【JFinal】⑤基于JFinal项目实现oracle与mysql的版本兼容配置
【JFinal】⑤基于JFinal项目实现oracle与mysql的版本兼容配置
[TOC]
基于JFinal项目实现oracle与mysql的版本兼容配置
将项目从mysql数据库迁移兼容oracle数据库,除却基本的的配置、语法调整,可以考虑在项目搭建和代码编写的时候考虑多数据源配置的整合方式,便于后期通过简单代码转换便能自由切换项目配置的主数据源,下述以EOAS项目为例进行简单说明,并针对通用的一些开发技巧作出思考
迁移步骤简单说明:
<1>数据库配置迁移
<2>项目配置调整
<3>项目接口相关sql调整
<4>数据库切换,进行项目流程测试
【1】数据库配置迁移
Oracle数据库迁移最常见的就是表和字段的大小写问题,此处通过EOAS项目简单叙述项目数据库的迁移兼容过程和常见问题处理
Mysql对应数据库创建配置:字符集一般选择“utf8—UTF-8Unicode”、排序规则一般选择“utf8_general_ci”(不区分大小写,校对速度快,但准确度稍差)
Mysql排序规则后缀的说明参考如下:
_BIN 二进制排序
_CI(CS) 是否区分大小写,CI不区分,CS区分
_AI(AS) 是否区分重音,AI不区分,AS区分
_KI(KS) 是否区分假名类型,KI不区分,KS区分
_WI(WS) 是否区分宽度 WI不区分,WS
Oracle:“不区分大小写”的概念是在没有引入双引号“”建立表或字段的前提下,在建表或者是定义字段的时候引用了双引号,则后续操作表必须以双引号的字符序列为准。下述在oracle数据库环境中简单通过案例进行说明:

当表和字段定义时未引用‘双引号’,则大小写不敏感正常生效,oracle正常转化成大写处理;当表和字段定义时引用了‘双引号’,此时的匹配规则则依赖于双引号中明确的字符序列,因此在针对某些情况下,失去了其大小写不敏感的作用
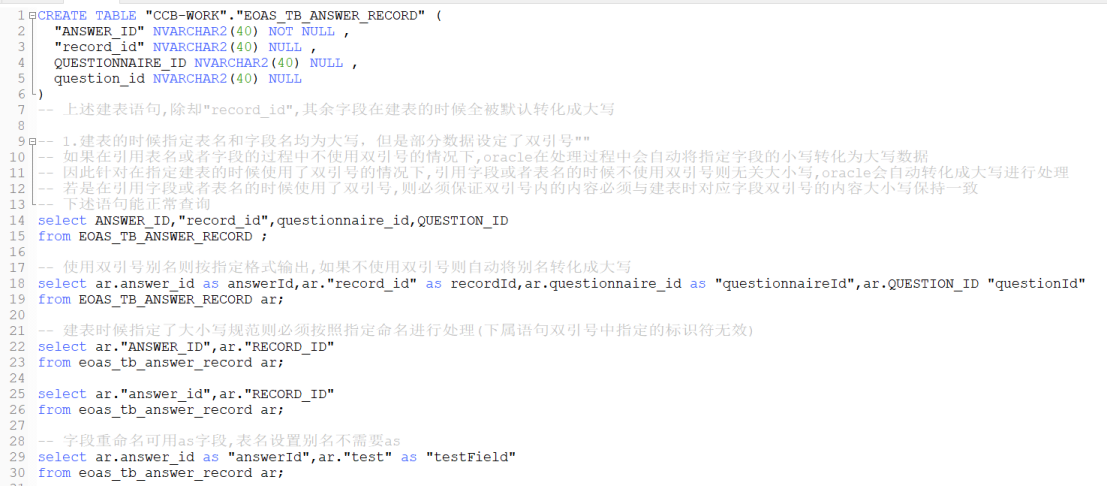
为了便于兼容mysql与oracle的sql特性,方便在两者之中进行灵活、简化的转化,简单说明几个在编码过程中的实用小技巧,实现mysql和oracle之间sql模板的通用转换,在尽可能不改动代码的情况下,建议
a.在oracle创建表的时候不使用双引号,实际建表语句大小写不限定,oracle会自动转换成大写,而mysql则保留指定格式
mysql:推荐表名和字段名均为小写设定、下划线:record_id
oracle:建表语句可与mysql保持一致,但建表时不使用双引号,字段使用下划线规范字段命名(oracle会相应自动转换为大写)
mysql到oracle的数据库配置迁移:使用mysql迁移数据库到oracle,随后导出sql语句,去除双引号限制,冲去创建无双引号限制的oracle。oracle指定表空间(用户名)可带上双引号,去除表名和字段定义的双引号,可使用编辑器进行全局编辑(注意双引号的中英文切换)
b. 在编写sql语句的时候考虑sql语句在对应数据库的通用性
例如在mysql中支持用‘as’关键字给字段和表起相应的别名,而在oracle中仅仅支持用as关键字给字段起别名。因此。考虑配置的通用性,可参考如下实现方式:

为简化sql代码和规范代码,以双引号形式命名,强制区分大小写(驼峰命名)
c.在尽可能减少逻辑代码的变动的基础上实现数据库迁移兼容
一般来说代码编写规范要求MVC架构编写风格,因此会在dao层统一封装数据库操作相关接口,不建议将数据库的sql操作嵌入到各式各样的业务逻辑中,建议在业务逻辑中调用dao层实现功能。但实际上,由于代码编写不规范,在编写代码的时候难免会将sql语句直接嵌入到代码逻辑中。此外,通过拼接生成的sql语句难以调试,而且经常会触发一些难以发觉的小问题导致程序出错。因此建议参考sql模板的方式编写sql语句,便于进行语句调试,提升效率。
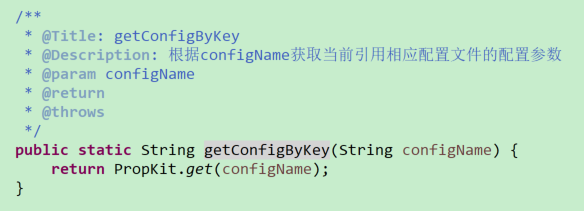
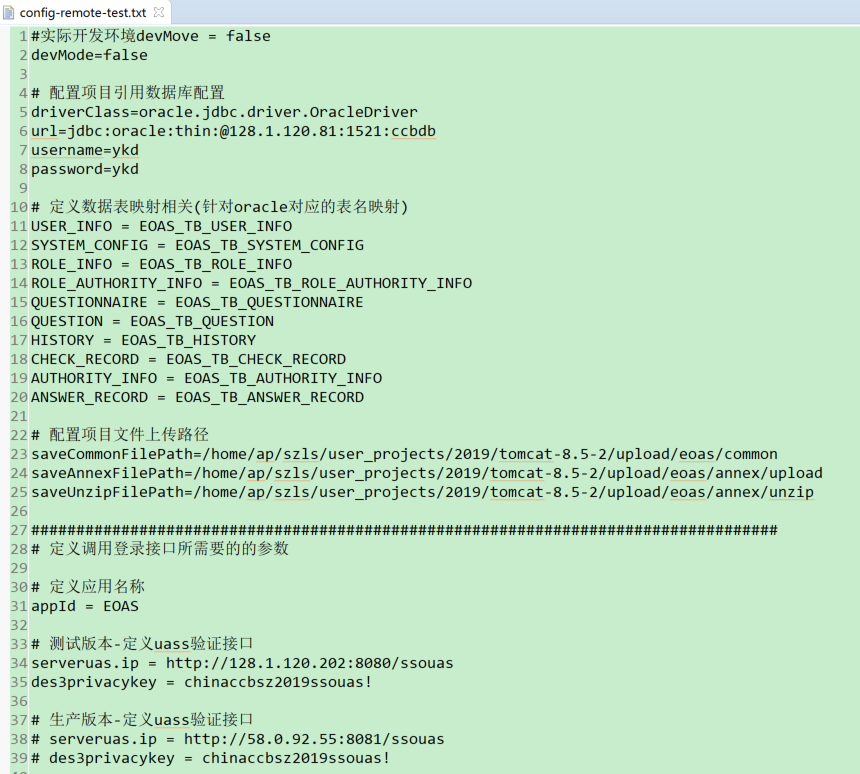
除此之外,在JFinal框架中借助Db+Record的形式实现数据库操作,需要传入指定表名进行操作,为了尽可能减少逻辑代码的变动,此处表名可以不限定常量字符串,而是通过从指定版本的配置文件中获取的方式实现(约定统一的变量名称)
不要在代码逻辑中嵌入sql语句
在dao层管理Db操作:dao层调用template模板完成数据操作
适配不同版本数据库中表名定义不同的情况

调整方式1:将数据库操作全部放置在指定sql模板,在sql模板中进行操作
调整方式2:根据不同的数据库类型定义相应的配置文件,一般sql语句放置在指定sql模板,一些在代码中使用的sql,或调用jfinal自定义的save或update方法,则从配置文件中获取指定的value值随后根据不同的表名执行操作即可。但针对save、update方法需要注意实体类日期相关的字段的处理
【2】项目配置调整
步骤说明:
a.数据库连接确认:确认引用数据库连接、用户名、密码以及关联数据表名
b.服务器文件路径确认:确认指定上传文件或下载文件临时存放的服务器路径
c.确认调用远程登录接口引用的服务路径和参数
a.在pom.xml配置文件中引入jar

