[JAVA]-集合
[JAVA]-集合
[TOC]
集合介绍
<1>Collection与Iterator接口
🔖基本概念
为了保存数量不确定的数据以及保存具有映射关系的数据,Java提供了集合类,集合类主要是负责保存,存储其他数据,所以集合类也被称为容器类。所有的集合类都位于java.util包下,后来为了处理多线程并发的安全问题,java在jdk1.5之后提供了java.util.concurrent包提供了一些支持多线程的集合类。
集合类和数组不同,数组元素即可以是基本类型的数值,也可以是对象,而集合里只能保存对象,集合里保存的是基类型的包装类即对象。
Java的集合主要由两个接口派生而来(Collection和Map),这两个接口是根接口,这两个接口又包含了子类和实现类。
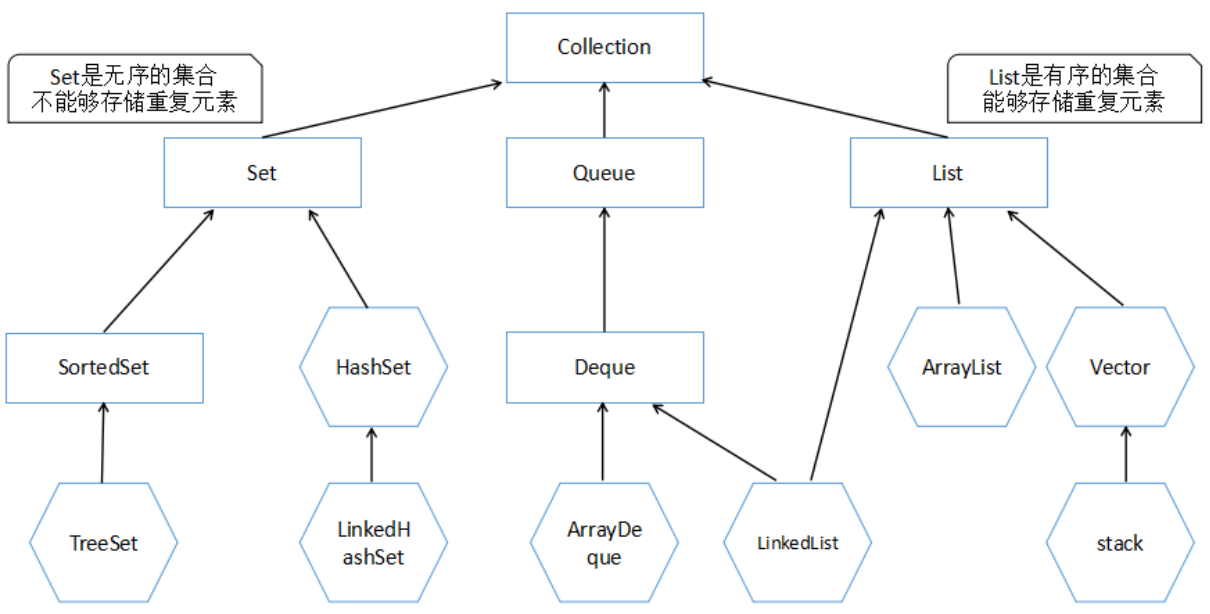
List
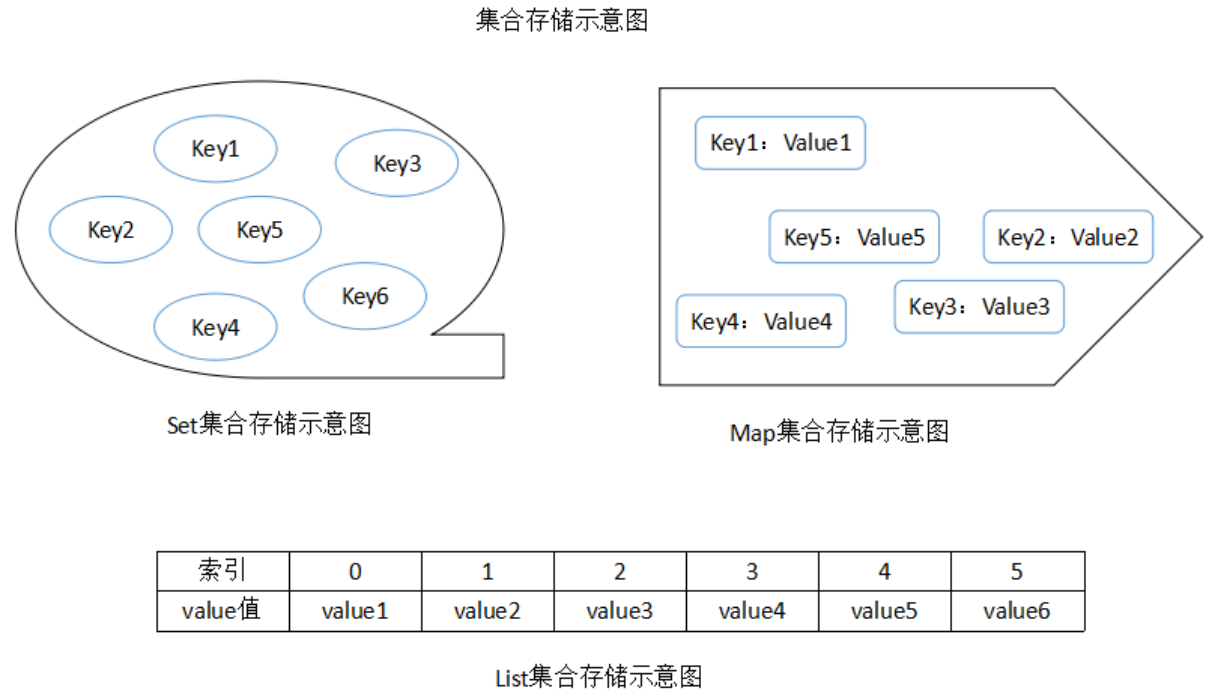
List集合是有序的集合,能够存储重复元素
- ArrayList和Vector作为List的两个实现类,功能完全相同,可以相互替代。
- Vector是一个线程安全的类,而ArrayList是线程不安全的类。
- 不推荐使用Vector,可以通过Collections工具类把ArrayList转换为线程安全的类。
各种线性表性能的分析
- Java提供了一个线性接口。而ArrayList/Vector/LinkedList都是其子类。
- ArrayList和Vector底层都是数组结构,而LinkedList集合底层是链表结构。
- Vector是线程安全的,其他两个不是线程安全的。
- 如果需要经常执行插入、删除操作改变含有大量数据的List集合的大小 可以使用LinkedList。使用ArrayList和Vector会重新分配内部数组的大小和位置,所以性能相当于LinkedList较低。
- 如果经常用到查找和修改操作 可以使用ArrayList和Vector。
Set
Set集合是无序的集合,能够存储不重复的元素
HashSet是set接口的典型实现,HashSet是按照Hash算法来存存储集合中的数据,所以具有很好的存储和查询的性能,HashSet具有以下特点:
它不保证 set 的迭代顺序;特别是它不保证该顺序恒久不变
HashSet不是同步的(不是线程安全的),如果多个线程同时访问一个HashSet,必须通过其他方式保证其同步。
集合中元素的值可以为null,但是只能有一个为null
HashSet还有一个子类LinkedHashSet, LinkedHashSet集合是根据元素的hashCode值决定元素的存储位置,通过链表维护元素次序。
TreeSet基于 TreeMap 的 NavigableSet 实现。使用元素的自然顺序对元素进行排序,或者根据创建 set 时提供的 Comparator 进行排序,具体取决于使用的构造方法。
- TreeSet自然排序:如果是基本数值类型 ,系统会自动实现排序,如果是抽象数据类型要实现比较必须实现Comparable接口,然后指定排序规则。
- 自定义排序:自定义排序是根据Treeset的构造函数进行指定,TreeSet的构造函数可以接受一个comparator的函数式接口,所有可以使用Lambda表达式进行相关的排序操作。
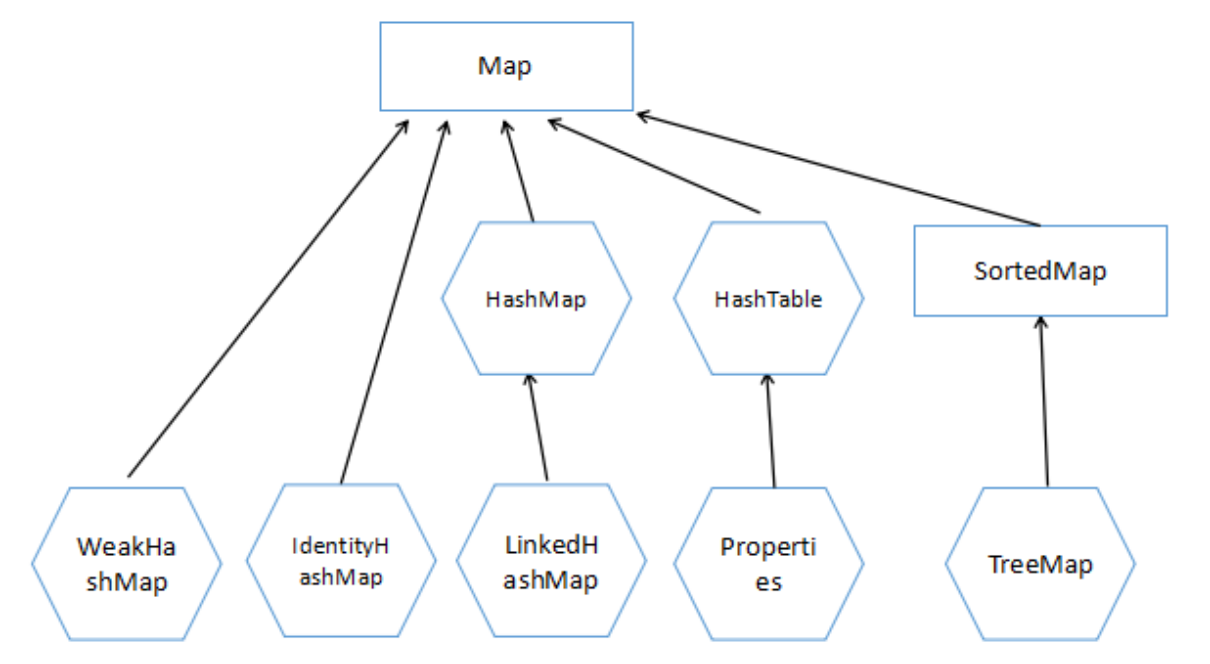
Map
Map存储具有映射关系的数据
Map用于保存具有映射关系的数据,所以map集合里保存的是一组数值,Map里以key-value的形式保存数据,其中key和value都可以是引用类型。其中Map里的key不允许出现重复,如果出现重复将会发生覆盖。
HashMap不保证迭代顺序,举例分析:
public static void main(String[] args) {
Map<String, String> map = new HashMap<>();
map.put(String.valueOf(System.currentTimeMillis()) + "a", "1");
map.put(String.valueOf(System.currentTimeMillis()) + "b", "2");
map.put(String.valueOf(System.currentTimeMillis()) + "c", "3");
map.put(String.valueOf(System.currentTimeMillis()) + "d", "4");
// 顺序是不确定的 是由于 HashMap不是按照固定位置存储 所以不保证迭代顺序
// 输出结果可能为1234/2314等......不同顺序
map.forEach((key, value) -> System.out.println(value));
}
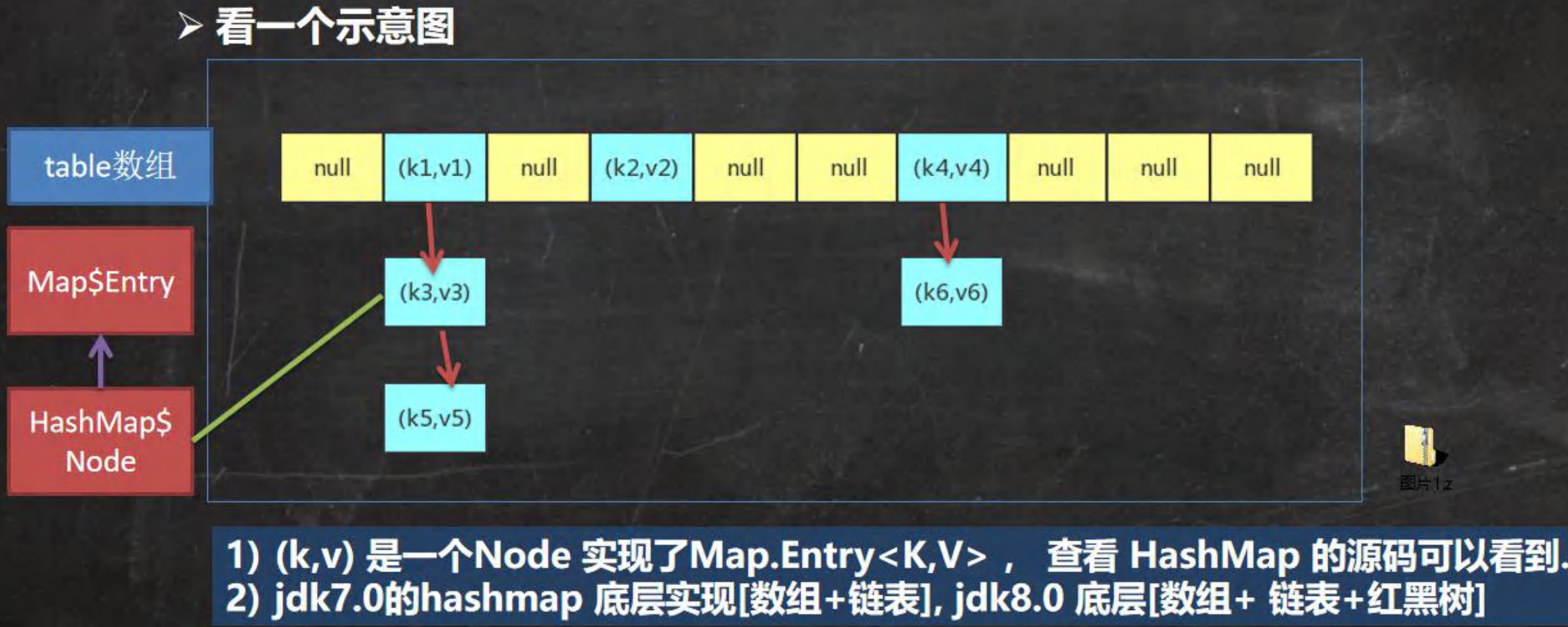
分析HashMap底层源码的实现:
HashMap和Hashtable都是map集合的子类 并且他们之间的关系和ArrayList和Vector之间的关系是相同的,两种功能基本类似,并且在没有并发的情况下可以相关替代。
Hashtable是一个线程安全的类,HashMap是线程不安全的类,所以HashMap性能比Hashtable要好一些,但是如果有多个线程访问Map使用Hashtable类会更好一些。
Hastable不允许使用Null作为key和value。而HashMap允许使用null作为key和value值。HashMap中也只能有一个key值为null,而value不限制
HashSet有一个子类LinkedHashSet,同理 HashMap下也有一个子类,这个子类是LinkedHashMap,使用双向链表维护key-value值的次序,该链表负责维护map迭代的顺序和插入的顺序是一致的。
TreeMap是根据key值进行对map集合排序
WeakHashMap:以弱键实现的基于哈希表的Map。在WeakHashMap 中,当某个键不再正常使用时,将自动移除其条目。更精确地说,对于一个给定的键,其映射的存在并不阻止垃圾回收器对该键的丢弃,这就使该键成为可终止的,被终止,然后被回收。丢弃某个键时,其条目从映射中有效地移除,因此,该类的行为与其他的 Map 实现有所不同。
IdentityHashMap:IdentityHashMap 的key值是根据对象判断是否是同一个对象,如果不是同一个对象,key值key保存相同的数据
🔖集合遍历的几种方式
无论是哪种迭代方式,在迭代的过程中均不能够对集合的大小作出修改(即不能直接在迭代过程中删除某个集合数据),否则报错
1>使用foreach语句遍历集合元素
import java.util.Collection;
import java.util.HashSet;
public class ForeachTest {
public static void main(String[] args) {
//通过foreach语句迭代集合
Collection c = new HashSet();
c.add("语文");
c.add("数学");
c.add("英语");
for(Object o : c)
{
System.out.println(o);
}
}
}
2>使用lambda表达式遍历集合
import java.util.Collection;
import java.util.HashSet;
public class LambdaTest {
public static void main(String[] args) {
//使用Lambda表达式遍历集合
Collection c = new HashSet();
c.add("语文");
c.add("数学");
c.add("英语");
//使用jdk8新增的forEach迭代集合
//c.forEach(Consumer action); Consumer是一个函数式接口,可以通过lambda表达式实现
c.forEach((obj)->{
System.out.println(obj);
});
}
}
3>使用Java8增强的Iterator遍历集合元素
import java.util.Collection;
import java.util.HashSet;
import java.util.Iterator;
public class IteratorTest {
public static void main(String[] args) {
Collection c = new HashSet();
c.add("语文");
c.add("数学");
c.add("英语");
//1、通过iterator接口简单实现集合的迭代
//把Collection集合转换为Iterator迭代器
Iterator iter = c.iterator();
//遍历迭代器中的每一个元素
while(iter.hasNext())
{
System.out.println(iter.next());
}
//2、通过java8增强的iterator,通过使用lambda表达式表示集合
//使用增强的方法forEachRemaining Consumer是一个函数式接口
iter.forEachRemaining((obj)->{
System.out.println(obj);
});
}
}
4>使用Java8新增的Predicate
通过传递的Predicate条件过滤集合,函数式接口概念
import java.util.Collection;
import java.util.HashSet;
public class PredicateTest {
public static void main(String[] args) {
Collection c = new HashSet();
c.add("语文");
c.add("数学");
c.add("英语");
c.add("数据分析与应用");
//使用Lambda表达式完成条件的过滤 :c.removeIf(Predicate filter)
//Predicate是一个函数式接口:obj指传入每个迭代的参数,箭头之后的内容用以表示具体的过滤条件
c.removeIf((obj)-> ((String)obj).length()>5 );
System.out.println(c);
}
}
通过自定义的方法完成条件的过滤
import java.util.Collection;
import java.util.HashSet;
import java.util.function.Predicate;
public class PredicateTest2 {
//通过自定义的方法完成条件的过滤
/**
* 根据传递的Predicate条件 统计 books中满足条件的内容
*
* @param books
* @param p
* @return
*/
public static int sumAll(Collection books, Predicate p) {
int total = 0;
// 循环集合中的数据,然后把集合中每个数据和条件进行匹配
for (Object obj : books) {
// 拿Predicate中的条件进行匹配,匹配成功则返回true,打印匹配的数据信息并进行统计
if (p.test(obj)) {
System.out.println(obj);
total++;
}
}
return total;
}
public static void main(String[] args) {
Collection c = new HashSet();
c.add("语文");
c.add("数学");
c.add("英语");
c.add("离散数学");
c.add("数据分析与应用");
//Predicate是函数式接口,通过lambda表达式实现
//1、筛选带有“数学”子串的数据的数量
System.out.println(PredicateTest2.sumAll(c, (obj)-> ((String)obj).contains("数学")));
