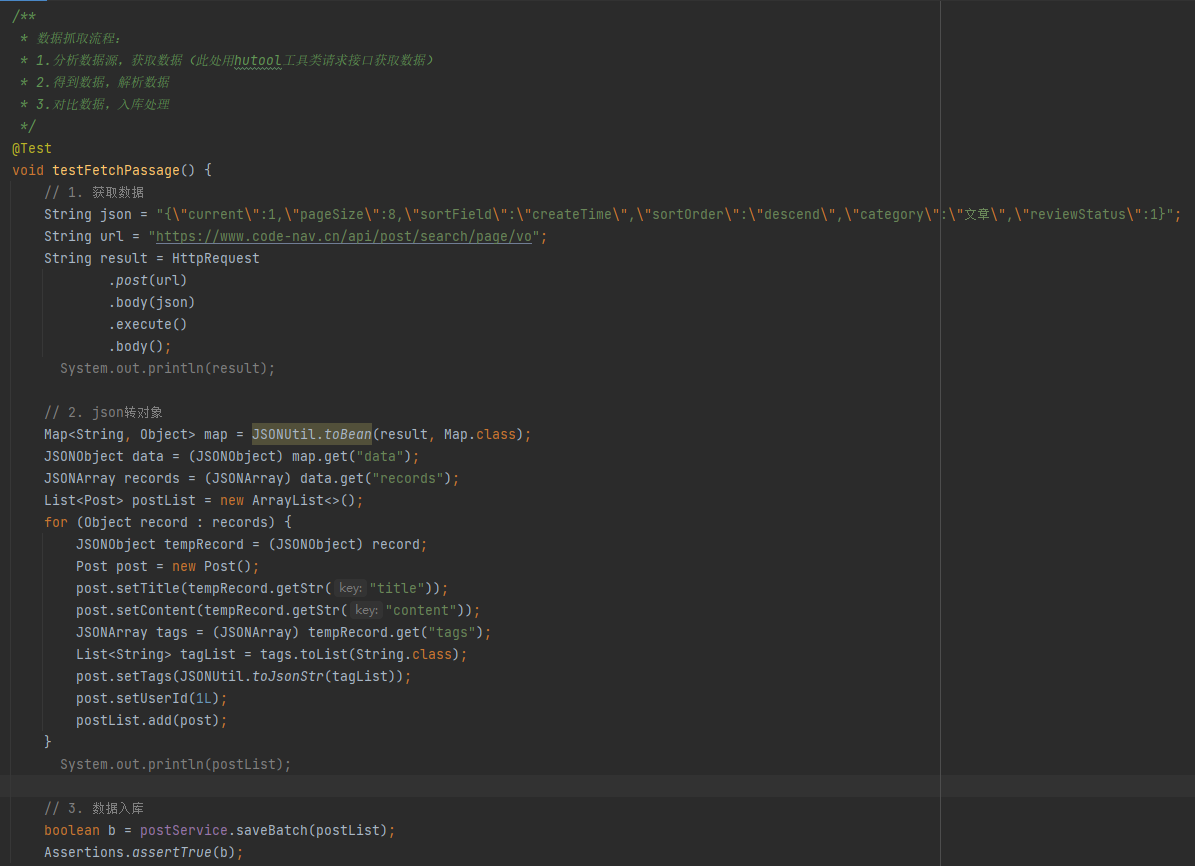
测试数据抓取是否成功,检查后台数据库数据是否正常入库
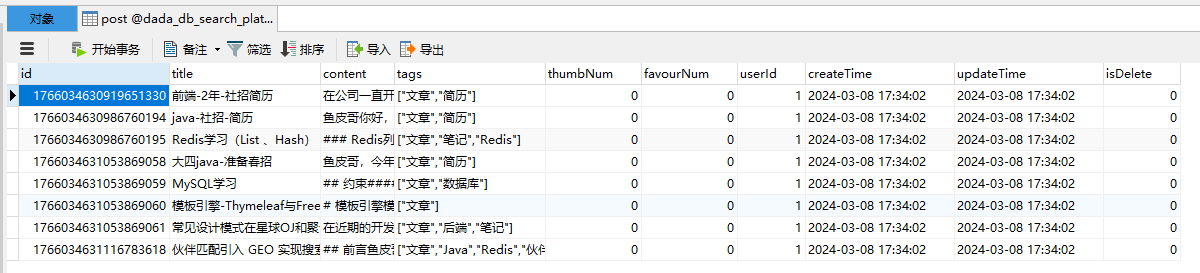
在idea中还可使用database栏访问数据库,完成驱动、用户名、密码、访问数据库名等配置即可,连接成功之后刷新数据库展示数据信息

【2】解析网页渲染的明文
等网页渲染出明文内容后,抓取整个前端页面的内容,然后再从前端完整页面中解析出需要的内容
【3】特殊场景下借助程序代码代替人为操作
有一些网站可能是动态请求的,他不会一次性加载所有的数据,而是要你点某个按钮、输入某个验证码才会显示出数据。可使用无头浏览器: java中的selenium、node.js中的puppeteer。
无头浏览器:即不用人工去执行某个操作,而是由程序代码代为执行,通过程序控制操作
数据源处理
【1】文章数据获取(接口获取)
如果内部系统没有,可以从互联网上获取基础数据=>爬虫
可使用该网站进行测试抓取: https://www.code-nav.cn/learn/passage (注意,仅做测试,不要频繁请求! ),获取到文章后要入库。
实现策略:离线抓取:定时获取或者只获取一次
定时器设定
在job/once包下创建FetchInitPostList.java,实现离线抓取文章列表,定时器设置为抓取一次(通过@Component控制,每次启动springboot项目的时候自动抓取一次,也可自定义设置定时规则,确保程序运行时定时触发抓取操作)
package com.noob.job.once;
import cn.hutool.http.HttpRequest;
import cn.hutool.json.JSONArray;
import cn.hutool.json.JSONObject;
import cn.hutool.json.JSONUtil;
import com.noob.model.entity.Post;
import com.noob.service.PostService;
import lombok.extern.slf4j.Slf4j;
import org.springframework.boot.CommandLineRunner;
import org.springframework.stereotype.Component;
import javax.annotation.Resource;
import java.util.ArrayList;
import java.util.List;
import java.util.Map;
/**
* 获取初始帖子列表
*/
// 取消注释后,每次启动 springboot 项目时会执行一次 run 方法
// @Component
@Slf4j
public class FetchInitPostList implements CommandLineRunner {
@Resource
private PostService postService;
@Override
public void run(String... args) {
// 1. 获取数据
String json = "{\"current\":1,\"pageSize\":8,\"sortField\":\"createTime\",\"sortOrder\":\"descend\",\"category\":\"文章\",\"reviewStatus\":1}";
String url = "https://www.code-nav.cn/api/post/search/page/vo";
String result = HttpRequest
.post(url)
.body(json)
.execute()
.body();
// System.out.println(result);
// 2. json 转对象
Map<String, Object> map = JSONUtil.toBean(result, Map.class);
JSONObject data = (JSONObject) map.get("data");
JSONArray records = (JSONArray) data.get("records");
List<Post> postList = new ArrayList<>();
for (Object record : records) {
JSONObject tempRecord = (JSONObject) record;
Post post = new Post();
post.setTitle(tempRecord.getStr("title"));
post.setContent(tempRecord.getStr("content"));
JSONArray tags = (JSONArray) tempRecord.get("tags");
List<String> tagList = tags.toList(String.class);
post.setTags(JSONUtil.toJsonStr(tagList));
post.setUserId(1L);
postList.add(post);
}
// System.out.println(postList);
// 3. 数据入库
boolean b = postService.saveBatch(postList);
if (b) {
log.info("获取初始化帖子列表成功,条数 = {}", postList.size());
} else {
log.error("获取初始化帖子列表失败");
}
}
}
【2】用户数据获取(自主收集)
网站用户信息一般都是自己的,无需从站外获取,可以通过用户注册或者用户管理等方式实现
【3】图片信息获取(页面解析获取)
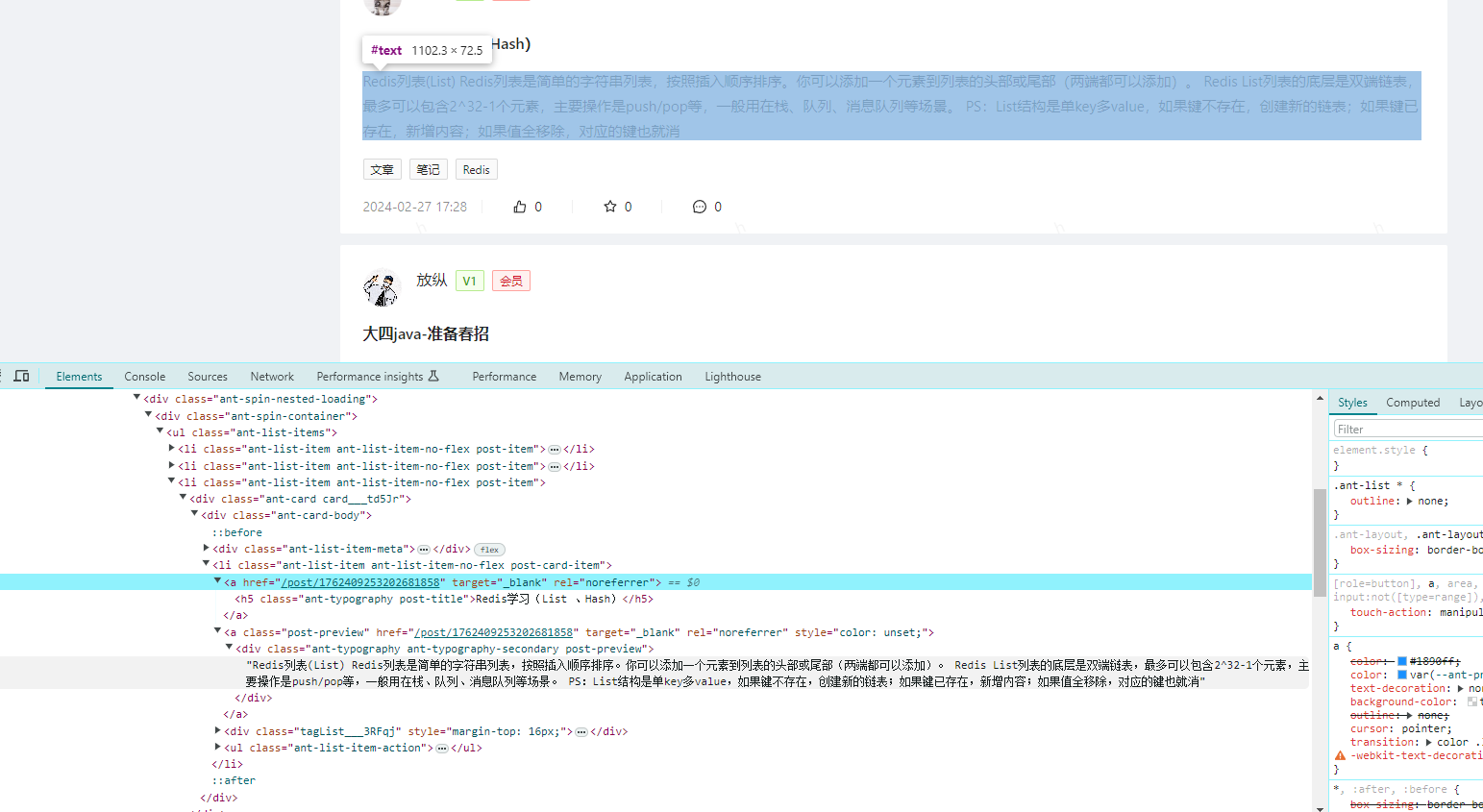
方式1:自主存储,图片信息可以从自己的数据库存储或者图床处获取,进而提供检索
方式2:实时抓取,本身项目数据库不存储这些信息,只是作为一个平台入口提供检索,当用户要搜索图片数据的时候直接通过别人的接口获取(网站/数据库)相当于借助外部海量图库进行检索,而不需要自己本地额外占用空间存储图片数据
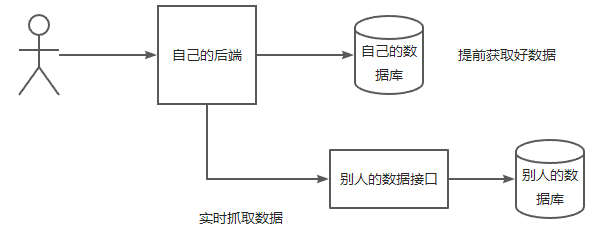
实现说明:当用户在检索图片的时候提供多方的数据供其参考,例如用户在我们的网站上搜索图片,可以检索出必应、百度等网站的图片。
不足之处:如果没有自身的数据图库,过于依赖外部数据,一旦外部数据出现偏差则极有可能对自身项目数据源造成一定的影响
流程分析
可以从必应上查看图片搜索数据,可以看到必应官网图片也是来自于不同网站的内容。且通过分析接口信息可以看到该网站并没有一个接口可以提供数据源,因此可以采用解析页面的方式进行数据源获取,解析每个节点的数据信息拿到关键的图片数据
解决方案:jsoup解析库:支持发送请求获取到HTML文档,然后从中解析出需要的字段。通过mvnrepository.com查阅相关信息
开发说明
【1】pom.xml中引入jsoup依赖
<!-- https://mvnrepository.com/artifact/org.jsoup/jsoup -->
<dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.15.3</version>
</dependency>
【2】创建测试类测试文档解析(定义Picture类封装重要的图片信息)
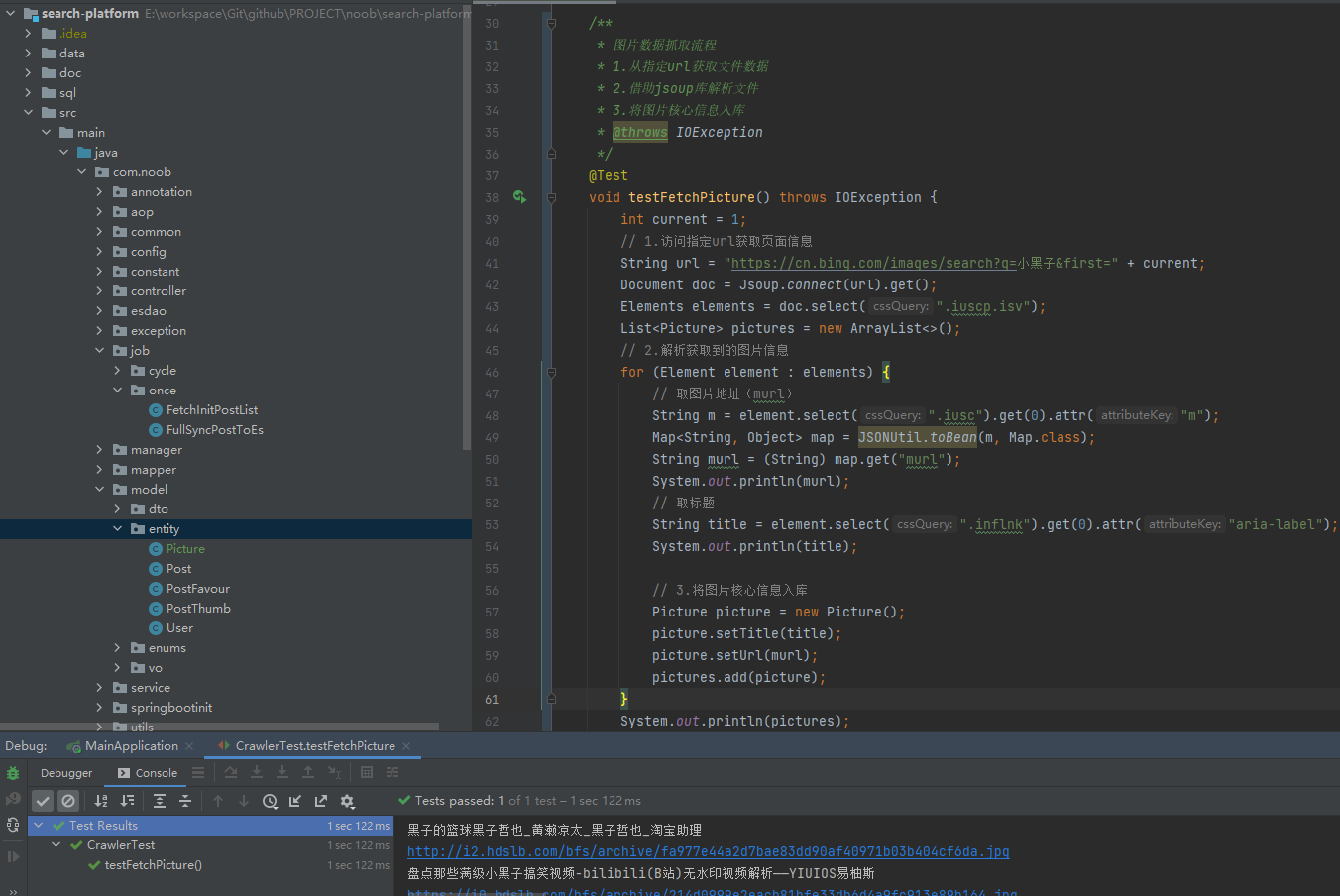
实时抓取
完成上述操作,可以通过访问url解析页面数据获取图片关键信息,随后可借助定时器完成定时抓取操作(如果信息要入库的话)
实际业务流程:当用户访问搜索页面,检索指定url获取关键图片信息,随后统一封装为list直接返回给前端即可(不需要额外入库,实现实时抓取)
数据交互
【1】基础数据交互
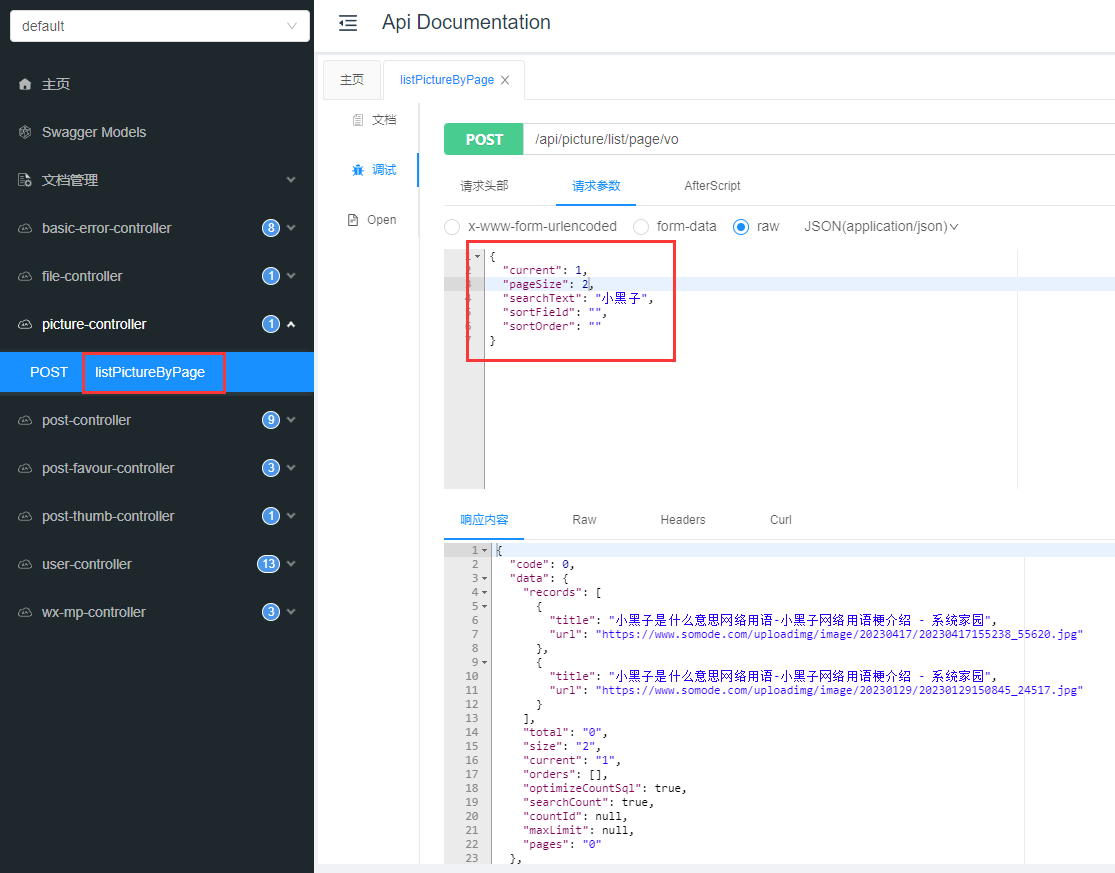
图片数据交互:提供图片数据接口
构建mvc层,完成图片数据接口封装,涉及类有PictureQueryRequest(图片查询请求参数)、PictureController(图片控制层)、PictureService(图片service层及其PictureServiceImpl)、Picture实体类
交互实现:接收前端传入参数,完成图片检索
接口测试:启动项目访问
扩展问题:为什么有些网站搜索前端不作分页而是滚动出现?涉及到一些分页性能问题
【2】业务场景分析优化
目前是在页面加载时,调用三个接口分别获取文章、图片、用户数据。
几种不同的业务场景:
【1】最简化的场景是用户点某个tab的时候,只调用这个tab的接口,比如: https://www.code-nav.cn/search/all?current= 2&pageSize= 8&searchText= &sortField=_ score&sortOrder= descend,前后端实现就是分别对应访问不同的url实现数据搜索
【2】如果是针对聚合内容的网页,其实可以一个请求搞定,比如: https://tophub.today/
【3】有可能还要查询其他的信息,比如其他数据的总数,同时给用户反馈,比如B站搜索页
根据实际情况去选择方式:
场景设计存在的问题:
【1】请求数量比较多,可能会受到浏览器的限制(不同类型浏览器会限制同时http发送请求的个数),如果说每个tab对应请求一次接口,当tab达到一定数量的时候则会受到限制。参考今日热榜,不同tab搜集的数据类型不同,如果用方式1完成则可能造成访问缓慢等问题
【2】请求不同接口的参数可能不一致,增加前后端沟通成本
【3】前端写调用多个接口的代码,重复代码
解决方案:
通过聚合接口的方式完成请求,当考虑前端页面加载一次性请求的资源比较多的时候,可以结合业务场景将接口进行聚合,然后通过前端请求参数的不同对接后台数据(相当于把前端请求多个数据接口的压力分摊到后台,由后台统一处理,进而避免前后端频繁交互请求的成本)
【3】聚合接口
概念梳理
后端工程师做聚合接口要结合实际场景分析,选择一种最优雅的方式给前端提供一个无记忆力负担和更低交互成本的接口,进而优化开发效率、提高系统性能等(讲到统一、聚合则要关注这块的内容)
结合上述业务场景分析,优化代码设计结构,通过采用聚合接口的方式完成数据交互操作,其开发思路参考如下(针对业务场景优化说明)
A.请求数量比较多,可能会收到浏览器的限制=>用一个接口请求完所有的数据(后端可以并发,几乎没有并发数量限制)
{
user = userService.query