需要利用maven指令将,ojdbcX.jar载入到本地仓库:
命令:“mvn install:install-file -Dfile=D:\oracle\ojdbc6.jar -DgroupId=com.oracle -DartifactId=ojdbc6 -Dversion=11.2.0.1.0 -Dpackaging=jar”
提示:-Dfile对应jar包所在路径,-DgroupId对应仓库下具体的下载位置,也是pom文件中的groupId,后面的内容也对应pom文件的内容
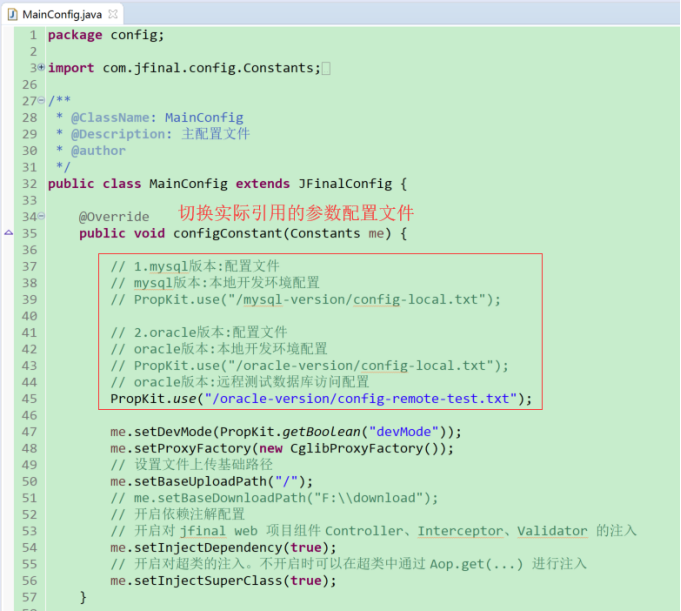
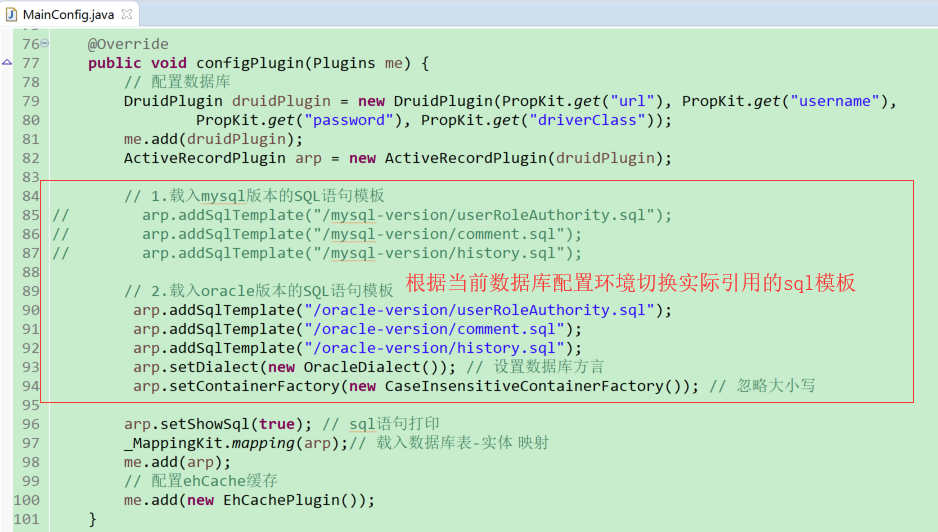
b.根据当前数据库配置环境切换实际引用的sql模板
项目实现了mysql与oracle版本的通用切换,如果需要切换数据库环境,只需要在相应JFinal主配置文件中,切换引用的配置文件和加载的sql模板(切换数据库引擎)即可
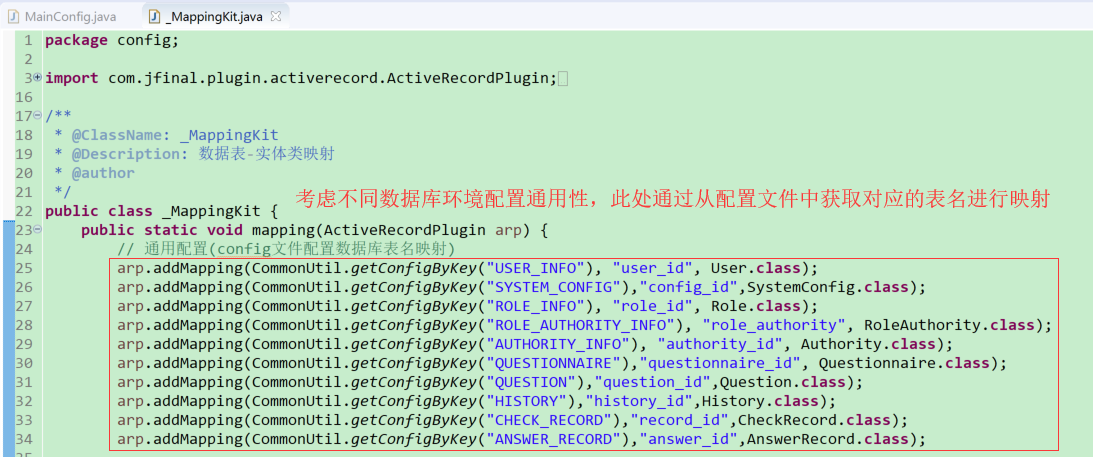
c._MappingKit数据库实体映射
考虑不同数据库环境配置的通用性(不同开发环境数据库表名可能不同,但目前设定需要保持字段定义一致),此处通过从配置文件中获取对应的表名进行映射,因此不需要变动_MappingKit文件的配置,但是相应地需要检查引用的配置文件中是否对项目中所需要引用的表名做了定义,如果没有配置或者配置出错会直接影响程序运行
此外,由于项目中设定了oracle语言忽略大小写,因此在oracle数据库建表的时候表名和字段名不推荐使用双引号(oracle默认转换大写,如果使用了双引号则标识了对象或字段将严格区分大小写,可能对程序中部分sql执行造成一定的影响,导致程序执行异常)
d.常见问题
问题描述:切换oracle版本后项目启动的时候报下述错误
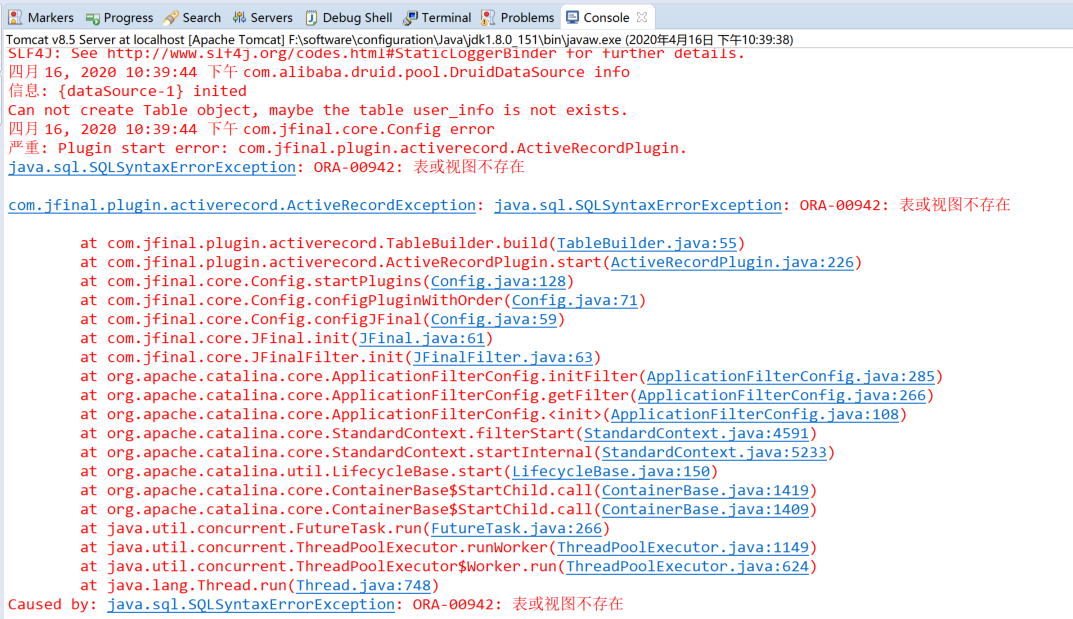
问题分析:
检查配置初始化映射的实体与数据库表名是否匹配
检查数据库连接相关配置、检查表名配置(表名大小写问题))
检查当前访问的oracle数据库是否有权限访问该表
赋予指定用户权限可借助可视化工具,亦可借助oracle指令:以系统管理员的身份登录oracle数据库,执行指令“grant connect,resource to username;”赋予该用户指定权限;“grant dba to username”是赋予系统管理员的权限
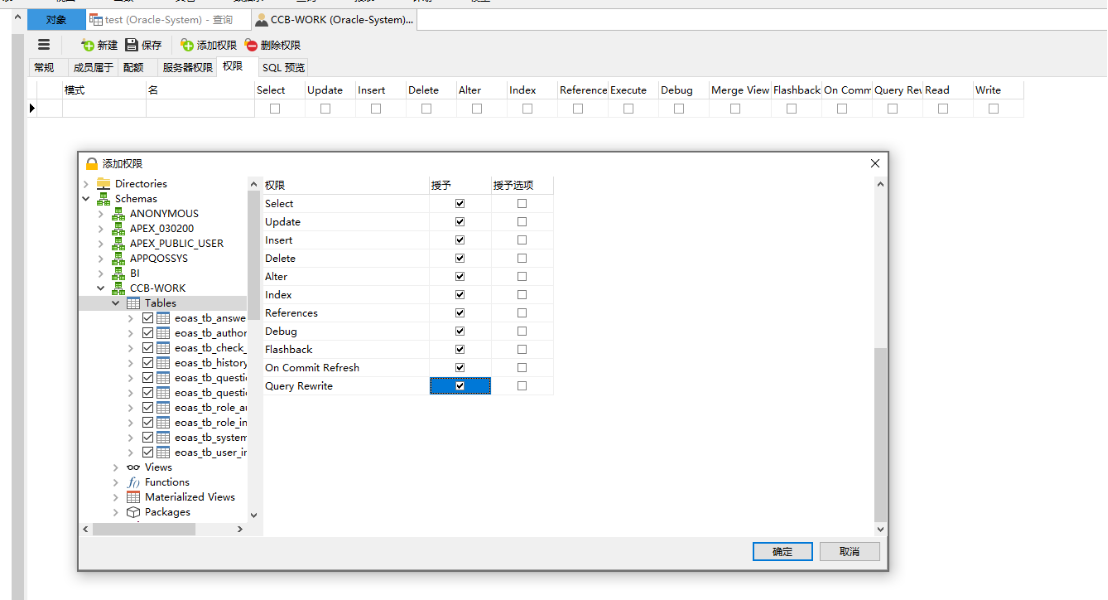
问题解决:
上述问题是因为通过navicat工具直接将mysql的数据表传输到oracle数据库,法案现限定了表名和字段名的大小写,导致大小写敏感失效,从而无法找到相应视图。之后通过调整可正常访问,但为了实现配置的通用性,此处通过“PropKit”的get方法获取到相应版本的配置文件中的数据库表名,从而不需要每次数据库变动都去调整该文件