//2、统计书名长度大于5的数据的数量
System.out.println(PredicateTest2.sumAll(c, (obj)-> ((String)obj).length()>5));
}
}
5>使用Java8新增的Stream
Java8新增了Stream,IntStream,LongStream,DoubleStream等流式的API这些API代表多个支持串行和并行聚集操作的元素。
独立使用Stream的步骤:
使用Stream的XxxStream的bulider方法创建Stream对应的Bulider对象
重复调用Bulider对象的add方法添加元素
调用Bulider对象的bulider方法 获取Stream
可以使用Stream中的聚集方法
参考案例1:
import java.util.Collection;
import java.util.HashSet;
import java.util.stream.IntStream;
import java.util.stream.IntStream.Builder;
public class StreamTest {
public static void main(String[] args) {
//IntStream is = IntStream.builder().add(20).add(30).add(40).add(-5).build();
Builder builder = IntStream.builder();
builder.add(20);
builder.add(30);
builder.add(40);
builder.add(-5);
IntStream is = builder.build();
//调用相应的聚集方法,但调用聚集方法的代码只能执行一次,连续执行出错
//1、求最大值max()、最小值min()
// System.out.println(is.max().getAsInt());
// System.out.println(is.min().getAsInt());
//2、求和sum()(求所有数据的总和)
// System.out.println(is.sum());
//3、统计数据的个数count()
// System.out.println(is.count());
//4、求解平均值average()
// System.out.println(is.average().getAsDouble());
//判断该Stream中是否所有的元素均大于或是小于某个值 is.allMatch(Preaicate predicate)
// System.out.println("is中所有的元素均大于10:"+is.allMatch( obj -> obj>10));
// System.out.println("is中所有的元素均大于-10:"+is.allMatch( obj -> obj>-10));
//迭代该Stream(方法引用:类名::实例方法)
// is.forEach(System.out::println);
// is.forEach(obj->System.out.println(obj));
}
}
参考案例2:
import java.util.Collection;
import java.util.HashSet;
import java.util.stream.IntStream;
public class CollectionStream {
public static void main(String[] args) {
Collection c = new HashSet();
c.add("语文");
c.add("数学");
c.add("英语");
c.add("离散数学");
c.add("数据分析与应用");
//把Collection集合通过stream方法转换为Stream对象,从而可以使用Stream中的聚集方法以及其他统计的方法
//1、筛选带有“数学”子串的数据的数量
System.out.println(c.stream().filter(obj->((String)obj).contains("数学")));
//2、统计书名长度大于5的数据的数量
System.out.println(c.stream().filter(obj->((String)obj).length()>5));
//把Collection集合转换Stream对象 然后再调用Stream对象的mapToInt方法获取原有Stream对应的IntStream
System.out.println("-----");
IntStream is=c.stream().mapToInt(ele->((String)ele).length());
is.forEach(System.out::println);
}
}
<2>Set集合
Set集合是无序的,不能存储重复元素,如果试图将两个相同的元素存储进set集合这个操作将失败。一个不包含重复元素的 collection。更确切地讲,set 不包含满足 e1.equals(e2) 的元素对 e1 和 e2,并且最多包含一个 null 元素。正如其名称所暗示的,此接口模仿了数学上的 set 抽象。
🔖HashSet
HashSet是set接口的典型实现,HashSet是按照Hash算法来存存储集合中的数据,所以具有很好的存储和查询的性能。
HashSet具有以下特点:
它不保证 set 的迭代顺序;特别是它不保证该顺序恒久不变
HashSet不是同步的(不是线程安全的),如果多个线程同时访问一个HashSet,必须通过其他方式保证其同步。
集合中元素的值可以为null,但是只能有一个为null
public class HashSetTest {
public static void main(String[] args) {
HashSet set = new HashSet();
set.add("aaa");
set.add("bbb");
set.add("ccc");
set.add("ddd");
set.add("ddd");
set.add(new String("ddd"));
System.out.println(set.size());
System.out.println(set);
/**
* 结果分析:
* 输出set集合大小为4
* 集合中存储的元素为4[aaa, ccc, bbb, ddd]
* 是由于Set集合不能存储重复的元素,虽然是通过new创建了一个
* 新的String类型的数据,但只要满足s1.equals(s2);便无
* 法重复存储相同的数据,因此此处"ddd"字符串只能存储1次
*/
}
}
/**
* 通过重写equals或者HashCode方法来进行测试,从而判断
* HashSet集合存储数据判断相等的依据是什么
*/
//1.DemoA重写equals方法但不重写HashCode方法
class DemoA{
@Override
public boolean equals(Object obj) {
return true;
}
}
//2.DemoB重写HashCode方法但不重写equals方法
class DemoB{
@Override
public int hashCode() {
return 1;
}
}
//3.DemoC重写equals和HashCode两个方法
class DemoC{
@Override
public boolean equals(Object obj) {
return true;
}
@Override
public int hashCode() {
return 2;
}
}
public class HashSetDemo {
/**
* HashSet判断两个对象是否相等的标准是通过equals
* 方法和HashCode方法共同决定的
*/
public static void main(String[] args) {
Set set = new HashSet();
set.add(new DemoA());
set.add(new DemoA());
set.add(new DemoB());
set.add(new DemoB());
set.add(new DemoC());
set.add(new DemoC());
set.forEach(System.out::println);
/**
* 结果分析:
* com.set.DemoA@7852e922
* com.set.DemoB@1
* com.set.DemoB@1
* com.set.DemoC@2
* com.set.DemoA@6d06d69c
* 由结果显示可知,DemoA、DemoB的两个对象均被装入HashSet集合中
* 而DemoC只显示一个内容,说明hashSet判断两个对象 的标准是通过
* equals和hashCode两个方法共同决定的
*/
}
}
🔖Object中的HashCode 和equals方法
/**
* 定义Person类,重写equals方法和
* hashCode方法,使得两个Person对象
* 只要满足id和name相同则视为同一个对象
* 随后用HashSet装载Person对象进行测试
*/
class Person {
private int id ;
private String name;
private int age;
public Person() {
}
public Person(int id, String name,int age) {
super();
this.id = id;
this.name = name;
this.age = age;
}
@Override
public String toString() {
return "Person [id=" + id + ", name=" + name + ", age=" + age + "]";
}
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
@Override
public int hashCode() {
/**
* 重写hashCode方法只要使得两个id和name
* 相同的对象的hashCode始终相同即可
*/
return this.id+this.name.hashCode();
}
@Override
public boolean equals(Object obj) {
/**
* 1.先判断是否指向同一个对象(引用),若个指向
* 同一个对象则直接返回true
*/
if(this==obj)
return true;
/**
* 2.其次判断两个对象的类型是否相同,如果相同则判断对应的
* id和name属性是否对应相同,如果相同则说明是同一个人,
* 此时则返回true,否则返回false
*/
// else if(obj!=null&&obj instanceof Person)
else if(obj!=null&&obj.getClass() == Person.class)
{
//先将obj强制类型转换为Person类型
Person p = (Person)obj;
if(this.getId()==(p.getId())&&this.getName().equals(p.getName()))
return true;
}
return false;
}
}
public class ObjectDemo
{
public static void main(String[] args) {
//测试:如果两个Person对象的id和name分别相同则视为同一个人
Person p1 = new Person(1,"haha",18);
Person p2 = new Person(1,"haha",19);
Person p3 = new Person(2,"xixi",20);
Person p4 = new Person(2,"haha",20);
Set<Person> set = new HashSet();
set.add(p1);