post = postService .query
picture = pictureService . query
return user + post + picture
}
B.请求不同接口的参数可能不一致,增加前后端沟通成本=>用一个接口将请求参数统一,前端每次传固定的参数,后端去对参数进行转换
{
前端统一传 searchText 查询参数
后端把searchText 转换为userName => queryUser
}
C.前端写调用多个接口的代码,重复代码=>用一个接口,通过不同的参数去区分查询的数据源。
{
前端传type
调用后端同一个接口,后端根据type 调用不同的service 查询
比如: type = user 对应调用 userService.query
}
此处可以参考网站项目,请求同一个接口通过一个指定参数不同的值调用相应的service,如果传入的是一个数组值也可通过解析做处理
此外为了减少前后端交互成本,前后端可以约定一个统一的返回结果,例如用Page页面封装,基础结构基本相同,前端只需要解析响应数据展示即可
实现说明
构建说明
【1】后台:定义一个统一的后台接口接收参数、由后台处理返回响应数据
【2】前端:根据后台返回的参数进行数据封装(前后可抽离公共方法处理数据)
后台实现
后台实现
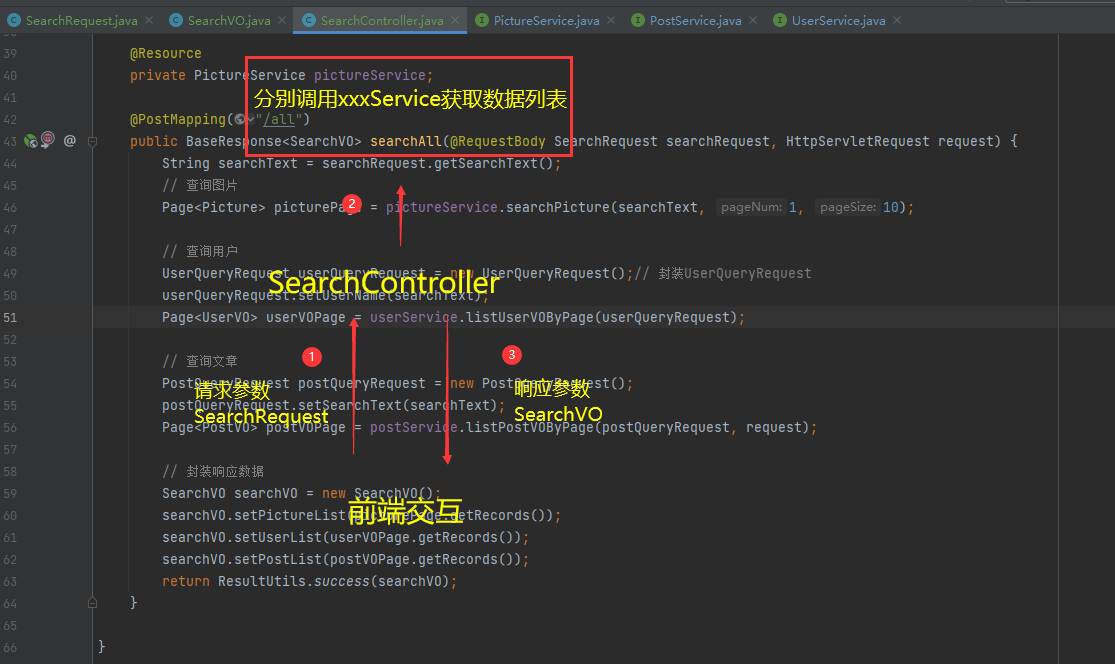
【1】定义SearchController提供一个接口searchAll接收参数SearchRequest,由后台统一处理返回响应数据
【2】SearchRequest中定义一个搜索词searchText,后台根据这个搜索词分别搜索用户、文章、图片等信息,随后返回查找到的所有数据
// 统一接口封装如下,其中需要引入相关的类则参考具体的代码实现,核心构建说明如下
【1】接收SearchRequest参数中的searchText
【2】将searchText数据进行封装,借助相关的Serivce对象调用相应的自定义分页查询进行数据检索
【3】定义SearchVO封装响应数据,将查找到的所有结果数据封装到对应的list集合,最终响应给到前端
【4】前端根据响应数据抽离公共方法完成数据解析并展示
/**
* 查询接口:聚合接口
*/
@RestController
@RequestMapping("/search")
@Slf4j
public class SearchController {
@Resource
private UserService userService;
@Resource
private PostService postService;
@Resource
private PictureService pictureService;
@PostMapping("/all")
public BaseResponse<SearchVO> searchAll(@RequestBody SearchRequest searchRequest, HttpServletRequest request) {
String searchText = searchRequest.getSearchText();
// 查询图片
Page<Picture> picturePage = pictureService.searchPicture(searchText, 1, 10);
// 查询用户
UserQueryRequest userQueryRequest = new UserQueryRequest();// 封装UserQueryRequest
userQueryRequest.setUserName(searchText);
Page<UserVO> userVOPage = userService.listUserVOByPage(userQueryRequest);
// 查询文章
PostQueryRequest postQueryRequest = new PostQueryRequest();
postQueryRequest.setSearchText(searchText);
Page<PostVO> postVOPage = postService.listPostVOByPage(postQueryRequest, request);
// 封装响应数据
SearchVO searchVO = new SearchVO();
searchVO.setPictureList(picturePage.getRecords());
searchVO.setUserList(userVOPage.getRecords());
searchVO.setPostList(postVOPage.getRecords());
return ResultUtils.success(searchVO);
}
}
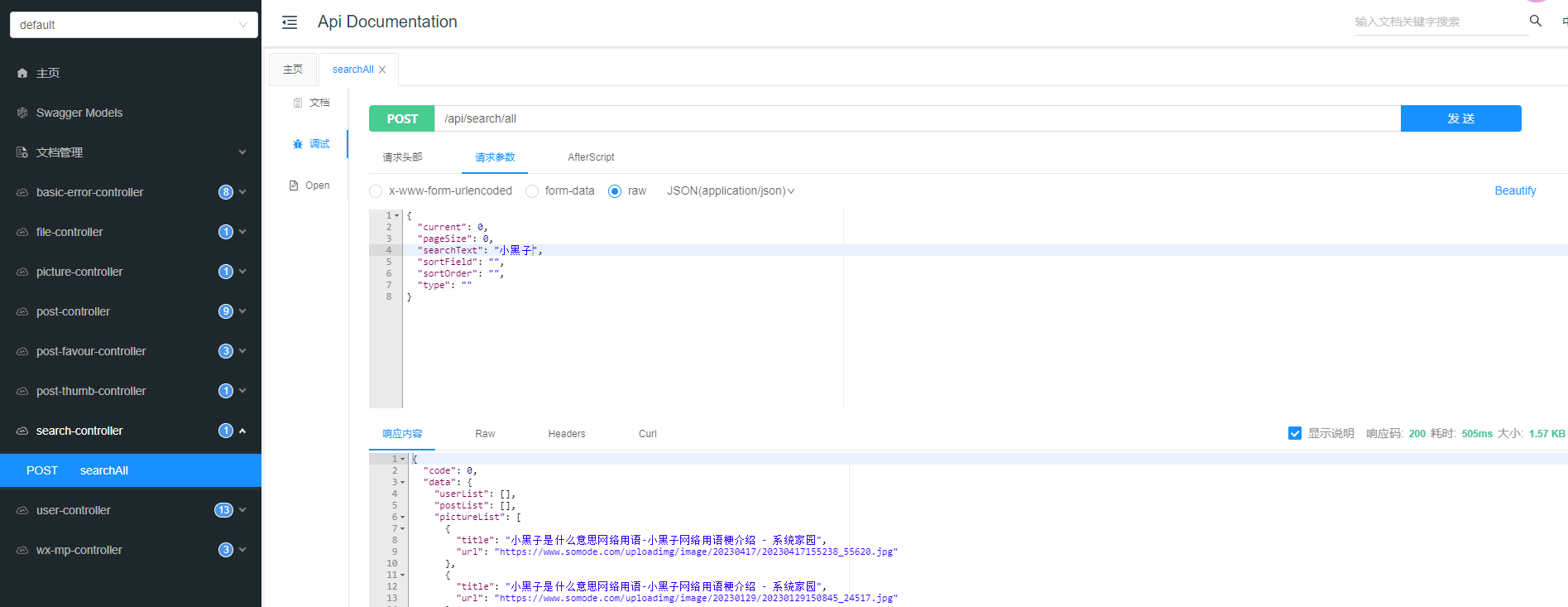
前端实现
【1】原有实现是一个个接口调用,响应处理
【2】优化后的结果是只需要调用一次接口,统一进行相应处理

【4】聚合接口优化
(1)聚合接口并发处理
基于上述项目基础,可以进一步修改SearchController接口,将其三个调用数据库查询操作调整为并发操作,并在一定场景下测试优化效果
/**
* 并发处理查询方法
*
* @param searchRequest
* @param request
* @return
*/
@PostMapping("/allByCon")
public BaseResponse<SearchVO> searchAllByCon(@RequestBody SearchRequest searchRequest, HttpServletRequest request) {
String searchText = searchRequest.getSearchText();
// 查询图片
CompletableFuture<Page<Picture>> pictureTask = CompletableFuture.supplyAsync(() -> {
Page<Picture> picturePage = pictureService.searchPicture(searchText, 1, 10);
return picturePage;
});
// 查询用户
CompletableFuture<Page<UserVO>> userTask = CompletableFuture.supplyAsync(() -> {
UserQueryRequest userQueryRequest = new UserQueryRequest();// 封装UserQueryRequest
userQueryRequest.setUserName(searchText);
Page<UserVO> userVOPage = userService.listUserVOByPage(userQueryRequest);
return userVOPage;
});
// 查询文章
CompletableFuture<Page<PostVO>> postTask = CompletableFuture.supplyAsync(() -> {
PostQueryRequest postQueryRequest = new PostQueryRequest();
postQueryRequest.setSearchText(searchText);
Page<PostVO> postVOPage = postService.listPostVOByPage(postQueryRequest, request);
return postVOPage;
});
// 并发操作:异步对象组合,再用一个join(相当于在这里打了一个断点阻塞,只有三个查询都结束之后才会执行下面的代码)
CompletableFuture.allOf(pictureTask, userTask, postTask).join();
// 封装响应数据
try {
Page<Picture> picturePage = pictureTask.get();
Page<UserVO> userVOPage = userTask.get();
Page<PostVO> postVOPage = postTask.get();
SearchVO searchVO = new SearchVO();
searchVO.setPictureList(picturePage.getRecords());
searchVO.setUserList(userVOPage.getRecords());
searchVO.setPostList(postVOPage.getRecords());
return ResultUtils.success(searchVO);
} catch (Exception e) {
log.error("查询异常", e);
throw new BusinessException(ErrorCode.SYSTEM_ERROR, "查询异常");
}
}
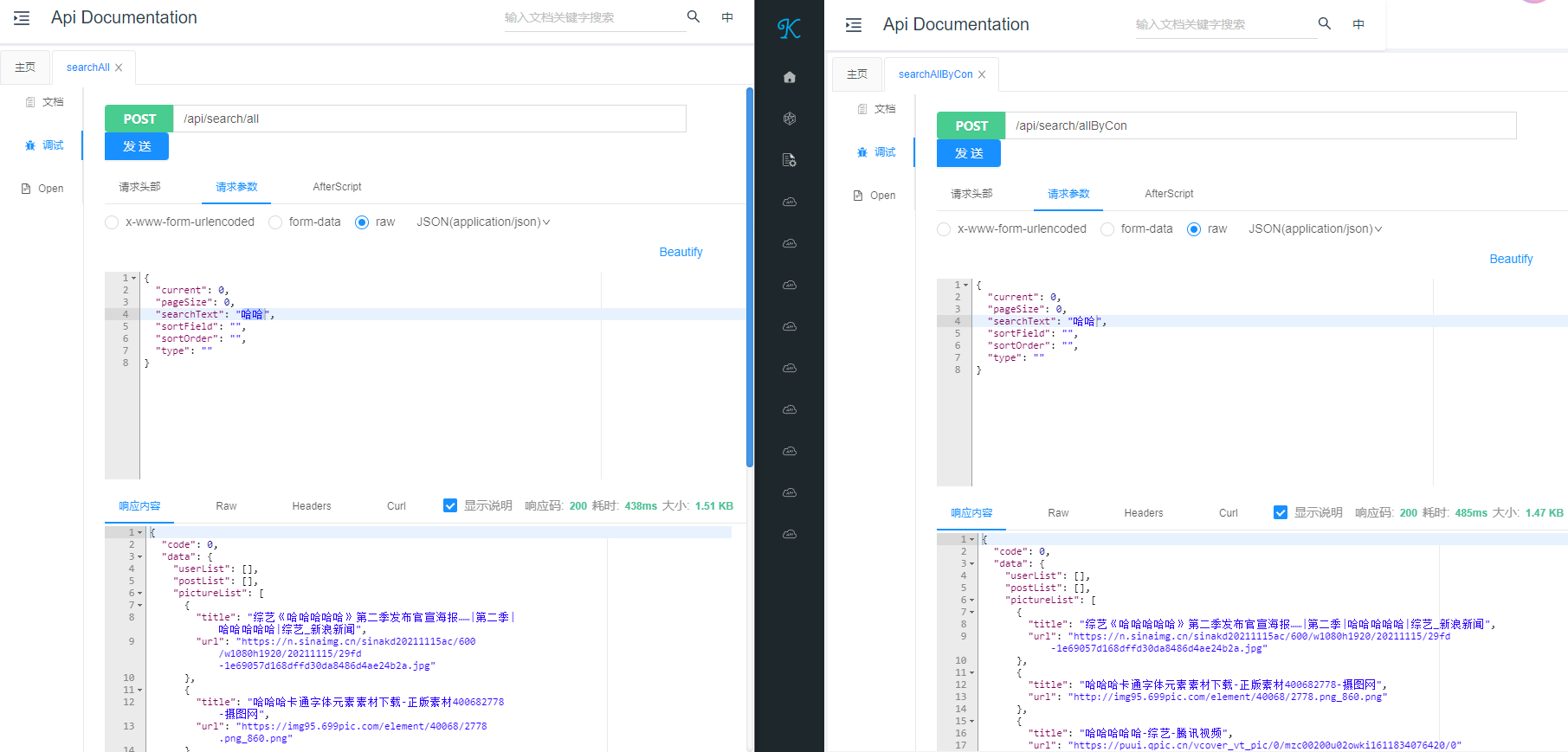
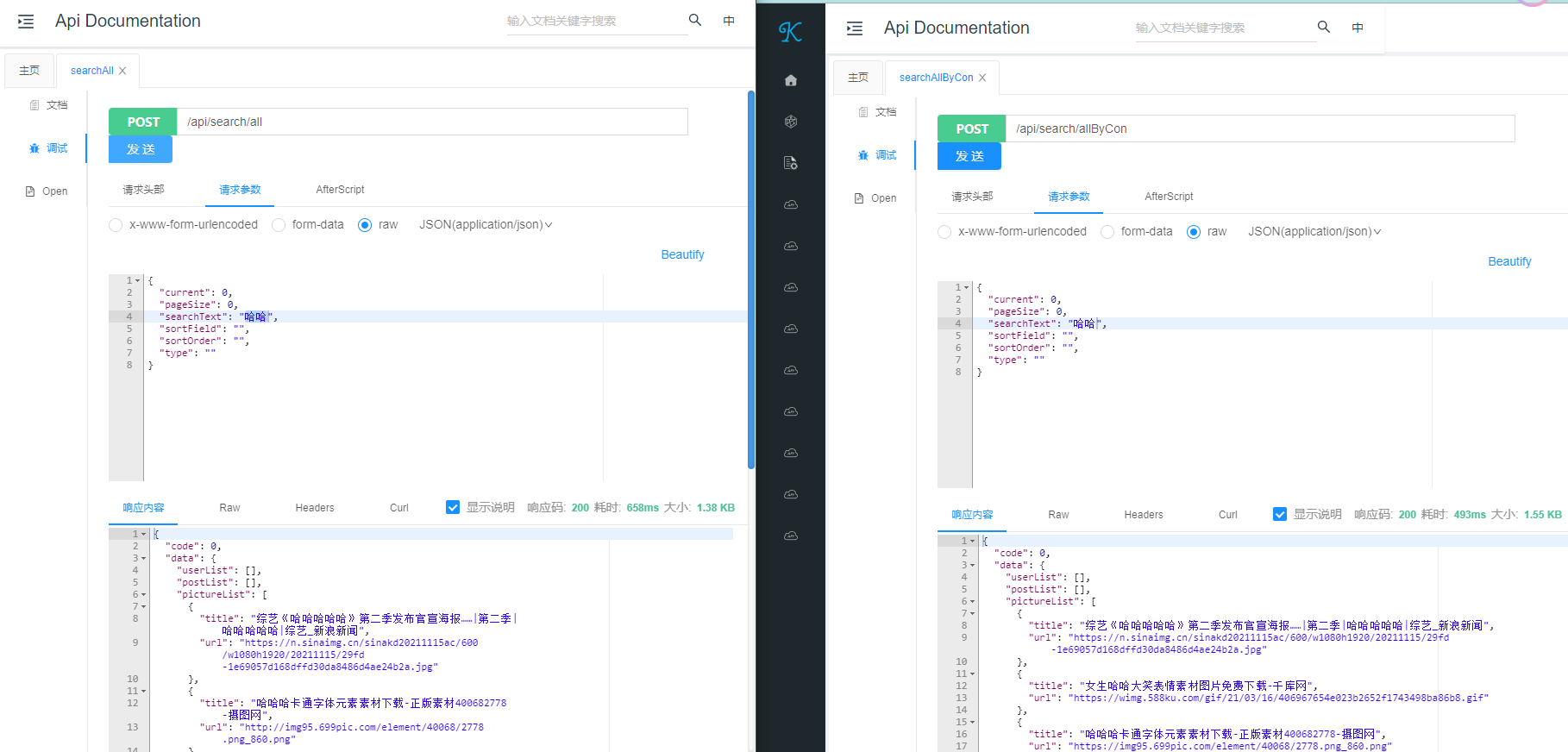
接口测试:由测试结果可知,通过单次访问可以看到其效率提升有些时候并不明显,甚至查询效率不升反降低,所以要通过实践去思考有些后台所谓的并发操作是否真正适合当下的应用场景,亦或是受到其他外部因素影响导致其他原因(网络或者调用第三方接口等)
此处涉及到一个短板效应概念:如果说调用三个方法中相互之间互不影响整体响应持平,三线并行则使得并发得到很大作用;但是如果三个方法中其中有个方法因为一些原因导致延迟,则整个进程被阻塞,则使用并发效率就没有得到很大体现
(2)问题扩展:如何扩展搜索类别和接入更多数据源
业务场景思考:怎么样能让前端又能一次搜出所有数据、又能够分别获取某一类数据(比如分页场景)
解决方案:通过新增type字段实现,前端传type调用后端同一个接口,后端根据type调用不同的service查询(一般情况下通过类型字段指定来解决一些重复代码处理的业务场景,便于后续维护,如果接口实现业务功能很大不同则进行拆分)
比如前端传递type = user, 后端执行userService.query
如果type为空,那么搜索出所有的数据
如果type不为空:如果type合法,那么查出对应数据;否则报错
# SearchRequest新增type字段,前端指定type类型,交由后台校验调用哪一个方法实现
/**
* 查询接口:聚合接口 伪代码实现
*/
public class SearchController {