【3】项目接口相关sql调整
除却一些特殊的方法和函数、日期格式等问题,mysql与oracle的语法基本类似
a.基本sql模板数据库表名确认
采用Db+template的方式对数据库操作,在对应版本的sql模板中表名也要与相应数据库一一对应
b.区分不同数据库的sql定义规则和操作结果
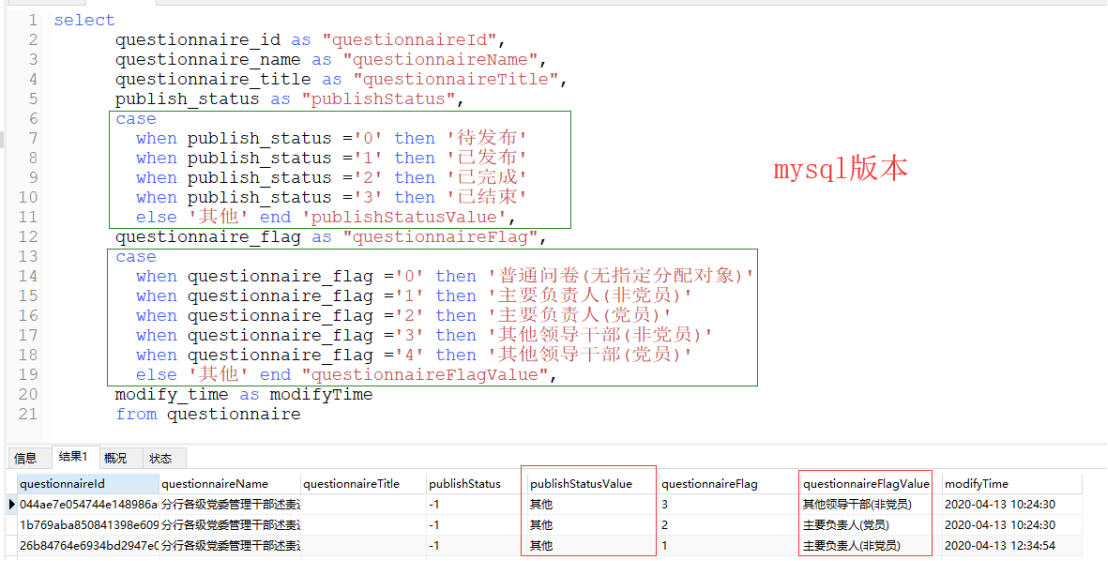
(1)as关键字的使用
例如在mysql中支持用‘as’关键字给字段和表起相应的别名,而在oracle中仅仅支持用as关键字给字段起别名。因此。考虑配置的通用性,可参考如下实现方式:

(2)双引号规范别名
引用别名必须使用双引号,mysql中可以识别‘’且不报错
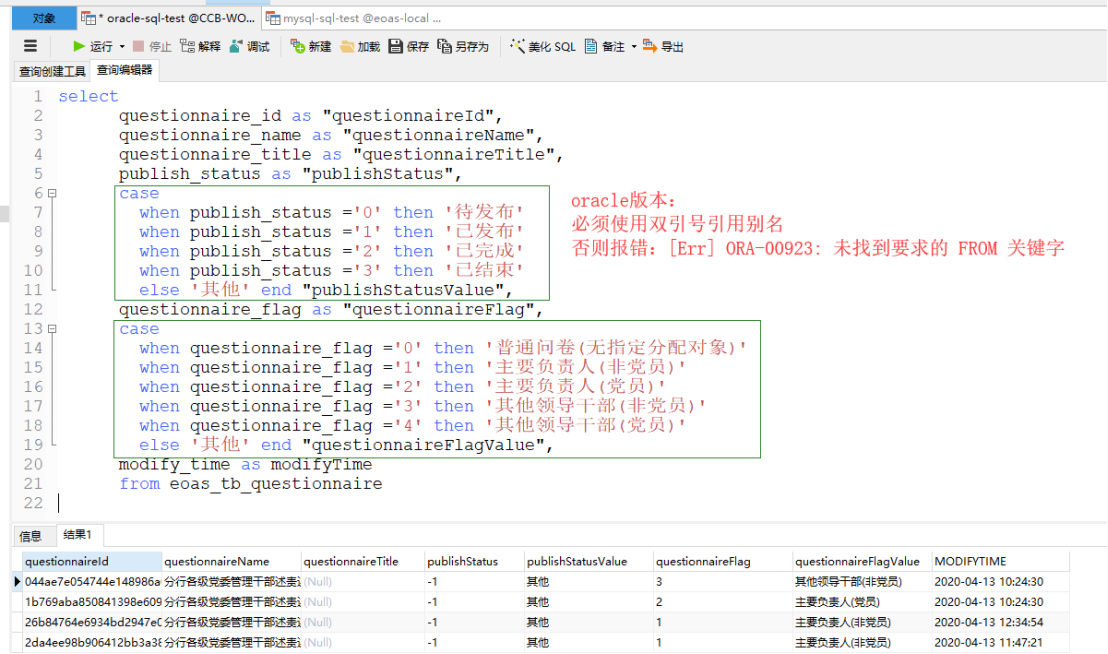
关联表引用别名:可以关联查找的时候不特别引用带有“双引号”的别名,最终查找反显数据再对查询的最终字段加双引号进行特殊标识
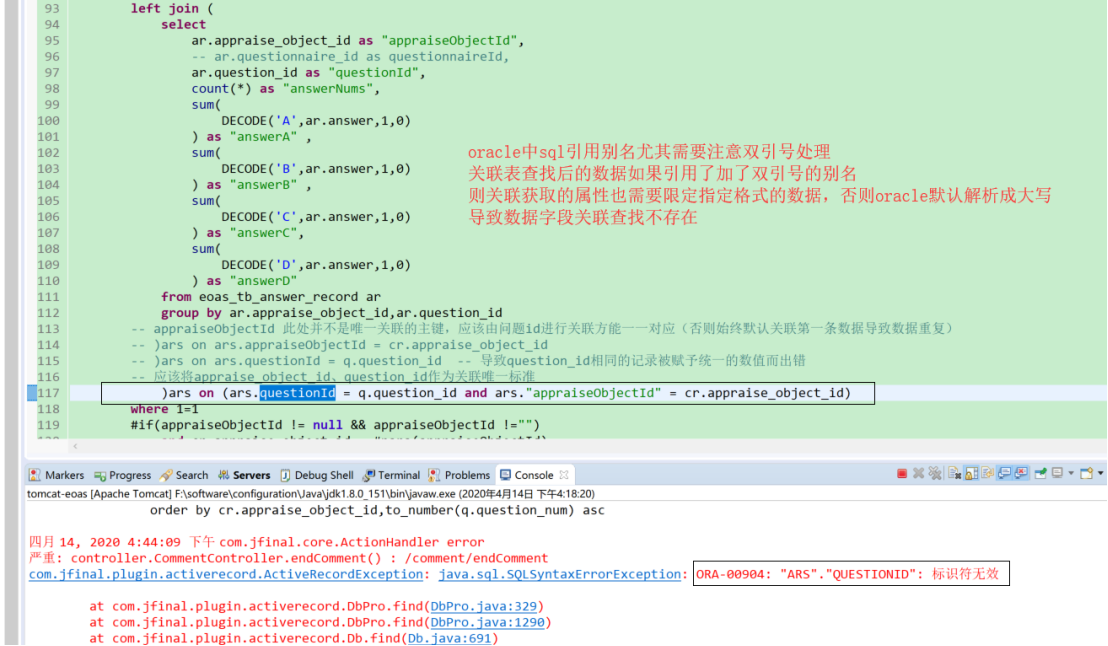
(3)日期格式问题
参考学习链接:
Oracle时间日期函数及sql语句:https://blog.csdn.net/sixi_sky/article/details/73368835
JFinal中调用批量插入到mysql操作,直接插入有效的日期字符串(格式化)不报错
JFinal中调用批量插入到oracle操作,日期格式限定(oracle中需用to_date函数转换)

to_date的格式:to_date([要转换的时间],[转换成的时间格式]), 两个参数的格式必须匹配,否则会报错。
需要注意的是,在Java中的时间格式是“yyyy-MM-dd HH:mm:ss”,但是在oracle的sql中由于不区分大小写,时间格式中的“mm”将被识别为月,导致出现“ORA 01810 格式代码出现两次”的错误。所以Oracle的SQL采用了mi代替分钟,oracle的全时间格式为“yyyy-MM-dd HH24:mi:ss”。同时,要以24小时时间的形式显示出来要用HH24,而不是HH。
to_char(日期,转换格式 ) 即把给定的日期按照“转换格式”转换。
yyyy 用4位数表示年,mm 用2位数字表示月,dd 表示当月第几天。同时,用q表示季度,用ww 来表示当年第几周,w用来表示当月第几周。ddd表示当年第几天,dd 表示当月第几天,d表示这个星期的第几天。
调整说明:
如果是针对单个数据插入操作,可以在sql模板中自定义插入规则,使用oracle的转换函数执行操作,但是针对批量插入操作则需要考虑其他的因素,且需要在不影响原有mysql正常执行的情况下调整代码

为了解决日期格式限定问题,可以用‘java.sql.Timestamp’(时间戳)定义日期,此种方式在mysql和oracle均适用,只需在设定参数值的时候限定日期类型为Timestamp即可
Timestamp currentTime = CommonUtil.getCurrentSystemTimeBySQL();

常见Timestamp使用:
- String --> Timestamp
Timestamp的valueOf()方法:Timestamp转换为String可以直接.toString(),但有时候显示时是不需要小数位后面的毫秒值,需要借助DateFormat在转换为String时重新定义格式