set.add(p2);
set.add(p3);
set.add(p4);
for(Person p:set)
System.out.println(p);
/**
* 显示结果分析:
* Person [id=1, name=haha, age=18]
* Person [id=2, name=haha, age=20]
* Person [id=2, name=xixi, age=20]
* 如果Person的id和name相应相等则说明是同一个人,
* 因此在HashSet中添加不会重复添加,从而可以根据需求
* 对相关的条件进行控制
*/
}
}
🔖LinkedHashSet
HashSet还有一个子类LinkedHashSet, LinkedHashSet集合是根据元素的hashCode值决定元素的存储位置,通过链表维护元素次序。
public class LinkedHashSetTest {
public static void main(String[] args) {
/**
* LinkedHashSet是一个有序的set集合,
* 可以按照存储的顺序遍历集合
*/
Set lst = new LinkedHashSet();
lst.add("aaa");
lst.add("bbb");
lst.add("ccc");
lst.add("111");
lst.add("222");
lst.add("333");
for(Object s : lst)
{
System.out.println(s);
}
}
}
🔖TreeSet
TreeSet基于 TreeMap 的 NavigableSet 实现。使用元素的自然顺序对元素进行排序,或者根据创建 set 时提供的 Comparator 进行排序,具体取决于使用的构造方法。
public class TreeSetTest {
public static void main(String[] args) {
TreeSet ts = new TreeSet();
ts.add(3);
ts.add(18);
ts.add(15);
ts.add(34);
ts.add(20);
System.out.println(ts);
//1.获取集合的第一个元素first和最后一个元素last
System.out.println("第一个元素"+ts.first());
System.out.println("最后一个元素"+ts.last());
System.out.println("1:"+ts);
//2.获取指定范围的元素
System.out.println("得到小于指定元素的最大元素"+ts.floor(25));
System.out.println("得到大于指定元素的最小元素"+ts.higher(16));
System.out.println("得到大于等于指定元素的所有元素"+ts.tailSet(15));
System.out.println("得到小于等于指定元素的所有元素"+ts.headSet(15));
System.out.println("得到满足指定范围的所有元素(包括左侧不包括右侧)"+ts.subSet(15, 20));
System.out.println("2:"+ts);
//3.移除指定的元素
/**
* 如果set为null,通过pollFirst、pollLast方法获取到的元素为null
* 如果set中不存在指定的内容,则通过remove方法移除指定元素失败返回false
*/
System.out.println("获取并移除第一个元素"+ts.pollFirst());
System.out.println("获取并移除最后一个元素"+ts.pollLast());
System.out.println("移除指定元素"+ts.remove(15));
System.out.println("3:"+ts);
//4.判断集合是否包含某个指定元素
System.out.println("判断集合是否包含某个指定元素"+ts.contains(20));
System.out.println("4:"+ts);
//5.清空集合元素
ts.clear();
System.out.println("5:"+ts);
}
}
1>TreeSet自然排序
如果是基本数值类型 ,系统会自动实现排序,如果是抽象数据类型要实现比较必须实现Comparable接口,然后指定排序规则。
public class User implements Comparable{
/**
* 基本的数据类型系统会自动进行排序
* 如果是抽象数据类型,则需要通过实现Comparable接口
* 并且按照自定义的内容重写compareTo方法,由此实现排序
*/
private int id;
private String name;
private int age;
public User(int id, String name, int age) {
super();
this.id = id;
this.name = name;
this.age = age;
}
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
@Override
public String toString() {
return "User [id=" + id + ", name=" + name + ", age=" + age + "]";
}
@Override
public int compareTo(Object o) {
/**
* 此处简单实现初步按照id号进行排序,如果id相同则利用
* 年龄age进行排序,分别返回负整数、0、正整数
*/
User user = (User)o;
if(this.getId()>user.getId())
return 1;
else if(this.getId()==user.getId())
{
/**
* if(this.getAge()>user.getAge())
* return 1;
* else if(this.getAge()==user.getAge())
* return 0;
* else if(this.getAge()<user.getAge())
* return -1;
*/
//上述语句可以用下述条件表达式代替
return this.getAge() > user.getAge() ? 1 : this.getAge() < user.getAge() ? -1 : 0;
}
else if(this.getId()<user.getId())
return -1;
return 0;
}
public static void main(String[] args) {
//测试
User u1 = new User(1,"haha",18);
User u2 = new User(3,"haha",20);
User u3 = new User(2,"haha",18);
User u4 = new User(3,"haha",18);
TreeSet ts = new TreeSet();
ts.add(u1);
ts.add(u2);
ts.add(u3);
ts.add(u4);
ts.forEach(System.out::println);
/**
* 输出结果:
* User [id=1, name=haha, age=18]
* User [id=2, name=haha, age=18]
* User [id=3, name=haha, age=18]
* User [id=3, name=haha, age=20]
*/
}
}
2>自定义排序
自定义排序是根据Treeset的构造函数进行指定,TreeSet的构造函数可以接受一个comparator的函数式接口,所有可以使用Lambda表达式进行相关的排序操作。
public class TreeSetSort {
/**
* 实现TreeSet的自定义排序,可以通过TreeSet的构造函数实现
* 该构造函数可以接收一个Comparator函数式接口,因此可以考虑
* 用相应的Lambda表达式实现即可
*/
public static void main(String[] args) {
TreeSet ts = new TreeSet((o1,o2)->{
Integer a = (Integer)o1;
Integer b = (Integer)o2;
int temp = a-b;
return temp==0?0:temp;
});
ts.add(15);
ts.add(8);
ts.add(10);
ts.add(20);
ts.add(3);
System.out.println(ts);
}
}
3>自然排序VS自定义排序
从实现上说明
- 自然排序:自定义类实现Comparable接口,重写compareTo方法,根据返回值进行排序
- 比较器排序(自定义排序): 创建TreeSet对象的时候传递Comparator的实现类对象,重写compare方法,根据返回值进行排序
返回值规则
- 如果返回值为负数,表示当前存入的元素是较小值,存左边
- 如果返回值为0,表示当前存入的元素跟集合中元素重复了,不存
- 如果返回值为正数,表示当前存入的元素是较大值,存右边
<3>List集合
有序的 collection(也称为序列)。此接口的用户可以对列表中每个元素的插入位置进行精确地控制。用户可以根据元素的整数索引(在列表中的位置)访问元素,并搜索列表中的元素。
🔖ArrayList基础用法
public class ArrayListTest {
public static void main(String[] args) {
ArrayList al = new ArrayList();
//1.添加指定的元素(任意类型)
al.add("语文");
al.add(123);
al.add(13.0);
al.add(true);
al.add(123);
al.add("haha");
//2.判断集合中是否包括指定元素,如果存在则返回true,反之返回false
System.out.println(al.contains("haha"));
System.out.println(al.contains(0));
//3.返回列表中指定位置的元素
System.out.println(al.get(0));
//4.返回列表中第一次出现指定元素的位置,如果不包含该元素则返回-1
System.out.println(al.indexOf(123));
System.out.println(al.indexOf("xixi"));
//5.返回列表中最后出现指定元素的位置,如果不包含该元素则返回-1
System.out.println(al.lastIndexOf(123));
System.out.println(al.lastIndexOf("xixi"));
//6.移除指定的元素或者是指定位置的元素
System.out.println(al.remove(2));
System.out.println(al.remove(13.0));
//7.替换指定位置的元素
System.out.println(al.set(0, "java"));
//8.得到列表中的元素个数
System.out.println(al.size());
//9.截取指定范围的列表元素(包括左边不包括右边)
System.out.println(al.subList(0, 3));
//10.将列表元素一一对应到数组中
System.out.println(al.toArray());
for(Object o:al.toArray())
System.out.print(o+"--");
}
}
ArrayList判断对象相等
List集合中比较两个对象是否相等是根据equals的返回值是true还是false决定的。
//类DemoA重写equals方法,直接返回true
class DemoA
{
@Override
public boolean equals(Object obj) {