@PostMapping("/all")
public BaseResponse<SearchVO> searchAll(@RequestBody SearchRequest searchRequest, HttpServletRequest request) {
String searchText = searchRequest.getSearchText();
String searchType = searchRequest.getSearchType();
if("picture".equals(searchType)){
// 查询图片信息
}else if("user".equals(searchType)){
// 查询用户信息
}else if("post".equals(searchType)){
// 查询文章信息
}else{
// 其他类型处理
}
// 统一封装处理返回列表数据
SearchVO searchVO = new SearchVO();
searchVO.setXXXList(查询到的数据);
return ResultUtils.success(searchVO);
}
}
❓衍生问题:当业务逻辑增加,type增多后,要把查询逻辑堆积在controller代码里么? 指定的type也要写死在每个引用到的位置?
解决方案:定义SearchTypeEnum用于封装查询参数,后续项目中可以直接引用,而不是写死在每个要用的地方上,当类型发生变化或者新增的时候只需要补充类型即可(这种思路还可以引申到将type类型字段存储到数据库中,从而扩展更多业务场景管理)
/**
* 搜索类型枚举
*/
public enum SearchTypeEnum {
POST("帖子", "post"),
USER("用户", "user"),
PICTURE("图片", "picture"),
VIDEO("视频", "video");
private final String text;
private final String value;
SearchTypeEnum(String text, String value) {
this.text = text;
this.value = value;
}
/**
* 获取值列表
*
* @return
*/
public static List<String> getValues() {
return Arrays.stream(values()).map(item -> item.value).collect(Collectors.toList());
}
/**
* 根据 value 获取枚举
*
* @param value
* @return
*/
public static SearchTypeEnum getEnumByValue(String value) {
if (ObjectUtils.isEmpty(value)) {
return null;
}
for (SearchTypeEnum anEnum : SearchTypeEnum.values()) {
if (anEnum.value.equals(value)) {
return anEnum;
}
}
return null;
}
public String getValue() {
return value;
}
public String getText() {
return text;
}
}
# 虽然设定了type进行校验返回不同的数据列表,但是程序设计上不可避免地存在if...else...,一旦业务扩展代码将会变得更加臃肿,存在未来业务扩展代码维护风险,把查询逻辑堆积在了controller中
@PostMapping("/all")
public BaseResponse<SearchVO> searchAllByCond(@RequestBody SearchRequest searchRequest, HttpServletRequest request) {
String searchText = searchRequest.getSearchText();
String type = searchRequest.getType();
// 检验传入指定类型为空字符串则抛出异常
ThrowUtils.throwIf(StringUtils.isBlank(type), ErrorCode.PARAMS_ERROR);
// 校验指定type不在指定的字符串范围内则抛出异常或者默认搜索出所有数据(结合业务场景处理)
SearchTypeEnum searchTypeEnum = SearchTypeEnum.getEnumByValue(type);
// ThrowUtils.throwIf(searchTypeEnum==null,ErrorCode.PARAMS_ERROR);
if (searchTypeEnum == null) {
// 此处可处理返回查询所有数据
} else {
SearchVO searchVO = new SearchVO();
// 根据Type类别分别处理
switch (searchTypeEnum){
case PICTURE:
// 查询图片
Page<Picture> picturePage = pictureService.searchPicture(searchText, 1, 10);
searchVO.setPictureList(picturePage.getRecords());
break;
case USER:
// 查询用户
UserQueryRequest userQueryRequest = new UserQueryRequest();// 封装UserQueryRequest
userQueryRequest.setUserName(searchText);
Page<UserVO> userVOPage = userService.listUserVOByPage(userQueryRequest);
searchVO.setUserList(userVOPage.getRecords());
break;
case POST:
// 查询文章
PostQueryRequest postQueryRequest = new PostQueryRequest();
postQueryRequest.setSearchText(searchText);
Page<PostVO> postVOPage = postService.listPostVOByPage(postQueryRequest, request);
searchVO.setPostList(postVOPage.getRecords());
break;
default:
}
return ResultUtils.success(searchVO);
}
}
此处可以借助代码复杂度插件进行分析,查看方法的圈复杂度。或者Statistic代码统计
扩展思考:查询类型增加,本质是业务扩展,用户需要插入更多的数据,引申到怎么能让搜索系统更轻松地接入更多的数据源?
基于上述方式实现,当type增加,相应需要增加SearchTypeEnum枚举对象,随后在controller中进行分支开发,但后续一旦业务扩展,就会使得整体代码非常臃肿且重复,此处可以巧妙利用设计模式去优化项目结构
【5】基于3种设计模式的聚合接口设计
(1)门面模式(外观模式)
常见分析
概念说明:帮助用户(客户端)去更轻松地实现功能,不需要关心门面背后的细节。
聚合搜索类业务基本都门面模式:即前端不用关心后端从哪里、怎么去取不同来源、怎么去聚合不同来源的数据,更方便地获取到内容。(例如此处前端不关注后端如何获取数据,而只是提供一个searchText或者searchTyoe调用接口实现数据访问,此处聚合接口则是一种门面模式设计的体现)简而言之,门面模式最大的作用体现帮助客户端更轻松地调用,不需要理解业务细节
适用场景:当调用系统(接口)的客户端觉得麻烦的时候,你就应该思考,不是可以抽象一个门面了。
可以参考其他框架的设计:例如sl4j框架
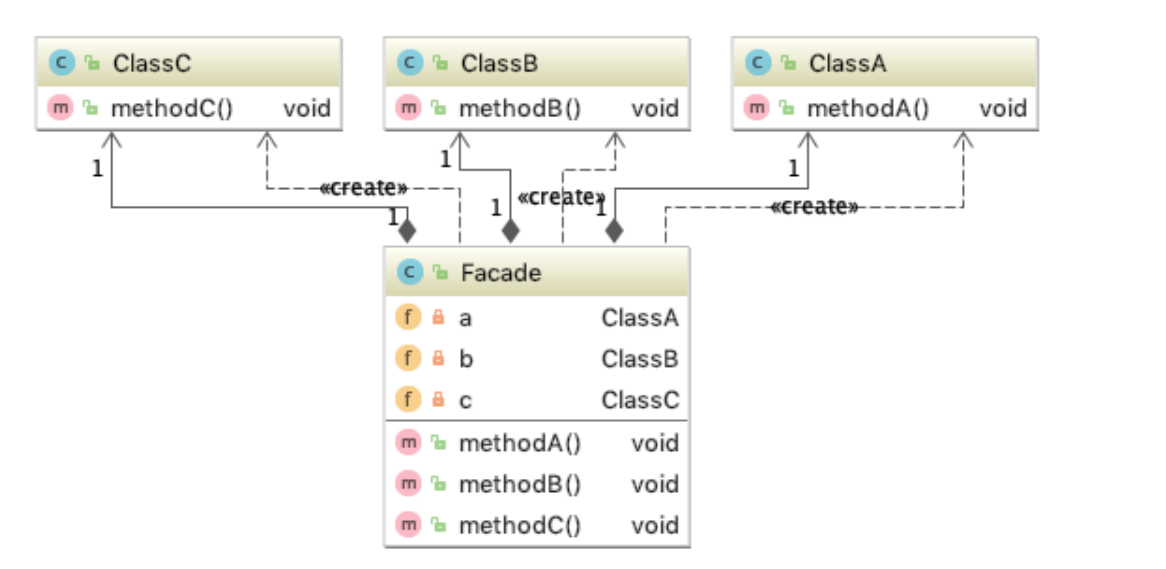
设计说明:(简单来说就是将原有controller业务处理实现放到一个类中处理,优化controller代码结构)
【1】新增SearchFacade,对外提供统一方法searchAll,规范入参和出参,将原有controller的业务处理逻辑通过searchAll方法实现
【2】controller只需根据SearchFacade提供的这个入口,直接调用searchAll方法完成数据响应交互
# 1.定义一个门面SearchFacade
public class SearchFacade {
public SearchVO searchAll(@RequestBody SearchRequest searchRequest, HttpServletRequest request) {
// 同样的业务处理逻辑,根据搜索参数获取到相应的数据(其中可能涉及到一些数据源的引用)
}
}
# 2.controller调用门面方法
public class SearchOptimizeController {
@Resource
private SearchFacade searchFacade;
/**
* V4.1 基于门面模式改造,即将原有controller层中的业务逻辑处理统一设定一个SearchFacade做处理
* controller不关心任何业务处理逻辑,而是通过一个入口指定入参和出参,所有处理交由SearchFacade
* @param searchRequest
* @param request
* @return
*/
@PostMapping("/all")
public BaseResponse<SearchVO> searchAllByCondFacade(@RequestBody SearchRequest searchRequest, HttpServletRequest request) {
// 调用门面将查询到的数据信息进行封装并返回
return ResultUtils.success(searchFacade.searchAll(searchRequest,request));
}
}
(2)适配器模式
场景分析
概念说明:本场景中使用适配器模式,通过转换,让两个系统能够完成对接。例如要调用一个对方接口,但是对方接口提供的调用参数和自身项目预期的参数不一致,因此借助适配器模式进行转化,可以和现实场景的转换器对照。
为什么要定制统一的规范,可以适当避免一些盲目接入接口的场景
定制统一的数据源接入规范(标准) :
什么数据源允许接入?