- java.util.Date --> Timestamp
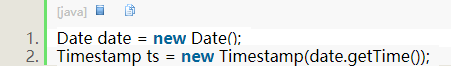

获取毫秒值:
System.currentTimeMillis(); (推荐使用,速度最快)
Calendar.getInstance().getTimeInMillis();
new Date().getTime();
(4)批量操作返回结果
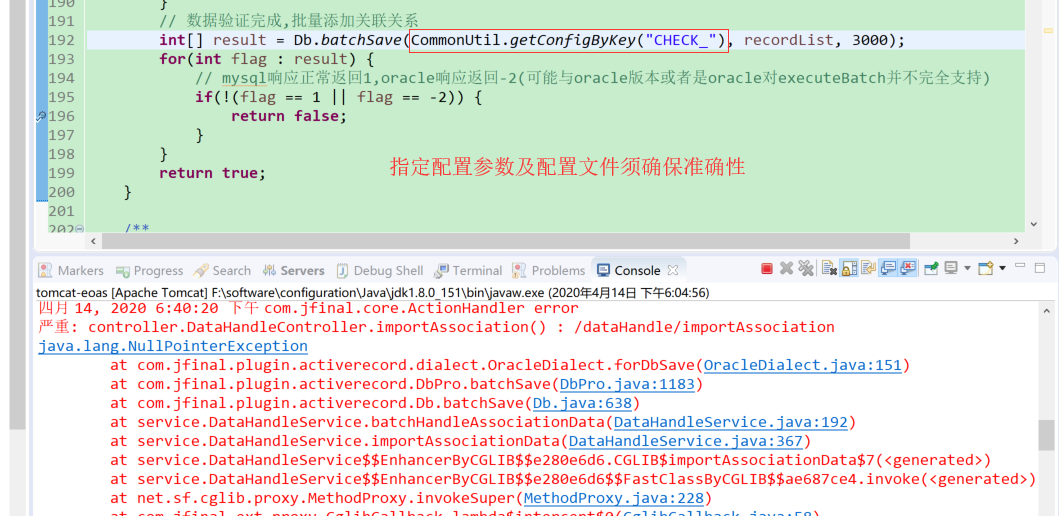
JFinal 执行Db.batch访问mysql数据库响应成功正常返回结果为1
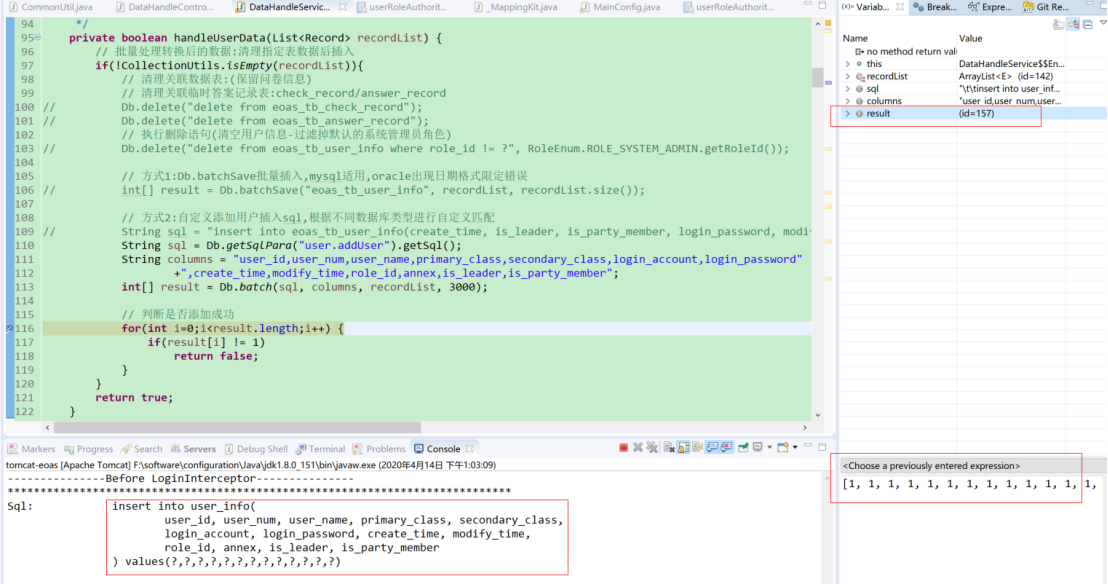
JFinal 执行Db.batch访问oracle数据库返回结果为-2,但实际上测试数据导入成功
可能是oracle版本问题?(考虑更换ojdbc相关jar或者切换不同的数据库版本)
参考学习链接:http://blog.sina.com.cn/s/blog_56d8ea900102x2pq.html
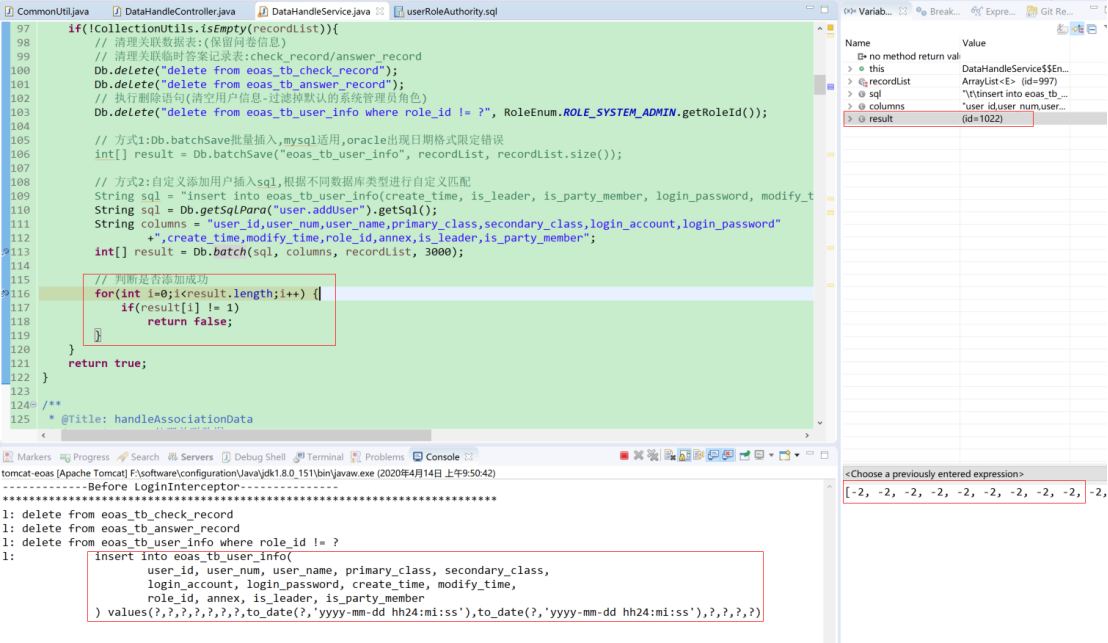
针对批量操作结果验证的问题,数组返回的结果针对的是受影响行数,一般是0或者1。Oracle之所以出现‘-2’的情况考虑是oracle对executeBatch并不完全支持,亦或是所使用的的oracle驱动和所访问的oracle版本不兼容所致。如果需要验证DB操作的有效性,判断数据是否操作成功,可参考如下思路:
方式1:循环遍历验证数组元素是否为正常执行后返回的标识
方式2:一般数据操作失败会抛出指定异常,因此可考虑借助try...catch...语句捕获异常抛出异常提示
(5)数据分页问题
正常情况mysql和oracle分页正常处理,但如果在筛选语句中使用了distinct关键字,在oracle版本中可能导致分页存在小问题
distinct影响下的数据分页
Oracle下的分页逻辑分析:

分析oracle分页的逻辑,先查找总记录条数,如果总记录条数为0直接返回结果,不执行分页查找操作,所以存在错误的sql语句不能通过空集合筛选出来;若筛选记录条数不为0则调用真正的数据库查询语句直接进行分页,此处错误的sql则访问报错(相应可分析一下mysql)
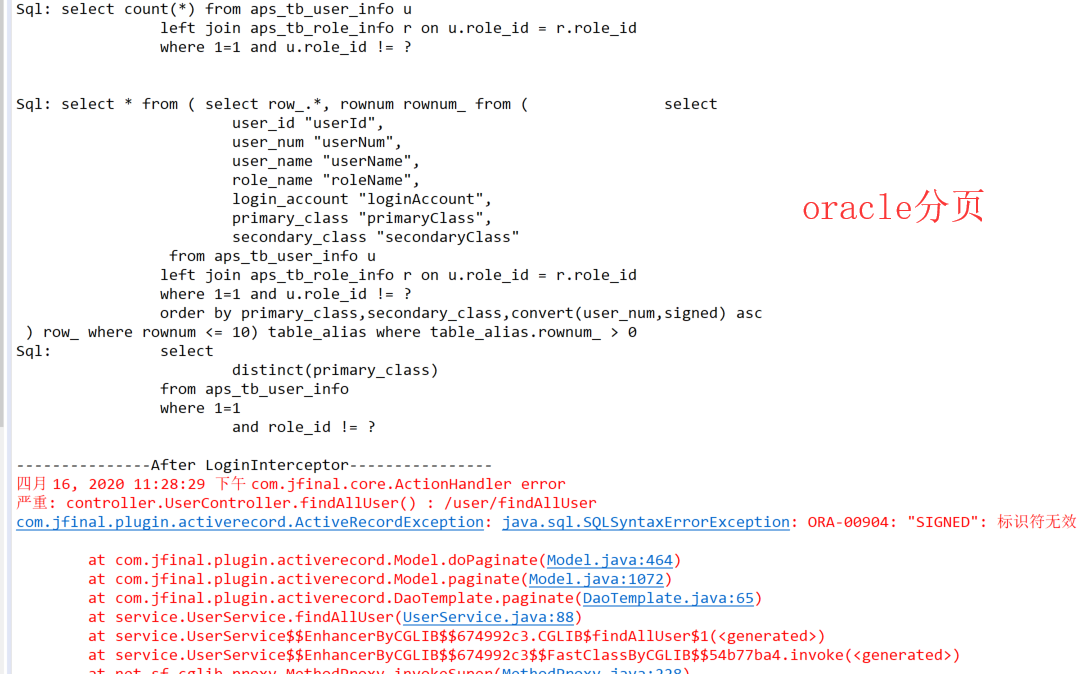
Oracle版本分页数据出现异常:
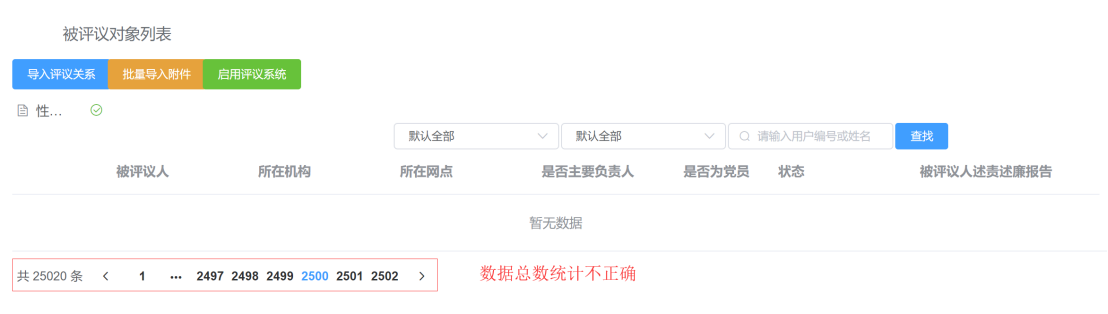
设置断点分析,oracle获取的分页统计数据是appraiseObjectId字段没有去重之后的统计总数,但实际数据返回却是去重后的record记录
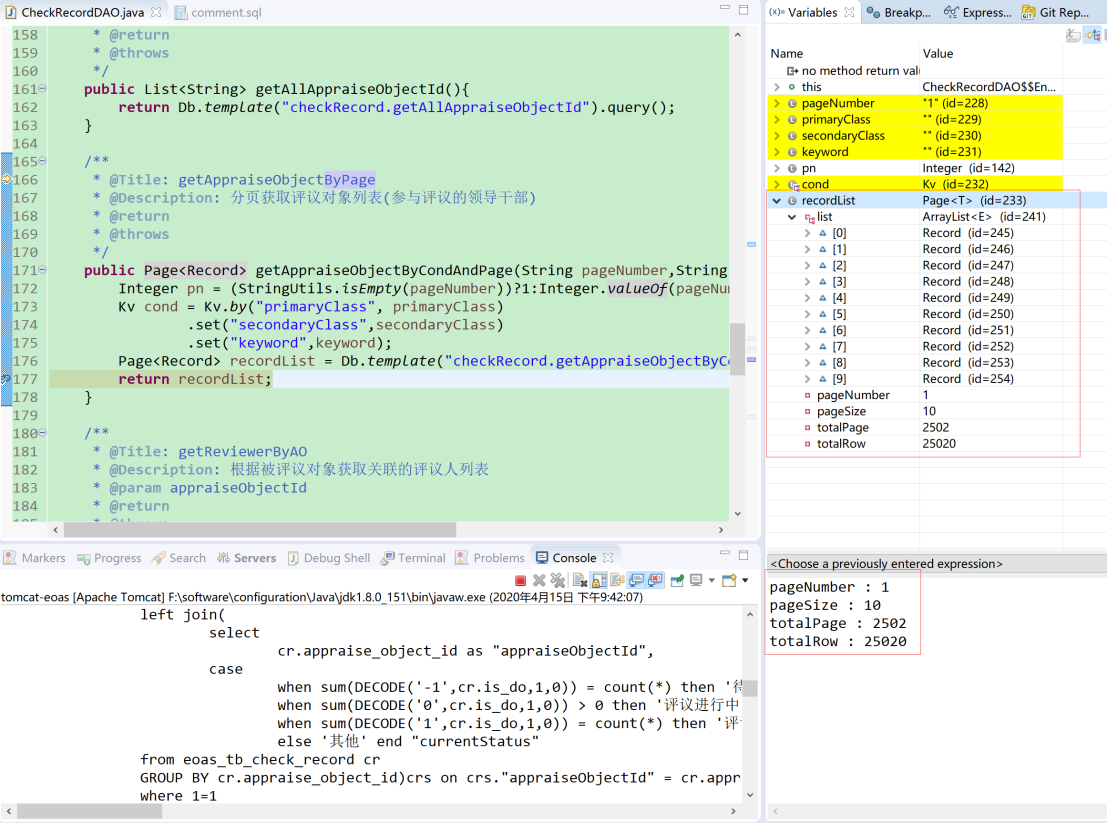
Oracle分页涉及到伪列概念:https://learnku.com/laravel/t/36993
原因分析:使用 paginate 分页的同时 distinct 去重,会导致分页数出错。具体表现在paginate会无视distinct的作用,按照原来搜索出来的结果进行分页。
在从mysql迁移到oracle数据库的时候,mysql中使用group by进行去重,但由于切换到oracle不允许未经group by 的字段出现在select中,所以在oracle中用了distinct去重导致分页出错。
解决思路1:因此此处考虑在oracle版本中先进行group by,后根据分组后的主体记录关联查找数据即可
解决思路2:外层嵌套select * from(原有带distinct的查询结果)as temp;(但这种方式会导致子查询为视图时性能降低)
解决思路3:JFinal修改调用分页方式
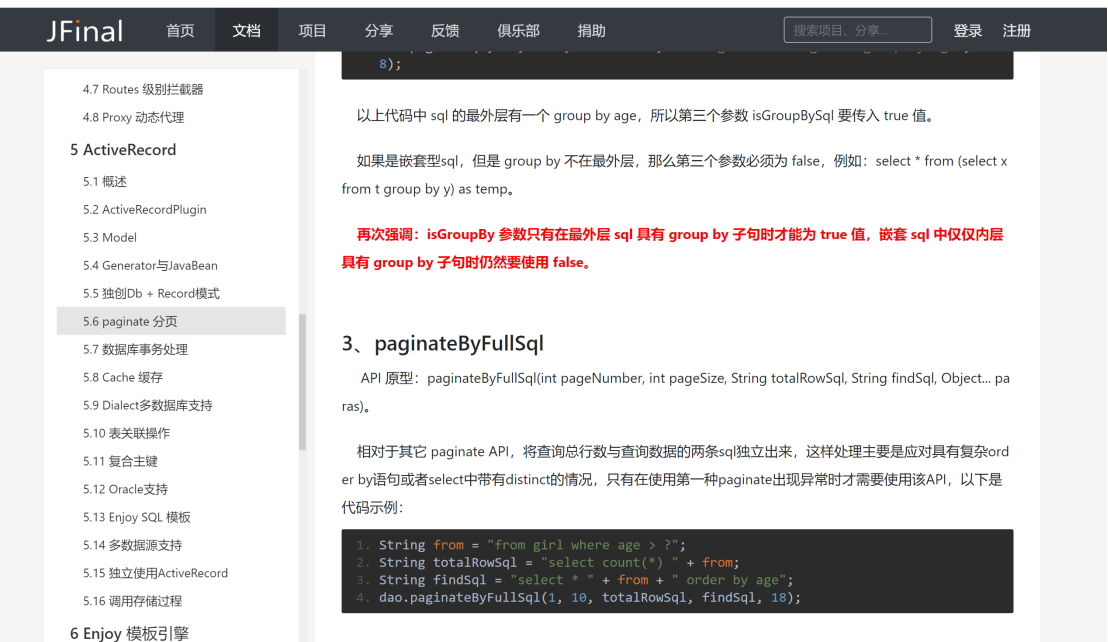
解决方式:为了尽可能不变动业务逻辑代码,此处考虑采用方式一解决问题。将需要去重的字段进行group by以及分组统计,随后以统计后的数据作为主表,根据appraiseObjectId关联数据