return true;
}
}
public class ArrayListDemo {
/**
* List集合中比较两个对象是否相等是通过equals方法
* 返回的值是true还是false决定的
*/
public static void main(String[] args) {
List books = new ArrayList();
books.add(new String("java入门基础"));
books.add(new String("Hibernate入门基础"));
books.add("数据库入门基础");
books.add(new String("java入门基础"));
System.out.println(books);
books.remove(new DemoA());
System.out.println(books);
books.remove(new DemoA());
System.out.println(books);
/**
* 结果分析:
* 通过remove方法移除的是DemoA对象,但显然DemoA对象并不存在于列表中
* remove方法是删除指定对象,其删除的过程是将指定的对象和列表集合中每个元素
* 一一进行比较,比较的时候使用的是equals方法,如果返回true则说明存在该元素,
* 便移除该元素。
* 但是由于此处通过DemoA类重写了equals方法,使得它无论如何都返回true,因此
* 当使用remove方法进行比较的时候始终有指定对象DemoA与第一个元素相比返回true,
* 则系统默认是存在该指定元素,则会删除第一个元素,以此类推,下述再进行分析即可
* 最终结果展示:
* [java入门基础, Hibernate入门基础, 数据库入门基础, java入门基础]
* [Hibernate入门基础, 数据库入门基础, java入门基础]
* [数据库入门基础, java入门基础]
* 通过类DemoA重写了equals方法,使得列表中的每个元素始终是与DemoA对象相同,
* 从而使得删除的始终为第一个与指定元素相同的对象,即始终删除的是列表的第1个元素
*/
}
}
🔖Java8为List新增的方法
public class ListDemo {
/**
* Java8 为List集合新增了sort()和replaceAll这两个默认方法
* sort需要 Comparator接口 这个接口也是一个函数式接口
* replaceAll需要UnaryOperator接口 也是一个函数式接口
* 因此可以通过Lambda表达式实现
*/
public static void main(String[] args) {
List books =new ArrayList();
books.add(new String("Spring入门基础"));
books.add(new String("Hibernate入门基础"));
books.add(new String("Struts2入门基础"));
books.add(new String("MyBatis入门基础"));
books.add(new String("MyBatis入门基础"));
/**
* 1.sort方法:通过重写Comparator中的compare(T o1, T o2)
* 方法,根据指定的方式实现列表元素的排序
* 此处根据集合的数据长度进行排序
*/
books.sort((o1,o2)->{
return ((String)o1).length()-((String)o2).length();
});
System.out.println(books);
/**
* 2.replaceAll方法:替换目标中所有内容
* 可以根据指定的内容实现替换
* 此处将集合中的元素替换为相应元素的长度
*/
books.replaceAll((ele)->{
return ((String)ele).length();
});
System.out.println(books);
}
}
🔖List集合中特有的方法
public class ListDemo2 {
public static void main(String[] args) {
//1.通过for语句可以将数组直接转化为List集合
String[] books = {"语文","数学","英语","物理","化学","生物"};
List list = new ArrayList();
for(String s : books)
{
list.add(s);
}
//2.通过迭代器ListIterator、Iterator对集合元素进行迭代
ListIterator lit = list.listIterator();
while(lit.hasNext())
{
System.out.println(lit.next());
}
System.out.println("----------------");
//使用ListIterator迭代器还可以对集合元素进行反转迭代
while(lit.hasPrevious())
{
System.out.println(lit.previous());
}
System.out.println("----------------");
Iterator iter = list.iterator();
while(iter.hasNext())
{
System.out.println(iter.next());
}
}
}
🔖实现自定义MyArrayList
public class MyArrayList {
/**
* 参考ArrayList的源码,自己实现一个MyArrayList
* 仿写相关的方法
* 其底层实现是数组,因此可以借助数组的相关概念进行操作
*/
private Object[] data = new Object[5];//用于存放数据,初始化大小为5
private int size = 0;//初始化集合大小为0
/**
* 1.add方法的实现
* 首先要进行判断,判断数组是否越界,即判断当前集合的大小
* 是否大于底层数组的大小,如果小于则可直接进行添加
* 反之,则需要对数组进行扩容(扩容大小自行指定,此处扩为
* 原来的两倍)
* 可以直接在判断的时候根据需求对数组进行扩容,从而可以简化代码
*/
public void add(Object o)
{
ensureCapacity();
this.data[size++] = o;
}
private void ensureCapacity()
{
Object[] newData = new Object[this.data.length*2];
if(this.size>=this.data.length)
{
for(int i=0;i<this.size;i++)
newData[i] = this.data[i];
this.data = newData;
}
}
/*
* public void add(Object o)
{
//进行判断
boolean flag = ensureCapacity();
if(flag)
data[size++] = o;
else
{
//进行扩容
expandCapacity();
data[size++] = o;
}
}
private void expandCapacity() {
Object[] newData = new Object[this.data.length*2];
for(int i=0;i<this.data.length;i++)
{
newData[i] = this.data[i];
}
this.data = newData;
}
private boolean ensureCapacity() {
if(this.size<data.length)
return true;
else
return false;
}
*/
/**
* 2.size方法的实现
* 判断当前列表元素的个数(列表的大小)
*/
public int size()
{
return this.size;
}
/**
* 3.set、get方法的实现
* set(int index,Object o):用元素o替换指定index位置上的元素
* get(int index):获取指定位置上的元素
* 通过数组下标访问指定位置的元素
*/
public Object set(int index,Object o)
{
this.data[index] = o;
return this.data[index];
}
public Object get(int index)
{
return this.data[index];
}
/**
* 4.indexOf、lastIndexOf方法的实现
* indexOf:返回列表中第一次出现指定元素的位置,查找失败则返回-1
* 通过遍历查找数据,如果存在指定元素则返回当前位置(下标值),否则返回-1
*
* lastIndexOf:返回列表中最后一次出现指定元素的位置,查找失败则返回-1
* 通过反向遍历查找数据,如果存在指定元素则返回当前位置,否则返回-1
*/
public int indexOf(Object o)
{
for(int i=0;i<this.size;i++)
if(o.equals(this.data[i]))
return i;
return -1;
}
public int lastIndexOf(Object o)
{
for(int i=this.size-1;i>=0;i--)
if(o.equals(this.data[i]))
return i;
return -1;
}
/**
* 5.contains方法的实现
* 如果列表中存在指定的元素,则返回true,反之则返回false
* 通过查找遍历数组,如果数组中存在指定的元素则返回true,反之返回false
*/
public boolean contains(Object o)
{
for(Object obj : this.data)
if(o.equals(obj))
return true;
return false;
}
/**
* 6.isEmpty方法的实现
* 如果列表中没有元素则返回true,反之返回false
* 通过判断size是否为0即可
*/
public boolean isEmpty()
{
return this.size == 0;
}
/**
* 7.remove方法的实现
* remove(int index):获取并移除指定位置的元素
* remove(Object o):移除首次出现的指定的元素
* 先创建一个新的数组(新数组的大小与this.data的大小相同),随后
* 通过查找指定位置或指定元素,如果满足条件则不将该元素放入新数组中,
* 最终将除指定的元素之外的所有元素迁移到新的数组中,并让
* this.data指向当前的新数组即可
* 对于size的处理也可以用一个新的变量记录个数
*
* removeRange(int from,int to):移除指定范围的列表元素
* 通过创建新的数组(新数组的大小与this.data的大小相同),如果
* 数组位置满足(fromIndex,toIndex)(包括左侧不包括右侧)
* 范围的话则不放入新数组,最终让this.data指向新数组
*
* 对于size的变化,需要手动处理(减1)
*/
public Object remove(int index)
{
//移除指定下标的数据必然不能超过列表大小,此处不需要判断
Object[] newData = new Object[this.data.length];
int count = 0;//定义记录新数组的大小的变量,初始化为0
Object find = this.data[index];//定义记录查找到的数据
for(int i = 0;i<this.size;i++)
{
if(i!=index)
{
newData[count++] = this.data[i];
}
}
this.size--;
this.data = newData;