数据源接入时要满足什么要求?
需要接入方注意什么事情?
本系统要求:任何接入当前系统的数据,它必须要能够根据关键词搜索、并且支持分页搜索。通过声明接口的方式来定义规范。
❓问题扩展:假如说数据源已经支持了搜索,但是原有的方法参数和目前的规范不一致,怎么办?
例如此处提供了Picture、User、Post等多个数据源,但其中Post是接入本地数据库进行查找,需要对请求信息进行校验 ,但这个request又不是各个数据搜索所必须的条件,遇到这种情况如何去做相应处理
【1】最直接了断的方式:不满足规范考虑剔除,对接参数需求额外提供接口/方法进行处理
【2】想办法解决参数问题:尽量自主获取到参数信息,此处借助RequestContextHolder获取请求信息从而拿到所需数据,但也会引申一个问题:当请求来源不同的时候这个request可能和系统所需的有所出入(或者如果借助shiro等一些权限校验框架,可以考虑通过其提供的工具类获取)
【3】有待考究的方式:修改规范,确认其他接口是否也是需要这个参数,但这个改造成本可能在后期会显得大,因为一些现有的接口已经按照既定规范执行,唯恐牵一发动全身
上述方式都是基于不同场景的考虑,需要结合实际选择一种改动最优的方式去解决,由于一开始就统一了规范,要规避一些已经上线结构因规范调整而牵动的联动
设计实现
实现:定义DataSource接口统一接口方法规范,不同数据源接入PictureDataSource、UserDataSource、PostDataSource实现接口实现对应业务逻辑封装。如果说要接入新的数据源,则定义xxxDataSource去实现相应的接口方法
// 1.定义DataSource接口统一规范,提供方法入口:统一入参和出参
// 入参:查询条件、出参:分页数据(为了便于前后端统一分页数据统一为dataList)
public interface DataSource<T> {
/**
* 搜索
*/
Page<T> doSearch(String searchText, long pageNum, long pageSize);
}
// 2.多个不同DataSource实现
public class PictureDataSource implements DataSource<Picture> {
@Override
public Page<Picture> doSearch(String searchText, long pageNum, long pageSize) {
return null;
}
}
public class UserDataSource implements DataSource<User> {
@Override
public Page<User> doSearch(String searchText, long pageNum, long pageSize) {
return null;
}
}
public class PostDataSource implements DataSource<Post> {
@Override
public Page<Post> doSearch(String searchText, long pageNum, long pageSize) {
return null;
}
}
// 3.响应交互:对外提供接口,根据入参确认访问的数据库(伪代码参考)
public BaseResponse<SearchVO> searchAllByCondAdaptor(@RequestBody SearchRequest searchRequest, HttpServletRequest request) {
// a.参数校验
// b.根据不同数据源进行接入
// c.封装响应数据并返回
----------------------------------------数据源接入参考----------------------------------------------------------------
DataSource dataSource = null;
// 根据Type类别分别处理
switch (searchTypeEnum){
case PICTURE:
// 指定图片数据源
dataSource = pictureDataSource;
break;
case USER:
// 指定用户数据源
dataSource = userDataSource;
break;
case POST:
// 指定文章数据源
dataSource = postDataSource;
break;
default:
}
// 根据数据源调用适配器方法获取相应的分页数据
Page page = dataSource.doSearch(searchText, searchRequest.getCurrent(), searchRequest.getPageSize());
// 最终将查询到的数据信息进行封装并返回
return 封装后的响应数据;
----------------------------------------------------------------------------------------------------------------
}
}
// 4.业务扩展:需要接入新的数据源(例如此处需要接入视频数据源,则只需要实现相应的DataSource规范的接口)
-- a.接入新数据源
public class VideoDataSource implements DataSource<Object> {
@Override
public Page<Object> doSearch(String searchText, long pageNum, long pageSize) {
return null;
}
}
-- b.业务逻辑引申处理
// 参考步骤3中controller层处理,只需要在条件语句中补充新接入的数据源即可
switch (searchTypeEnum){
case PICTURE:
// 指定图片数据源
dataSource = pictureDataSource;
break;
case VIDEO:
// 新接入视频数据源
dataSource = videoDataSource;
break;
case MORE:
// 更多数据源接入
dataSource = moreDataSource;
break;
default:
}
// 根据数据源调用适配器方法获取相应的分页数据
Page page = dataSource.doSearch(searchText, searchRequest.getCurrent(), searchRequest.getPageSize());
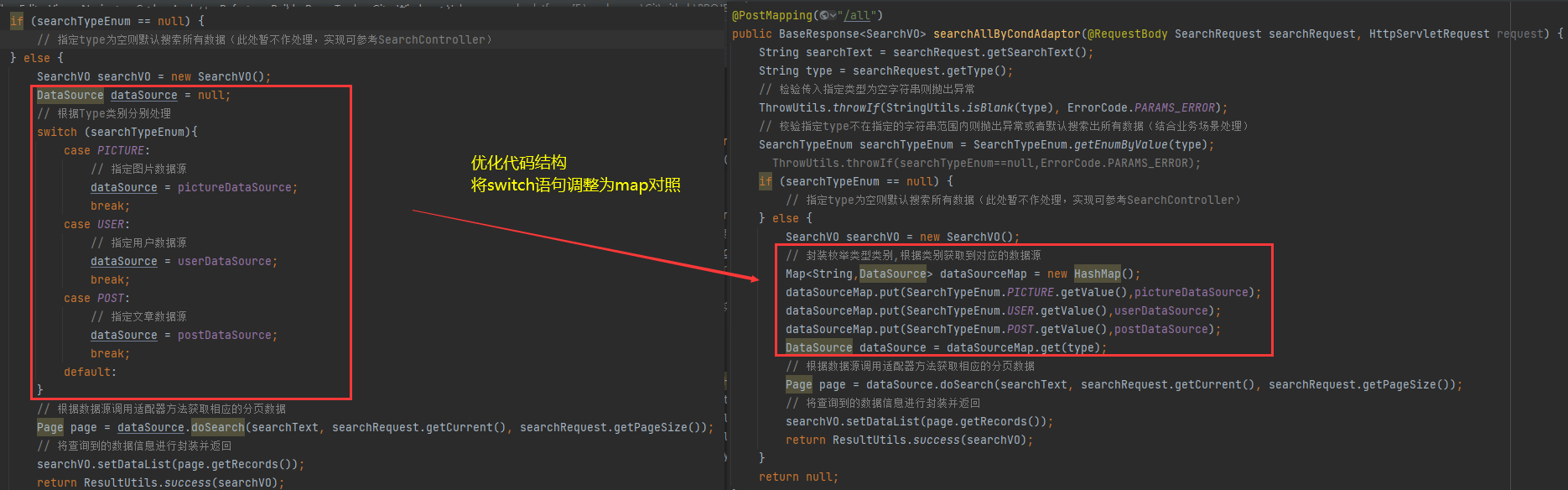
条件语句优化
根据上述适配器模式改造,可以看到在controller层接入不同数据源是通过switch去遍历实现,此处可以考虑进一步简化代码,将数据源和对应数据源类型枚举进行对照,封装为Map,随后再依次遍历Map集合完成数据源检索。
(3)注册器模式(本质也是单例)
在上述适配器模式改造场景中,对switch语句进行了优化,调整为提前通过一个map或者其他类型存储好后面需要调用的对象。其效果体现在替代了if...else...代码量大幅度减少,可维护可扩展。
可以看到相关的map在每次指定controller都会去遍历一次,但其实实际业务场景系统上线这些数据源都是确定的,只需要考虑在初始化加载一次即可,而不像一些动态数据源概念一样反复封装,基于这个场景可以借助注册器模式进一步优化代码结构(可以从单例概念理解)
为了解决上面的问题,此处可以将【数据源注册】作为一个初始化操作,在系统启动的时候对所有涉及到的数据源进行注册,因此构建一个DataSourceRegistry用于封装所有不同类型的数据源
结合上述内容对项目代码进行优化,整合门面模式、适配器模式、注册器模式的结合应用
# 1.定义一个数据源注册器(项目启动确保初始化,将所有的数据源类型注入)
@Component
public class DataSourceRegistry {
@Resource
private PostDataSource postDataSource;
@Resource
private UserDataSource userDataSource;
@Resource
private PictureDataSource pictureDataSource;
private Map<String, DataSource<T>> typeDataSourceMap;
@PostConstruct
public void doInit() {
System.out.println(1);
typeDataSourceMap = new HashMap() {{
put(SearchTypeEnum.POST.getValue(), postDataSource);
put(SearchTypeEnum.USER.getValue(), userDataSource);
put(SearchTypeEnum.PICTURE.getValue(), pictureDataSource);
}};
}
public DataSource getDataSourceByType(String type) {
if (typeDataSourceMap == null) {
return null;
}
return typeDataSourceMap.get(type);
}
}
# 2.门面中引入数据源直接从注册器中获取数据源信息,随后根据不同的数据源响应相应的数据检索方法
public class SearchFacade {
@Resource
private DataSourceRegistry dataSourceRegistry;
public SearchVO searchAll(@RequestBody SearchRequest searchRequest, HttpServletRequest request) {
String type = searchRequest.getType();
SearchTypeEnum searchTypeEnum = SearchTypeEnum.getEnumByValue(type);
ThrowUtils.throwIf(StringUtils.isBlank(type), ErrorCode.PARAMS_ERROR);
String searchText = searchRequest.getSearchText();
// 搜索出所有数据
if (searchTypeEnum == null) {
// 指定type为空则默认搜索所有数据(此处暂不作处理,实现可参考SearchController)
} else {
SearchVO searchVO = new SearchVO();
// 1.从数据源注册器中获取到对应的数据源信息(注册模式)
DataSource dataSource = dataSourceRegistry.getDataSourceByType(type);
// 2.根据数据源调用适配器方法获取相应的分页数据(适配器模式)
Page page = dataSource.doSearch(searchText, searchRequest.getCurrent(), searchRequest.getPageSize());
// 将查询到的数据信息进行封装并返回
searchVO.setDataList(page.getRecords());
return searchVO;
}
return null;
}
}
# 3.controller层调用门面方法直接进行响应
public class SearchOptimizeController {
@Resource
private SearchFacade searchFacade;
@PostMapping("/all")
public BaseResponse<SearchVO> searchAllByCondFacade(@RequestBody SearchRequest searchRequest, HttpServletRequest request) {
// 调用门面将查询到的数据信息进行封装并返回
return ResultUtils.success(searchFacade.searchAll(searchRequest,request));
}
}
(4)改造说明
基于上述三种设计模式的代码改造,可以看到改造后的代码维护、功能迭代、可读性的增强
原有实现
新增一个业务功能需要引入新的数据源、类型的时候,需要在controller层根据不同的type不断的堆叠代码进行判断、调用
优化实现
- controller通过调用门面方法完成交互不需要做调整,门面方法调用:根据不同的数据源类型直接调用处理
- 新增数据源:补充数据源枚举类型、适配不同业务场景的数据检索、然后再注册器中进行注册
组件应用
基于上述前后端项目构建,已经基本出了一个搜索平台雏形,但是结合实际业务场景还需相应接入其他组件进一步优化项目内容,此处引入ES进一步构建完善项目
场景分析
现有问题:搜索不够灵活。比如搜一些分词信息无法匹配," java helloWorld”无法搜到”java Hello World",因为MySQL数据库的like包含查询。
需要分词搜索,最简单的方式就是对搜索条件进行分词拆分,然后对每个词进行数据like检索。但是基于这种场景拆分的概念和规则过于模糊,有时候不知道要拆分多少个词、匹配的规则如何
1.ES基础应用
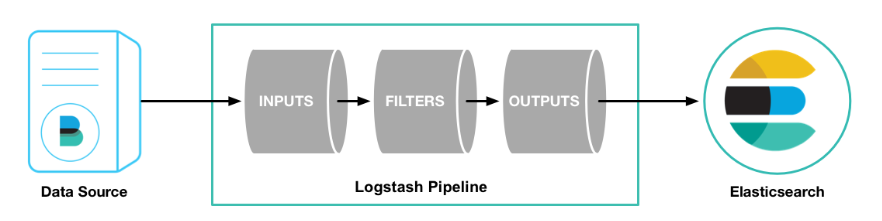
ES引入
es介绍
elastic stack围绕es扩展了很多新的技术栈,包含了数据的整合=>提取=>存储=>使用,一整套!