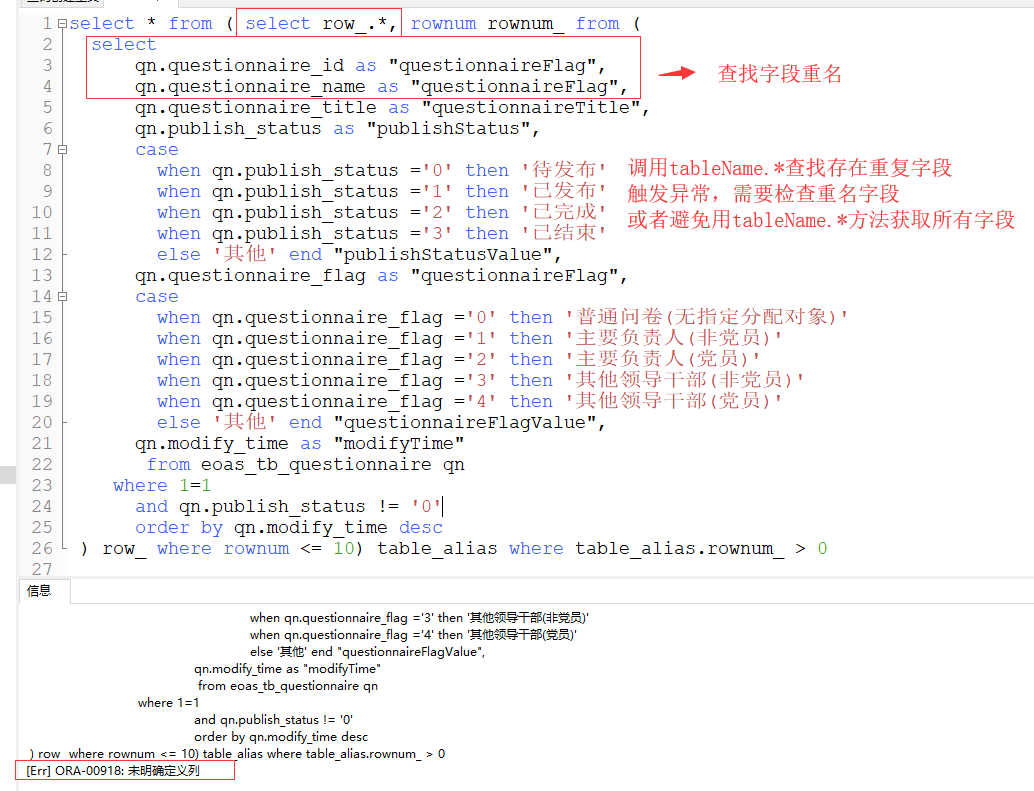
进一步解决distinct和分页的矛盾

错误:[Err] ORA-00918: 未明确定义列
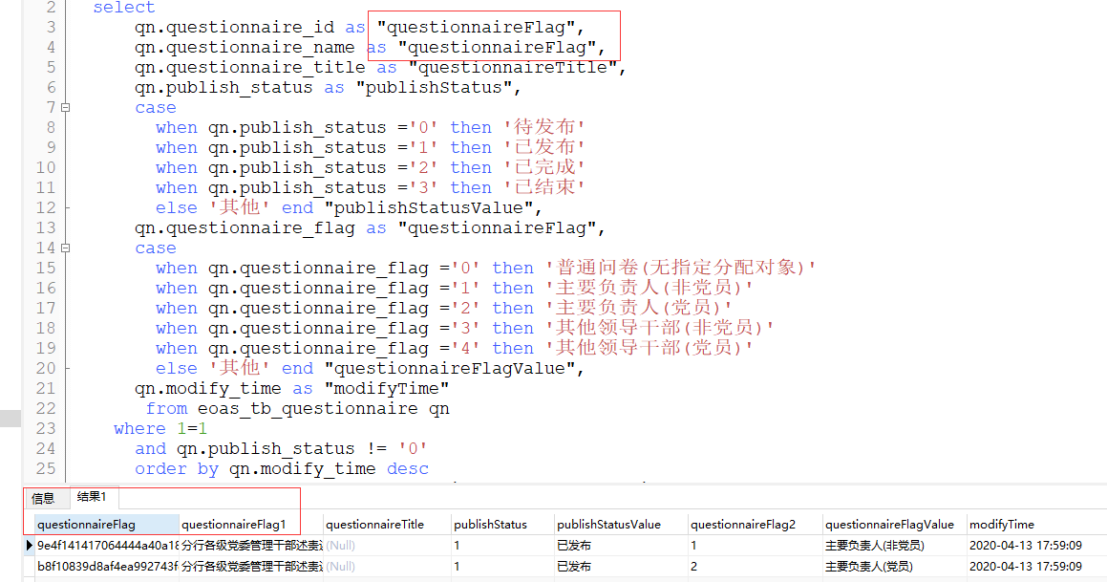
普通查找的时候如果字段同名:数据库会自动为查找字段后添加标识数字进行区分
如果调用分页:会在已有筛选数据的基础上进行分页,此时如果出现重名字段会导致“[Err] ORA-00918: 未明确定义列”错误
常见还有在关联表查找出现重名字段也会出现这种问题
(6)特殊方法调用
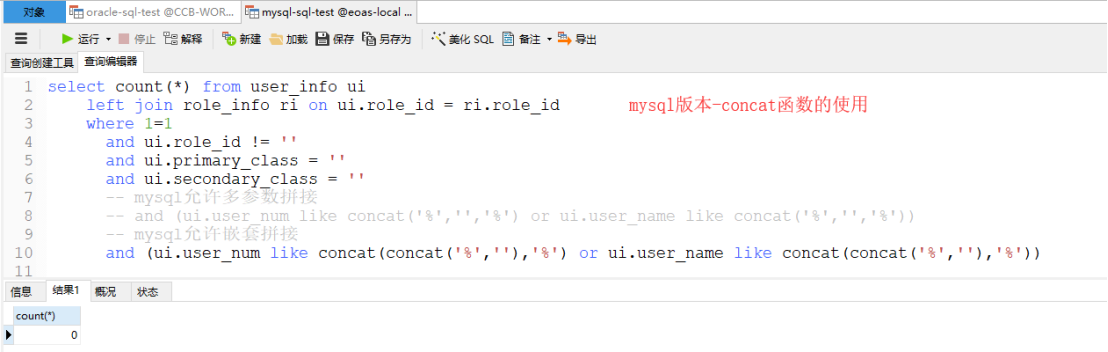
concat函数
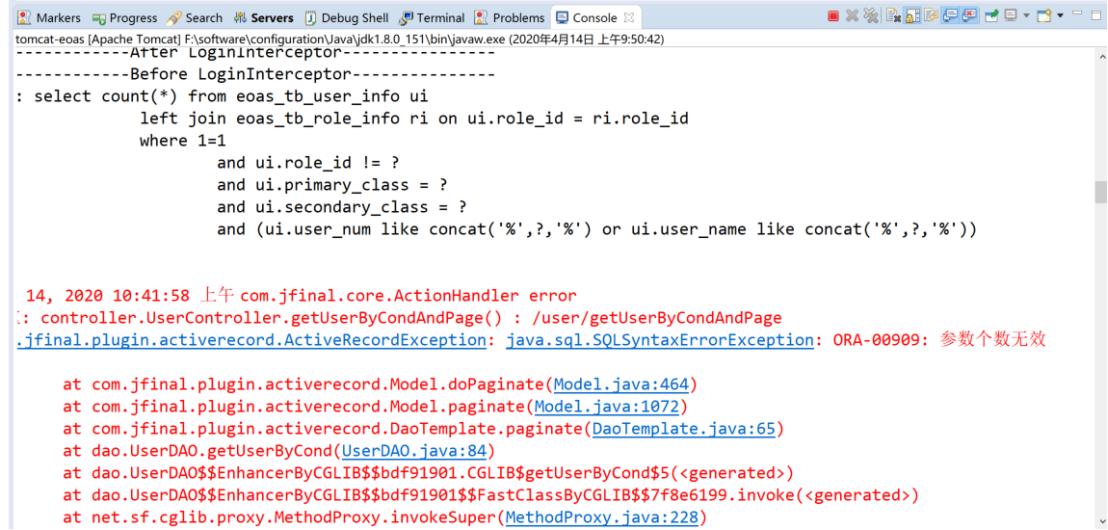
在oracle中使用concat连接多个字符的时候需要嵌套操作
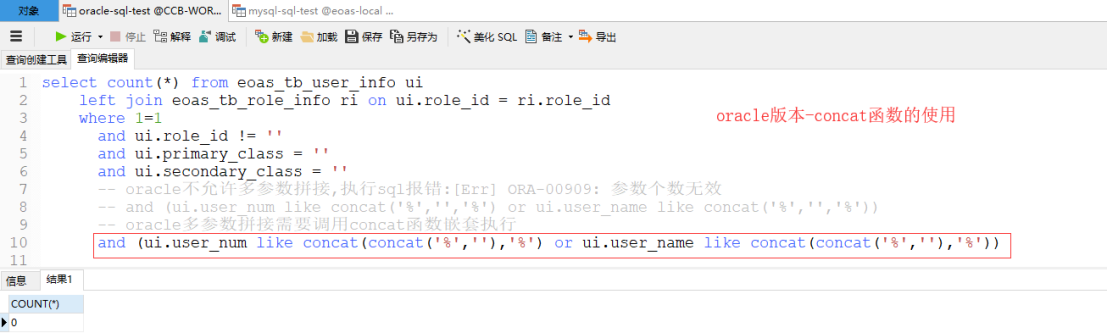
类型转化函数
问题编号排序,将问题编号字符串数据装换成int数值进行排序:
Mysql中使用convert函数或者是cast函数:
convert(question_num,signed)、cast(question_num as sssigned)
Oracle中使用to_number函数:
to_number(question_num)
order by to_number(question_num) asc