return find;//返回之前的数据
}
public boolean remove(Object o)
{
//移除指定的元素需要通过遍历查找,查找并移除成功则返回true,反之返回false
Object[] newData = new Object[this.data.length];
int count = 0;//定义记录新数组的大小的变量,初始化为0
boolean flag = false;//定义查找的标志,查找成功返回true,反之返回false
for(int i=0;i<this.size;i++)
{
if(!this.data[i].equals(o))
newData[count++] = this.data[i];
else
flag = true;
}
this.size--;
this.data = newData;
return flag;
}
public void removeRange(int from,int to)
{
//移除指定范围的元素
Object[] newData = new Object[this.data.length];
int count = 0;//定义用于记录新数组大小的变量,初始化为0
for(int i=0;i<this.size;i++)
{
if(!(i>=from&&i<to))
newData[count++] = this.data[i];
}
this.size -= (to-from);
this.data = newData;
}
/**
* 8.toArray方法的实现
* toArray():将列表中的元素转化成数组元素
* 由于底层是数组的实现,直接返回当前数组即可
*/
public Object[] toArray()
{
return this.data;
}
/**
* 9.clear方法的实现
* clear():将列表元素清空
* 创建一个新的数组(与this.data数组大小相同),让this.data
* 指向这个新的空数组,并使得size置为0
*/
public void clear()
{
Object[] newData = new Object[this.data.length];
this.data = newData;
this.size = 0;
}
/**
* 重写toString方法实现数据打印
*/
@Override
public String toString() {
StringBuilder sb = new StringBuilder();
for(int i=0;i<this.size;i++)
{
sb.append(this.data[i]+"--");
}
return sb.toString();
}
}
public class MyArrayListTest {
public static void main(String[] args) {
//测试自行实现的MyArrayList
MyArrayList mlt = new MyArrayList();
mlt.add("语文");
mlt.add("数学");
mlt.add("英语");
mlt.add("物理");
mlt.add("化学");
mlt.add("生物");
mlt.add("数学");
System.out.println(mlt);
System.out.println("当前列表元素大小:"+mlt.size());
System.out.println("set方法测试:"+mlt.set(5, "java"));
System.out.println("get方法测试:"+mlt.get(5));
System.out.println(mlt);
System.out.println("indexOf方法测试:"+mlt.indexOf("java"));
System.out.println("indexOf方法测试:"+mlt.indexOf("gogo"));
System.out.println(mlt);
System.out.println("lastIndexOf方法测试:"+mlt.lastIndexOf("数学"));
System.out.println("lastIndexOf方法测试:"+mlt.lastIndexOf("gogo"));
System.out.println(mlt);
System.out.println("contains方法测试:"+mlt.contains("java"));
System.out.println("contains方法测试:"+mlt.contains("gogo"));
System.out.println(mlt);
System.out.println("isEmpty方法测试:"+mlt.isEmpty());
System.out.println("remove方法测试:"+mlt.remove(5));
System.out.println("remove方法测试:"+mlt.remove("gogo"));
mlt.removeRange(3, 5);
System.out.println("removeRange方法测试"+mlt);
System.out.println("toArray方法测试:"+mlt.toArray());
for(Object o : mlt.toArray())
{
System.out.print(o+"--");
}
System.out.println("\ntoString方法测试:"+mlt.toString());
}
}
🔖LinkedList
public class LinkedListTest {
public static void main(String[] args) {
LinkedList list = new LinkedList();
list.add("aaa");
list.add("bbb");
list.add("ccc");
list.add("ddd");
list.add("eee");
/**
* 1.从指定位置插入数据
* addFirst:将指定元素插入列表开头
* addLast:将指定元素插入列表尾部
* offerFirst:在此列表的开头插入指定的元素。
* offerLast:在此列表末尾插入指定的元素。
*/
list.addFirst("java");
list.addLast("数据库");
list.offerFirst("haha");
list.offerLast("bibi");
/**
* 2.获取指定位置的元素
* element:获取列表的第一个元素但不移除
* get:获取列表指定位置的元素
* getFirst:获取列表的第一个元素
* getLast:获取列表的最后一个元素
*/
System.out.println(list.element());
System.out.println(list.get(3));
System.out.println(list.getFirst());
System.out.println(list.getLast());
/**
* 3.peek、poll
* peek():获取但不移除列表的头(第一个元素)
* peekFirst():获取但不移除列表的第一个元素,如果列表为空则返回 null
* peekLast():获取但不移除列表的最后一个元素,如果列表为空则返回 null
* poll():获取并移除列表的头(第一个元素)
* pollFirst():获取并移除列表的第一个元素,如果列表为空则返回 null
* pollLast():获取并移除列表的最后一个元素,如果列表为空则返回 null
*/
System.out.println(list.peek());
System.out.println(list.peekFirst());
System.out.println(list.peekLast());
System.out.println(list);
System.out.println(list.poll());
System.out.println(list.pollFirst());
System.out.println(list.pollLast());
System.out.println(list);
/**
* 3.移除指定要求的元素
* remove():获取并移除列表的头(第一个元素)
* remove(int index): 移除列表中指定位置处的元素
* remove(Object o):从列表中移除首次出现的指定元素(如果存在则移除并返回true)
* removeFirst():移除并返回列表的第一个元素
* removeFirstOccurrence(Object o):从列表中移除第一次出现的指定元素
* removeLast():移除并返回列表的最后一个元素
* removeLastOccurrence(Object o):从列表中移除最后一次出现的指定元素
*/
System.out.println(list.remove());
System.out.println(list);
/**
* 4.将列表转化为数组
*/
Object[] obj = list.toArray();
for(Object o:obj)
{
System.out.print(o+"--");
}
}
}
🔖各种线性表的性能的分析
Java提供了一个线性接口。而ArrayList/Vector/LinkedList都是其子类。
ArrayList和Vector底层都是数组结构,而LinkedList集合底层是链表结构。
Vector是线程安全的 其他两个不是线程安全的。
如果需要经常执行插入、删除操作改变含有大量数据的List集合的大小 可以使用LinkedList。使用ArrayList和Vector会重新分配内部数组的大小和位置,所以性能相当于LinkedList较低。
如果经常用到查找和修改操作 可以使用ArrayList和Vector。
ArrayList和Vector作为List的两个实现类,功能完全相同,可以相互替代。Vector是一个线程安全的类,而ArrayList是线程不安全的类。什么时候都不推荐使用Vector。可以通过Collections工具类把ArrayList转换为线程安全的类。
Vector list =new Vector();
list.add(new String("Spring入门基础"));
list.add(new String("Hibernate入门基础"));
list.add(new String("Struts2入门基础"));
list.add(new String("MyBatis入门基础"));
list.add(new String("MyBatis入门基础"));
System.out.println(list);
list.add(1, new String("Redis基础入门"));
System.out.println(list);
<4>Map集合
Map用于保存具有映射关系的数据,所以map集合里保存的是一组数值,Map里以key-value的形式保存数据,其中key和value都可以是引用类型。其中Map里的key不允许出现重复,如果出现重复将会发生覆盖。
🔖Map基础用法
1>HashMap的基础用法
public class HashMapTest {
public static void main(String[] args) {
//HashMap不保证迭代的顺序,尤其是不保证该迭代顺序恒定不变
Map map = new HashMap();
map.put("语文", 60);
map.put("数学", 99);
map.put("英语", 88);
map.put("物理", 70);
map.put("化学", 60);
//1.添加数据时如果key值重复,相应的value值会发生覆盖
map.put("数学", 100);
//2.判断是否包含指定的Key值或者是Value值
System.out.println(map.containsKey("生物"));