各组件介绍:
- beats套件:从各种不同类型的文件/应用中采集数据。比如: a,b,c,d,e,aa,bb,cc
- Logstash: 从多个采集器或数据源来抽取/转换数据,向es输送。比如: a,bb,cc
- elasticsearch: 存储、查询数据
- kibana: 可视化es的数据
es引入:一套技术引入需要确保版本一致,此处统一通7.17版本
ES7.17官方文档:quick start、ES7.17下载
【1】安装步骤
ES安装
下载es包,将es进行解压,随后在相应的安装目录执行指令启动,参考安装目录:D:\software\dev\es\elasticsearch-7.17.19
cmd进入安装目录bin下(存放可执行的二进制文件)执行elasticsearch.bat文件,确保窗口常在启动es(一般用作随用随启)
检查es是否成功:先了解es的基本语法,执行对es的CRUD操作进行测试
检查方式
(1)可以直接访问localhost:9200
(2)借助curl指令访问
curl -X GET "localhost:9200/?pretty"
kibana安装
将安装包解压到指定安装目录(D:\software\dev\es\kibana-7.17.9),随后进去bin目录启动kinbana.bat
启动完成访问localhost:5601
常见启动问题:Kibana启动卡住,则需要检查其依赖的ES是否正常启动,否则就会出现下述错误(windows [error][elasticsearch-service] Unable to retrieve version):
【1】排查elstaticsearch是否正常启动,是否在win环境运行下卡住
【2】如果es正常启动则再次尝试启动kibana,检查启动日志是否正常
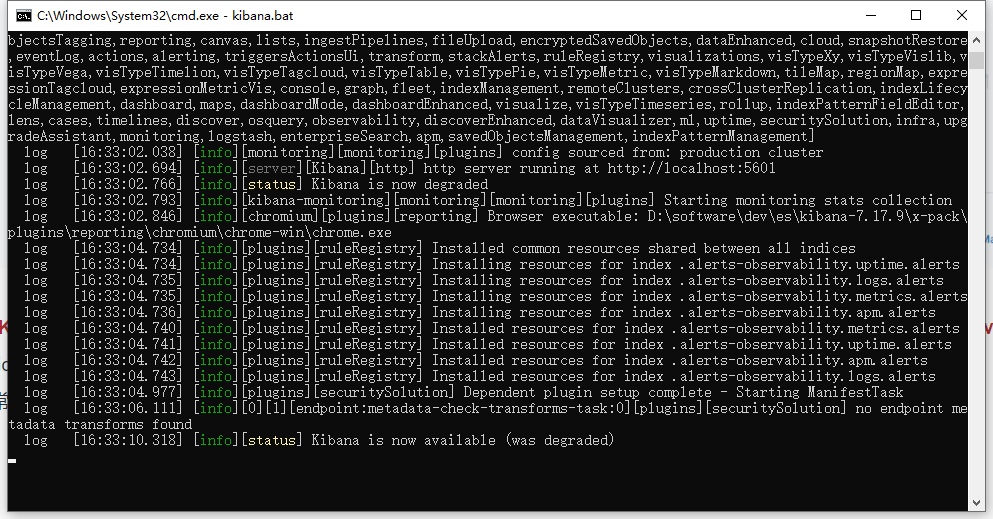
【3】kibana是在es服务基础上应用的,如果说相关的es关闭,则其也会联动停止(可以尝试先将es服务关闭,则看到kibana会实时跟踪关联es服务启动情况,如果没有es正常启用则同理无法使用kibana)

看板测试
主菜单栏目-》Dashboard-》Add sample data查看示例数据
项目中经常用到的是kibana中的dev_tools工具,可以对es进行操作
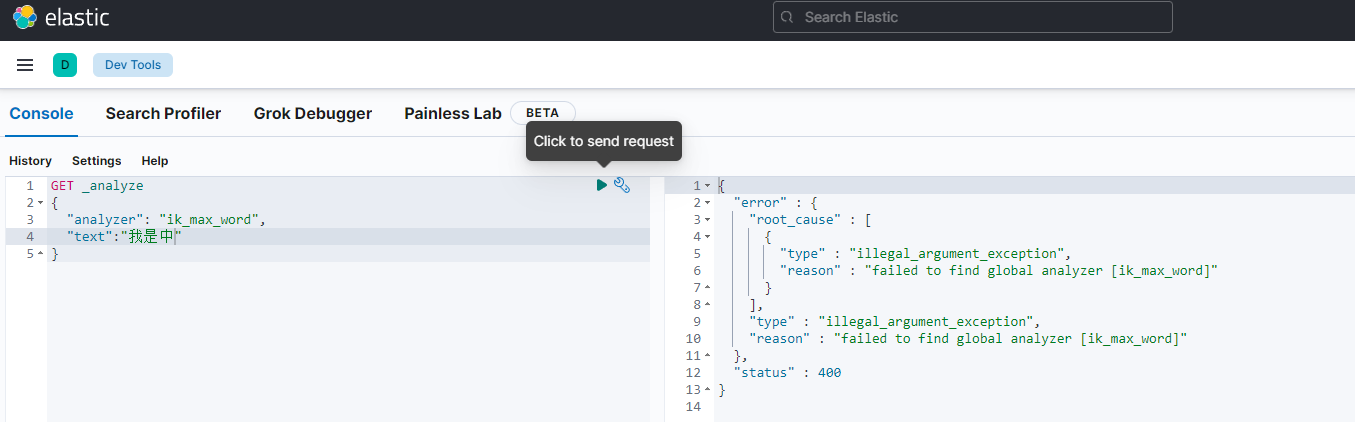
ES使用
【1】基本概念
把它当成MySQL一样的数据库去学习和理解。
入门学习:
Index索引=> MySQL里的表(table)
建表、增删改查. (查询需要花费的学习时间最多)
用客户端去调用ElasticSearch (3种)
语法: SQL、代码的方法(4 种语法)
ES相比于MySQL,能够自动做分词,能够非常高效、灵活地查询内容。
索引
正向索引:理解为书籍的目录,可以快速帮你找到对应的内容(怎么根据页码找到文章)
倒排索引:怎么根据内容找到文章
文章A:你好,我是noob --》 切词:你好,我是,noob
文章B:hello你好,我是coder --》 切词:hello,你好,我是,coder
构建倒排序索引表:
| 词 | 词id |
|---|---|
| 你好 | 文章A,文章B |
| 我是 | 文章A,文章B |
| noob | 文章A |
| hello | 文章B |
| coder | 文章B |
当用户搜索:【你好 coder】,ES会先对搜索内容进行切词【你好,coder】然后再根据倒排索引表去找到对应的文章
【2】ES的几种调用方式
(1)restful api调用(发送api请求)
GET请求: http://localhost:9200/
curl可以模拟发送请求: curl -X GET "Iocalhost:9200/?pretty"
ES的启动端口:9200: 给外部用户(给客户端调用)的端口;9300: 给ES集群内部通信的(外部调用不了的)
(2)kibana devtools
自由地对ES进行操作(本质也是restful api),devtools不建议生产环境使用
根据官方文档介绍测试,举例如下
# 建表插入
POST logs-my_app-default/_doc
{
"@timestamp": "2099-05-06T16:21:15.000Z",
"event": {
"original": "192.0.2.42 - - [06/May/2099:16:21:15 +0000] \"GET /images/bg.jpg HTTP/1.0\" 200 24736"
}
}
# 查询数据
(3)客户端调用
常见的java客户端、go客户端等
客户端调用
【3】ES语法
建议根据场景选择适合自己的语法,避免使用一些和现有语言容易混淆的语法,导致记忆干扰
⚡DSL(Domain Specific Language)领域特定语言
json格式好理解,和http请求最兼容,应用最广
# 这些语法不用特意去记,可通过官方文档进行查阅
(1)建表、插入语句
POST post/_doc/123456
{
"title":"hello",
"desc":"hello es"
}
(2)查询数据
GET post/_search
{
"query": {
"match_all": { }
},
"sort": [
{
"@timestamp": "desc"
}
]
}
(3)根据id查询
GET post/_doc/123456
(4)修改数据
POST post/_doc/123456
{
"title":"hi",
"desc":"hello world"
}
(5)删除
# 删除普通索引
DELETE index_name
# 删除数据流式索引
DELETE _data_stream/logs-my_app-default
此处运行结果有个提示信息,目前一般使用kibana没有使用任何用户名密码等校验,在实际系统上线时会存在风险,任何人只需要知道相应的上线地址就可以通过kibana对es进行直接操作,因此要结合其官方文档开启校验操作(日常学习使用可忽略,真正项目上线需关注)
EQL(标准指标文档)
专门查询ECS文档(标准指标文档)的数据的语法,更加规范,但只适用于特定场景(比如事件流)
Mapping
Mapping可以理解为数据库的表结构,有哪些字段、字段类型。ES支持动态mapping,表结构可以动态改变,而不像MySQL 一样必须手动建 表,没有的字段就不能插入
GET post/_mapping
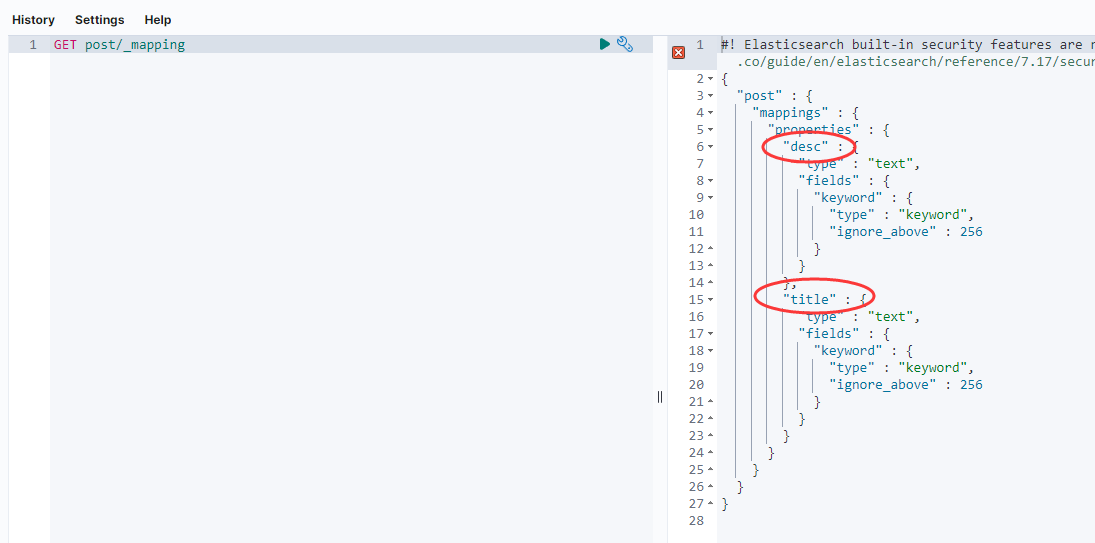
# 创建user表
PUT user
{
"mappings": {
"properties": {
"age": { "type": "integer" },
"email": { "type": "keyword" },
"name": { "type": "text" }
}
}
}
# 查看表结构
GET user/_mapping
SQL
SQL文档,学习成本低,但是可能需要插件支持、性能较差
# 创建数据库
PUT /library/book/_bulk?refresh
{"index":{"_id": "Leviathan Wakes"}}
{"name": "Leviathan Wakes", "author": "James S.A. Corey", "release_date": "2011-06-02", "page_count": 561}
{"index":{"_id": "Hyperion"}}
{"name": "Hyperion", "author": "Dan Simmons", "release_date": "1989-05-26", "page_count": 482}
{"index":{"_id": "Dune"}}
{"name": "Dune", "author": "Frank Herbert", "release_date": "1965-06-01", "page_count": 604}
# 查询数据库
POST /_sql?format=txt
{
"query": "SELECT * FROM library WHERE release_date < '2000-01-01'"
}

Painless Scripting language
编程式取值,更灵活,但是学习成本较高
2.ES项目整合
ElasticStack
【1】ElasticStack概念
ES索引(Index) =>表
ES field (字段) =>列
倒排索引
调用语法(DSL. EQL. SQL等)
Mapping表结构:自动生成mapping、手动指定mapping
分词器:指定分词规则
空格分词器:whitespace
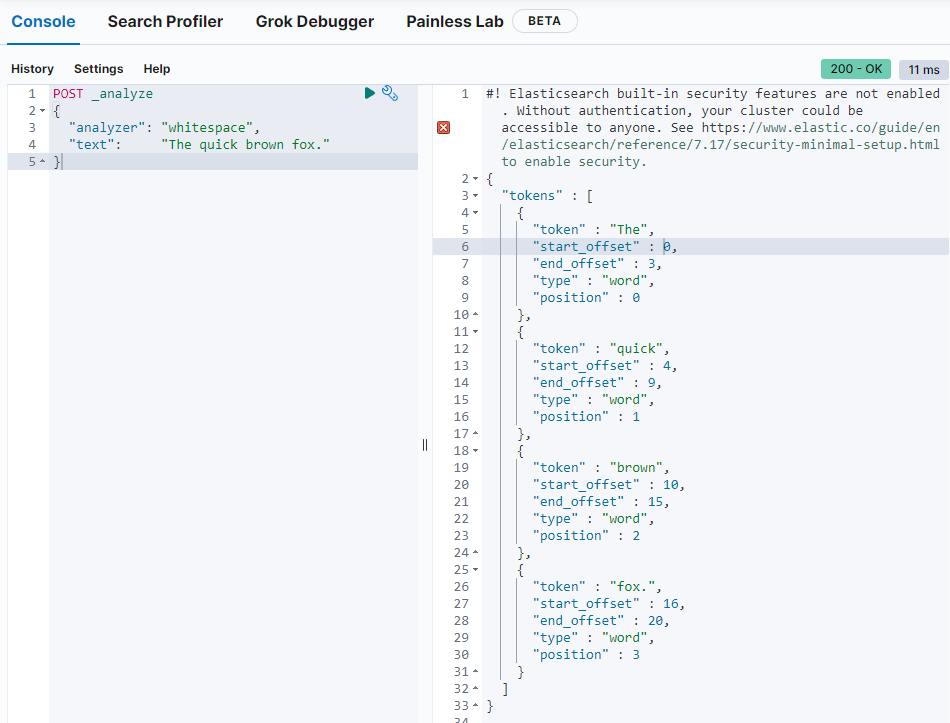
标准分词器:
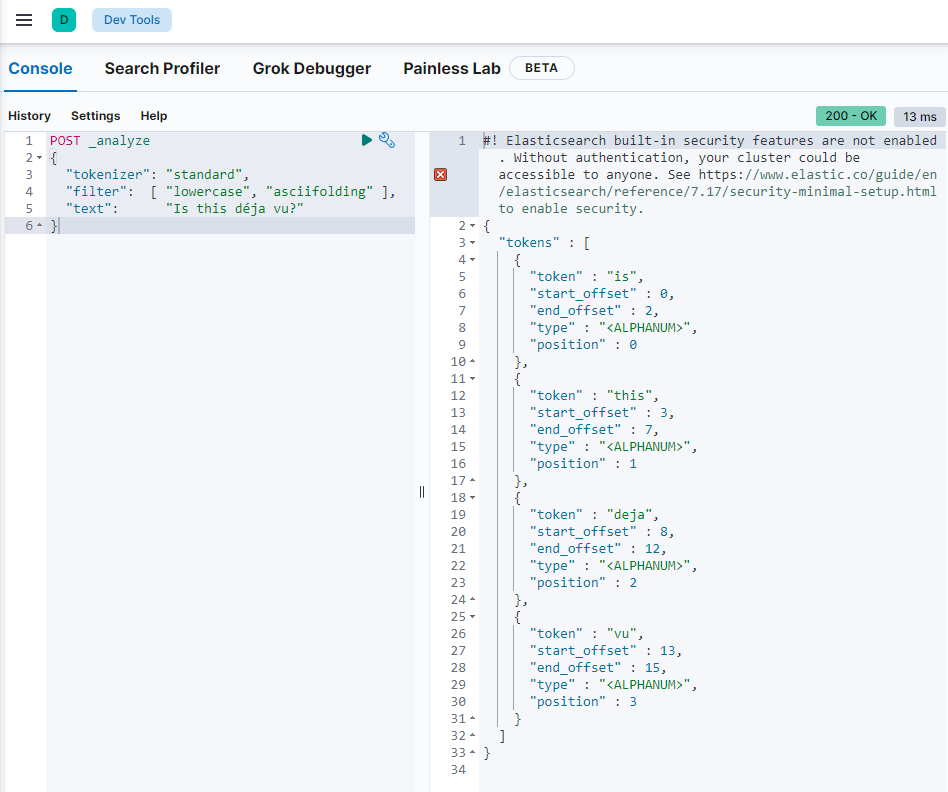
关键词分词器:不分词(整句话当做专业术语)
什么场景下不分词:例如id、分类等不需要拆分词进行检索的场景
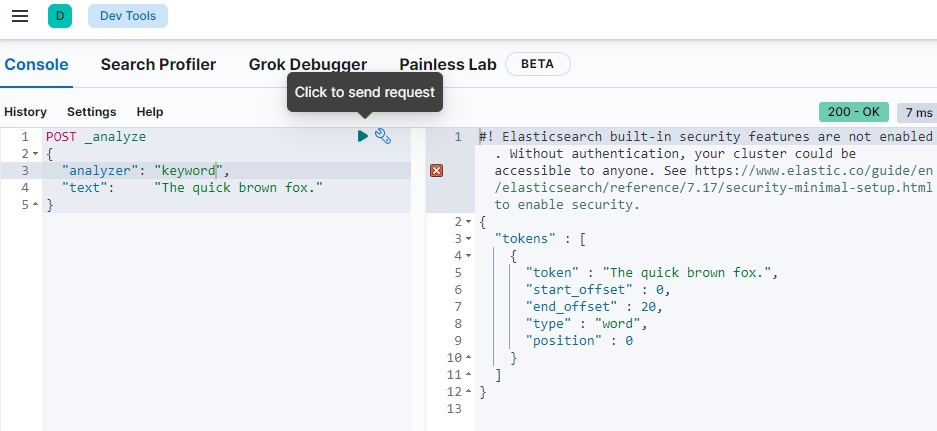
⚡IK分词器(ES插件)
思考:怎么样让ik按自己的想法分词? 解决方案:自定义词典(自己尝试)
ik和es在使用的时候尽量保持包版本一致
ik_smart和ik_max_word的区别?举例:“小黑子”
ik_smart是智能分词,尽选择最像一个词的拆分方式,比如”小”、“黑子”
ik_max_word尽可能地分词,可以包括组合词,比如"小黑”、甲 “黑子”
配置:在es安装目录下创建一个plugins目录,将下载好的ik相关的zip解压后的内容放到对应插件目录下,随后重启es
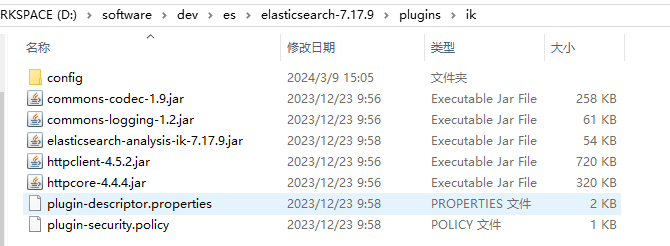
POST _analyze
{
"analyzer": "ik_smart",
"text": "哈哈,加油,冲冲冲,滴滴滴"
}
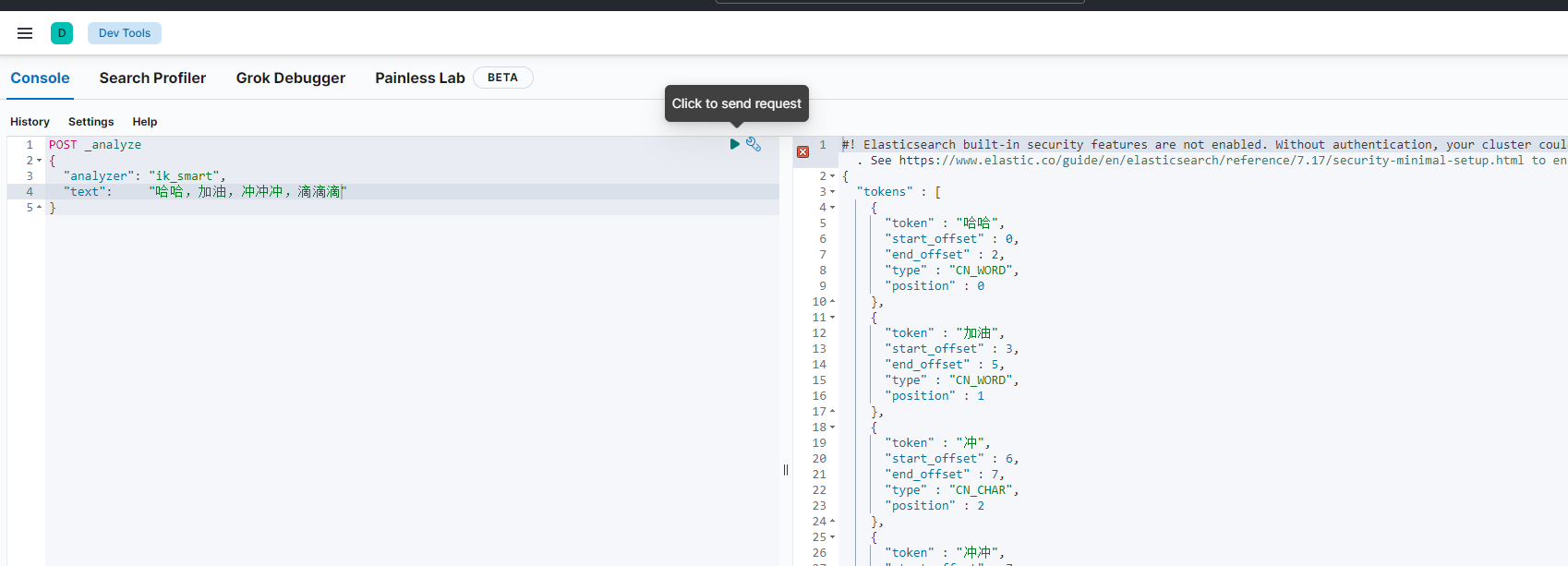
POST _analyze
{
"analyzer": "ik_max_word",
"text": "哈哈,加油,冲冲冲,滴滴滴"
}
扩展:打分机制
举例:数据库里有3条内容
小明是猪
小明是小黑子
我是小黑子
用户搜索匹配的是什么?