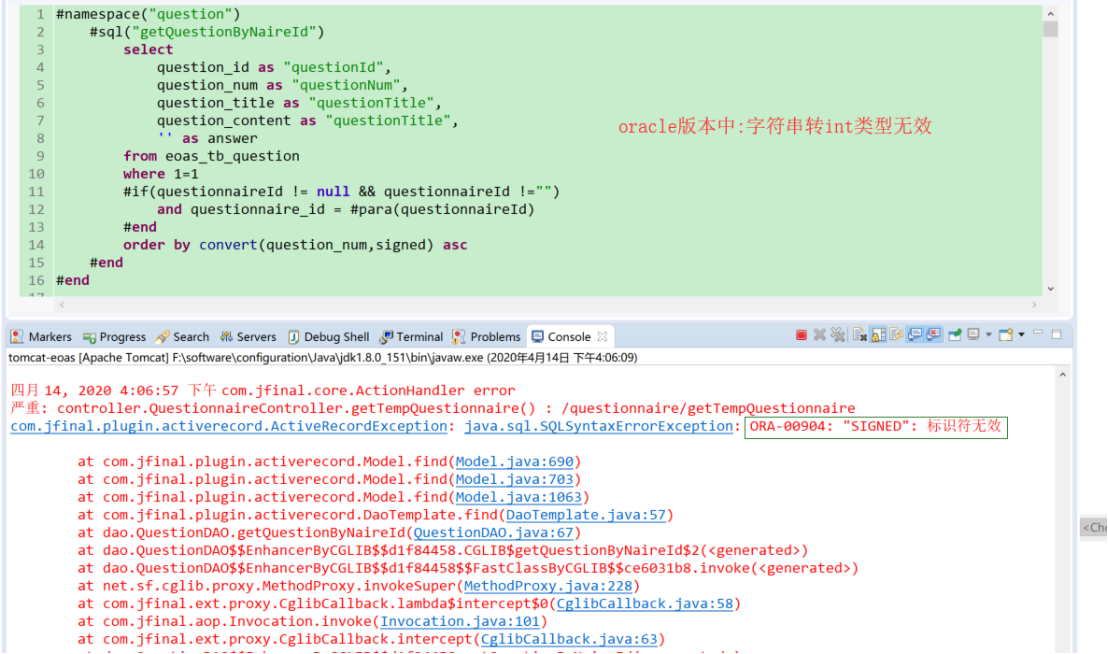
(7)统计相关函数使用
If(mysql)和DECODE(oracle)
应用场景:在指定的筛选范围统计指定字段的个数
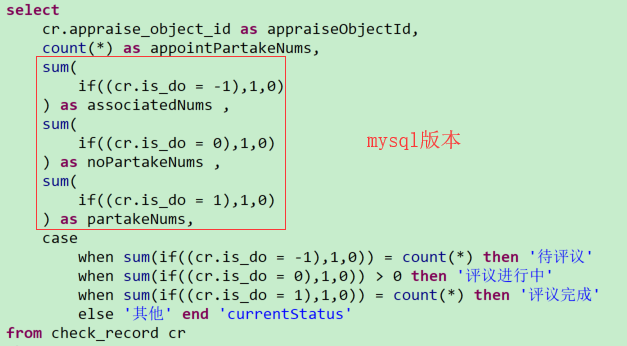
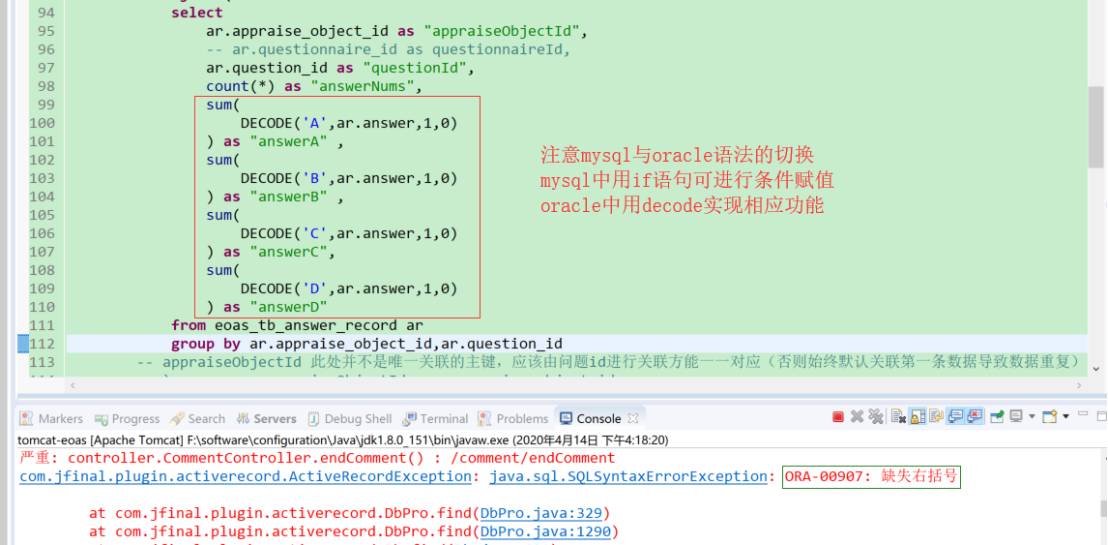
Mysql统计答题个数:if((ar.answer = 'B'),1,0)
Oracle统计答题个数:DECODE('A',ar.answer,1,0)
IFNULL(mysql)和NVL(oracle)
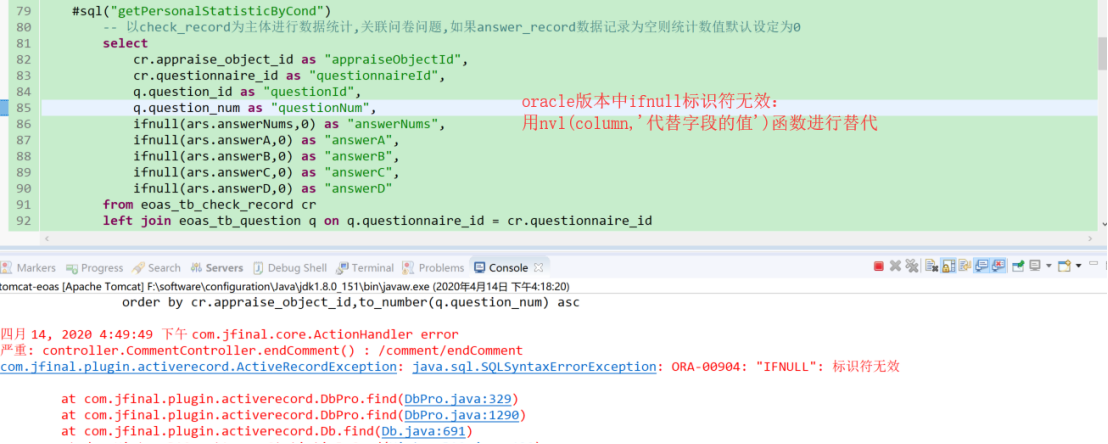
GROUP BY函数
在oracle版本中测试的时候出现错误:ORA-00979: 不是 GROUP BY 表达式
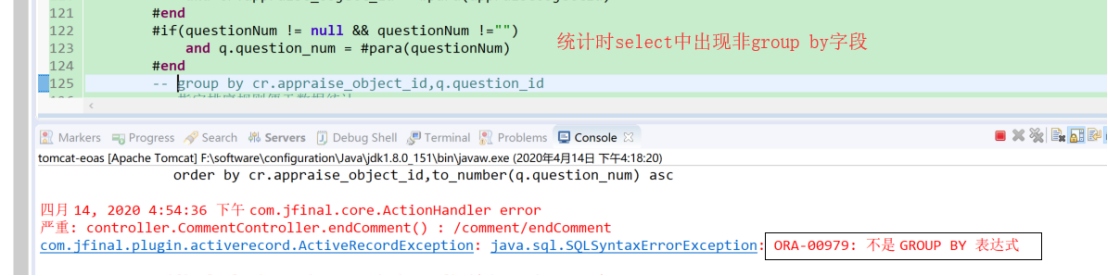
mysql和oracle中group by函数的使用规则有所不同,mysql中order by的使用没有限制,会自动读取第一行数据,而oracle在使用group by时,查询字段必须是分组的依据或者是聚合函数。由上述分析可知在mysql中使用group by的时候稍有不慎就容易忽略统计结果的正确性 ,因此在编写sql语句的时候建议严格按照oracle中group by的使用规范