System.out.println(map.containsValue(100));
//3.根据指定的Key值获取相应的Value值
System.out.println(map.get("数学"));
//4.移除指定的Key对应的映射关系(如果存在的话则移除,否则移除无效)
//如果是通过指定的Key或者Value进行移除则必须一一对应,否则移除无效
System.out.println(map.remove("语文"));
System.out.println(map.remove("英语",99));
//5.获取当前map集合的元素个数(即得到集合大小)
System.out.println(map.size());
//6.清空map集合中所有的映射关系
map.clear();
//7.判断集合是否为空
System.out.println(map.isEmpty());
}
}
2>迭代map集合
public class HashMapDemo {
/**
* 三种方式对map集合进行遍历(迭代)
* 1.使用KeySet方法返回包含的键的Set视图,
* 随后通过get方法得到对应的value
* 2.使用entrySet返回映射关系的视图,
* 随后通过iterator迭代器对数据进行迭代
* 3.使用java8新增的特性,forEach循环遍历实现数据的迭代
*/
public static void main(String[] args) {
Map map = new HashMap();
map.put("语文", 60);
map.put("数学", 99);
map.put("英语", 88);
map.put("物理", 70);
map.put("化学", 60);
//1.KeySet方法
Set set = map.keySet();
Iterator iter = set.iterator();
iter.forEachRemaining((obj)->System.out.println(obj+"--"+map.get(obj)));
//2.entrySet方法
Set<Map.Entry<String, Integer>> enset = map.entrySet();
Iterator<Map.Entry<String, Integer>> iter2 = enset.iterator();
while(iter2.hasNext())
{
//取出的是一个映射关系,需要进行拆分
Map.Entry<String, Integer> m = iter2.next();
String key = m.getKey();
Integer value = m.getValue();
System.out.println("key:"+key+"--value:"+value);
}
//3.java8新增的forEach方法
map.forEach((key,value)->System.out.println(key+"--"+value));
}
}
案例分析:
public class MapTest {
public static void main(String[] args) {
Map<String, String> map = new HashMap<>();
map.put(String.valueOf(System.currentTimeMillis()) + "a", "1");
map.put(String.valueOf(System.currentTimeMillis()) + "b", "2");
map.put(String.valueOf(System.currentTimeMillis()) + "c", "3");
map.put(String.valueOf(System.currentTimeMillis()) + "d", "4");
/**
* 遍历上述map集合得到的结果顺序是不确定的,是由于 HashMap并不是
* 按照固定位置存储,所以不保证其迭代顺序,且每次迭代的结果均有所不同
*/
map.forEach((key, value) -> System.out.println(value));
}
}
3>Java8为Map新增的方法
public class MapNewTest {
public static void main(String[] args) {
Map map = new HashMap();
//1.put方法:向集合中存储数据
map.put("语文", 60);
map.put("数学", 99);
map.put("英语", 88);
map.put("物理", 70);
map.put("化学", 60);
//2.replace方法:替换指定key值对应的value值
map.replace("数学", 50);
System.out.println(map);
/**
* 3.merger方法:可以实现用原来的value值参与相关运算得出的结果进行替换
* 此处第一个参数是key值,第二个参数是param(需要参与运算的值),第三个参数
* 则通过Lambda表达式实现原来的的value值与param进行运算的结果作为新的
* value值存入集合中
* 但如果指定的key值不存在,则将key与相应的value作为新的映射关系存储到map集合中
*/
map.merge("haha", 20, (oldValue,param)->(Integer)oldValue+(Integer)param);
System.out.println(map);
/**
* 4.替换或创建
* computerIfAbsent:如果指定的key值不存在或者为null时,使用后方的Lambda
* 表达式计算的结果作为该key值的value存储为新的映射关系
* computerIfPresent:如果指定的key值存在,则使用后方的Lambda表达式计算的
* 结果作为新的value覆盖之前的value值
*/
map.computeIfAbsent("haha", (key)->((String)key).length());
map.computeIfPresent("数学", (key,value)->(Integer)value * (Integer)value);
System.out.println(map);
}
}
4>LinkedHashMap
HashSet有一个子类LinkedHashSet,同理 HashMap下也有一个子类,这个子类是LinkedHashMap,使用双向链表维护key-value值的次序,该链表负责维护map迭代的顺序和插入的顺序是一致的
public class LinkedHashMapTest {
public static void main(String[] args) {
/**
* HashMap下有一个子类为LinkedHashMap,其是使用双向链表维护
* key-value值的次序,该链表负责维护map迭代的顺序和插入的顺序
* 是一致的
*/
LinkedHashMap lhm = new LinkedHashMap();
lhm.put("语文", 60);
lhm.put("数学", 80);
lhm.put("英语", 70);
lhm.put("物理", 60);
lhm.put("化学", 90);
lhm.put("生物", 50);
lhm.forEach((key,value)->System.out.println(key+"--"+value));
/**
* 由输出结果显示,LinkedHsahMap的迭代次序与插入数据的顺序始终保持一致
*/
}
}
🔖HashMap与HashTeble
1>Java8改进的HashMap和Hashtable
分析HashMap底层源码的实现:
HashMap和Hashtable都是map集合的子类 并且他们之间的关系和ArrayList和Vector之间的关系是相同的,两种功能基本类似,并且在没有并发的情况下可以相关替代。 区别如下:
Hashtable是一个线程安全的类,HashMap是线程不安全的类,所以HashMap性能比Hashtable要好一些,但是如果有多个线程访问Map使用Hashtable类会更好一些。
Hastable不允许使用Null作为key和value。而HashMap允许使用null作为key和value值。HashMap中也只能有一个key值为null,而value不限制
public class HashMapTableDemo {
public static void main(String[] args) {
/**
* HashMap与Hashtable的区别
* 1.HashMap是线程不安全的,Hashtable是线程安全的
* HashMap的性能较好,但如果涉及多个线程访问Map则使用Hashtable较好
* 2.HashMap允许null作为key或者是value值,但只能有一个key值为null,对value不作限制
* Hashtable不允许null作为key或者是value值
*/
//1.Hashtable不允许key或者value值为null
Hashtable ht = new Hashtable();
// ht.put(null, null);
// ht.put(null, 0);
// ht.put(0, null);
/**
* 2.HashMap允许null作为key或者是value值
* 但只能有一个key值为null,对value则不作限制
*/
HashMap hm = new HashMap();
hm.put(null, null);
hm.put(null, 1);//发生value值的覆盖
hm.put("haha", null);
hm.put("xixi", null);
System.out.println(hm);
}
}
2>Properties
Properties类继承Hashtable并实现了Map接口,以键值对的形式保存数据。可用于配置文件(xxx.properties)读取、修改
public class PropertiesTest {
public static void main(String[] args) throws Exception {
Properties prop = new Properties();
//1.向Properties中添加相关的属性信息
prop.setProperty("username", "noob");
prop.setProperty("password", "123456");
prop.setProperty("money", "1000");
//2.将属性固化到一个文件当中(之后常用Properties配置文件的相关属性)
prop.store(new FileOutputStream("d://test.ini"), "PropertiesTest");
/**
* 结果分析:
* 运行之后在指定的目录打开相应的文件,显示如下信息
* #PropertiesTest
* #Wed Mar 28 11:56:41 CST 2018
* password=123456
* money=1000
* username=noob
*/
}
}
public class PropertiesDemo {
public static void main(String[] args) throws Exception {
//读取相应配置文件保存的信息
Properties prop = new Properties();
//load方法实现文件信息读取(从指定的文件中加载流)
prop.load(new FileInputStream("d://test.ini"));
System.out.println(prop);
/**
* 结果分析:
* 从指定的文件中读取文件的相关属性,显示如下信息
* {password=123456, money=1000, username=xx}
*/
}
}
🔖TreeMap
public class TreeMapTest {