- 搜索小明,第1条分数最高,因为第1条匹配了关键词,而且更短(匹配度更大)
- 搜索小明小黑子,第2条分数最高,es会根据分词器规则进行拆分,比如拆分为小明、小、黑子
【2】如何使用Java操作ES
1)ES官方的Java API
快速开始
2)ES以前的Java API,HighLevelRestClient(已经废弃,不建议使用)
更适合系统学习过ES查询DSL的人,因为这套API就是翻译ES的DSL。
3)Spring Data Elasticsearch(推荐)
严格根据版本参照对应,找到对应版本的官方文档进行开发
spring-data系列: spring 提供的操作数据的框架
spring-data-redis:操作redis的一方法
spring-data-mongodb:操作mongodb的一套方法
spring-data-elasticsearch:操作elasticsearch的一套方法
自定义方法:用户可以指定接口的方法名称,框架自动生成查询(按照既定规则命名方法,ES自动生成可用的方法)
方式1:ElasticsearchRepository<PostEsDTO, Long>,默认提供了简单的增删改查,多用于可预期的、相对没那么复杂的查询、自定义查询,返回结果相对简单直接。
方式2:Spring 默认提供的操作es的客户端对象ElasticsearchRestTemplate,也提供了增删改查,它的增删改查更灵活,适用于更复杂的操作,返回结果更完整,但需要自己解析。(核心步骤:取参数、把参数组合为ES支持的搜索条件、从返回值中取结果)
聚合搜索接口优化
【1】建表(ES建立索引)
-- 帖子表
create table if not exists post
(
id bigint auto_increment comment 'id' primary key,
title varchar(512) null comment '标题',
content text null comment '内容',
tags varchar(1024) null comment '标签列表(json 数组)',
thumbNum int default 0 not null comment '点赞数',
favourNum int default 0 not null comment '收藏数',
userId bigint not null comment '创建用户 id',
createTime datetime default CURRENT_TIMESTAMP not null comment '创建时间',
updateTime datetime default CURRENT_TIMESTAMP not null on update CURRENT_TIMESTAMP comment '更新时间',
isDelete tinyint default 0 not null comment '是否删除',
index idx_userId (userId)
) comment '帖子' collate = utf8mb4_unicode_ci;
**根据数据库的表结构,思考表中的哪些字段需要放到es?**ES中尽量存放需要用户筛选(搜索)的数据
ES Mapping:
id (可以不放到字段设置里)、点赞数/收藏数这些数据变化比较频繁不作为检索关键
aliases:别名(给索引指定多个名称,为了后续方便数据迁移)
字段类型是text,这个字段是可被分词的、可模糊查询的;而如果是keyword,只能完全匹配、精确查询。如果想要让text类型的分词字段也支持精确查询,可以创建keyword类型的子字段
analyzer (存储时生效的分词器) :用ik_max_word,拆的更碎、索引更多,更有可能被搜出来
search_ analyzer (查询时生效的分词器) :用ik_smart,更偏向于用户想搜的分词
语法结构参考:sql/post_es_mapping.json文件
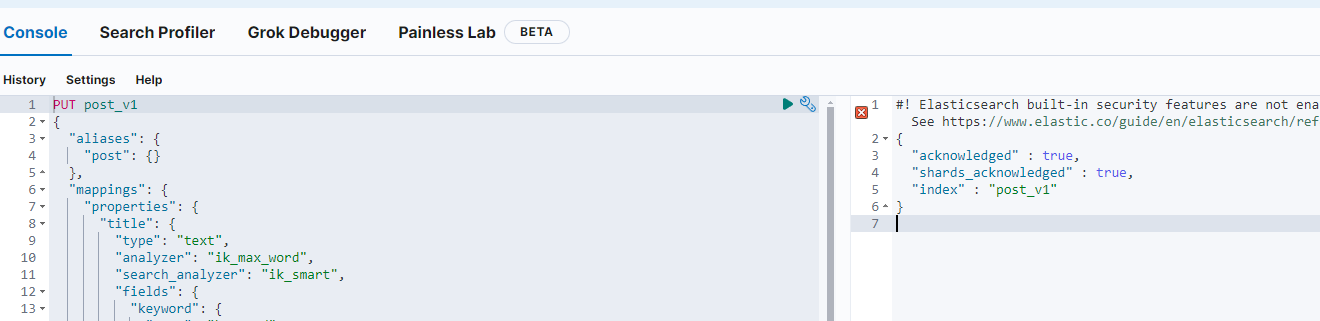
PUT post_v1
{
"aliases": {
"post": {}
},
"mappings": {
"properties": {
"title": {
"type": "text",
"analyzer": "ik_max_word",
"search_analyzer": "ik_smart",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256 // 超过字符数忽略查询
}
}
},
"content": {
"type": "text",
"analyzer": "ik_max_word",
"search_analyzer": "ik_smart",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"tags": {
"type": "keyword"
},
"userId": {
"type": "keyword"
},
"createTime": {
"type": "date"
},
"updateTime": {
"type": "date"
},
"isDelete": {
"type": "keyword"
}
}
}
}
在前期的测试中如果出现例子与当前重名则删除相关索引后重新尝试即可(DELETE /*)

如果出现devtools页面响应卡顿的情况,则在es启动的cmd窗口动点击一下(动一下窗口),如果还是没有响应则依次检查elasticsearch、kibana的启动状态,重启后尝试再次请求,请求成功响应结果如下
【2】Java操作ES
整合ES
在pom.xml中引入相关jar
创建
PostEsDTO与创建的索引字段相对应,放开@Document注释,注入组件ES配置:在application.yml中引入es配置
启动项目查看系统是否正常连接到es服务
⚡方式1:借助ElasticsearchRepository实现
ElasticsearchRepository< PostEsDTO, Long>默认提供了简单的增删改查,多用于可预期的、相对没那么复杂的查询、自定义查询,返回结果相对简单直接。
开发步骤
- 自定义定义接口PostEsDao继承ElasticsearchRepository<PostEsDTO, Long>
- 自定义方法实现:用户可以指定接口的方法名称,框架自动生成查询(按照既定规则命名方法,ES自动生成可用的方法)
/**
* 帖子 ES 操作
*/
public interface PostEsDao extends ElasticsearchRepository<PostEsDTO, Long> {
List<PostEsDTO> findByUserId(Long userId);
}
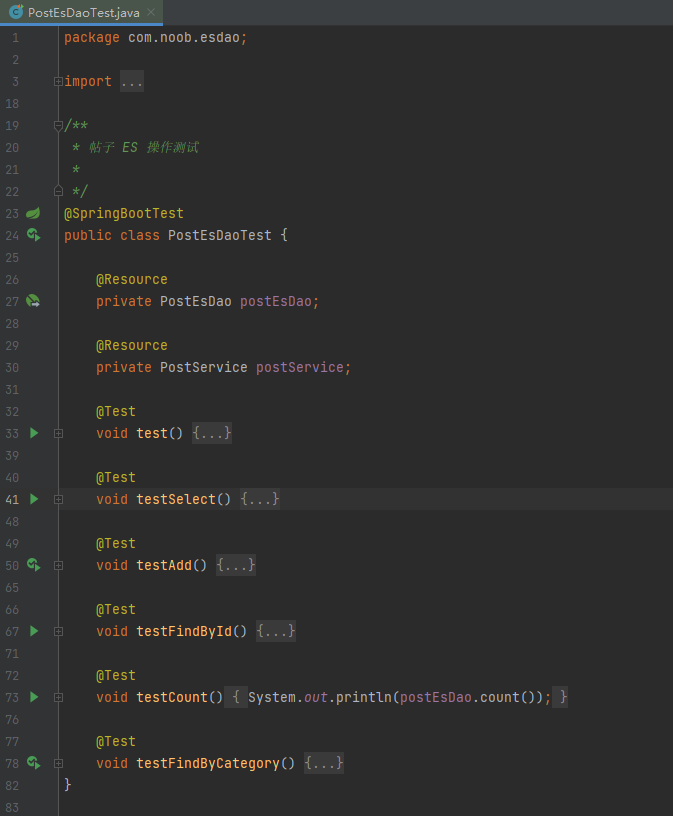
- 业务代码调用方法通过PostEsDao实例化对象调用相应的方法与es进行交互
测试:PostEsDaoTest
依次测试PostEsDaoTest中的CRUD方法
ES中,开头的字段表示系统默认字段, 比如_id, 如果系统不指定,会自动生成。但是不会在_source 字段中补充id的值,所以建议手动指定。在PostEsDTO通过@Id注解将自定义的id与es提供的id进行绑定,如果不指定则会自动生成
ElasticsearchRepository提供的方法自动实现测试
在PostEsDao中自定义接口方法根据title查询数据(不需要额外的任何实现,框架会自动根据方法命名规则自动生成相关的实现)
在PostEsDaoTest中调用进行测试
/**
* 帖子 ES 操作
*/
public interface PostEsDao extends ElasticsearchRepository<PostEsDTO, Long> {
// 根据userId查找文章信息
List<PostEsDTO> findByUserId(Long userId);
// 新增根据title查找文章信息(验证ElasticsearchRepository的自动实现)
List<PostEsDTO> findByTitle(String title);
}
/**
* 测试
*/
@SpringBootTest
public class PostEsDaoTest {
@Test
void testFindByTitle(){
List<PostEsDTO> postEsDaoTestList = postEsDao.findByTitle("test");
System.out.println(postEsDaoTestList);
}
}
⚡方式2:借助ElasticsearchRestTemplate实现
Spring默认提供的操作es的客户端对象ElasticsearchRestTemplate, 也提供了增删改查,它的增删改查更灵活,适用于更复杂的操作,返回结果更完整,但需要自己解析。对于复杂的查询,建议用第二种方式。
开发步骤
- 取参数
- 把参数组合为ES支持的搜索条件
- 从返回值中取结果
案例参考PostService中的searchFromEs实现
本质上是DSL与Java代码的转化(可以参考MyBatis和SQL的代码转化),可以先测试相关的DSL然后再根据DSL转化为Java代码
查询DSL参考文档:
https://www.elastic.co/guide/en/elasticsearch/reference/7.17/query-filter-context.html
https://www.elastic.co/guide/en/elasticsearch/reference/7.17/query-dsl-bool-query.html
# DSL查询
GET post/_search