Oracle:在统计的时候关联查找其他列的数据,可以先将统计后的数据作为一个新表,随后查找主体信息关联其他表数据,并根据指定字段关联相应的统计信息
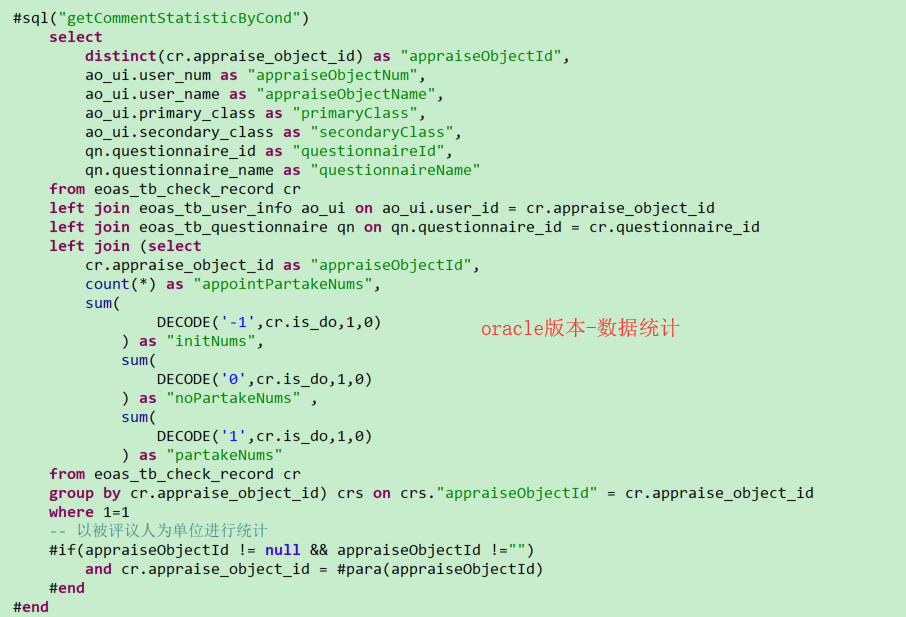
统计所有被评议人接口

尤其需要注意可能存在问题:配置中的参数设置不正确或者是配置文件没有指定字段,Db执行的时候如果没有指定正确的数据表,则Db初始化不正常,oracle执行报错
(8)数据类型问题
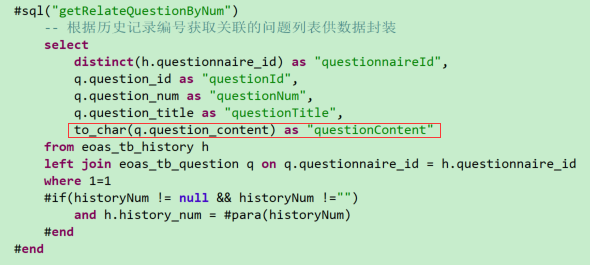
在oracle版本中:通过select方法获取数据库字段类型为NCLOB的字段,需要通过to_char方法进行转化
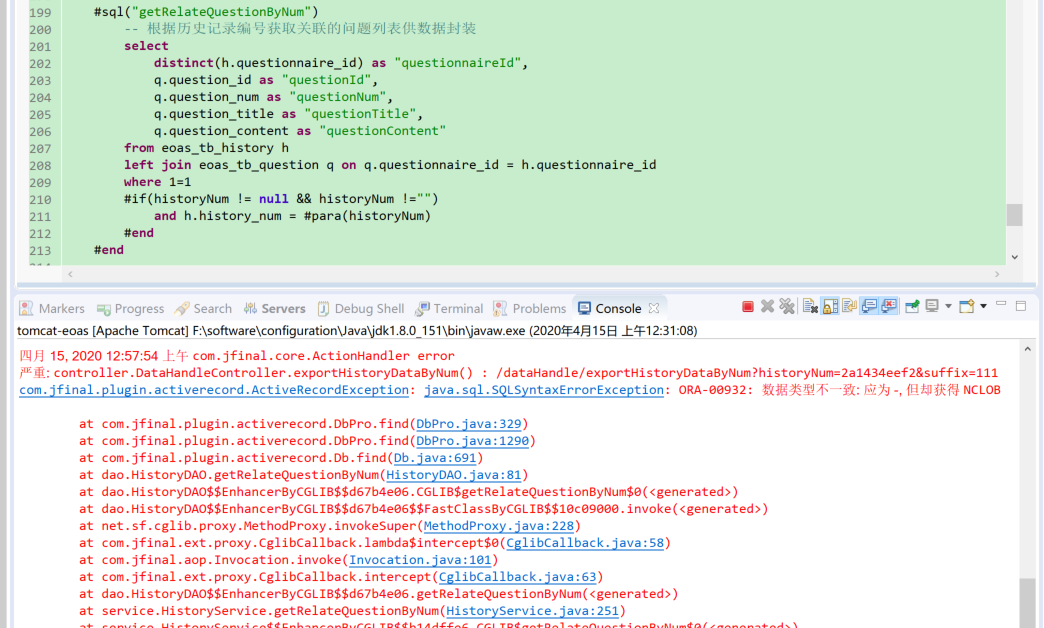
问题排查:检查oracle表字段
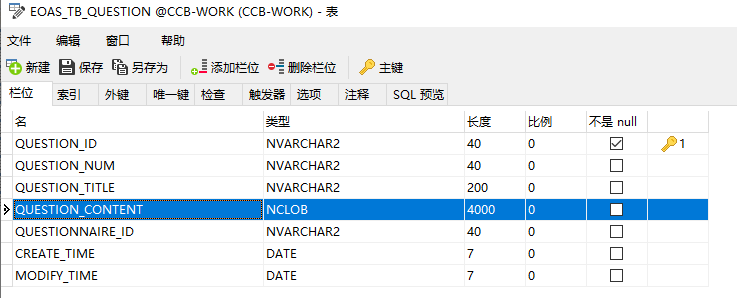
问题解决:
(9)调用中的无效参数
oracle版本下保存数据出错:java.sql.SQLIntegrityConstraintViolationException: 调用中的无效参数
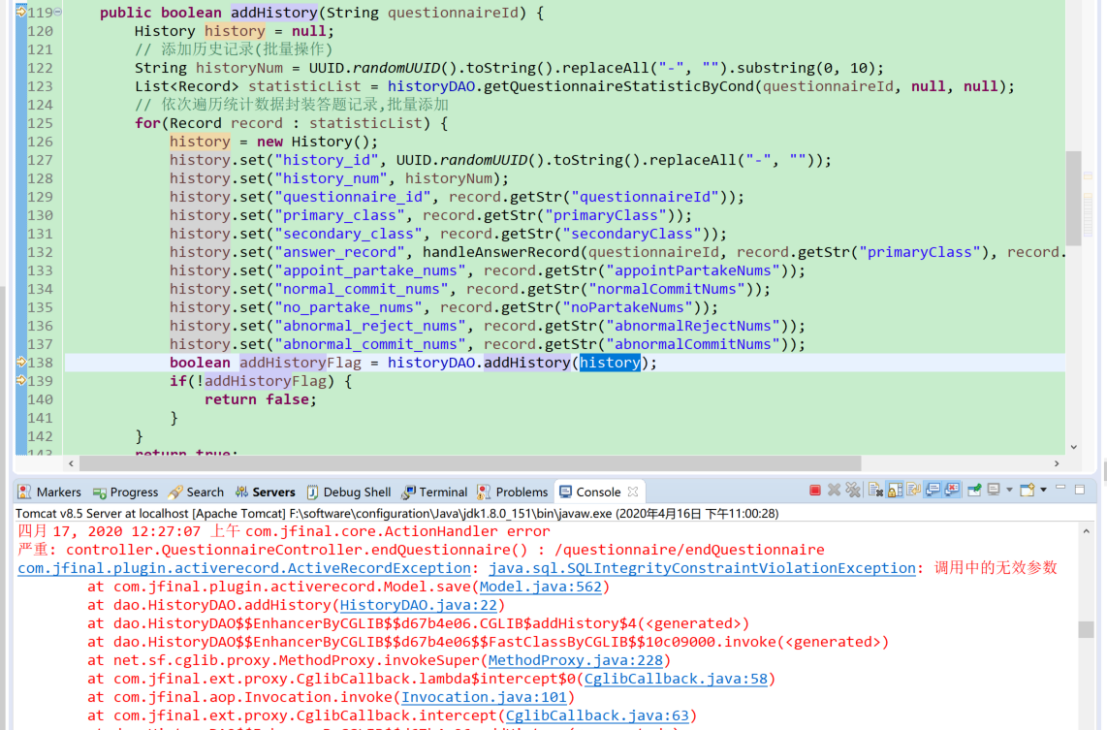
上述问题是在oracle版本下测试发现,在mysql版本下数据正常执行(就算id映射写错,没有出现异常说明)
如果插入报空指针,检查是否配置了映射关联_MappingKit;如果插入报调用中的无效参数,检查映射关联是否正常;必须确保表名和id映射要完全正确(mysql下没有验证出该错误,oracle版本下执行出错)
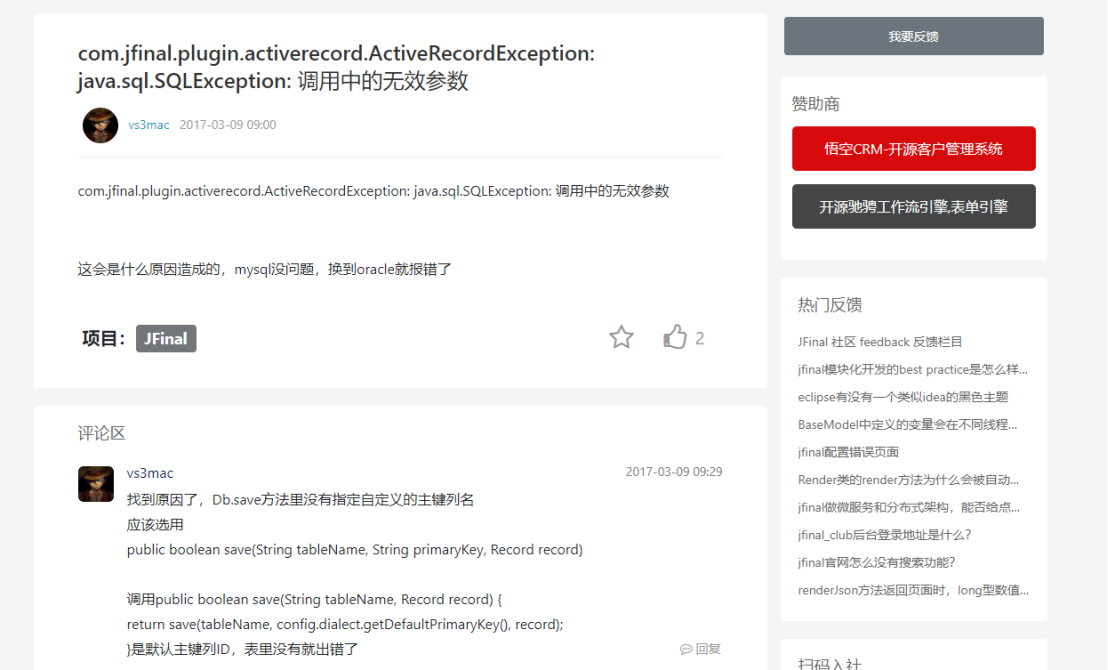
检查映射配置:
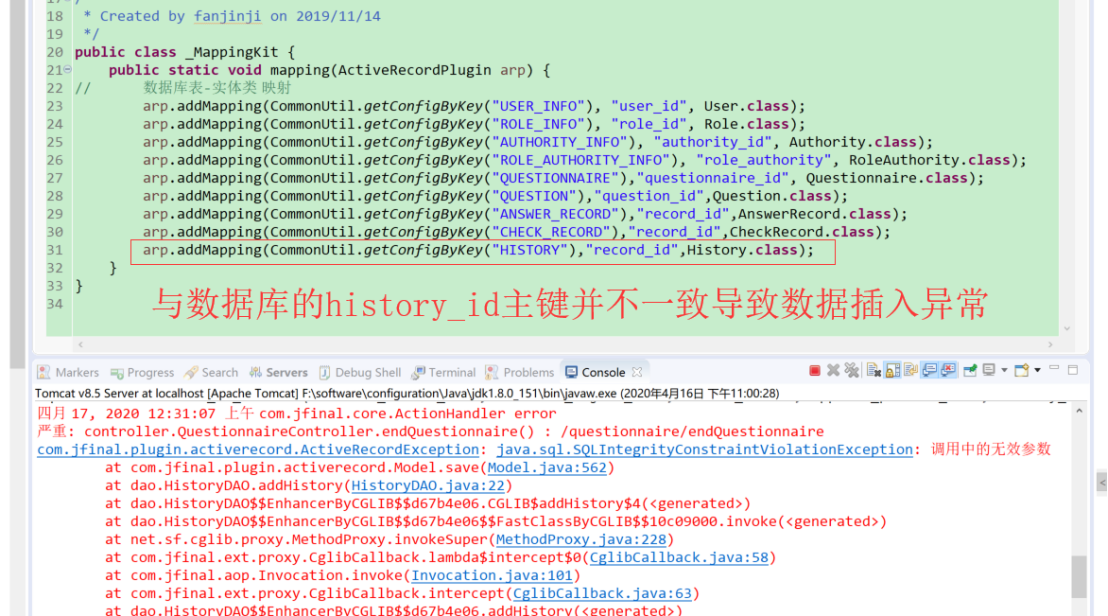
问题分析:查看save源码(针对model.save())分析上述情况在mysql和oracle中不同结果处理
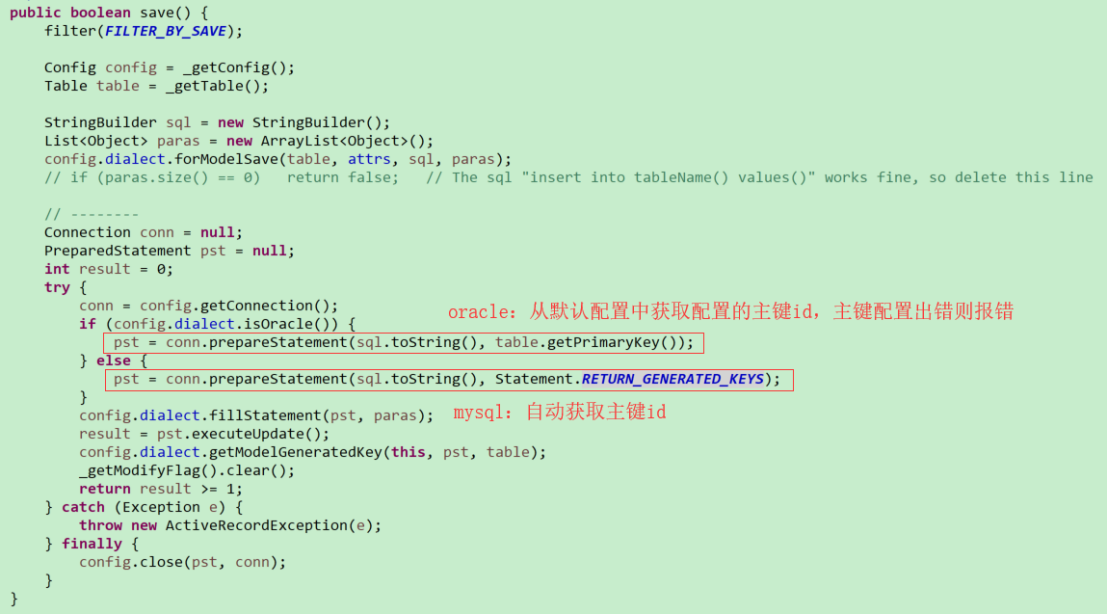