public static void main(String[] args) {
//TreeMap是通过key值的自然顺序完成集合元素的排序
TreeMap tm = new TreeMap();
tm.put(60, "语文");
tm.put(70, "化学");
tm.put(80, "数学");
tm.put(90, "物理");
tm.put(55, "英语");
tm.put(88, "生物");
tm.forEach((key,value)->{System.out.println(key+"*--*"+value);});
/**
* 1.取出指定的元素(按照key值的自然顺序排序后的元素)
* firstKey():得到集合的第一个key值
* firstEntry():得到集合的第一个映射关系
* lastKey():得到集合的最后一个key值
* lastEntry():得到集合的最后一个映射关系
*/
System.out.println(tm.firstKey());
System.out.println(tm.firstEntry());
System.out.println(tm.lastKey());
System.out.println(tm.lastEntry());
/**
* 2.得到满足指定条件的数据
* lowerKey():返回小于给定key值的最大的key值
* higherKey():返回大于给定key值的最小的key值
*/
System.out.println(tm.lowerKey(80));
System.out.println(tm.higherKey(50));
/**
* 3.截取集合中满足条件的部分数据
* subMap(from,to);包括左侧而不包括右侧
*/
System.out.println(tm.subMap(70, 90));
}
}
🔖WeakHashMap
WeakHashMap是以弱键实现的基于哈希表的Map。在 WeakHashMap 中,当某个键不再正常使用时,将自动移除其条目。更精确地说,对于一个给定的键,其映射的存在并不阻止垃圾回收器对该键的丢弃,这就使该键成为可终止的,被终止,然后被回收。丢弃某个键时,其条目从映射中有效地移除,因此,该类的行为与其他的 Map 实现有所不同。
public class WeakHashMapTest {
public static void main(String[] args) {
/**
* WeahHashMap存储的数据 如果是弱引用,
* 那么在执行垃圾回收的时候将把这个对象进行回收
* WeahHashMap迭代的次序也不能确定
*/
WeakHashMap whm = new WeakHashMap();
whm.put(new String("Java"), new String("优秀"));
whm.put(new String("Oracle数据库"), new String("良好"));
whm.put(new String("数据结构与分析"), new String("中等"));
whm.put("算法分析与设计", "及格");
whm.forEach((key,value)->System.out.println(key+"*--*"+value));
//通知系统进行垃圾回收
System.gc();
System.runFinalization();
System.out.println("垃圾回收后.....");
whm.forEach((key,value)->System.out.println(key+"*--*"+value));
/**
* 结果分析:
* 通过new关键字创建出来的字符串(在堆内存中)被垃圾回收了,
* 垃圾回收会对堆内存中的没有被引用的数据进行回收,因此集合中
* 只剩下常量池中的相关数据,其余均被垃圾回收回收了
* 结果显示:
* 数据结构与分析*--*中等
* 算法分析与设计*--*及格
* Oracle数据库*--*良好
* Java*--*优秀
* 垃圾回收后.....
* 算法分析与设计*--*及格
*/
}
}
🔖IdentityHashMap
public class IdentityHashMapTest {
public static void main(String[] args) {
/**
* IdentityHashMap的key值是根据判断是否是同一个对象
* 如果不是同一个对象 key值则key保存相同的数据
*/
IdentityHashMap ihm = new IdentityHashMap();
ihm.put(new String("java"), 100);
ihm.put(new String("java"), 100);
ihm.put("haha", "123456");
ihm.put("haha", "000000");
System.out.println(ihm);
/**
* 结果分析:
* key值为“java”是通过new关键字创建了不同的字符串对象,因此可以认为key不同
* 从而可以允许存储相同的数据,而key值为“haha”均为字符串常量,均为指向常量池的
* 同一个字符串对象,因此是属于同一个对象,如果继续添加指定的内容,则value值会被覆盖
* 结果显示:
* {java=100, haha=000000, java=100}
*/
}
}
集合扩展
<1>工具类Collections和Arrays
Java提供了一个操作set 、list、map 等集合的工具类,Collection工具类提供了大量的方法 对集合完成排序,查询,修改等操作。
🔖Collections工具类
1>排序操作
public class CollectionsSortTest {
public static void main(String[] args) {
ArrayList al = new ArrayList();
al.add(2);
al.add(18);
al.add(32);
al.add(25);
al.add(15);
al.add(8);
//1.使用Collections类提供的sort方法对集合进行排序
Collections.sort(al);
System.out.println(al);
//2.使用Collections类提供的reverse方法对集合进行反转
Collections.reverse(al);
System.out.println(al);
//3.使用Collections类提供的shuffle方法对集合进行随机排序
Collections.shuffle(al);
//随机排序每次的排序结果均不尽相同
System.out.println(al);
}
}
2>查找替换操作
public class CollectionsSearchTest {
public static void main(String[] args) {
ArrayList al = new ArrayList();
al.add(2);
al.add(18);
al.add(32);
al.add(25);
al.add(15);
al.add(8);
al.add(32);
//1.借助Collections类查找列表中指定的数据
System.out.println("列表中最大的数据:"+Collections.max(al));
System.out.println("列表中最小的数据:"+Collections.min(al));
//2.借助Collections类替换指定的数据
Collections.replaceAll(al, 32, 100);
System.out.println(al);
/**
* 3.借助Collections类实现二分查找集合中的数据
* (对集合进行二分查找之前一定要先将集合元素进行排序)
*/
Collections.sort(al);
System.out.println(Collections.binarySearch(al, 32));
System.out.println(Collections.binarySearch(al, 100));
}
}
3>同步控制
public class CollectionsDemo {
public static void main(String[] args) {
//分别创建List set map 线程安全的集合
Collection c= Collections.synchronizedCollection(new ArrayList());
List list =Collections.synchronizedList(new ArrayList());
Set set =Collections.synchronizedSet(new HashSet());
Map map=Collections.synchronizedMap(new HashMap());
}
}
🔖Arrays工具类
1>Arrays工具类基础用法
public class ArraysTest {
public static void main(String[] args) {
/**
* 通过Arrays工具类实现对数组的操作
* 1.对数组是否相等进行判断(equals)
* 2.完成对数组的扩容、拷贝(copyOf)
* 3.将数组转换为字符串数据(toString)
* 4.对数组进行填充(fill:包括左侧,不包括右侧的数据)
* 5.对数组进行排序(sort)
*/
//1.判断两个数组是否相同(每个数组的元素、元素次序要一一对应)
int[] arr1 = {1,2,3,4,5};
int[] arr2 = {1,2,3,4,5};
System.out.println(Arrays.equals(arr1, arr2));
//2.对数组进行扩容、拷贝
int[] arr3 = Arrays.copyOf(arr1, arr1.length*2);
//3.将数组转化为字符串数据
System.out.println(Arrays.toString(arr3));
/**
* 4.对数组进行填充(包括左侧,不包括右侧的数据)
* 第1个参数是指要进行操作的数组
* 第2、3个参数是指填充的范围from、to
* 第4个参数是指用什么数据进行填充
*/
Arrays.fill(arr3, 4, arr3.length-1, 9);
System.out.println(Arrays.toString(arr3));
//5.对数组进行排序
int[] arr = {5,9,1,14,3,25};
Arrays.sort(arr);
System.out.println(Arrays.toString(arr));
}
}
2>使用Java8增强的Arrays类的方法
Java8增强了Arrays类的功能,为Arrays类增加了一些工具方法,这些工具方法都是利用多cpu并行的能力提高 性能。
public class ArraysDeepTest {
public static void main(String[] args) {
/**
* java8增强了Arrays类的功能
* 1.判断两个数组中对象的引用是否相同(deepEquals)
* 2.对数组进行并发排序(parallelSort)
* 3.使用自定义排序规则对数组进行排序(parallelSort)
* 只是在底层优化,并不会看到多么明显的效果
*/
Object[] obj1 = new Object[]{5,9,18,8,20,3};
Object[] obj2 = new Object[]{5,9,18,8,3,20};
//1.判断两个数组中对象的引用是否相同(底层用==进行判断)
System.out.println(Arrays.deepEquals(obj1, obj2));//false
//2.对数组进行并发排序
int[] arr3 = {6,15,23,4,2,9};
Arrays.parallelSort(arr3);
System.out.println(Arrays.toString(arr3));
//3.使用自定义排序规则对数组进行排序(此处用字符串长度进行排序)
String[] arr = {"java","Oracle","MySql","数据库","c++"};
Arrays.parallelSort(arr, 0, arr.length, (o1,o2)-> o1.length()-o2.length());
System.out.println(Arrays.toString(arr));
}
}
<2>泛型
Java集合有一个缺点,把一个对象丢进集合中,集合就会忘记这个对象的数据类型,该对象的类型就变为Object类型。Java集合之所以这样设计因为集合的设计者不知道要存储的类型是什么,为了做到通用性设计为Obejct 。
泛型是JDK5中引入的特性,它提供了编译时类型安全检测机制,将运行时期的问题提前到了编译期间,从而避免了强制类型转换。所谓的泛型就是在创建集合的时候指定集合的类型。
参考案例:
import java.util.ArrayList;
import java.util.HashSet;
import java.util.TreeMap;
public class ArrayListDemo {
public static void main(String[] args) {
//在编译的时候不检查类型的异常
ArrayList al = new ArrayList();
al.add(1);
al.add("haha");
al.add('k');
al.add(1.23333);
//上述集合添加数据操作,编译器正常执行,不显示任何错误操作,不检查错误
//在创建集合的时候指定集合存储数据的类型称之为泛型
ArrayList<String> als = new ArrayList<String>();
als.add("haha");
als.add("xixi");
//als.add(1); 一旦指定了集合数据存储的数据类型,就必须添加指定类型的数据,否则编译器会报错
//java7的菱形语法,后方的数据类型可以省略,系统会自动判断数据类型
ArrayList<Integer> ali = new ArrayList<>();
HashSet<Double> hs = new HashSet<>();
TreeMap<String,String> tm = new TreeMap<>();
}
}
🔖深入泛型
//定义泛型类和泛型接口
public class Apple<T> {
//使用T类型的参数定义实例变量
private T info;
public Apple(){ };
public Apple(T info){
this.info = info ;
}
public T getInfo()
{
return this.info;
}
public void setInfo(T info)
{
this.info = info ;
}
}
//子类继承泛型父类 需要明确数据类型 或者 继续使用泛型
public class DemoA<String> extends Apple {
@Override
public String getInfo() {
return (String)super.getInfo();
}
}
public class DemoB<T> extends Apple {
@Override
public Object getInfo() {
return super.getInfo();
}
}
🔖使用泛型通配符
泛型通配符说明:
类型通配符: <?>
- ArrayList<?>: 表示元素类型未知的ArrayList,它的元素可以匹配任何的类型
类型通配符上限: <? extends 类型>
- ArrayListList <? extends Number>: 它表示的类型是Number或者其子类型
类型通配符下限: <? super 类型>
- ArrayListList <? super Number>: 它表示的类型是Number或者其父类型
参考案例:
import java.util.ArrayList;
//为了表示各种泛型List的父类 可以使用类型通配符。类型通配符是一个问号(?)。
//将一个问号作为类型实参传递给List集合。
public class GenDemo {
public void f1(ArrayList<Object> list)
{
//对list集合进行迭代
list.forEach(System.out::println);
}
public void f2(ArrayList<String> list)
{
list.forEach(System.out::println);
}
public void f3(ArrayList<?> list)
{
list.forEach(System.out::println);
}
public static void main(String[] args) {
GenDemo gd = new GenDemo();
ArrayList<String> list = new ArrayList<>();
list.add("123");
list.add("234");
list.add("345");
//gd.f1(list); ArrayList<Object> 不是ArrayList<String>的父类,因此编译不通过
gd.f2(list); //编译通过
gd.f3(list); //ArrayList<?>是ArrayList<String>的父类,编译通过
}
}
设置通配符的上限和下限
当直接使用List<?>这种形式,表明List集合可以是任何泛型List的父类 ,但是有一种特殊的情况,程序不希望这个List<?>是任何泛型List的父类 而是希望是某一种泛型List 的父类。
import java.util.ArrayList;
import java.util.Collection;
//定义Person、Worker、Teacher、Student四个类进行测试
public class GenDemo1 {
public static void show(Collection<?> list )
{
list.forEach(System.out::println);
}
public static void main(String[] args) {
/**
* 泛型的限定
* ? extends E: 接受E类型 或者E的子类类型
* ? super E: 接受E类型 或者E的父类类型
*/
ArrayList<Person> ap =new ArrayList<>();
ap.add(new Person("张三1", 11));
ap.add(new Person("张三2", 12));
ap.add(new Person("张三3", 13));
ap.add(new Person("张三4", 14));
ArrayList<Student> as =new ArrayList<>();
as.add(new Student("李四1", 11));
as.add(new Student("李四2", 12));
as.add(new Student("李四3", 13));
as.add(new Student("李四4", 14));
ArrayList<Worker> aw =new ArrayList<>();
aw.add(new Worker("王五1", 11));
aw.add(new Worker("王五2", 12));
aw.add(new Worker("王五3", 13));
aw.add(new Worker("王五4", 14));
ArrayList<Teacher> at =new ArrayList<>();
at.add(new Teacher("赵六1", 11));
at.add(new Teacher("赵六2", 12));
at.add(new Teacher("赵六3", 13));
at.add(new Teacher("赵六4", 14));
//1、如果show方法中的形参是Collection<?>,下述四种情况编译均通过
show(ap);
show(as);
show(aw);
show(at);
//2、如果要求show方法只能够接收Worker或者是Worker的子类
//则show方法中的形参为Collection<? extends Worker>
show(ap); //编译不通过
show(as); //编译不通过
show(aw);
show(at);
//3、如果要求show方法只能够接收Worker或者是Worker的父类
//则show方法中的形参为Collection<? super Worker>
show(ap);
show(as); //编译不通过
show(aw);
show(at); //编译不通过
}
}
🔖泛型方法
import java.util.ArrayList;
import java.util.Collection;
public class GenericMethodTest {
//将一个数组中的数据存储到集合当中
public static void save(Object[] arr,Collection<Object> coll)
{
for(Object o : arr)
{
coll.add(o);
}
}
//使用泛型方法实现上述功能
public static <T> void saveGeneric(T[] arr,Collection<T> coll)
{
for(T t : arr)
{
coll.add(t);
}
}
public static void main(String[] args) {
//测试
Object[] oa = new Object[100];
Collection<Object> co = new ArrayList<>();
save(oa,co);
saveGeneric(oa,co); //此时T类型为Object类型
String[] sa = new String[100];
Collection<String> cs = new ArrayList<>();
// save(sa,cs); 编译出错
saveGeneric(sa,cs); //此时T类型为String类型
Integer [] ia =new Integer[100];
Float [] fa =new Float[100];
Number [] na =new Number[100];
Collection<Number> cn =new ArrayList<>();
//下述T类型为Number类型,分别从Integer、Float、Number-->Number
saveGeneric(ia,cn);
saveGeneric(fa,cn);
saveGeneric(na,cn);
//下述T类型为Object类型,从Number-->Object
saveGeneric(na,co);
//下述代码报错,此时T类型为String类型,Number类型并不是String的子类,因而无法转化
saveGeneric(na,cs);
}
}
🔖泛型擦除
Java中的泛型是假泛型 ,仅仅是在编译期有效,在运行期是不存在的。
当把一个具有泛型信息的对象赋值给另外一个没有泛型信息的变量时候,所有在尖括号之间的类型信息都将被扔掉。
public class ErasureTest {
public static void main(String[] args) {
Apple<Integer> a =new Apple<Integer>(6);
//as将得到集合大小
Integer as =a.getSize();
//把a对象赋值给apple变量b 将丢失尖括号的类型信息
Apple b=a;
//b只是getSize返回的类型是Number类型 所以不报错
Number as2=b.getSize();
//下面的代码将报错 是由于在对b进行赋值丢失了数据类型 所以报错
// Integer as3 =b.getSize();
}
}