{
"query": {
"bool": { // 组合条件
"must": [ // 必须都满足
{ "match": { "title": "test" }}, // match 模糊查询
{ "match": { "content": "java" }}
],
"filter": [
{ "term": { "status": "published" }}, // term 精确查询
{ "range": { "publish_date": { "gte": "2015-01-01" }}} // range 范围查询
]
}
}
}
# 查询结果
{
"took" : 0,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 0,
"relation" : "eq"
},
"max_score" : null,
"hits" : [ ]
}
}
动静分离设计:先模糊筛选静态数据,查出数据后,再根据查到的内容id去数据库查找到动态数据。(即es中存储的是核心搜索字段,根据字段匹配信息检索,随后拿到id后再根据id查找到实际数据库的数据源信息,试下动态查找)
DSL与代码对照searchFromEs方法Java实现(不要死记硬背,而是结合具体搜索条件匹配)
{
"query": {
"bool": {
"must_not": [
{
"match": {
"title": ""
}
},
]
"should": [
{
"match": {
"title": ""
}
},
{
"match": {
"desc": ""
}
}
],
"filter": [
{
"term": {
"isDelete": 0
}
},
{
"term": {
"id": 1
}
},
{
"term": {
"tags": "java"
}
},
{
"term": {
"tags": "框架"
}
}
],
"minimum_should_match": 0
}
},
"from": 0, // 分页
"size": 5, // 分页
"_source": ["name", "_createTime", "desc", "reviewStatus", "priority", "tags"], // 要查的字段
"sort": [ // 排序
{
"priority": {
"order": "desc"
}
},
{
"_score": {
"order": "desc"
}
},
{
"publishTime": {
"order": "desc"
}
}
]
}
❓常见问题解决
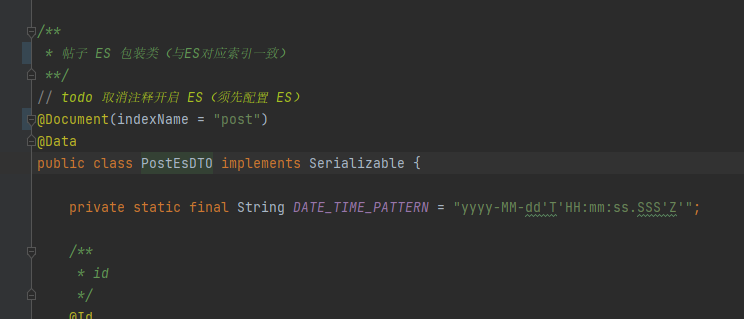
问题解决:如果一开始没有按照步骤跟踪的话直接导入项目配置启动项目,可能出现下列错误(postEsDao未定义)

问题排查:打开对应PostEsDTO,可以看到该类是与ES操作相关的文件,项目在未开启ES相关配置以及解除@Document注解的时候能够正常启用,但是当联动ES启动项目的时候却发现抛出如下异常,原因在于项目启动会相应去检索需要注入的对象,此处构建的PostEsDTO其与ES创建的索引post一致,会对其自动映射,如果说系统启动並没有连接到ES服务,导致PostEsDTO注入失败进而无法启动项目
除此之外,当项目正常启动后,需要相应在es中创建与PostEsDTO对应的索引,以供后续java程序进行访问

【3】数据同步
一般情况下,如果做查询搜索功能,使用ES来模糊搜索,但是数据是存放在数据库MySQL里的,所以说我们需要把MySQL中的数据和ES进行同步,保证数据一致(以MySQL为主)。
目前项目场景:MySQL=> ES (单向)
首次安装完ES,把MySQL数据全量同步到ES里,写一个单次脚本
4种方式:全量同步(首次) +增量同步(新数据)
【1】定时任务,比如1分钟1次,找到MySQL中过去几分钟内(至少是定时周期的2倍)发生改变的数据,然后更新到ES。(一定程度上可以防止数据同步失败带来的影响,一分钟更新一次过去几分钟内的数据,就算本次执行失败,下次也会更新。)
增量插入定时任务:IncSyncPostToEs、全量插入定时任务:FullSyncPostToEs(同id校验更新覆盖而不会重复插入)
优点:简单易懂、占用资源少、不用引入第三方中间件
缺点:有时间差
应用场景:数据短时间内不同步影响不大、或者数据几乎不发生修改
【2】双写:写数据的时候,必须也去写ES;更新删除数据库同理。(数据库事务: 建议先保证MySQL写成功,如果ES写失败了,可以通过定时任务+日志+告警进行检测和修复(补偿) )
【3】用Logstash数据同步管道(一般要配合kafka消息队列+ beats采集器) (考虑性能问题,不适合大规模的数据传输场景)
【4】Canal监听MySQL Binlog,实时同步
a.定时任务同步
增量同步:IncSyncPostToEs
全量同步:FullSyncPostToEs
b.Logstash
传输和处理数据的通道
- 好处:用起来方便,插件多
- 缺点:成本更大、一般要配合其他组件使用(比如kafka)
cd logstash-7.17.9
.\bin\logstash.bat -e "input { stdin { } } output { stdout {} }"

最简单的一个应用,提供一个输入,Logstash输出数据
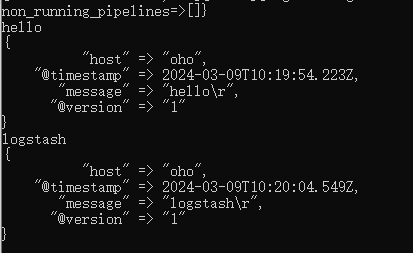
在【安装目录】\logstash-7.17.9\config常见myTask.conf,填充示例内容(可参考其他文件提供的示例信息)
- myTask.conf简单示例
# 开启udp端口的监听,监听514端口,如果有数据则输出
input {
udp {
port => 514
type => "syslog"
}
}
# 输出:指定输出的格式和编码
output {
stdout { codec => rubydebug }
}
- 启动通道测试,执行指令
cd C:\logstash-7.17.9\
.\bin\logstash.bat -f .\config\myTask.conf

将mysql数据同步给es(输入是mysql数据库、输出)
确认输入(jdbc)输出(elasticsearch)组件,参考简单示例以及输入输出的配置规则,完成两个input、output配置
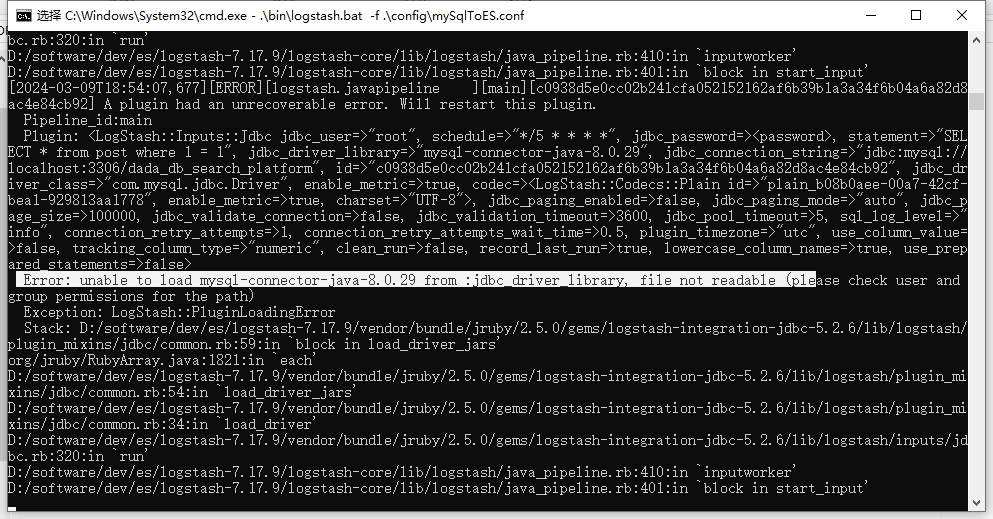
在测试demo的时候不要想着一步到位,要尝试分布执行,从而一一排查错误(例如此处可以先写输入测试,然后测试输出)
注意mysql数据库的驱动jar位置存放路径(驱动包可以从maven仓库中进行拷贝(项目工程中引用外部依赖中查找即可),或者配置修改为驱动包的绝对路径),测试demo结合实际进行配置
cd C:\logstash-7.17.9\
.\bin\logstash.bat -f .\config\mySqlToES.conf
❓数据库驱动路径配置问题
❓Logstash同时启用问题

⭕demo测试成功
# 构建mysql输入(每隔一段时间查询数据库,然后将查到的数据进行输出)
input {
jdbc {
# 数据库要素填充
jdbc_driver_library => "D:\software\dev\es\logstash-7.17.9\config\mysql-connector-java-8.0.29.jar"
jdbc_driver_class => "com.mysql.cj.jdbc.Driver"
jdbc_connection_string => "jdbc:mysql://localhost:3306/dada_db_search_platform"
jdbc_user => "root"
jdbc_password => "root"
# 执行什么指令
statement => "SELECT * from post where 1 = 1"
schedule => "*/5 * * * * *" # 正则表达式:定时规则(暂定设置为5s执行一次)
}
}
# 构建es输出:指定输出的格式和编码
output {
stdout { codec => rubydebug }
}
全量增量同步问题:记录上次数据更新的时间,只查出大于该更新时间的数据
# 构建mysql输入(每隔一段时间查询数据库,然后将查到的数据进行输出)
input {
jdbc {
# 数据库要素填充
jdbc_driver_library => "D:\software\dev\es\logstash-7.17.9\config\mysql-connector-java-8.0.29.jar"
jdbc_driver_class => "com.mysql.cj.jdbc.Driver"
jdbc_connection_string => "jdbc:mysql://localhost:3306/dada_db_search_platform"
jdbc_user => "root"
jdbc_password => "root"
# 执行什么指令(增加时间限制和排序是为了避免重复更新)
statement => "SELECT * from post where updateTime > :sql_last_value and updateTime < now() order by updateTime desc"
tracking_column => "updatetime"
tracking_column_type => "timestamp"
use_column_value => true
parameters => { "favorite_artist" => "Beethoven" }
schedule => "*/5 * * * * *"
jdbc_default_timezone => "Asia/Shanghai"
}
}
# 编写过滤(去除不需要同步的字段、字段大小写对应调整)
filter {
mutate {
rename => {
"updatetime" => "updateTime"
"userid" => "userId"
"createtime" => "createTime"
"isdelete" => "isDelete"
}
remove_field => ["thumbnum", "favournum"]
}
}
output {
stdout { codec => rubydebug }
# es 输出配置
elasticsearch {
hosts => "127.0.0.1:9200"
index => "post_v1"
document_id => "%{id}"
}
}
在指定jdbc组件中查看D:\software\dev\es\logstash-7.17.9\data\plugins\inputs\jdbc下的logstash_jdbc_last_run文件,它记录上次同步到的数据的最后一行的指定的字段(如果是要全量更新只需要清理该文件内容或者直接删除该文件)
查询语句要按照updateTime进行排序,以确保最后一条数据是最大的
c.订阅数据库流水的同步方式
场景:当数据发生改变,能够like将数据同步到es
优点:实时同步,实时性非常强
原理:数据库每次修改时,会修改binlog文件,只要监听该文件的修改,就能第一时间得到消息并处理
canal:帮你监听binlog,并解析binlog为可以理解的内容,它伪装成了MySQL的从节点,获取主节点给的binlog
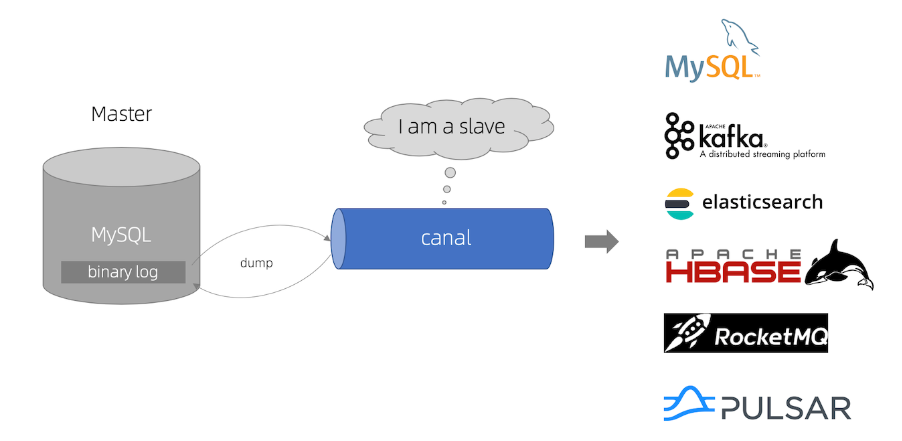
配置说明:参考canal快速开始
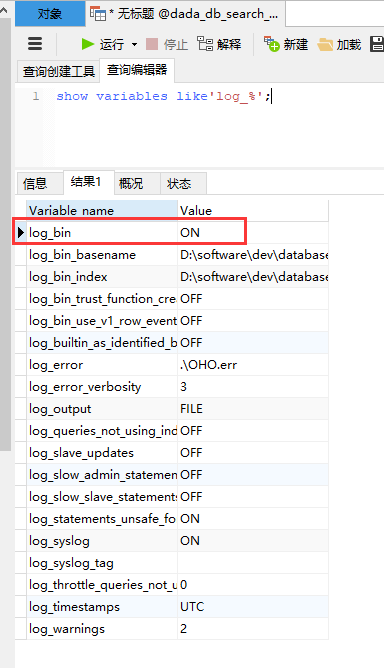
(1)windows系统,找到你本地的mysql[安装目录](D:\software\dev\database\MySQL Server 5.7),在根目录下新建my.ini文件:开启mysql的binlog功能并且定义一个主节点id(相当于把mysql服务器当做主节点)
[mysqld]
log-bin=mysql-bin # 开启 binlog
binlog-format=ROW # 选择 ROW 模式
server_id=1 # 配置 MySQL replaction 需要定义,不要和 canal 的 slaveId 重复
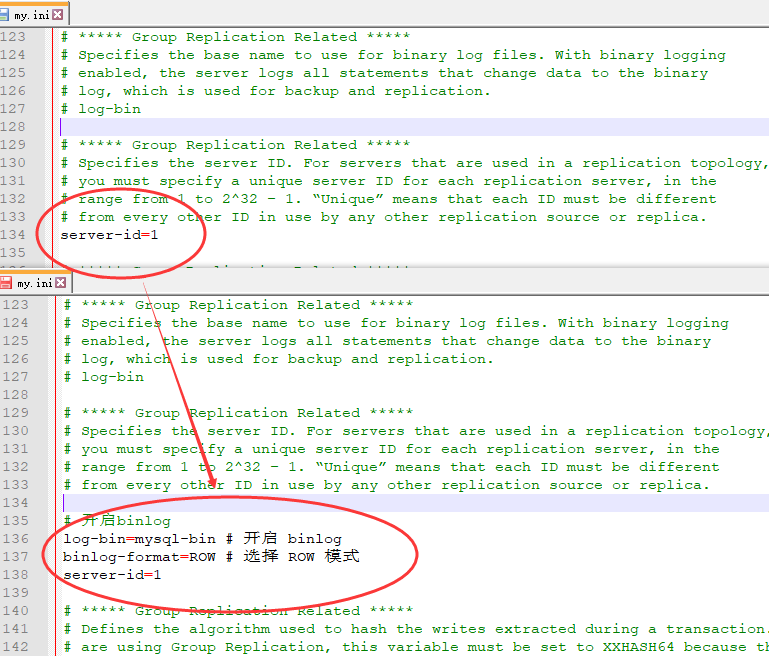
(2)授权 canal 链接 MySQL 账号具有作为 MySQL slave 的权限, 如果已有账户可直接 grant(查询控制台中执行)
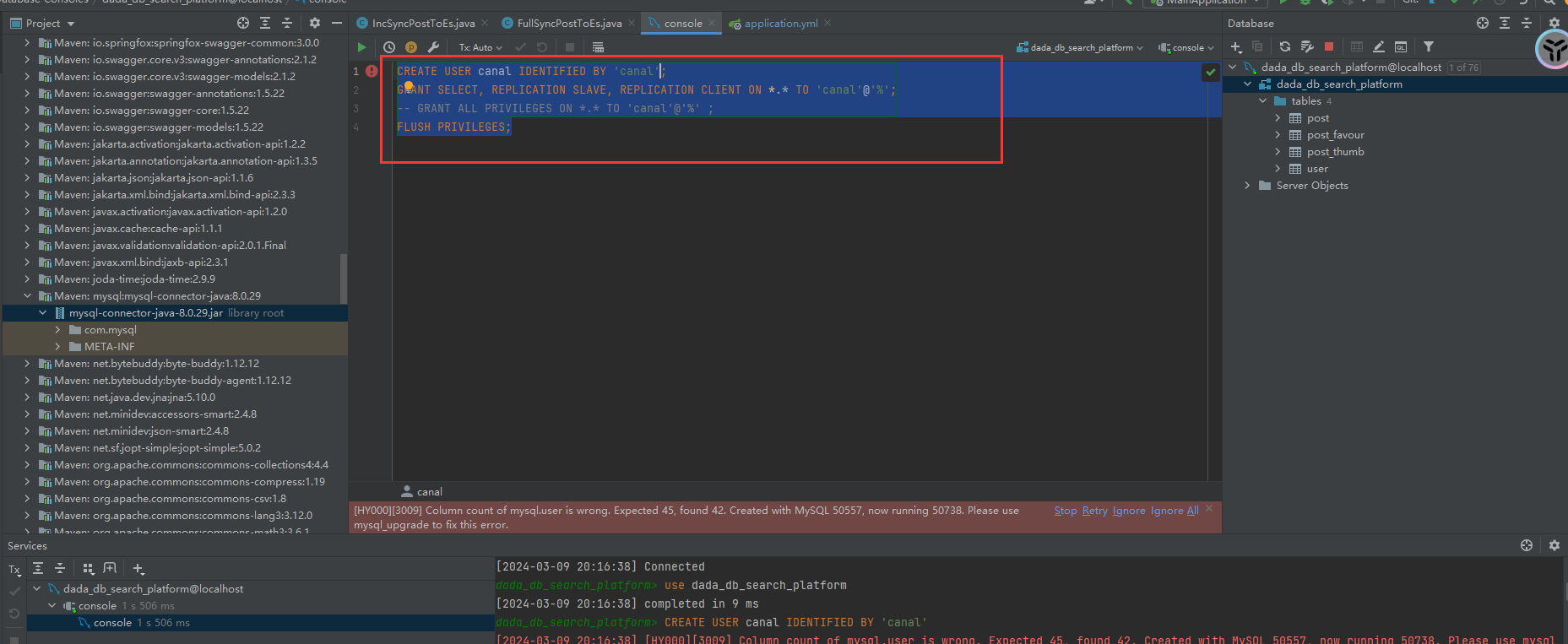
CREATE USER canal IDENTIFIED BY 'canal';
GRANT SELECT, REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'canal'@'%';
-- GRANT ALL PRIVILEGES ON *.* TO 'canal'@'%' ;
FLUSH PRIVILEGES;
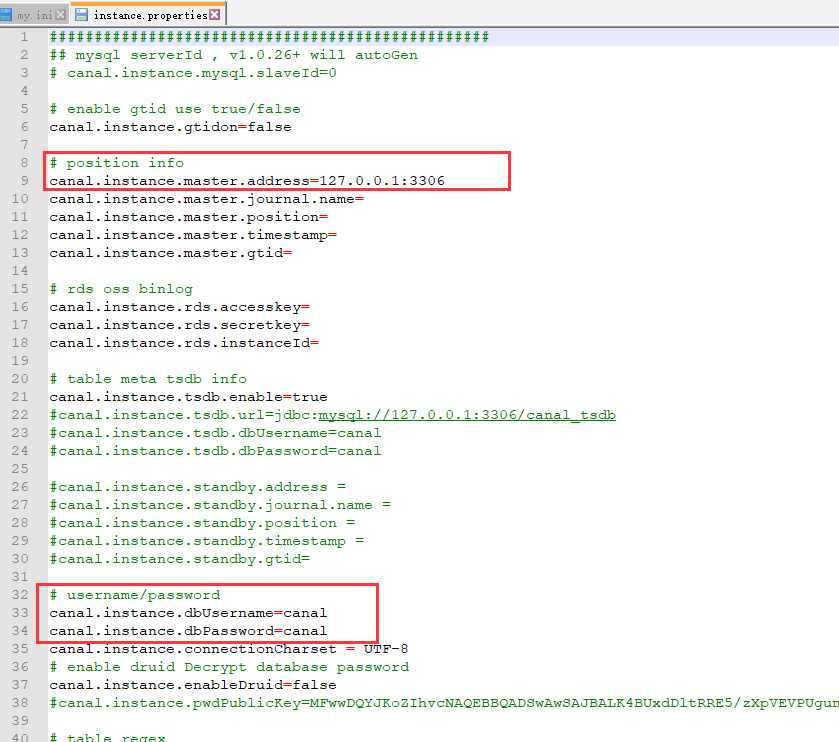
(3)下载canal,解压缩,修改配置(安装目录/conf/example/instance.properties)(参考步骤2中创建的用户)
(4)进入bin目录,启动canal
如果提示java找不到,修改startup.bat脚本为自己的java home(可以从自己的idea中下载引用)
问题:mysql 无法链接,Caused by: java.io.IOException: caching_sha2_password Auth failed
解决方案:https://github.com/alibaba/canal/issues/3902
ALTER USER 'canal'@'%' IDENTIFIED WITH mysql_native_password BY 'canal'; ALTER USER 'canal'@'%' IDENTIFIED BY 'canal' PASSWORD EXPIRE NEVER; FLUSH PRIVILEGES;
(5)客户端
pom.xml中引入canal包
创建SimpleCanalClientExample示例测试
❓存在问题:canal启动、java连接代码测试发现无法接听数据库变化?考虑是否binlog日志被清理
排查canal是否正常启动
排查mysql的binlog是否正常启用、修改my.ini配置文件后重启mysql服务器再次尝试
检查canal、mysql数据库版本是否兼容(实验参考mysql版本mysql-8.0.26)
【4】配置kibana可视化看板
(1)创建索引
(2)导入数据
(3)创建索引模式
(4)选择图标,根据业务需求托拉拽构建
(5)保存
项目测试
JMeter压力测试
JMeter下载安装:D:\software\dev\test\apache-jmeter-5.5\bin\ApacheJMeter.jar,进入bin目录双加jar启动JMeter
找到 jar 包:apache-jmeter-5.5\apache-jmeter-5.5\bin\ApacheJMeter.jar 启动
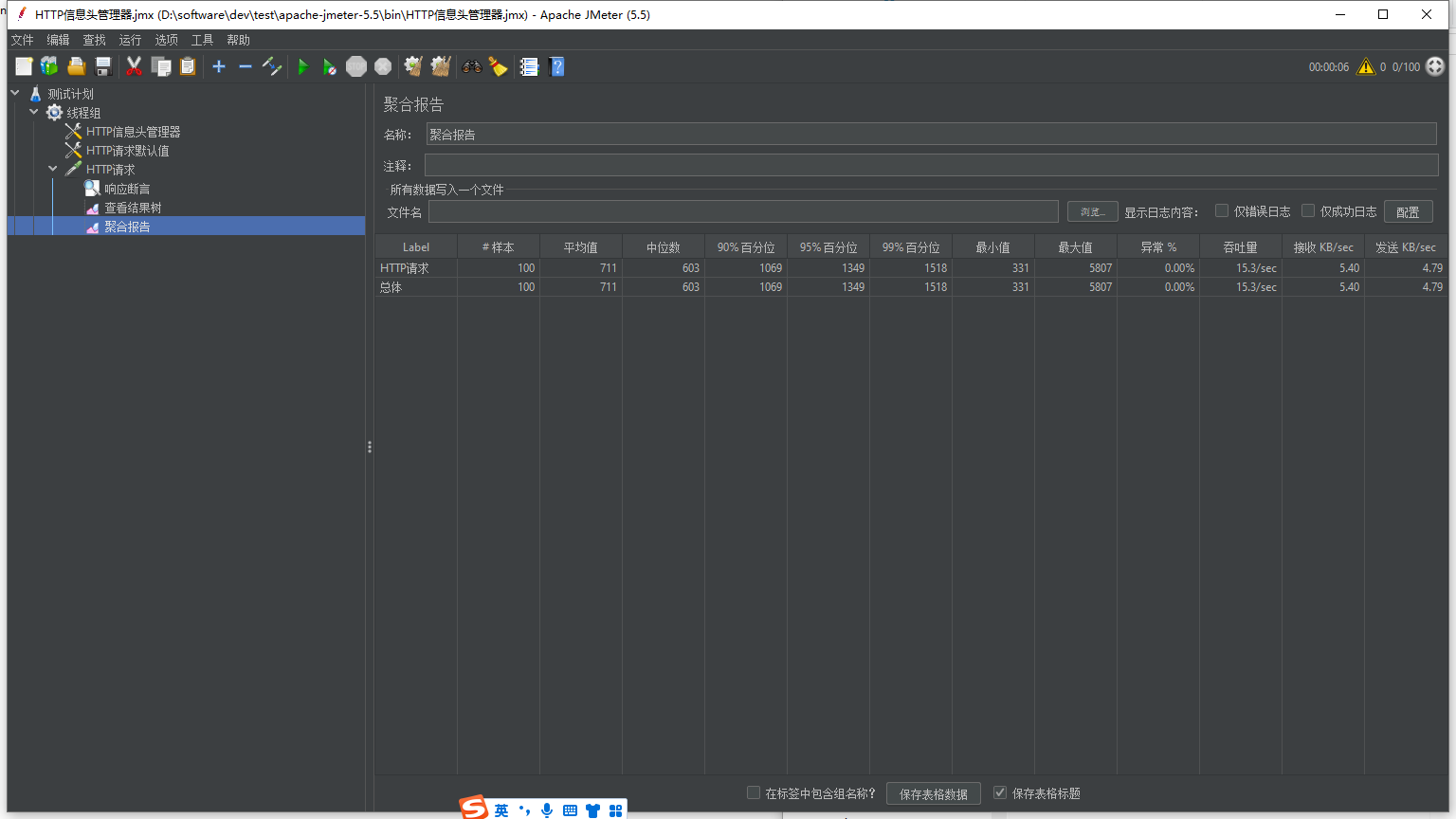
配置线程组 => 请求头 => 默认请求 => 单个请求 => 响应断言 => 聚合报告 / 结果树
插件:https://jmeter-plugins.org/install/Install/
下载后文件为plugins-manager.jar格式,将其放入jmeter安装目录下的lib/ext目录,然后重启jmeter,即可。
参考文章:https://blog.csdn.net/weixin_45189665/article/details/125278218
(1)新建普通线程组:右键选择测试计划-》添加-》线程(用户)-》线程组
(2)选择指定线程组:右键添加配置元件-》HTTP信息头管理器(添加请求头信息Content-Type:application/json)
(3)选择指定线程组:右键添加配置元件-》HTTP请求默认值(设置默认服务器IP和端口)
(4)选择指定线程组:右键添加取样器-》HTTP请求(设置消息体数据)
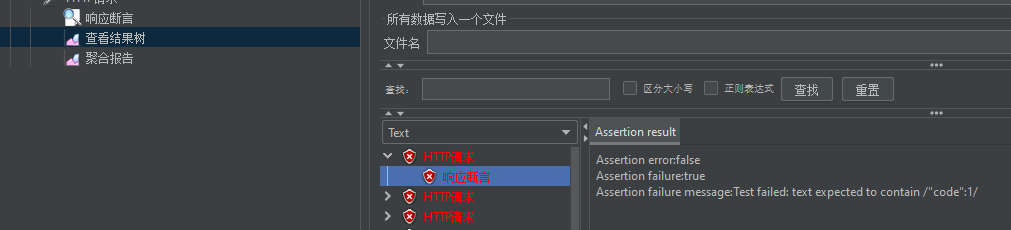
(5)选择指定HTTP请求:右键添加断言-》响应断言
(6)选择指定HTTP请求:右键添加监听器-》查看结果树
(7)选择指定HTTP请求:右键添加监听器-》查看聚合报告
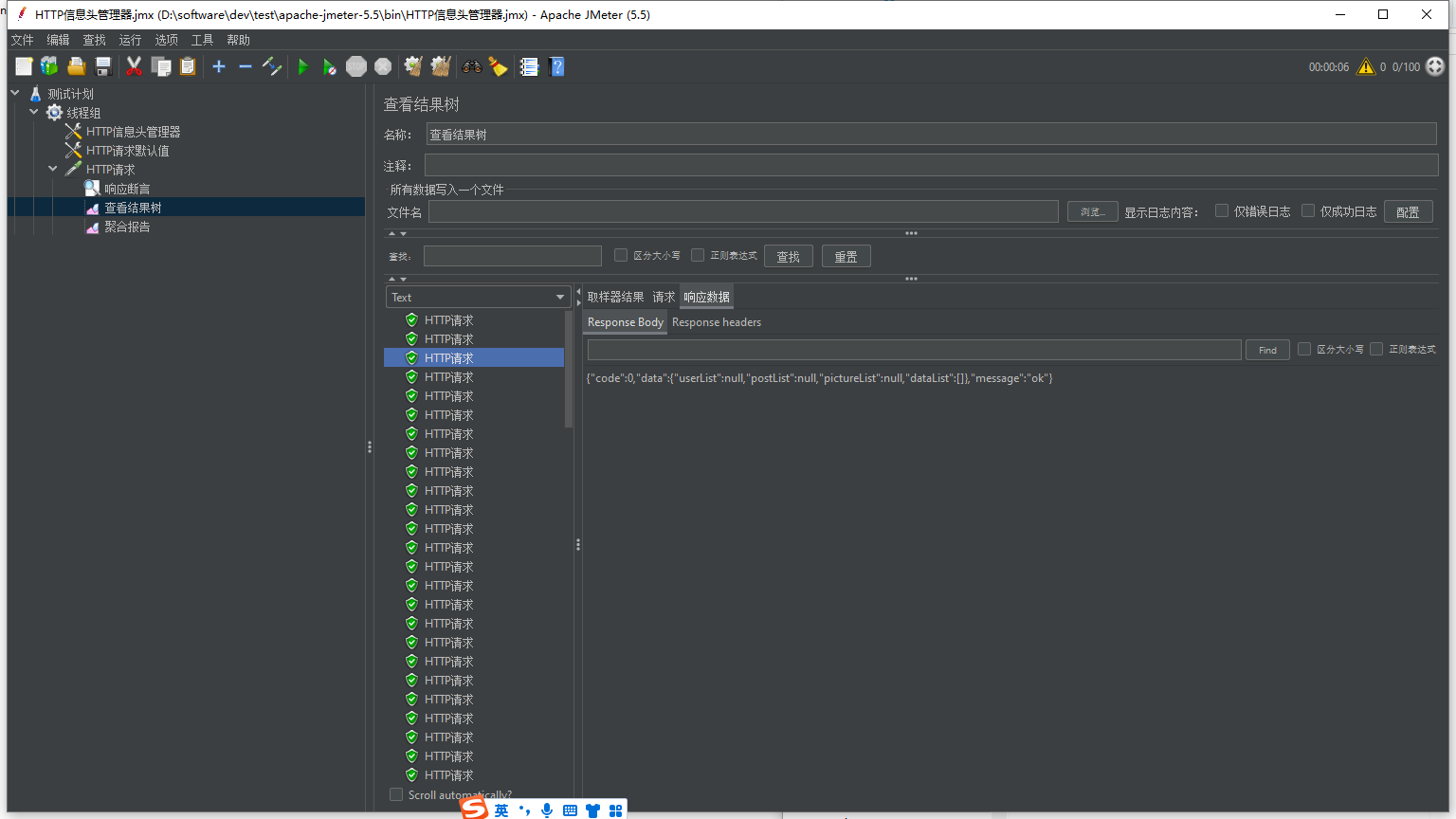
配置完成,点击启动按钮,查看结果树和聚合报告分析接口响应效率
聚合报告:压力测试(一般情况下关注99%和吞吐量两个比较重要的分位)
响应断言判断:
插件:https://jmeter-plugins.org/install/Install/
下载后文件为plugins-manager.jar格式,将其放入jmeter安装目录下的lib/ext目录,然后重启jmeter,即可。
参考文章:https://blog.csdn.net/weixin_45189665/article/details/125278218
项目扩展
搜索建议
搜索建议参考官方文档
GET post_v1/_search
{
"query": {
"match": { "content": "hello noob" }
},
"highlight": {
"fields": {
"content": {
"pre_tags" : ["<h1>"], "post_tags" : ["</h1>"]
}
}
},
"suggest" : {
"my-suggestion" : {
"text" : "hello noob",
"term" : {
"field" : "content"
}
}
}
}
搜索高亮
搜索高亮参考官方文档
GET post_v1/_search
{
"query": {
"match": { "content": "hello noob" }
},
"highlight": {
"fields": {
"content": {
"pre_tags" : ["<h1>"], "post_tags" : ["</h1>"]
}
}
},
"suggest" : {
"my-suggestion" : {
"text" : "hello noob",
"term" : {
"field" : "content"
}
}
}
}
高亮和建议值都可以从返回值拿到
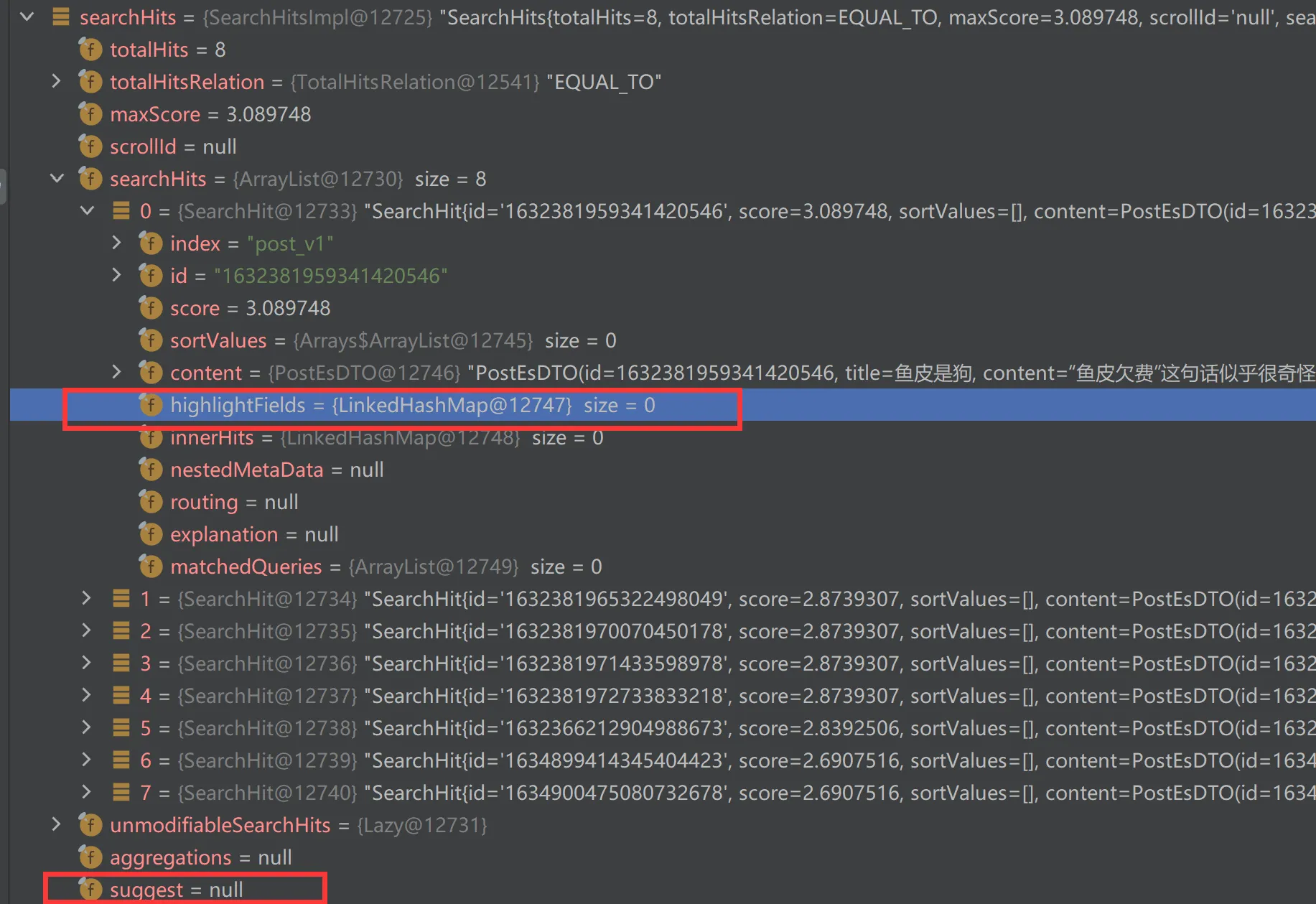
前端防抖节流(自行扩展)
问题:用户频繁输入、频繁点搜索按钮怎么办?
解决:使用 lodash 工具库实现防抖和节流。
节流:每段时间最多执行 x 次(比如服务器限流)https://www.lodashjs.com/docs/lodash.throttle
防抖:等待一段时间内没有其他操作了,才执行操作(比如输入搜索)https://www.lodashjs.com/docs/lodash.debounce
接口稳定性优化(自行扩展)
问题:调用第三方接口不稳定怎么办?(比如 bing 接口)
使用 guava-retrying 库实现自动重试:https://github.com/rholder/guava-retrying
参考文章学习:https://cloud.tencent.com/developer/article/1752086