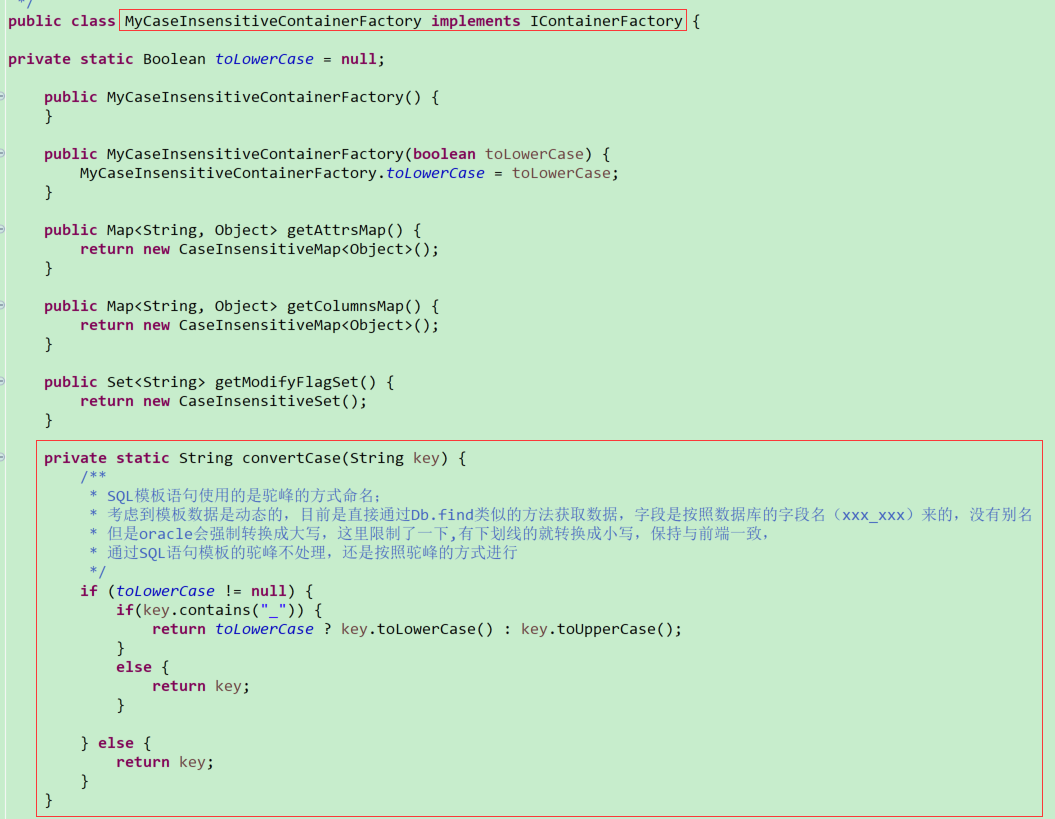
(10)Oracle的大小写问题
针对一些明确的DB操作,上述方式基本可以兼容mysql与oracle数据版本,但针对特殊需求仍然需要额外考虑。例如在CCIMS系统中有设置‘通用模板’的概念,由于一开始并没有考虑切换数据库版本的问题,和前端约定的字段均为小写的表名和字段名。在这种应用场景下如果使用oracle忽略大小写,则会导致结果对接参数出错。

参考网上的内容可以设置成小写:
arp.setContainerFactory(new CaseInsensitiveContainerFactory(false));
但是在测试的过程中会发现JFinal内部机制会将查找后的字段全部小写化,此时通过双引号的字段别名定义便毫无意义,反而造成其它接口对接出错。(主要也是在项目中没有引用JFinal的驼峰命名机制,导致代码混乱)。因此,在尽量减少逻辑代码变动的情况下,自定义规则对指定格式的字段进行转化
仿com.jfinal.plugin.activerecord.CaseInsensitiveContainerFactory类自定义实现一个MyContainerFactory类,在适当的地方将属性名转换成驼峰形式
// 设置自定义大小写规则
arp.setContainerFactory(new MyCaseInsensitiveContainerFactory(true));
参考原有的CaseInsensitiveContainerFactory实现自定义自身的转换规则: